基于 Slurm 的深度学习高性能计算平台设计及其调度实现技术
2018-10-15陆忠华胡腾腾王彦棡刘芳王珏
陆忠华,胡腾腾,2,王彦棡,刘芳,王珏*
1.中国科学院计算机网络信息中心,北京 100190
2.中国科学院大学,北京 100190
引言
物联网和移动互联网时代的到来,数据产生以各类形式来源于生产生活的方方面面,例如:感知器,日志文件,emails,社交媒体,各类图片和视频等等。据估计当今 80% 的数据是无结构化的,无结构化的数据正以 15 倍于结构化的数据增长,预计到 2020年全球数据总量将达到 40 zettabytes (1021 bytes),人类已经真正步入了一个以数据为中心的时代[1]。2003、2004年,Google 相继发表了两篇文章论述了他们为应对海量数据而开发的两项新技术 GFS和 MapReduce,使得许多正为数据急剧膨胀而头疼不已的企业看到了希望。受到该两篇论文的启发,开源社区做出了一系列的具有工业化生产价值的生态系统:Hadoop,MapReduce,Hive,Pig,HBase 等。大规模数据的处理,业界已经达到很好的效果,但是随着 2012年,Hinton 采用深度学习的方法一举夺得ImageNet 比赛的冠军,人类对大规模数据进行复杂的计算需求日益增长。
HPC (高性能计算集群)天然就拥有一整套完整的、成熟的、高度优化的针对高性能计算的家族体系技术。例如:专有的高性能优化传递网络(InfiniBand,IBM Blue Gene interconnects),高性能消息传递库 (MPI),丰富的面向各类体系结构加速的数学计算库 (BLAS,LAPACK),高效的并行文件存储系统 (Lustre,Parastor)以及将各类软件组合在一起的调度器 (Slurm,LSF)。
已发展成熟的高性能计算完美适配于以深度学习为代表的强调大数据计算的算法,本文以高性能计算集群的相关设施为基础,针对人工智能与机器学习方面的需求,进行相关技术的选型,并通过代码编写,使 Slurm 适配于分布式 Tensorflow,从而对大规模的数据进行深度学习方面的学习与训练。
本文接下来组织方式如下:第一部分介绍基于 Slurm 的深度学习计算平台设计,第二部分使用Slurm 调度 Tensorflow 进行相关实验,第三部分整理并总结全文。
1 基于 Slurm 的深度学习 HPC 设计
深度学习计算平台实践主要是从物理节点层、共享存储层、调度层和应用层这四个层次进行选型设计实践的,为了应对大数据和深度学习使用的要求,本文针对所设计的深度学习平台上述的每个层次都认真进行技术选型。在 Slurm 的调度层次针对分布式TensorFlow 制作了插件改进,下面在各小结中予以阐述。
1.1 物理节点层
1.1.1 GPU、CPU 型号选择
每台服务器采用 2 颗 Intel Xeon 2650v4 处理器,其双精度浮点运算峰值 40.55 亿万次每秒,于 2016年中国高性能计算机性能 TOP15 中有 3台选择了 Intel Xeon 2650v3 处理器,Intel Xeon 2650v4 与 Intel Xeon 2650v3 差别并不大,故所选 CPU 属于较为典型的高性能 CPU。GPU 选择NVIDIA Tesla P100,这是 NVIDIA 公司 2017年推出的新一代面向深度学习的 GPU,其双精度计算峰 1786TFlops,单精度峰值达 3534TFlops。相比于K80, P100 在双精度计算上是其 1.6 倍,在内存带宽上是其 3 倍,在 GPU-GPU 通信中,比传统 PCI express 提高了 3 倍。

