车路协同环境下驾驶员行为识别方法研究∗
2018-12-12王明露
马 雷,陈 珂,王明露,曲 瑞
(燕山大学车辆与能源学院,秦皇岛 066004)
前言
人是交通系统的主体,而驾驶行为识别是智能交通和智能车辆决策的基础,其准确性将进一步增强决策的可靠性。国内外学者对驾驶行为识别进行了较为深入的研究,驾驶员模型研究取得了很多成果。如:(1)基于人—车—环境闭环系统车辆操纵稳定性的驾驶员模型,其主要运用于人—车—环境这类封闭系统车辆稳定性控制的分析和评估,及车辆主动安全操控和智能车辆研发[1-3],该模型仅基于汽车稳定行驶状态建立,未考虑路况、车况影响,及汽车接近失稳该临界状态下的驾驶行为特性;(2)基于智能交通系统的驾驶员行为模型,该模型表现了驾驶员在智能交通系统中对汽车的控制,跟驰和换道模型是该模型的主要模型[4-6],其考虑了车辆密集程度、车道数、车辆模型等外部因素,但未考虑汽车动力学特性,不以汽车行驶稳定性控制为目标;(3)基于交通安全的驾驶员疲劳模型,该模型是反映驾驶员操纵关系与驾驶员疲劳状况的模型[7],但目前还未建立能够清楚地表示出驾驶员疲劳状态和其具体行为关系的驾驶员疲劳模型。
基于车路协同环境及驾驶模型的分析,提出了一种介于车辆操纵稳定性和智能交通系统的驾驶员行为识别方法,该识别方法结合了两者的优点,更加符合人们对驾驶行为状态的描述。本文中主要利用车路协同环境获取道路上各行驶车辆的位置、速度等信息,但由于条件有限,选取微观仿真软件获取道路上行驶车辆的位置、速度等信息,根据汽车动力学完成基本行驶参数到行驶状态参数的转化。具体识别过程为:首先运用邻域粗糙集来对样本数据特征约简;再将EEMD和样本熵融合,完成特征提取及聚类特征向量构建;然后运用模糊聚类对驾驶员行为进行分类识别;最后利用微观交通软件和UC-Win/Road驾驶模拟器仿真得到的样本,采用最小平均贴近度择近原则进行检测分析验证,并根据最大贴近度和次最大贴近度计算待测样本属于某类驾驶行为的隶属度。实验证明该方法取得了良好的识别效果。
1 样本获取与识别特征初选
利用交通微观仿真软件建立城市和高速工况下的路网模型,仿真获取本车及周边车辆的速度、位置等信息,再结合汽车动力学获得车辆动力学信息,为后续处理提供样本数据。
1.1 样本获取
通过预设软件中跟车和换道两个驾驶员模块参数来预先设置驾驶员行为。样本获取:首先,选择合适的高速和城市交通区域,根据调查的交通路网实际运行情况建立路网;然后,预先设置驾驶员行为,仿真获取基本样本。
驾驶员模块参数设置:根据VISSIM用户手册和文献[8]中跟车和换道模型中城市和高速模型各参数与驾驶行为的关系及文献[9]中驾驶员反应时间,分析得到跟车和换道模型中对驾驶员行为影响较大的参数,并将驾驶员行为分为良好、普通、危险3类,分别用A,B,C表示。再结合正交实验法得到城市和高速驾驶员行为分类结果,具体结果见表1,其中bxadd和bxmult分别为城市跟车安全距离附加部分和安全距离倍数部分,CC1为高速跟车期望保持的车头时距,amax1,amax2,a′max1和 a′max2分别为换道超车和被超车最大减速度和可接受最大减速度,d和b分别为换道最小车头空距和协调制动最大减速度。

表1 跟车和换道模型组合下的驾驶行为分类
从表1中3类驾驶员行为各选取一组参数进行仿真,得到各车辆在各路段各车道中各时间点的速度和车头车尾世界坐标系(Xf,Yf),(Xr,Yr)。 文中后续均以该3类驾驶行为类别为准。
1.2 识别特征初选
驾驶员行为用本车及本车周边车辆位置和速度安全信息间接反映,某时刻本车与预换道车道周边车辆状态分析如图1所示,其中若无换道则用与本车相邻的任意一车道代替预换道车道。
根据图1所示的本车与周边车辆行驶状态,初步选取各车辆本车与同车道前后邻近车辆的相对纵向车间距、相对纵向车速(ΔS1,ΔV1,ΔS2,ΔV2),本车与换道前换道车道前后邻近车辆的相对纵向车间距、相对纵向车速(ΔS3,ΔV3,ΔS4,ΔV4),本车与换道前换道车道前邻近车辆的相对横向车间距、相对横向车速(ΔS5和ΔV5),及各车辆的横摆角速度和质心侧偏角12个参数作为判断驾驶员行为状态的特征参数,参数转化如下。

