物流与信息服务产业的聚集关联及优势匹配
——基于云南的实证
2018-09-03廖望科陈春艳焦晓松
廖望科,陈春艳 ,焦晓松
(1.大理大学经济研究所,云南大理 671003;2.大理大学经济与管理学院,云南大理 671003)
一、研究背景与意义
物流会带来信息流,而信息流又会驱动物流,两者既可相互促进、也可相互制约。作为现代服务业中的基础性产业,物流业与信息服务业正发展成为我国国民经济新的增长点和未来重点发展的领域,而物流业信息化正是这一发展的主题。
在经济实践方面,物流信息平台在全国近600个已完工和在建的物流园区中进行了部署,经常使用平台服务的物流企业占整体企业的50%左右。我国物流业的信息化水平持续提升,物流信息平台建设步伐加快,2010年,我国物流供应链信息化解决方案市场整体规模达到10亿元,并以平均45%的速度增长。2013年前半年,全国电子商务交易额就达到4.35万亿元,直接从事于电子商务服务行业的人员总数超过220万人,间接带动的就业人数超过1 600万人。
在政府政策方面,“十一五”规划期间国家就出台了《物流业调整和振兴规划》(国发〔2009〕8号),明确提出了以信息化为中心,推动现代物流业的升级改造,以信息服务延伸现代物流业的增加值,以信息化促使物流业走向高端服务业。“十二五”期间出台的《关于推进物流信息化工作的指导意见》(工信部信〔2013〕7号),明确了以信息技术服务、通信、现代物流及电子商务为切入点,加强试点示范,选择有条件的地区、行业和领域先行先试。
物流业信息化的市场力量与国家产业战略的政策要求对各级地方政府如何选择所谓“有条件的地区、行业和领域”推动物流业信息化提出了决策挑战。区域物流服务与信息服务的互动关系,尤其是产业关联与优势匹配现状成为地方政府决策所需的关键基础信息。在国家“一带一路”倡议下,对作为我国面向南亚、东南亚的物流通道和基地、信息平台和窗口的云南省而言,掌握这一现实发展情况显得极其重要。因此,研判和测度区域物流业与信息服务业的产业关联与优势匹配现状是物流业信息化的一项基础性研究工作。但目前鲜有针对省级区域层次的研究,同时现有的测度方法也需进一步完善。本文提出了一种针对该问题的测算方法和判别步骤,并将其应用于云南的省情检验,以期对相关研究领域提供新思路和新方法。
二、文献综述与研究路径
(一)专业化、产业聚集与比较优势
准确描述区域专业化、产业聚集与地区比较优势的理论和实证关系是一个尚有争议的问题。首先,大多数观点认为,产业的地区专业化程度就代表了产业聚集程度,例如Delgado等〔1〕对美国产业聚集与产业集群的实证研究。Liang和Xu〔2〕在对我国产业专业化和比较优势动态的研究中,把产业聚集与专业化视为一体两面:聚集是现象、专业化是其测度。他们采用基于产业增加值加权比例的Krugman专业化指数方法(LQ方法的一种形式)来对产业聚集进行刻画,并把特定产业的区域聚集看作比较优势的表现。针对云南省的区域产业,廖望科等〔3-4〕采用区位商与多重分析的方法已经进行过尝试。
