基于SPSS多元线性回归模型在城市用水量的预测
2018-08-31周鹏飞卢泽雨
周鹏飞,卢泽雨
(河北工程大学 水利水电学院,河北 邯郸 056000)
0 引 言
随着我国人口持续增长、经济飞速发展、人民生活水平不断提高,城市工业和生活用水量增加,使得城市水资源量的供需矛盾加剧。城市用水量预测是城市给水系统规划设计和优化运行的重要基础,直接影响到城市的规划、城市的可持续发展和区域水资源优化配置等。因此,准确预测城市用水量的需求对城市发展有着极其重要的作用。一般来说,城市用水量采用综合指标法、平均增长率法等经验类推可以取得较好的研究结果。但在城市的发展过程中,由于城市用水量受人类活动影响较大,其市场数据存在不规则的变化,采用历史数据类推达不到理想的效果。因此,目前城市用水量预测常用的方法有定额预测法、回归分析法、灰色预测法等[1]
本文采用多元线性回归中的逐步回归分析法,利用SPSS软件进行多元回归分析,建立城市用水量预测模型。多元线性回归不仅要对回归系数进行检验,还需要对预测以及假设性检验方面进行讨论与研究,考虑各个自变量之间的相互关系,检验是否存在共线性问题。如果存在共线问题,需要对变量进行筛选,为了克服共线问题,增加预测的精确度。所以,本文采用多元线性逐步回归分析法。
1 多元回归分析原理及SPSS介绍
1.1 多元回归分析数学原理[2]
在现实生活中,要对某个因变量进行统计分析时,由于影响该因变量的自变量往往不止1个。需要考虑k个自变量X1、X2、X3……、XK与因变量y之间的关系时,建立回归方程:
yi=b0+b1xi1+b2xi2+…+bkxik+ui
(1)
式中:b0、b1、…、bk为待估的回归系数;i=1,2,…,n(n是样本容量);ui为随机误差。
假设随机误差总体分布N(0,σ2)分布且相互独立,就可在X、Y的观测样本下以最小二乘法来估计b0、b1、…、bk,该回归方程可以写成矩阵形式:
矩阵表示的多元线性回归模型为:
Y=XB+u
(2)
式中:Y为观测值的向量;B为参数向量;X为常数向量;u为随机误差向量。
采用最小二乘法估计总体参数,其估计量为B=(b0,b1,…,bk)T,总体参数的最小二乘估计量:
BLS=(XTX)-1XTY
(3)
回归方程的显著性检验用统计量F检验,记:
(4)
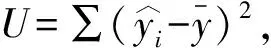
回归系数的显著检验用统计量t来检验,记:
(5)
式中:bj为最小二乘估计;S(bj)为样本估计量。
1.2 SPSS介绍