图1 周边车辆行驶状态示意图
由2自由度汽车模型运动[10]分析,可得车辆在大地坐标系与车辆坐标系下转化公式:
式中:vx,vy分别为车辆在大地坐标下的纵向速度和横向速度,由车辆车头车尾坐标(Xf,Yf),(Xr,Yr)得到;v,uc分别为汽车在车辆坐标系下的横向速度和纵向速度;γ为车辆的位置角。
由2自由度汽车模型运动分析及实际运动中侧向加速度v·很小常常忽略,得汽车的质心侧偏角β和横摆角速度ω分别为

式中:ay为汽车质心绝对加速度在oy方向分量。
2 特征的属性约简与数据挖掘
为减少驾驶员行为特征值的冗余性,提高运算速度及识别准确性,在经典粗糙集和传统邻域粗糙集基础上,提出了一种改进邻域粗糙集算法,约简得到对驾驶员行为影响较大的特征属性。再利用EEMD和样本熵相结合对样本数据进行数据挖掘,为聚类提供了数据来源。
2.1 基于改进邻域粗糙集的属性约简
采用基于改进邻域粗糙集属性约简算法是在经典邻域粗糙集前向贪心算法的基础上,将原来的单一邻域半径改成了一个数组形式的邻域半径,然后以空集为起点,逐步向约简集合添加新属性并计算每次全部剩余属性的重要度,将重要度大于设定重要度下限的属性依次添加到约简集合,通过反复迭代,直至最后剩余属性重要度全部小于设定的重要度下限为止。
已知邻域决策系统(U,C∪D),其中 U={t1,t2,…,tn},C,D分别为条件和决策属性集合,∀B∈C,∀ti∈U,ti的 B 邻域为
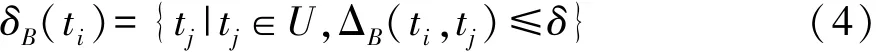
由于在改进邻域粗糙集的属性约简算法中,标准差是反映数据在平均值附近平均波动大小的特性,采用标准差作为邻域半径的选取标准,弥补了经典邻域粗糙集属性约简算法中各条件属性邻域半径设定为同一单一值带来的较大误差[11]。其中,邻域半径计算公式为

式中:δ(ti)为条件属性;ti为邻域半径;Std(ti)为所有样本条件属性ti全部数据的标准差;λ为邻域半径计算参数。
式(5)中,λ是控制邻域半径δ的关键参数。选取λ的范围为[2,4][12],0.1为步长,从2到4对λ进行赋值。属性约简步骤:首先通过设置改进的前向贪心邻域粗糙集算法中λ值,不断修正条件属性的邻域半径,再将计算得到各λ值下的各条件属性重要度与重要下限0.05和0.001比较,选取条件属性重要度大于给定重要度下限作为属性约简后的条件属性;然后再应用分类精度较高的决策树算法(C4.5)和分类性能较稳定的朴素贝叶斯NB(Naive Bayesian)进行分类,计算两种分类器分类精度的平均值(AVG);最后再根据分类精度和属性约简后的属性个数,比较确定最佳λ参数值及最终约简后的属性。
在城市和高速公路工况选取各250个样本,根据文中1.2部分设定条件属性为12个,根据文中1.1部分决策类别为3种,分别为A,B和C。以城市为例,图2和图3为各λ参数在0.05和0.001重要度下限约简前后两种分类算法的平均分类精度和各属性约简个数结果。
图2中1,3和4线分别为约简后C4.5,AVG和NB,2线为约简前 AVG。图 3中 1线为 0.001和0.05约简前,2线为0.001约简后,3线为0.05约简后。由图2和图3可见,当λ=[2.6,3]时,分类精度高,选取λ=2.8和重要下限0.05时,分类精度的均值和剩余约简属性达到最优,此时分类精度为86.8%,剩余6个属性:本车与同车道前近邻车相对纵向车间距、相对纵向车速,本车与换道前换道车道前近邻车相对纵向车间距、相对纵向车速,及各自本车横摆角速度和质心侧偏角。其中,λ=2.8时得到各条件属性的重要度如表2所示。由表2可见,0.05重要度下限下剩余6个属性,上述约简正确。类似地以相同方法约简高速各样本属性最终得到相同剩余约简属性,不再论述。

