基于PCA-LWCA-LS-SVM回采工作面瓦斯涌出量预测
2018-12-13李雅梅
张 瑞 李雅梅
(辽宁工程技术大学电气与控制工程学院 辽宁 葫芦岛 125105)
0 引 言
瓦斯是引发煤矿安全事故的主要因素之一。瓦斯涌出量的精确预测,是预防煤矿瓦斯事故的重要前提。针对此项工作,已有众多学者提出了较为有效的预测方法,如:矿山统计法、瓦斯地质数学模型法、分源预测法等线性瓦斯预测方法,以及卡尔曼滤波法、神经网络预测法、灰色系统法、主成分回归分析法、聚类分析法等非线性瓦斯预测方法。但上述预测模型也存在着一定的缺陷,如:神经网络模型需要选择模型及参数,存在着收敛速度慢等缺点[1];灰色理论预测当原始数据序列波动大并且信息过于分散时,预测精度将会降低[2];聚类分析法中隶属度的确定受人为因素影响较大[3]。且上述各种方法都不能很好地解决实际工作中普遍存在的变量之间多重共线性问题[4]。
针对以上现状,提出基于主成分分析PCA与双层狼群算法LWCA优化最小二乘支持向量机LS-SVM相耦合的预测模型。该模型首先引入PCA对数据进行降维处理,保留绝大部分信息的同时,降低了数据的维度。然后利用LS-SVM求解速度快、泛化能力强的特点[5]对瓦斯涌出量进行预测。为了进一步提升预测模型的性能,借鉴文献[6]利用LWCA优化Elman神经网络ENN(Elman Neural Network)参数的思想,采用LWCA来优化LS-SVM的参数,改善了传统的群体智能算法收敛速度慢,易陷入局部最优解等问题[7],在简化了模型求解过程的同时提高了模型的预测精度。同时由于利用LS-SVM进行瓦斯涌出量的预测,改善了神经网络需要大量训练样本及训练时间长的缺点。
1 核心理论模型
1.1 PCA算法
在瓦斯涌出量预测过程中,多个影响因素之间常具有多重共线性,此将会对模型的建立及其预测性能造成不利影响。利用PCA算法对其进行处理,可改善此问题。同时由于主成分贡献率较小的特征向量往往与噪声有关,因此也可起到一定的去噪效果[8]。采用PCA处理后的数据,既保留了原数据的大部分信息,又能够降低数据的维度,从而降低问题的复杂性。