其次,产业的区域聚集大体上可以分为某个单一产业聚集、紧密相关产业聚集、关联产业集群聚集三种层次,产业的产值、增加值、贸易量、企业数量、就业人数等数据可以作为其测度的指标,其方法又有产业区位商(Location Quotient,LQ)〔5〕、专业化Gini系数〔6-8〕、区域产业聚集指数〔9〕、Theil指数或更一般的广义熵GE(α)指数〔10〕,等等。Krugman指出,区位商是能同时捕捉上述各种区域聚集外部性的最佳量化测度〔11〕54-68。此外,Porter〔12〕在综合考虑要素市场均衡、劳动力成本差异、地区价格差异、通货膨胀以及数据可得性与统计准确性等各种因素后,将现有企业数量、就业量视为最为合适的两个区位商指标。其思想是:在劳动力与商品自由流动的市场经济与自由贸易条件下,区域产业的就业量就已经包含了企业和个人在微观层次对政府政策、资源禀赋、市场条件、价格因素、生产率、贸易成本、边际报酬、外部经济性等各种区域经济条件进行综合权衡决策后的劳动力宏观供求均衡,它不仅涵盖,而且超越了增加值、产出值、企业数量等指标所包含的区位优势信息。樊福卓〔13〕进一步拓展了这一思想,并对其实证应用提出了建议。
最后,针对产业聚集与比较优势二者的关系存在三种观点:源自Ohlin〔14〕的资源禀赋理论认为比较优势代表着地区禀赋差异,它驱动着区域专业化和产业聚集,比较优势和产业聚集为因果关系;Krugman的新贸易理论认为,区域规模经济的外部性所带来的企业报酬递增和市场竞争力提升吸引着产业聚集,同时催生了地区比较优势,因而产业聚集的现象与比较优势的性质是一体两面,二者共同推动了地区专业化的形成与演化〔11〕36-53;衍生于Marshall〔15〕的外部经济性理论把区域产业聚集视为给定,认为聚集的溢出效益产生比较优势,从而影响地区专业化形态,此时产业聚集为因,比较优势为果。
(二)物流服务与信息服务产业的关系
早在1990年代互联网技术为代表的信息产业飞速发展初期,国外学者就意识到了物流与信息流互动的前景和挑战〔16〕。随着信息技术和信息产业的壮大、贸易全球化的进程,近年来信息与物流的关系也渐受重视。Lai等〔17〕从对香港物流企业信息化需求的问卷研究中意识到物流业对信息业本地化的推动作用;而Aoyama等〔18〕反过来考察信息化电子商务的发展对物流业组织重构的影响;Aoyama和Ratick〔19〕的实证研究更进一步指出,尽管信息技术被物流企业日益广泛地采用并深刻改变着物流组织形式,但美国物流业的区域专业化分布和物流企业的地理聚集并未受到冲击,表现出惊人的稳定性。尽管国内学者如杨申燕和胡斌〔20〕、刘艳〔21〕及陈翠萍等〔22〕分别从物流信息服务产品定价、物流信息服务系统构建及物流园区信息服务平台等方面定性描述了物流业对信息服务业的全面发展需求,但物流及信息服务产业之间的互动机理如何仍有疑问。
尽管物流业信息化成为物流产业升级的主题,但当前国内学术期刊中对物流与信息服务之间产业关联这一关键问题的理论探讨较多,而实证研究较少,区域层次的定量研究更少。王静〔23〕定性论述了两个产业的可能关联方式、当前问题和发展建议;王发曾和王新涛〔24〕论述性地指出了物流、信息流的不整合是我国当前城市群发展的一个重大瓶颈,并提出了全局性的政策建议;Lin〔25〕对北京、上海、深圳三地物流企业的问卷调查证实了国内企业在市场竞争压力下强烈的信息化愿望和投入;郑燕飞和徐伟〔26〕的研究是目前基于全国数据少见的定量分析文献之一,但并无对两个产业的关联测度和区域层次分析。