图2 0.05和0.001重要度下限的分类

图3 0.05和0.001重要度下限下约简前后的属性个数
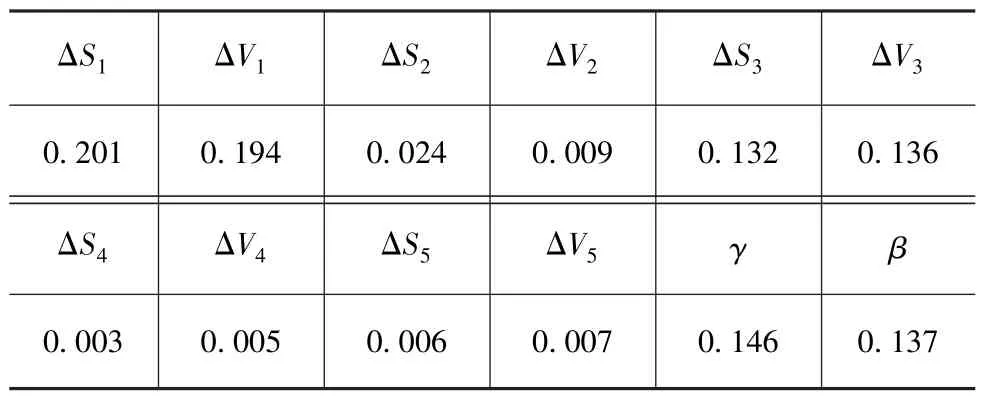
表2 城市道路λ=2.8时各条件属性重要度
2.2 基于EEMD和样本熵的特征提取
EEMD是基于EMD在原始信号中加入高斯白噪声产生的,其应用白噪声频域频率均匀分布及零均值特性,使信号分解既保留了EMD的优点且抑制了EMD的模式混淆现象,使原始信号分解精度有效提高[13-14]。EEMD具体算法如下:
(1)确定平均运算次数M与将要加入的高斯白噪声的幅值,将白噪声加入原始信号x(t),得到新信号xi(t),其中i为添加白噪声次数;
(2)将xi(t)EMD分解,得到一组IMF分量;
(3)将上述IMF分量从x(t)中剔除,得到新信号。
重复以上步骤,直至得到x(t)所有分量为止,将得到的对应IMF总体求均值,得到最终IMF和一个剩余残余量rn(t)。

式中cij(t)为第i次加入白噪声后,经EEMD分解得到的第j个IMF分量。
根据EEMD算法,设定本次实验白噪声幅值为0.1,运算次数100,以城市3类驾驶员中一组横摆角速度EEMD分解为例,结果如图4所示。图中各曲线表示各类驾驶行为下各自横摆角速度信号分解得到的初始数据信号的固有模态函数(即IMF分量)。城市3类驾驶行为各特征相关系数与阈值见表3。
由表3可见,IMF1和IMF2相关系数相对其余IMF分量较大,则上述城市3类驾驶行为车辆的真实分量为IMF1和IMF2。采用上述相同方法,处理城市和高速中各样本数据,得到大多数特征真实分量均在 IMF1~IMF2之间。因此,最终取 IMF1~IMF2作为所有特征的真实分量。
样本熵是一种度量时间序列复杂度的方法,反映了原时间序列维数改变时产生新模式的概率及模式间自我相似度,具有良好的一致性和抗数据丢失能力。再将上述筛选出的各特征IMF真实分量的样本熵值作为驾驶员行为识别特征向量,会相应提高驾驶员行为识别准确率。
时间序列{c(t)|1≤t≤M}样本熵算法如下:
(1)构造m维矢量 c(k)=[c(k),c(k+1),…c(k+m-1)],(1≤k≤M-m+1);
(2)计算c(k)和c(j)间对应元素的最大值d[c(k),c(j)];
(3)计算小于给定相似容限r的d[c(k),c(j)]的数目与矢量总数M-m的比值的均值Bm(r);