图1 平台整体架构图Fig.1 Platform architecture diagram
1.1.2 InfiniBand 网络
Infiniband 网络通过一套中心 Infiniband 交换机在存储、网络以及服务器等设备之间建立一个单一的连接链路。[2]计算存储网络方案采用 Infiniband 高速网络,配置 1 台 108 口 56Gb/s FDR大端口模块化 IB交换机,实现系统节点之间 56Gb/s FDR 线速交换。56Gb/s FDR InfiniBand 仅有 0.7 微妙低延时,较高带宽,采用大端口模块化核心层 IB 交换机组网方案,布线规划更简单,扩展灵活机动。相比于小交换机堆叠方案,模块化大端口交换机内部采用背板、页板接插无线缆设计,适用于 InfiniBand 高速信号,信号损失小,可靠性更高。
1.2 共享存储系统层
目前,较为主流的分布式存储系统有:GFS、HDFS、Lustre 和 parastor。前两者是互联网大数据公司较为常用,而 Lustre 与 parastor 主要应用于超算系统。GFS 分布式文件系统是由 Sanjay Ghemawat 等人提出,并在 2003年于的 ACM Sigops operating system review 上发表的一篇名为《 The google file system》文章。HDFS 在最开始是作为 Apache Nutch 搜索引擎项目的基础架构而开发的,放宽了一部分 POSIX 约束,从而实现流式读取文件的目的并能提供高吞吐量的数据访问,适合大规模数据集上的应用。HDFS是以 master、slave 为架构,每个 HDFS 集群由一个Namenode 和一定数目的 Datanodes 所组成,[3]采用单独写,多读模式。Lustre 由 OST、MDS 和客户端通过高速网络构成,多客户段并发进行大文件读写访问,写得性能要优于读的性能。[4]Parastor 并行存储系统支持 POSIX、RESTful、HDFS、NFS/CIFS/FTP多种网络协议访问接口,并支持 1GbE/10GbE/40Gb IB/56Gb IB/100Gb IB 等多种数据网络模块,且支持RDMA 高速网络协议。支持多副本或者 N+M:b 纠删码数据保护模式,允许系统中任意一台索引控制器或者数据控制器、任意两块硬盘失效而存储系统正常提供存储服务,并且实际存储空间利用率达 80%。[5]Parastor 不仅满足多客户端对大文件进行读写,也满足海量小文件的应用场景。其较之开源 HDFS,空间利用率高,性能优越,冗余度高。
1.3 Slurm 系统调度层
Slurm (Simple Linux Utility For Resource Management)最初是由 Lawrence Livermore National Laboratory 于 2002年为方便 Linux 集群管理和系统具有良好的可扩张性而开发的资源管理器,并于 2013到 2014年,逐步形成现在的 Slurm。Slurm 是一个高度可扩展的,支持现代多线程多核调度的资源调度器,其高度可定义热插拔模块能够无缝对接于各类工作流,网络体系结构,排队策略以及调度策略。为了尽可能降低从其他调度器转变过来的习惯,Slurm 也人性化地提供了相关的转变接口。成熟的 Slurm 已广泛应用于全球超级计算机,天河 2 号 310 万核以及通过模拟技术更大的系统已经成功运用 Slurm 进行管理[6]。

表1 三款调度器功能对比Table 1 Comparison of three schedulers

表2 Singularity Shifter Docker 之间比较Table 2 Comparison of singularity shifter and docker
一款优秀的软件不仅需要在核心代码上拥有安全可靠、高效成熟的特点,周边产品的集成也是一个重要的参考标准。Slurm 拥有高度可配置化的插件,支持 26 类 100 多款插件:认证插件 (Munge),MPI 插件(pmi2),网络拓扑插件 (tree),记录存储插件 (MySQL)等。丰富的插件和社区,使得 Slurm 变得较其他调度软件拥有更多的易用性和功能性,对于调度器的扩展也更加的便捷。表一比较了三款调度器的功能[7]。
从调度器功能角度上来说,Slurm 具备传统 HPC调度器所该拥有的一切功能,并且对现代的计算机体系结构也支持的较为充分,其卓越的表现已经赢得广大超级计算机的爱好。从性能上来说,Slurm 比大数据 hadoop 中的 YARN 要表现优异。[8]
1.4 Singularity 容器
在过去的十多年里,虚拟化技术已经从某些工程师自我爱好逐步转变成全球化的工业化的基础需求。Singularity 作为容器将各类开发环境包裹在 容器当中,如此,对于工程师、科学家这类人可以将自己开发或所需要的软件环境装载于 Singularity 之中,一次构建,多次多平台无缝对接使用,提高了工程人员和科研人员的工作效率,使得他们能够专注于更加核心更加重要的问题本质的研究,而不过多被边角琐碎事情烦恼;对于系统管理员来说亦是生产大解放,如今各类软件如雨后春笋般踊跃出来,各个用户需求可能有不尽相同,统一安装所有软件,不现实也没有必要,可能同一款软件,A 用户使用 1.0 版本,而B 用户使用 1.2 版本,也可能 A 软件编译依赖版本库0.5,而 B 软件编译依赖版本库 0.8。Singlularity 作为一个环境的封装,能够较完美地用户和系统管理员双方的需求。
Singularity 本身为 HPC 而设计开发的容器,天然支持高性能计算中的关键技术例如 InfiniBand 和Lustre,无缝对接于所有的高性能资源管理器,例如Slurm,Torque,SGE。特别地,Singularity 能够集成为 Slurm 当中的一个插件,如此能够使得 Slurm jobs天然运行到 Singularity 的容器中。容器 Singularity、Shifter 和 Docker 对比见表二[9]:
2 平台深度学习性能试验
深度学习计算平台[10–11]需要在大数据集上进行密集型计算,因此首先对海量数据的读写带宽要求较高,才能控制各个深度学习业务模型在训练过程中的网络延迟。本平台使用了 Parastor 的 Infiniband 的组网方式,保障了数据传输速率。
平台拥有 48 个节点,每个节点上 8 块 Tesla P100 gpu,基于 Slurm 的调度器,平台已实现至动态分配到卡数级别的调度,能够满足各类深度学习调度上的需求。
深度学习平台对各类深度学习框架支持和扩展度都非常优异,目前主流的深度学习框架均已经支持,例如:TensorFlow、Caffe、Mxnet、Pytourch 等。为了兼顾各个版本的需求以及用户自定义的深度学习框架,平台提供了容器级别的虚拟化条件,并可以复用Docker 的容器,用户一次成功编译环境,此后再无需再进行任何改变就可以无缝对接移植到本平台上进行相关的基础实验,大大提高了实验的便捷性。
为了体现平台使用实践的代表性,本次测试选取了深度学习最为典型的框架 TensorFlow 进行了单节点上了的直接裸跑,调用 Slurm 进行动态节点分配测试,虚拟化容器中 TensorFlow 环境测试,Slurm 调度装载 TensorFlow 容器 Singularity 进行测试。单节点测试上又采用了 1,2,4,8 多块 GPU 多类别测试。图2 是测试结果表格。
单节点上的实验输出结果是每一秒中处理的图片数量,实验选取的数据集为 ImageNet 中的 2012 实验集,深度学习网络统一选取 Resnet50,训练过程中BatchSize 均采用 32。
从单节点的实验效果来看,四大组实验均达到了线性加速比,并且采用 Slurm 调度与 Singularity 的虚拟化实验,几乎未对实验效果带来性能上的损失。下图体现出各类实验效果相差无异。 (注:Python:直接登录计算节点进行测试;Slurm:Slurm 动态调度计算节点进行测试 Singularity:登录到计算节点采用 Singularity 测试,Singularity on Slurm:Slurm 调度Singularity 进行节点测试)