虽然廖望科等〔27〕探讨了一种测度区域建筑业与房地产业之间聚集关联与优势匹配的方法,并发现了相关关联与匹配的证据,而且Za⁃wawi等〔28〕和Choy等〔29〕分别从香港、珠三角、马六甲等地区案例出发,对国际加工贸易核心区和物流港口区的信息化程度与需求进行了研究,但是总的来说,如何测度和判别区域物流业与信息服务业的专业化与产业聚集关联,以及比较优势匹配仍然是一个有待深入的课题。
(三)研究设定与路径
本研究中,专业化的程度和专业化的分布形态被分别作为产业聚集的和比较优势的测度,不考虑其尚有争议的复杂互动机制,而着重于对其现状关系的量化。依照目前统计数据中产业分类目录,本文将物流服务与信息服务分别视为物流产业集群和信息产业集群,因此这里的聚集是产业集群层次的聚集,考察的是物流服务与信息服务这两个关联产业集群的区域联系。这一视角也更符合政府决策的实际需要。
本文研究思路如下:首先,以基于就业量区位商的专业化测度来刻画区域物流服务与信息服务产业各自的产业聚集分布。随后通过灰度关联分析,分别考察物流服务产业聚集随时间变化的地区自相关程度(这可以说明物流产业聚集分布是否稳定),以及物流与信息服务产业聚集分布的区域相关程度(这可以说明物流与信息产业聚集的区域关联性质)。而物流与信息产业聚集关联是否具有因果联系则通过Granger检验进行分析。综合上述研究,我们预期这一因果关系很可能是总体不确定和地区不一致的。最后,对产业专业化程度地区分布的多重比较和方差分析可以给出产业优势的地区间两两比较结果,它可以明确指向为区域产业比较优势分布。而通过对物流与信息服务产业的地区比较优势分布的关联分析,就可以给出两个产业的区域比较优势的匹配程度。这些结果都是制定相关产业规划布局和配套措施的有益信息。
三、产业聚集程度的测度样本:基于就业量的区位商
我们首先获取2003年至2011年云南省16个州市地区的物流业与信息服务业就业量区位商的样本值。考虑到我国省级统计年鉴是从2004年才开始将以前的“交通运输、仓储及邮电通讯业”拆分为“交通运输、仓储及邮政业”与“信息传输、计算机服务和软件业”两个明确指向物流服务与信息服务产业的就业统计,我们以2004年的统计年鉴(2003年数据)为起点,目前可得最新年鉴为2012年(2011年数据)。以就业量为指标的各年份产业区位商样本值计算公式为

其中Employi,r,t表示第i(i=1,…,I)产业,在第r(r=1,…,R)地区(同级别州市),于第t(t=2003,…,2011)年末的就业量。可见,LQi,r,t能够表征i(i=1,…,I)产业在r(r=1,…,R)地区的产业聚集程度的当年观测值:通常,若LQi,r,t>1,则表明i(i=1,…,I)产业在r(r=1,…,R)地区趋向具有高度聚集;若LQi,r,t<1,则表明i(i=1,…,I)产业在r(r=1,…,R)地区趋向具有低度聚集。