图4 城市道路3类驾驶行为横摆角速度EEMD分解
(4)将模式维数m加1,重复步骤(2)和步骤(3)得到Bm+1(r)。当M有限时,可计算得到时间序列样本熵SampEn(m,r,M)的估计值。
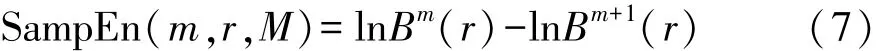
参数m和r影响样本熵的计算精度,经分析,选取m=2,r=0.1ε(ε为原始数据的标准差)时,样本熵统计特性相对较理想。以城市道路3类驾驶行为为例,根据上述EEMD分解、特征筛选和样本熵计算,部分样本熵如表4所示,并将计算所得样本熵值构成特征向量作为聚类的数据来源。

表3 城市3类驾驶行为各特征相关系数与阈值
3 基于GG聚类驾驶行为识别验证
3.1 GG聚类不同驾驶行为实验分析
基于GG聚类优点:它是基于数学统计的模糊估计聚类法;GG聚类曲线呈不规则形,扩张了其应用范围,对大小、密度、形状均不同的样本集合也可实施聚类分析。因此选GG聚类运用于驾驶员行为识别[15],GG聚类算法如下。
假设聚类样本集合 X={x1,x2,…,xn},对任意样本xi(0≤i≤n)均有 s个特性指标,即:xi={xi1,xi2,…,xis},现将该集合划分为 c类(2≤c≤n);设其隶属度矩阵和聚类中心分别为 U=[μjk]c×n和 V=[v1,v2,K,vc]T,其中 μjk为第 k 个样本元素对于第 j类的隶属度且μjk∈[0,1]。该聚类原则是经过多次迭代来调整(U,V)使目标函数J(U,V)取最小,目标函数为

表4 城市道路3类驾驶行为剩余属性的样本熵(部分)
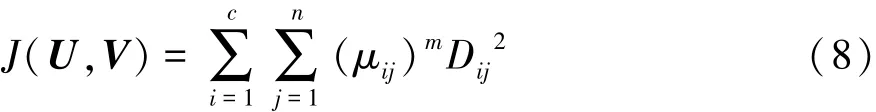
式中:m为模糊指数,m的值越大各聚类重叠的越多,即划分的越模糊,一般选取m=2;Dij为引入模糊最大似然估计的距离测度。
GG聚类具体运算步骤如下:
(1)设定聚类分类数目c,模糊指数m,初始化模糊划分矩阵U;
(2)计算聚类中心vj,其中L为迭代次数

