临床研究统计分析思路与统计图表概述
2018-08-18谷鸿秋
谷鸿秋
近年来,无论是从国家层面的临床研究机构体系建设,还是从学术层面的临床研究经验交流来看,临床研究都得到了前所未有的重视,但也存在着短板和不足[1,2],如专职临床研究人员的匮乏、常用临床研究方法和技能的欠缺、尤其是统计分析思路与方法的欠缺。本文将围绕临床研究统计分析思路及统计图表做一概要介绍,以期为临床研究提供相关借鉴。
临床研究设计类型不同,其统计分析思路与方法也不同,因此有诸如CONSORT、STROBE、TREND以及STARD等适用于不同研究类型的报告规范[3-6]。多数临床研究项目的统计分析思路基本可归纳为一个通用策略:描述基线信息;估计效应大小;补充敏感性分析。
1 描述基线信息
临床研究论文的结果部分首先需呈现的是研究人群的基本信息。例如,多少人参与筛选?经过入选排除标准筛选后,多少人纳入研究?经过数据清理后,多少人纳入统计分析?研究人群基线特征信息如何?纳入统计分析的人群与排除的人群特征差异如何? 诸如此类信息可在研究结果的第一部分交代清楚。对于基线信息的描述,常用工具无非研究流程图和基线信息表。由于这些图表常最先出现在论文结果中,因此常被命名为“图1”、“表1”。
图1是临床研究中“图1”的一个最为简易的通用模板。“图1”将提供从最初筛选到最终纳入统计分析各阶段人数。不同研究设计类型在具体的阶段和流程上有所不同:对于临床试验,从筛选、随机化、随访、方案遵循情况等阶段进行例数统计,例如评估强化血糖控制对2型糖尿病患者血管结局的ADVANCE随机对照研究[7],强化降压对心血管病结局的SPRINT研究[8]等;对于抽样调查研究,则从各阶段的抽样人数、应答情况等方面进行描述,如PURE研究中,对心血管病患者健康生活方式的调查研究[9];对于基于已有登记注册库的研究,则从研究的亚人群、变量的缺失情况等方面筛选,例如基于GWTG数据库的ST段抬高的心梗患者的急救医疗服务使用现况的研究[10];而Meta分析中,“图1”则是对检索的文献进行剔除,Meta分析的报告规范PRISMA甚至还提供了相应流程模板[11]。如果研究人群的筛选流程较简单,可直接在正文方法学或结果部分用文字直接描述,如针对心源性急性脑缺血患者抗凝效果和时机的RAF研究[12]。相反,如果文章中图表过多,为节约版面,可将此图置于附件图中,如NEJM上诸如CHANCE、DAWN等一些著名的随机对照研究[13,14]。
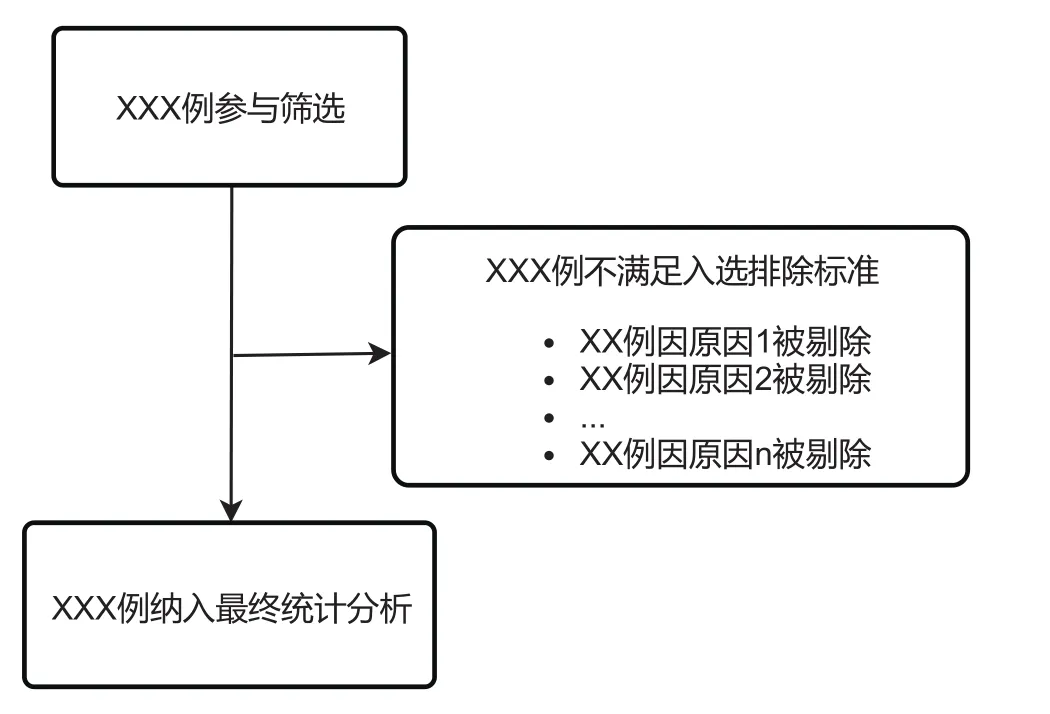
图1 临床研究常用流程图模板