本文以2004年至2012年《云南统计年鉴》中16个地区(州市)分行业年末城镇单位就业人数①《云南统计年鉴》中关于各州市分行业就业量分为就业人数、职工人数、在岗职工三种指标。其中我们所采用的“就业人数”指标反映了省内全部劳动力资源在某个行业的全年利用情况,更符合本文的研究意图。作为Em⁃ployi,r,t,i=1,…,19;r=1,…,16;t=2003,…,2011。计算出2003年至2011年云南省16个地区物流与信息服务产业在云南省内的产业聚集度LQ如表1~2所示。

表2 信息服务业地区产业聚集程度LQ的样本值分布(2003年至2011年)
从表1不难看出,9年中物流服务产业的聚集分布大致稳定,但有逐步向省会集中的趋势。昆明作为省会城市,其物流专业化程度一枝独秀。而红河、文山、怒江、版纳作为边贸地区,大理作为滇西中心,迪庆作为滇藏运输中心,虽然物流业聚集超过其他州市,但总体仍处于低度聚集,无法满足辐射中心建设中物流基地、通道的要求。
从表2可以发现,9年中信息服务产业的聚集分布大致稳定,但也有地区调整。文山、版纳、大理的信息业聚集程度在不断上升,而迪庆则有大幅下降。其中,昆明、文山、怒江、版纳、大理、迪庆、楚雄目前聚集程度较高,直观看来,这与物流业的聚集分布有一定对应,但具体关联测度有待量化分析。
四、物流业与信息服务业的产业聚集关联:灰度关联分析
耦合协调度模型、多元统计分析、主成分分析和灰色关联模型等是测度产业聚集关联度的主要方法。其中,灰色关联模型〔30〕特别适用于小样本空间、样本信息不确切、不全面,具有灰色性的研究对象。它根据因素之间发展态势的相似或相异程度来衡量各因素间关联的程度从而揭示事物动态关联的特征和程度。国内学者已经将其广泛用于全国某一产业或省级各个产业之间的关联性研究中。如黄雯和程大中〔31〕对省级服务业地区专业化分布的研究;王珍珍和陈功玉〔32〕对我国制造业与物流业联动因素的研究;姚瑶〔33〕对我国房地产行业与国民经济其他行业关系的研究;等等。但现有文献对产业聚集和专业化程度的关联度关注较少。基于物流产业聚集和信息产业聚集之间的相互作用存在着大量的随机性和不确定性的特征而产业聚集的关系又在不断变化的这一事实,更考虑到每个地区仅有9年的小样本数据,因而采用灰色关联模型对物流业与信息服务业的区域聚集关联度进行测算成为最佳选择。步骤如下:
1)确定参考序列和比较序列:其中因变量参考数据列也称为母序列,这里是物流业的地区年度LQ序列自变量比较数列也称为子序列,这里是信息服务业的LQ序列其中T=9(2003-2011年)、R=16(16个地区),上标L、I分别代表物流业与信息业,下标i、j为不同地区。
2)序列无量纲化处理:采用极差标准化的方法对数据进行无量纲化处理转换为可比较的数据序列。对本文问题,区位商LQ本身已经是产业就业比例的比值,无需再做无量纲化。
3)产生对应差数列表:即将标准化后的比较数列与参考数列进行差值计算,并求绝对值。对应差数列表内容包括:与参考数列值差(绝对值每列最大差列最小差
5)计算关联度:对于不同i地区,将其关联系数求平均值可以得到一个关联度γij。如果LQ的上标L或I一致,t不变,i≠j,它测度的就是某个年份同一产业在不同地区间的聚集关联度;如果LQ的上标一致,i=j,t改变,它测度的就是各个地区同一产业在不同年度的聚集自关联度;如果LQ的上标分别为L、I,t改变,i=j,它测度的就是各个地区两个产业之间在不同年度的聚集关联度;我们这里测算的是上述第二、三种情况。关联度γij的计算公式为在计算同一地区同一产业年度自关联时,N=R=16(16个地区);在计算同一地区两个产业间的关联度时,N=T=9(9个年份)。