PCA降维步骤如下:
将含有k个样本,且每个样本具有n个特征x1,x2,…,xn的数据集表示为矩阵形式:
(1)
Step1对式(1)进行标准化处理:
(2)
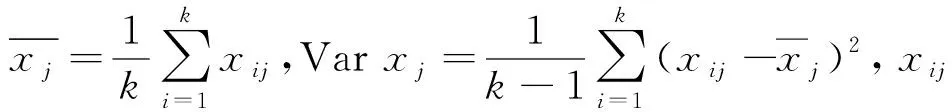
Step2计算样本相关系数矩阵:
(3)
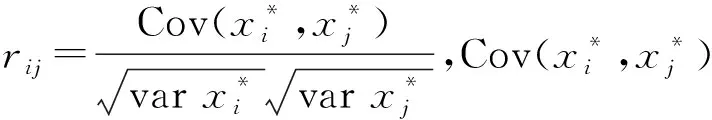
Step3计算R的特征值(λ1,λ2,…,λn),特征向量αi=(αi1,αi2,…,αin),i=1,2,…,n。
Step4利用步骤3中获取的特征向量αi=(αi1,αi2,…,αin),求得主成分:
Fi=αi1X1+αi2X2+…+αinXni=1,2,…,n
(4)
Step5利用主成分累计贡献率确定需要采用的主成分个数:
(5)
由此便可利用以上步骤所获得的主成分代替原始数据进行后续的处理。
1.2 LS-SVM回归算法
LS-SVM从损失函数着手,在其优化问题的目标函数中使用二范数,并用等式约束替换不等式约束。从而缩短了SVM的学习时间,具有求解速度快,泛化能力强[9]的优势。优化目标为:
(6)
s.t.yi=ωTφ(xi)+b+ζi
式中:c为正则化参数,它可以在模型的复杂程度和训练误差之间做一个折衷选择,便于使所求的模型拥有较好的泛化能力。ζi为松弛变量。通过引入拉格朗日函数及KKT最优条件,得出LS-SVM的回归模型:
(7)
式中:k(x,xi)为核函数,本文选取学习能力较强的高斯核函数[10]:
(8)
式中:σ为核宽度。
1.3 LWCA算法
当通过交叉验证CV(Cross Validation)的方式来取得LS-SVM参数c与σ的值时,不能保证所获取的参数为全局最优,从而不能充分发挥模型的性能。因此本文利用LWCA的全局寻优能力及收敛速度快等优点来获取LS-SVM回归模型的最优参数。