表3 TensorFlow 测试实验Table 3 The experiment of TensorFlow

表4 分布式 TensorFlow 测试效果Table 4 The experiment of distributed TensorFlow
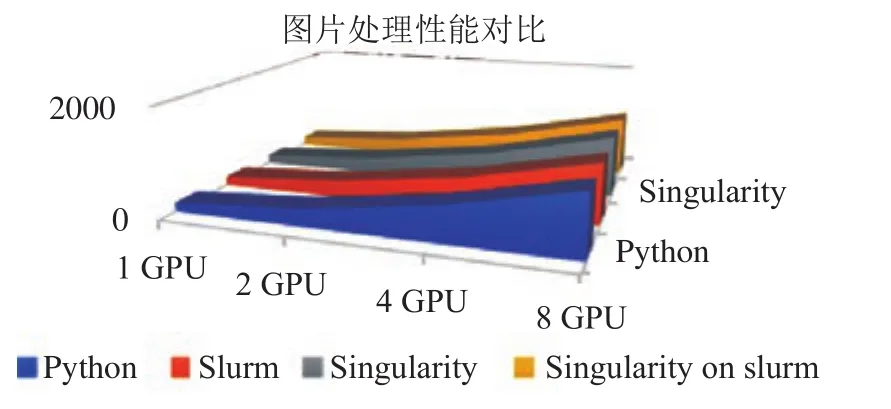
图2 四组实验性能效果Fig.2 The performance of four experiments

图3 分布式 TensorFlow 效果图Fig.3 The performance of distributed TensorFlow
8 块 GPU 已经能够满足绝大多数深度学习上的训练所需要求,为了支持超大规模模型上的训练与加速,通过编程实现添加 Slurm 调度的插件,使得分布式 TensorFlow 也无缝对接于 Slurm 的动态调度之上。表4 展示了从 1 到 4 个节点的分布式 TensorFlow 的性能测试。
从测试的处理性能结果来观看,8 块 gpu 到 64块 GPU 上的扩展基本也达到了线性加速比的效果。体现了平台的优秀的可扩展的特性。具体效果图 3。
3 结语
本文设计了基于 Slurm 的深度学习高性能计算平台,从实验效果上来看,实现了从单节点到跨节点的GPU 线性加速比,出色的完成了深度学习所需的计算性能要求。平台计算资源的动态分配,较好的满足了多个用户的同时便捷使用的目的。主流框架的无缝对接支持,多个版本虚拟化容器的共存,实现了用户广泛自定义的需求以及优良的可移植性的效果。整个平台采用了传统高性能体系架构,完美融合了当今最为火热的深度学习技术,产生了良好的应用价值