SPSS是目前世界上最流行的统计软件之一,被广泛用于社会科学和自然科学的各个领域。SPSS的基本功能包括数据管理、统计分析、图表分析和输出管理,其基本功能主要包含有描述性统计、相关分析、回归分析、聚类分析、时间序列分析等十几大类,具有操作简单、操作方便、功能强大、数据接口全面、功能模块组合灵活、针对性强的特点[3]。
2 城市用水量SPSS回归分析及结果检验
影响城市用水量的因素有很多,根据2005~2014年邯郸市统计年鉴资料和2005~2014邯郸市《水资源公报》,选取7个影响城市用水量的因素,见表1。其中,X1为GDP(万元),X2为人均GDP(元),X3为固定资产投资(万元),X4为工业个数,X5为城市总人口(万人),X6为工业用水量(104m3/a),X7为人均日常生活用水量(L),Y为总用水量(104m3/a),建立数学模型,对邯郸市的城市用水量进行预测[4]。
2.1 逐步回归分析的基本思路
在实际问题中,人们总是希望选择一些对Y有显著影响的变量作为自变量,应用多元回归分析的方法,建立“最优”的回归方程,以便对因变量进行预测和分析。逐步回归分析就是依据这种原则提出来的一种回归分析方法。它的基本思路是建立多元线性回归方程时,这些因子的挑选是逐步进行的,即每进行一步挑选一个因子。首先,计算m个因子的方差贡献,挑选其中未引进因子中方差最大者给定信度α下的F检验(即引进检验)。若通过检验,则引进该因子;如果没有通过检验,则不引进该因子。引进2个因子后,在计算m个因子的方差贡献,挑选其中引进因子中方差贡献最小者进行给定信度α下的F检验(即剔除检验),若通过该检验则剔除该因子,否则不剔除。最后,直至回归方程中既不能引进也不能剔除因子或者可供挑选的因子均通过引进检验而全部被引进时,逐步回归结束[5]。
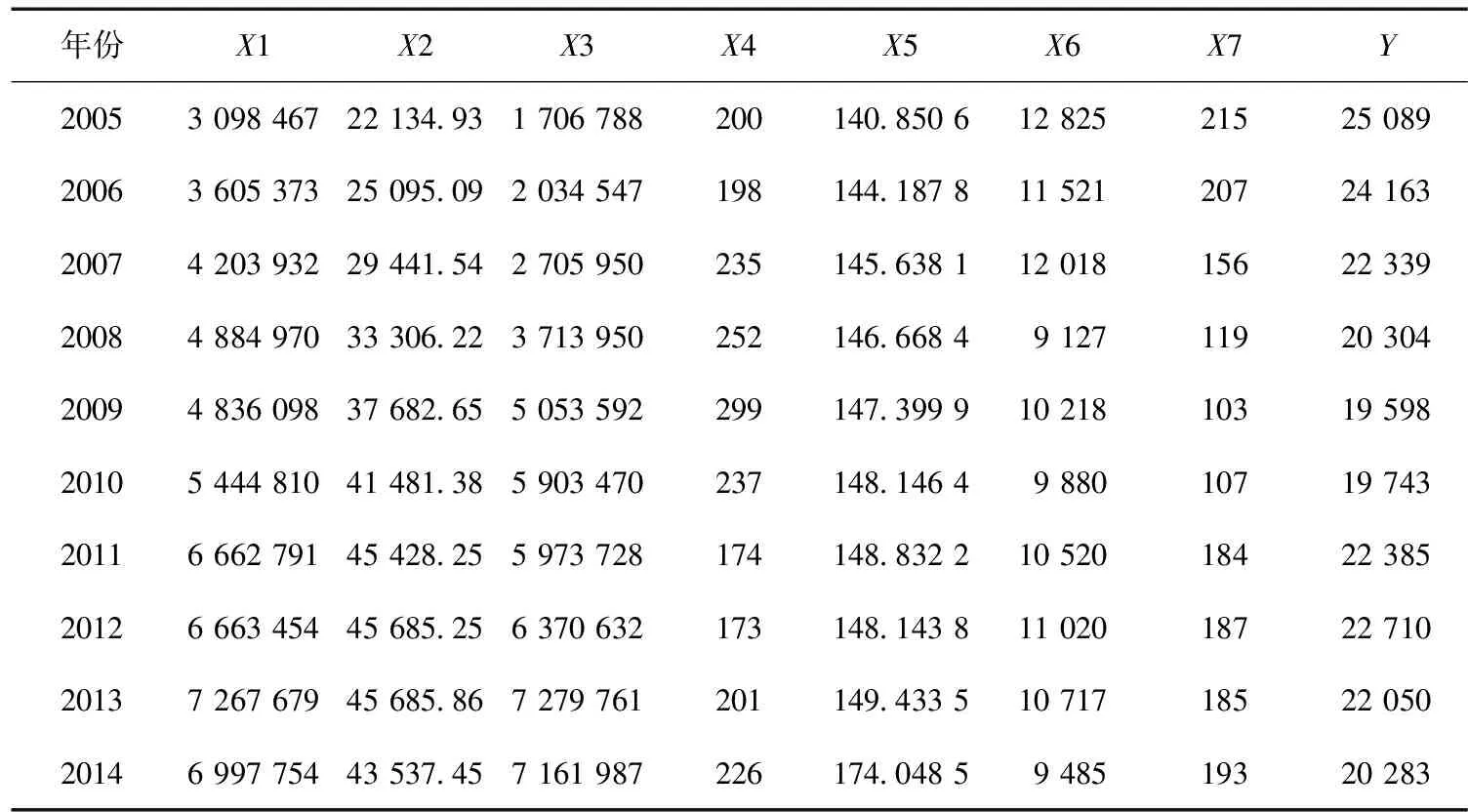
表1 城市用水量及其影响因素的基本资料Table 1 Urban water consumption and its influencing factors
2.2 SPSS多元回归具体的实现过程[6]
SPSS具体操作过程如下:打开SPSS文件窗口,录入表1中数据。在SPSS菜单上选择“分析→回归→线性”,则出现“线性回归”主对话框,将Y选入“因变量”,将X1到XK选入到“自变量”中;在统计量对话框中选择“估计”、“模型拟合度”和“部分相关和偏相关性”,点击“继续”;在“保存”对话框中选择“未标准化”,点击“继续”;在“方法”框中选择“逐步”,然后完成以上操作步骤后,点击OK。
2.3 SPSS分析[6]
将数据输入到SPSS Data Editor 中,对数据进行多元线性回归分析,软件会自动在数据编辑窗口中保存数据和计算结果。结果见表2~表4。