LWCA是模拟狼群捕食过程而提出的一种算法,由于其采用胜者为王和强者生存的法则,使其具有良好的全局寻优能力及快速的收敛速度[11],其规则如下:
1) 初始化狼群。
首先建立由N匹狼组成的狼群,令狼群中的个体随机分布在搜索空间内。
Xi=(xi1,xi2,…,xid) 1≤i≤N,1≤d≤D
xid=xmin+rand×(xmax-xmin)
(9)
式中:rand为均匀分布在[0,1]中的随机数,xmax、xmin为搜索空间的上下界。
2) 首狼的选取。
首先在狼群中选出适应值最优的q匹竞选狼,竞选狼在h个方向中的第j个点第d维的位置更新为:
yjd=xxid+rand×stepa
(10)
式中:rand为均匀分布在[-1,1]内的随机数;stepa为搜索步长;xxid为竞选狼,1≤j≤h。
3) 向首狼移动。
由于首狼最为接近猎物,所以参照首狼位置,其他狼向首狼移动,其他狼的位置更新公式为:
zid=xid+rand×stepb×(xld-xid)
(11)
式中:rand为均匀分布于[-1,1]的随机数,stepb为移动步长,xld为首狼位置,xid为其他狼当前的位置。
4) 种群包围。
首狼找到猎物后,通知其他狼对猎物进行包围:
(12)
5) 越界处理。
(13)
在搜索的初期,为尽快寻找到全局最优的邻域,狼群采用较大的包围步长,在到达最优邻域的附近后,个体减小包围步长,以进行局部的搜索。步长计算公式如下:
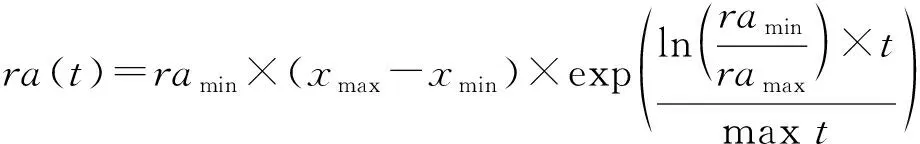
(14)
式中:maxt为最大迭代次数,ramax为最大的包围步长,ramin为最小包围步长。
狼群按照以上规则搜索猎物,每轮迭代完成后,采用淘汰适应值最差的m个个体,再以随机的方式生成m个个体的方式对狼群进行更新。此算法可以精确、快速地搜寻到全局最优解。