6)关联度的判断:不难看出,0≤γij≤1;γij越接近于1,说明关联性越大,反之亦然。一般认为,0≤γij≤0.35时,两者为弱度关联;当0.35<γij≤0.65时,两者为中度关联;当0.65<γij≤0.85时,两者为较强关联;当0.85<γij≤1时,两者为极强关联。
表3给出了云南省所有地区两个年度之间的物流业聚集度的自我关联系数与总体关联度,表4给出了以物流产业聚集为参考序列、信息产业聚集为比较序列的产业聚集关联度。

表3 物流服务产业聚集分布的年度自关联系数及关联度(ρ=0.5)

表4 物流与信息服务产业聚集分布的年度关联系数与地区关联度(ρ=0.5)
表3展现出整个云南地区专业化的分布具有相当的稳定性,体现为LQ的地区分布在所有年度之间关联度基本大于0.65、但小于0.85,属于较强关联,说明产业聚集的分布相对稳定,但也有动态调整。
从表4的结果可得:①普洱显现出极强的物流业与信息业关联性(γij>0.85);②昆明、迪庆、德宏、楚雄、保山、版纳、曲靖、文山、怒江等9个地区显示出较强的关联性(0.65<γij< 0.85),其中德宏、保山、版纳、文山、怒江等州市恰好都是国家或省级沿边开放城市及物流业重点发展城市;③丽江、大理、昭通、红河、临沧、玉溪等6州市仅为中度关联(0.35 < γij< 0.65);④昆明、迪庆、版纳、文山、怒江体现为两个产业高度聚集下的高度关联,而德宏、楚雄、保山、曲靖等体现为两个产业低度聚集下的高度关联。也就是说,云南全省2∕3的地区呈现出物流与信息服务产业聚集的高度关联,其余1∕3为中度关联。不过,这些关联的因果性尚待确认。
五、产业聚集关联的Granger因果性检验
经济因素和地区禀赋条件会影响区域产业聚集的动态变化,因为检验物流业与信息业产业聚集的地区分布时间序列是否具有因果关联,需要首先进行平稳性检验。但是,时间序列平稳性检验所要求的自由度大于这里的9年样本。因此在后续计量检验中,一方面我们适度放宽了显著性要求(10%),另一方面我们对其结果持观察存疑的态度。表5是基于表1、2的LQ序列、最大1期滞后、2次差分、无截距项及趋势项的ADF平稳性检验结果。显然,2次差分后,几乎所有地区的LQ序列都呈现平稳。
序列的平稳性保证了进行Granger因果性检验的可能性。表6给出了云南省16个地区物流业与信息业产业聚集的Granger检验F统计量,P值和检验结果。

表5 物流与信息服务业地区专业化强度的ADF平稳性检验(10%显著性水平)
不出我们的预期,由于时间序列相对较短,很难从计量分析中给出明确的产业聚集因果联系和方向,表6中大部分地区的情况如此。通过对我国目前各类年鉴和统计数据的比照,考虑到这几乎是唯一可得的省级以下地区产业聚集测度,仍然值得一试。而且,正如已有研究所指出的,这种因果关系因为地区禀赋的差异,可能是存在两个方向:物流业的聚集催生本地化的信息化需求和信息业聚集,而本地信息业的聚集使得物流企业更能从中收益而更快成长、推动本地物流业聚集。在10%显著性水平上,保山地区的结果证实了第一种情况,而曲靖证实了第二种。