表2 模型汇总Table 2 Model Summary
注:模型1预测自变量为X6;模型2预测自变量为X6、X7;模型3预测自变量为X6、X7、X5;模型4预测自变量为X6、X7、X5、X3;模型5预测自变量为X6、X7、X5、X3、X4。
表2是各步模型汇总的情况。从表2中可以看出,多元线性逐步回归分析模型的相关系数R为1.000>0.999>0.994>0.951>0.865,说明第五步的自变量与因变量之间的相关性较好;决定系数R2反映总体回归效果,决定系数R2=0.999。以上结果表明,第五步的多元线性回归方程的拟合度较好,即所选的因变量Y与所选的5个自变量(X6、X7、X5、X3、X4)之间存在非常密切的线性相关性。

表3 方差分析Table3 Analysis of variance
注:预测自变量为X6、X7、X5、X3、X4;因变量为y;相伴概率中文采用ρ,而表中采用Sig.
表3是第五步模型的方差分析表。第五步F值最大,具体显示为对因变量Y有显著影响的变量分别为工业用水量、人均日常生活用水量、城市总人口、固定资产投资和工业个数。该模型的回归平方和U=31 373 903.44,残差平方和Q=25 000.964,离差平方和Syy=31 499 904.4,其对应的自由度分别为5、4、9。当统计量F=1 007.158时,相伴概率ρ=0.000<0.001,说明回归方程通过了显著检验(F检验),表明所建立的线性回归模型具有统计学意义。

表4 回归系数及显著性检验Table 4 Regression coefficients and the test of significance
注:因变量为y;B为回归系数;相伴概率中文采用ρ,而表中采用Sig.
表4是第五步模型的回归系数。该模型常数项系数b0=26 422.704 248,回归系数为b1=0.241 547,b2=29.673 624,b3=-68.125 082,b4=-0.000 165,b5=-5.007 862。经过t检验,各项回归系数的相伴概率值ρ都小于剔除因子标准值0.1。所以,不能从回归方程中剔除,表明回归系数有统计学意义。逐步回归方程为:

(6)
2.4 多元线性回归模型的拟合误差检验
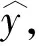

表5 多元线性回归方程的城市用水量拟合检验Table 5 Urban Water Consumption Fitting Test for Multiple Linear Regression Equations

续表5
通过SPSS软件模拟出的预测值与实际值在图形上也可以明显的看出拟合效果良好,见图1。

图1 实际值和预测值拟合效果图Figure 1 Actual value and predictive value fitting effect chart
3 结 论
1) 影响城市用水量的因素有7个,应用多元线性回归分析原理,利用SPSS软件通过逐步回归分析的方法,最终选择工业用水量、人均日常生活用水量、城市总人口、固定资产投资、工业个数5个变量建立回归模型。并对实际值和预测值进行比较,该模型预测最大的相对误差是0.378%,最小的误差为0.058%,平均误差为0.241%,说明SPSS逐步线性回归模型具有较高的精确度,拟合情况良好,可以用来预测用水量。
2) 该方法建模过程简单、结果直观、精确度高,大幅度减少了计算时间,以便于推广和应用。如果在样本足够且具有典型性和代表性时,可以得到更加精确的结果。