2 预测模型建立
首先利用PCA对数据进行降维处理。而后通过LWCA对LS-SVM回归模型的参数进行全局寻优以提升其性能。
2.1 适应度函数选取
以下式作为衡量狼群个体适应度的标准:
J(xi)=-RMSE
(15)
式中:RMSE为模型的训练均方根误差,其定义如下误差越小,狼群个体的适应度越好。
(16)
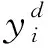
2.2 基于PCA-LWCA-LS-SVM的预测模型建立
在建立预测模型的过程中,以狼群的个体代表LS-SVM的正则化参数c与核参数σ,根据式(15)确定的适应值来衡量狼群位置的优劣。
模型的建立步骤如下:
Step1对狼群进行初始化,令其规模为N,最大迭代次数为maxt,竞选狼个数q,搜索方向h,竞选狼的最大搜索次数maxdh,搜索步长stepa,移动步长stepb,最大最小包围步长ramax、ramin及最差狼群个数m,通过式(9)初始化狼群的位置分布。
Step2初始化LS-SVM的正则化参数c与核参数σ,并将其映射至狼群个体。
Step3输入经过PCA降维的训练样本。
Step4利用式(15)计算狼群个体的适应值,狼群根据适应值进行迭代寻优。
Step5当模型达到要求的精度或达到最大迭代次数时停止训练。通过适应度最优的狼群的位置,获取LS-SVM的参数,从而获得预测模型。
3 实 验
3.1 样本选取
选取煤层深度、煤层厚度、煤层倾角、开采层原始瓦斯含量、煤层间距、采高、临近层瓦斯含量、临近层厚度、层间岩性、工作面长度、推进速度、采出率、日产量,共13个对瓦斯涌出量影响较大的因素作为模型的输入变量。
采用沈阳某煤矿2015年间瓦斯涌出量的检测数据来验证本文提出的模型的性能。共选取30组数据作为样本集,其中前20组数据作为本文模型的训练样本集,其余10组作为测试样本。
3.2 数据降维
利用spss软件对现场获取的数据进行PCA降维处理,将所得数据列于表1、表2。