表6 物流与信息服务业地区产业聚集的Granger因果性检验(10%显著性水平)
六、信息服务业与区域物流的比较优势匹配
尽管两个产业之间区域聚集的因果关系以及单个产业聚集与比较优势之间的因果关系都尚不明确,但是两个产业聚集的高度关联仍然提示我们,考察产业之间地区比较优势的匹配是否对应着产业聚集的关联将是政策的重要参考。政府决策者也期望从地区之间的两两比较和产业配套的角度中选择稀缺产业资源的政策配置方向。
为此,我们首先需要确定每个产业的比较优势分布。按照作者之前的工作〔34-35〕,对任意两个地区之间的产业比较优势分析需采用Tukey、LSD、Bonferroni、Scheffe、Dunnet、Student-Newman-Keuls等多重比较方法。由于进行比较的个体(即各个州市)是完全对等关系的情况①严格地说,昆明市是副省级省会城市,与其他州市地位并不完全对等。但对于我们所研究的问题,云南的现实是省会城市的地位有区位因素影响,但并未对其带来政策、资源等特殊影响。,且样本量相等,故适宜采用Tukey②Tukey检验方法:设r个因素水平下均有m个独立观测值,对于假设“H0:μi=μj,i≠j,i,j=1,…,r;H1:H0不成立”的检验问题,我们需要计算Tukey统计量其中为)t极差化统计量其分布可由随机模拟法得到,进而可得其a分位数qa(r,n-r);若|i-j |> Ta,则认为 μi与μj之间的差异显著,否则认为两者无显著差异。方法对表1中的样本数据进行多重比较〔36〕,其原假设与备择假设分别为“两地区不存在差异性”和“两地区存在差异性”,即假设物流业16个地区多重比较结果如图1所示、信息业如图2所示。


图1 16个地区物流产业聚集的多重分析比较结果
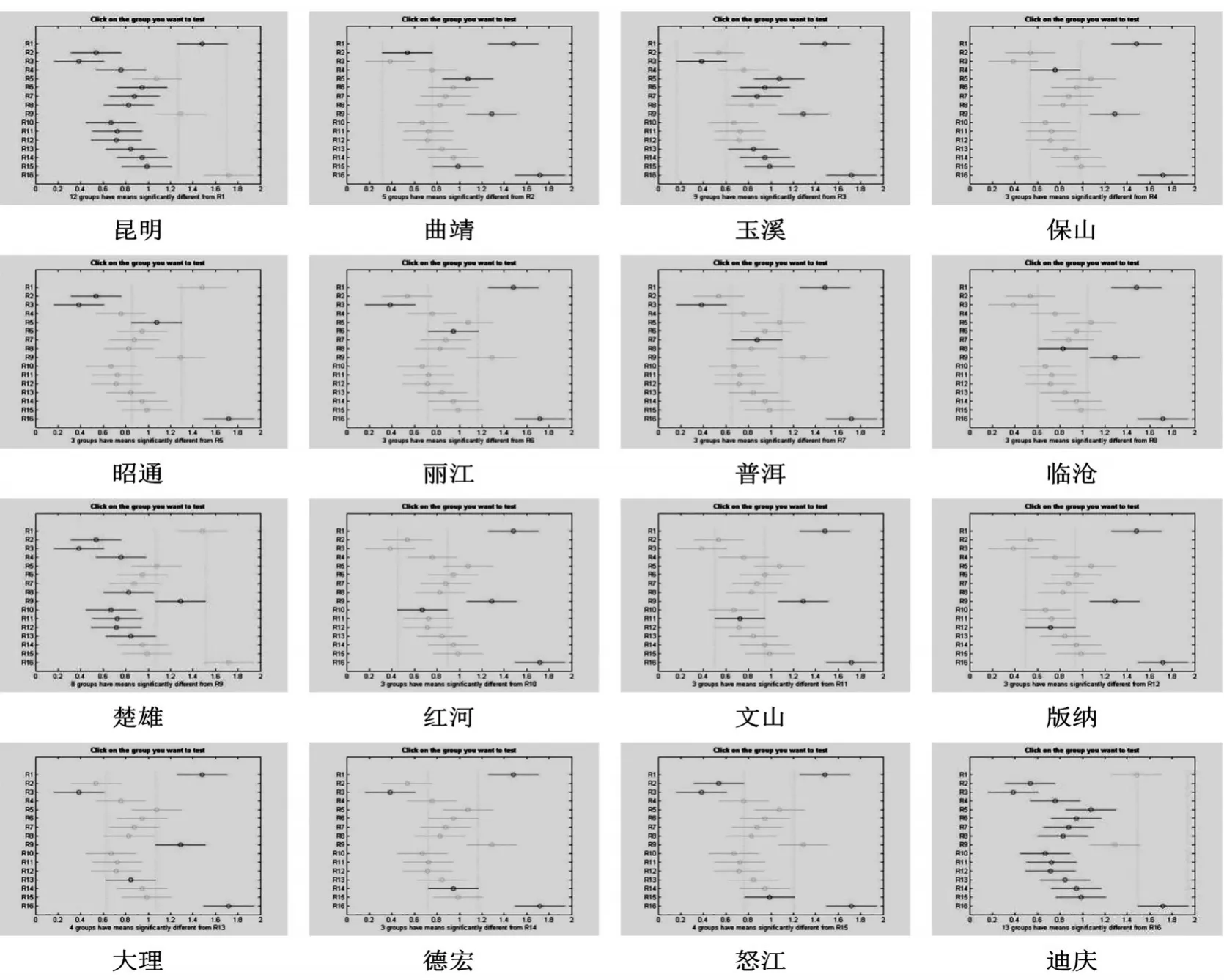
图2 16个地区信息产业聚集的多重分析比较结果
采用Searle等〔37〕对偏差均值的分析方法,我们对两两地区间专业化程度偏差均值也进行了95%区间估计(结果略)。结合云南省的5大经济区域及其产业规划布局,通过图1和图2的多重比较及偏差均值分析结果即可比较出任意两地区间的物流业和信息业比较优势相对强弱,如表7、8所示。可见假设成立,即虽然整体存在显著的地区差异,但两地区间的比较优势既存在显著强弱的情形,也存在无显著差异的情形。

表7 云南省物流业的地区比较优势分布:基于多重比较与均值偏差的专业化强度两两比较

表8 云南省信息业的地区比较优势分布:基于多重比较与均值偏差的专业化强度两两比较
不难看出,表7和表8都是逆对称的,两两强弱对比的事实也应当如此。横向看,一个地区“●”的个数越多,该地区比较优势越强,“○”越多则比较优势越弱。
从表7、8的结果反映了物流与信息两个产业各自比较优势分布的现实,并且与产业聚集程度并非一一对应,同时也揭示出一些值得注意的问题:①两两地区间专业化强度的对比给出了实际经济意义上的地区产业比较优势强弱,物流业比较优势最高的是昆明市(15个,高于其他15个州市),其次分别是大理、临沧、文山(分别为5个),再次是怒江、昭通(分别为3个),最后是丽江、红河、迪庆(分别为2个),其他州市相互之间几乎没有什么物流业比较优势、或者处于比较弱势;②信息业比较优势最高的是迪庆(13个,高于其他15个州市),其次是昆明(12个),楚雄(8个),再次是怒江、昭通(分别为2个),最后是丽江、大理、德宏、普洱(分别为1个),其他州市相互之间几乎没有什么信息业比较优势、或者处于比较弱势;③两个产业比较优势分布略有差异:物流业优势地区集中在昆明(滇中)、大理(滇西)和西南沿边各地区,信息业优势地区集中在滇中和西北沿边各地区。