(3)引入模糊最大似然估计距离测度

式中:pj为聚类中第j类被选中的先验概率;Bj为聚类中第j类的协方差矩阵;Djk为引入模糊最大似然估计的距离测度。
(4)更新隶属度矩阵U

至满足‖U(L+1)-U(L)‖<σ,(σ 为∀正数),否则继续迭代,重复(2),至满足更新终止条件。
应用GG算法聚类,聚类数目c=3,模糊指数m=2,容差τ=0.0001,将上述章节获取的样本熵看作GG聚类的输入特征矩阵。选取1 250组样本数据,运行GG聚类不断迭代更新聚类中心,得到聚类结果如图5所示,其中“o”是样本的聚类中心。
向量X根据同属于一个类别驾驶行为的不同样本数据享有相似性,经GG聚类,其将会围绕在同一个聚类中心附近。从图5可以看出,城市和高速各形成3个聚类中心,其中各类中的样本点分别紧凑地分布在各类聚类中心周围,表明GG聚类算法达到了良好的聚类效果。
应用分类系数法和平均模糊熵法检验GG聚类效果,结果如表5所示。
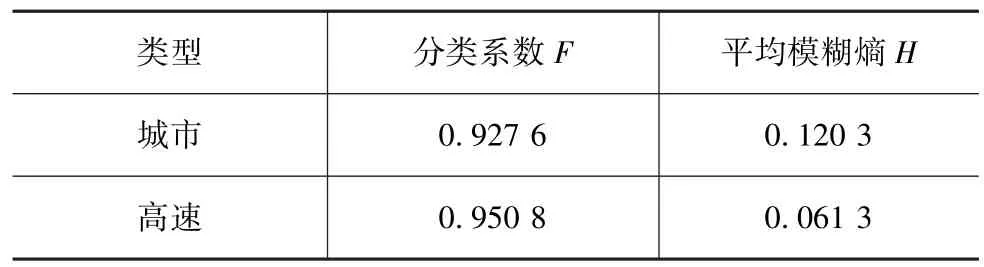
表5 GG聚类效果检验
依据原则:分类系数F的值越靠近于1,同时平均模糊熵H的值越靠近于0,则其聚类效果越好。所以由表5可知,GG聚类适合用于驾驶行为识别中,且效果较好。
3.2 不同类型驾驶行为识别
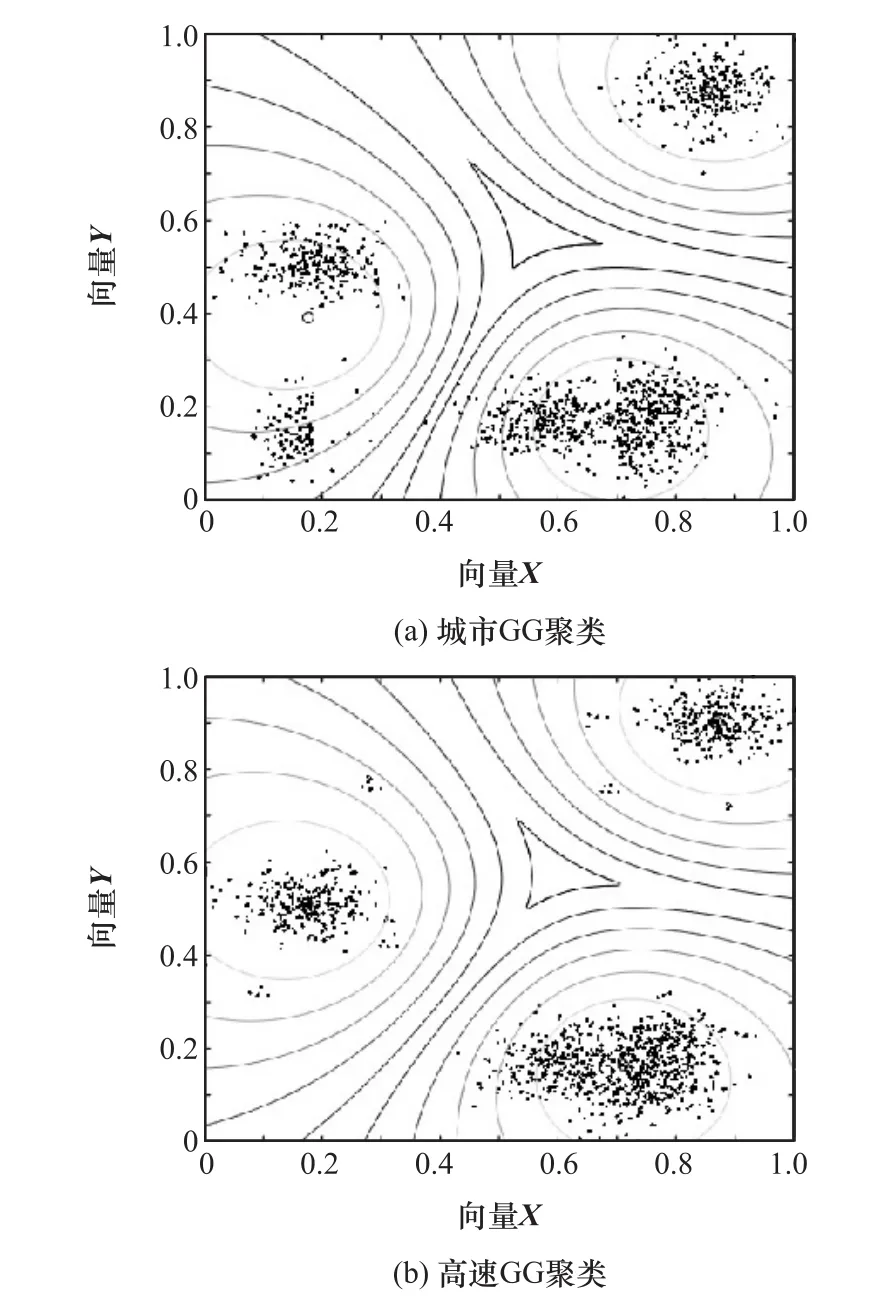
图5 城市和高速下3种驾驶行为状态GG聚类
选取20人次通过UC-Win/Road 3自由度驾驶模拟器模拟3类不同驾驶行为,获取 20组待测样本,其余待测样本通过微观仿真软件仿真获取,最终共获得200组待测样本。驾驶模拟器如图6所示。将实验样本经过EEMD和样本熵处理得到的数据作为待识别样本,以GG聚类的聚类中心为标准样本,标准样本见表6和表7。