表1 特征值累积贡献率
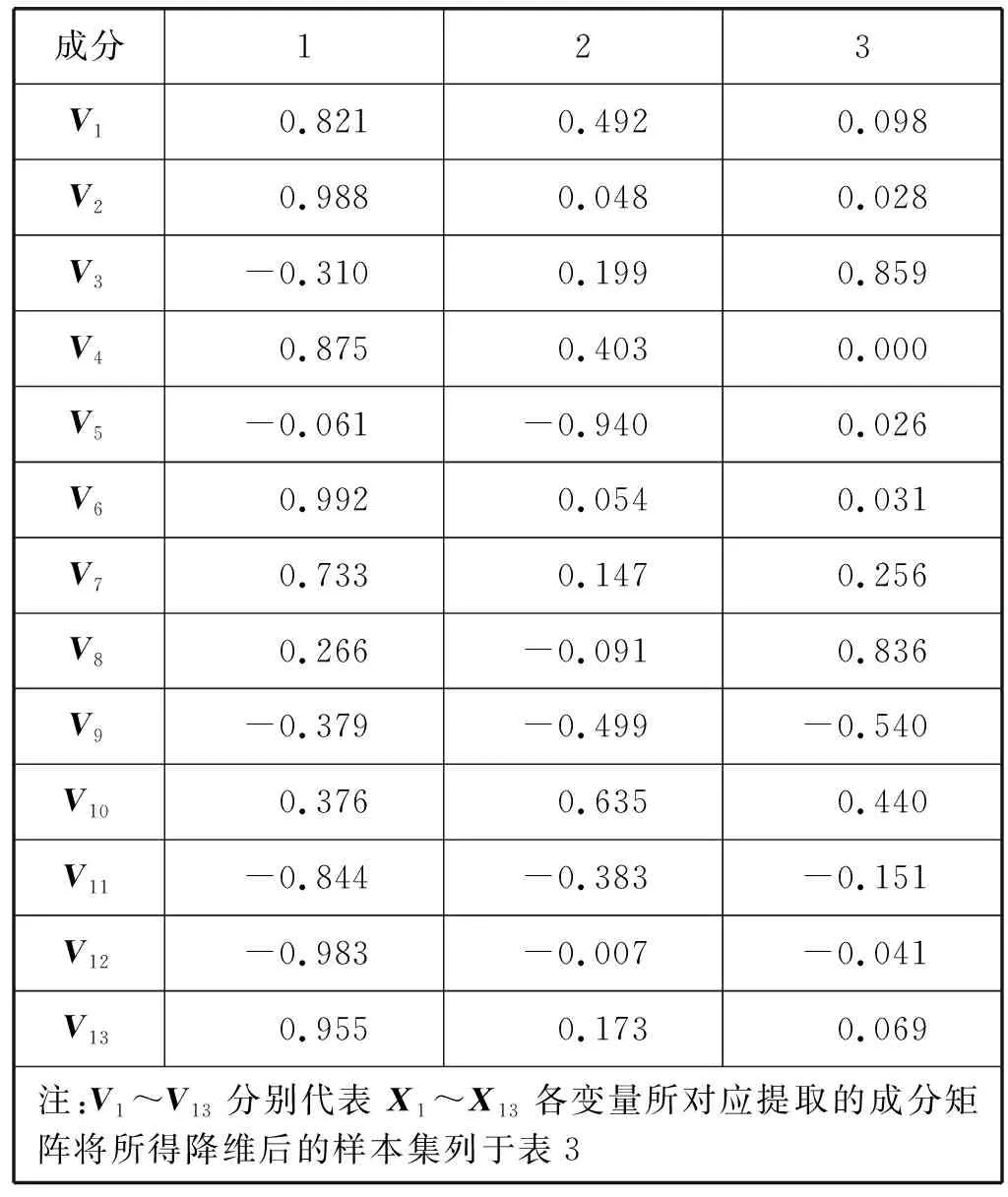
表2 成分矩阵
由于前三个主成分的累积贡献率为86.187%,大于85%,根据主成分选取原则[12],选取前三个主成分。
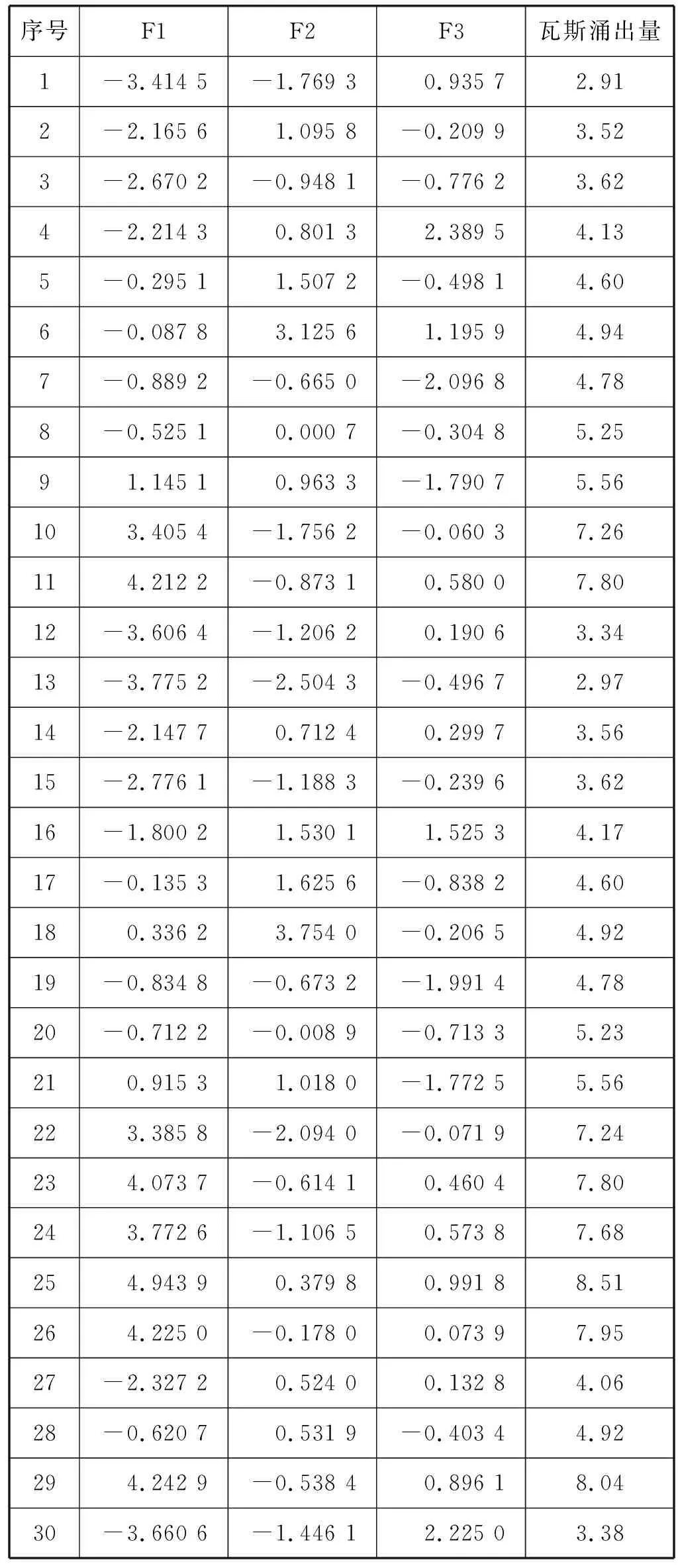
表3 降维后样本集
3.3 仿真实验
将测试样本应用于PCA-LWCA-LS-SVM 预测模型中。初始化狼群,经多次实验,最终狼群算法的参数的设置如表4所示。

表4 狼群算法参数设置
利用MATLAB软件对本文提出的模型进行仿真实验,表3中测试样本的{F1,F2,F3}对应模型的输入,将所获得预测结果列于表5。

表5 PCA-LWCA-LS-SVM预测结果
为进一步检验文中所提模型性能,将其与LS-SVM预测模型、PCA与遗传算法优化的LS-SVM相耦合的预测模型进行对比。各模型获得的预测结果相对误差见图1。
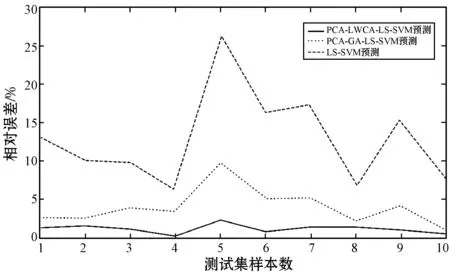
图1 预测结果相对误差
取三种模型预测的最大相对误差、最小相对误差、平均相对误差,列于表6。
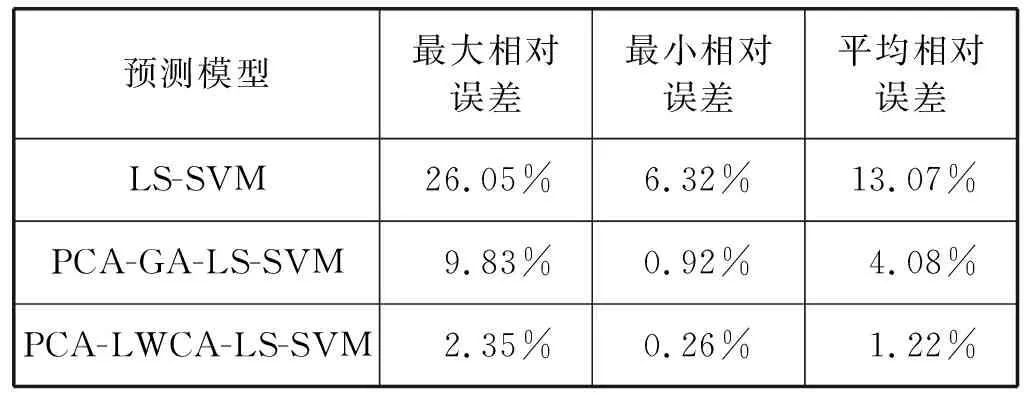
表6 预测结果比较
以上结果表明,PCA-LWCA-LS-SVM 预测模型预测精度高、泛化能力强,可以有效地预测回采工作面瓦斯涌出量。
4 结 语
本文提出的基于PCA-LWCA-LS-SVM的瓦斯预测模型,利用主成分分析法对高维的原始数据进行降维处理,提取出数据的主要信息,同时缓解了瓦斯涌出量影响因素间的多重共线性对模型带来的不利影响。然后利用LWCA对LS-SVM的参数进行全局寻优。该方法在简化模型求解过程的同时,又提高了模型的性能。采用实际工程中获取的数据对该模型进行验证,结果显示该模型具有良好的泛化能力及较高的预测精度,可有效地对瓦斯涌出量进行预测。