这从另一个侧面说明,产业区域聚集与地区比较优势之间有联系,但也有差异。
我们可以通过简单的灰度关联计算来直观测度物流与信息产业的比较优势匹配程度:每个比较优势以3分计、比较均势以2分计、比较弱势以1分计,得到各个地区两个产业的比较优势积分;比较优势的匹配以积分的关联度计算。结果如表9,关联度为0.732 1,属于较强关联。其他算法的结果基本一致,可见物流业与信息业的地区比较优势也呈现出显著的一致性,并且与前面产业聚集关联分析所反映的信息基本一致,证明了比较优势的匹配对应于产业聚集的关联。因此,任何旨在推动区域物流业信息化的政策措施必须着眼于提高关联产业区域聚集的经济规律。

表9 云南省物流业与信息业地区比较优势匹配程度
七、总结与启示
我国当前各个地区的物流业和信息业仍然存在严重脱节的情况,两个产业无论从业人员素质结构、具体服务的行业类型等方面都存在互动缺乏的现状,仅仅在商业和个人网购等领域有所互动匹配。许多物流业经营实体仍然是以家庭为主、2~3台车辆、少数非正式雇工的形式,物流需求的信息交流主要是以个体中介、亲友联系、老客户网络等低端形式,不少地方物流信息发布甚至仍以黑板粉笔的形式。全国物流车辆的平均返程空载率达到50%以上,推高了物流成本、导致超重超载。
本文试图以国家定位于面向南亚、东南亚物流基地和信息窗口的云南省为实证案例,通过实证分析考察其地区物流服务与信息服务的产业关联及其优势匹配的现状,对我国地区物流业信息化的升级路径提供若干基础信息。首先,我们以就业区位商为指标,通过灰度关联分析确认了物流与信息服务产业区域聚集分布的高度关联。这一发现为制定物流业信息化政策提供了实证基础。而对物流与信息产业聚集关联的Granger因果检验分析进一步验证了这一关联的总体不确定和地区不一致性。此外,采用多重比较和方差分析给出的物流与信息产业地区比较优势分布结果,运用灰度关联分析,我们证明了比较优势匹配与产业聚集关联的一致性。研究结果说明,两个产业的聚集与匹配存在着由市场力量、而非政策因素所驱动的内在联系,任何旨在推动区域物流业信息化的政策措施必须着眼于提高关联产业区域聚集的经济规律。这些结果都是制定相关产业规划布局和配套措施的有益信息。
本研究在以下几方面值得改进和拓展:第一,因为数据可得性的限制,本文实证分析中时间序列数据并不完整,在更长的尺度上结论的信度会更高;第二,在产业聚集分析中,需要依关注的产业和地区不同而对具体测度指标和统计分析方法的选取作相应调整;第三,这里的研究是政府决策之前的必要参考,但物流与信息产业聚集和比较优势的动态变迁是值得关注的研究方向。因为决策实施之后,由于政策效应作用和经济结构变迁,在较长的时间尺度上,各个地区的产业聚集和比较优势几乎可以肯定会存在趋势变化,此时新的计量分析是必要的。