图6 驾驶模拟器

表6 城市道路下标准样本

表7 高速道路下标准样本
对数据进行标准化处理,然后根据最小平均贴近度公式:

其中0≤Z(t)≤1
分别计算其和各自标准样本最小平均贴近度,对样本进行诊断识别,根据最大贴近度原理上述200组样本部分诊断结果如表8所示。
统计以上200个样本识别结果,计算得到城市和高速驾驶员行为诊断正确率分别为92%和93%。且根据表9可知,出现分类错误的几个样本其最大贴近度与次贴近度大小相近,说明上述GG聚类分类器是可靠和有效的。图7为3类驾驶员行为各样本最大贴近度与次贴近度图。其中横坐标取各类样本总数间隔分之一。
如图7(a)所示,次贴近度曲线代表A类样本与B类样本的贴近程度,图中左侧距离B类聚类中心较远,说明这些样本驾驶行为更加良好,而右侧靠近B类样本中心,说明这些样本驾驶行为逐步向B类靠拢;图7(b)次贴近度曲线左右两侧分别于A类和C类的贴近程度;图7(c)与图7(a)情况相似。贴近度表征两模糊子集间的相近程度,贴近度越趋近于1表明两子集越接近。如表8中组号1和2两个样本,3个贴近度之和不相等,且不为一,其原因是聚类中心为12维,因此其分类边界是复杂的,不能将最大贴近度作为该样本属于该类的隶属度。根据式(14)可知,贴近度计算已对数据进行标准化处理,即实现对数据的归一化,同时可以认为1-δi表征到3个聚类中心距离。而驾驶员行为是渐进变化的,因此设直线上有A,B和C 3点分别表示与3类贴近度为1的点,在直线上选取两点m和n,分别属于A和B两类,如图8所示。
图8中Lij表示点i到j的距离。m点代表图7(a)中左侧样本,与图7(c)右侧样本类似;n点代表其它样本。计算m和n点样本隶属度分布如式(15)~式(17)所示,图9为样本隶属度计算结果。

表8 不同驾驶员行为类型诊断结果(部分)

图7 各类样本最大贴近度与次贴近度关系

图8 隶属度计算示意图

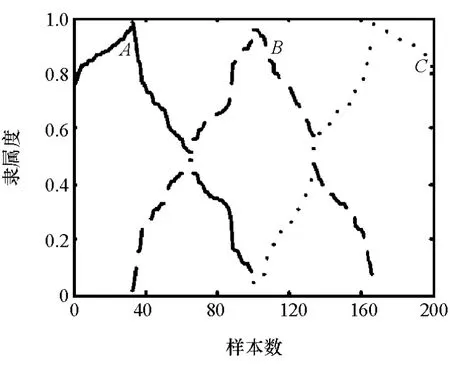
图9 样本隶属度图
如图9所示,A,B和C分别为3类的中心值,从分布上看基本与模糊控制中的三角形分布相类似。表8中组号3和4两个样本属于A类的隶属度分别为0.894和0.825。虽然组号3的隶属度大于组号4,但是组号4的样本位于A类中心的左侧,而组号3位于A类中心的右侧,说明其驾驶行为相对于样本3更加良好,说明隶属度更有利于对驾驶行为的评价。表9为分类误判样本的隶属度。

表9 误判样本隶属度表
根据表9可知,误判样本的隶属度都在0.4和0.6之间,位于图9中两类隶属度交叉处,说明即使在识别不准确的情况下,隶属度也基本可描述该样本的驾驶行为。
4 结论
(1)给出基于本车车辆动力学信息与周边车辆的位置、速度等信息的驾驶员行为评价方法。该方法是介于车辆操纵稳定性与智能交通系统的驾驶员行为评价方法,结合了两者的优势,更加符合实际人们对驾驶行为状态的描述。
(2)运用粗糙集理论实现对识别特征的属性约简,使识别特征属性由12个约简为6个,有效地避免了模式识别中的维数灾难问题,提高了方法的可用性。利用EEMD对约简后特征进行数据挖掘,可以从大量历史数据中自动搜索隐藏于其中的特殊关系性,利于发现识别特征有益于模式识别的内在属性,提高识别的可靠性。
(3)采用GG聚类方法,应用最小平均贴近度择近原则实现了不同驾驶行为的识别。根据最大贴近度和次最大贴近度计算待测样本属于某类驾驶行为的隶属度,即使在识别不准确的情况下,该隶属度也基本可描述样本的驾驶行为。