表1 临床研究常用基线信息表格模板
表1给出了临床研究中“表1”的一个较为通用的模板。“表1”中,通常将各组及组间比较的P值作为单独的列项列出,而将需要描述的重要变量作为行条目列出。至于分组变量、描述变量、统计量和P值的选择,则需依据研究类型,研究目的及数据属性做综合考量。“表1”中的列,除了各分组和P值外,有时还会增加一个合并的总体列[15],或是需展示的其它统计量,如标化的组间差值[10]。弃用P值,转用标化的组间差值,常见于大样本的观察性研究[16,17]。P值评价组间差异,有两个缺陷:一是P值只给出定性结论,无法给量化差异大小;二是大样本时,P值过于敏感[18],假阳性过高。因此,在大样本的随机对照研究中[7,13,14],仅报告描述性统计量,不报告P值。“表1”中描述的变量常包含社会人口学特征、疾病史、用药史、实验室检查指标及临床特征等方面的内容。当所描述的变量过多时,可按一定逻辑层次展示,甚至拆分成多个表格[19]。若不分组描述,可将所有研究人群作为整体直接描述,如GWTG的台湾登记研究[20]。
2 估计效应大小
一篇临床研究论文旨在回答某干预措施的效果如何?某暴露因素与结局的关联强度如何? 此即效应估计。估计效应计时,结局变量的类型不同,其效应评价指标也不同。例如,连续性结局变量的效应评价指标通常为均数差;分类结局变量的效应指标略微复杂,依据研究类型,常用指标有率差、危险度比(RR)以及优势比(OR);生存结局数据的效应评价指标为生存率和风险比(HR)。无论采用哪种效应评价指标,通常都需进行两类的效应估计:粗略的效应估计;校正的效应估计。粗略的效应估计是指未经协变量校正的,单变量分析结果;而校正的效应估计则是在多因素回归模型中校正潜在的混杂变量后的效应估计。在观察性研究中,由于缺乏随机分配过程,组间可能存在大量不均衡的混杂因素,因此必需报告多因素校正的效应估计。
效应估计的统计图形可依据不同的效应指标而做不同的选择,常用的效应估计统计图形如图2所示。连续变量可用带误差限的条图(如评估阿利吉伦与氨氯地平片降压的临床试验中的Figure 3[21])、散点图与箱线图或类似图形的组合图展示(如在经皮冠状动脉介入术后,具有氯吡格雷高血小板反应性的急性冠脉综合征患者中,比较替格瑞洛和普拉格雷的血小板反应性研究的Figure 3[22]);分类变量,若效应指标是率,则可将率做成条图(如阿利吉伦与氨氯地平片降压的临床试验中的Figure 5[21]),若效应指标是OR,RR或HR,则可采用带置信区间的点图,横向或是纵向均有大量研究实例(如吸烟、戒烟对体重及肥胖的影响研究,及院外心脏骤停的发病及生存情况的时间变化趋势研究中的Figure 2[23,24]);生存数据最适合的图形当然是展示整个研究时期内生存经历的Kaplan-Meier生存曲线,这在此前提及的随机对照研究中已很常见[7,14]。

图2 临床研究常用效应估计统计图形模板

表2 临床研究常用效应估计统计表格模板
效应估计的表格可以用一个较为通用的模板展示,具体如表2所示。此表对于连续变量、分类变量以及生存数据均适用,只需依据变量类型替换相应的效应指标即可。例如,连续性结局变量的均数差(如急性缺血性卒中患者强化降压的CATIS研究中的Table 2[25]),分类结局变量的率差(如评估安定类药物是否增加老年痴呆患者死亡率研究的Table 2[26])、OR(如急性缺血卒中患者的动脉内治疗的随机对照MR CLEAN研究的Table 2[27])或RR(如SWIFT PRIME研究[28]中比较卒中患者静脉t-PA溶栓后支架取栓与单纯静脉t-PA溶栓的Table 2),以及生存数据的HR(此前提及的PLATO[29]中的Table 3和CHANCE研究[14]里的Table 2)。
除了单纯的统计图形和表格,也可将统计图表进行结合,此即用“森林图” 展示研究结果。严格来说,森林图是一种以无效线(横坐标刻度为0或1)为中心,结合了数字、文本、图形,同时展示各研究及汇总研究结果的综合图形。不过在单个研究中,森林图里并无汇总结果,展示的是各终点指标或各暴露因素相应的效应估计值。具体实例如FREEDOM[30],CHANCE[14]等研究。
3 补充敏感性分析
一篇临床研究文章在报告完基线信息和效应估计后,基本已是完整的分析结果。很多情况下,研究者们通常会进行“敏感性分析”,以获得更为稳健的结论。所谓“敏感性”是指当分析方法、统计模型、变量定义及研究假定发生变化时,研究结果和结论的稳健性[31,32]。当敏感性分析的结论与主要分析结论一致时,可提升研究结论的可信度,若不一致,则需进一步讨论,并给出合理解释。敏感性分析适用的场景非常广泛,从数据的缺失值、离群值的不同处理策略,研究结局的不同定义,到不同统计模型,以及相同统计模型里的不同层次的协变量校正,研究人群划分,亚组分析等均属于敏感性分析的范畴[32]。
敏感性分析的结果没有普遍统一的展现形式,基本上是变换不同的条件重复效应估计的步骤。例如在CHANCE研究1年随访结果中,作者依据不同的缺失值填补策略采用了三个统计模型,并依据不同亚组人群的划分,分别估计氯吡格雷+阿司匹林对比单用阿司匹林预防卒中复发的效果[33]。有时也用森林图展示,尤其是进行亚组分析的时候,森林图是最为普遍的展现方式,如此前提及的ADVANCE研究[7]中的Figure 5及CHANCE研究中[14]的Figure 2。
本文是临床研究统计分析思路与统计图表系列文章的首篇,对临床研究统计分析思路与统计图表做了一个概述。不同的临床研究设计类型,其统计分析思路与方法不同。本文并非企图提供一个完全普适的临床研究统计分析策略,而是旨在提供一种在通常情况下均可借鉴的、典型的统计分析思路,并尝试通过模板化的统计图表来体现、实现此思路。
目前传统的卫生/生物统计教学中,统计方法与临床研究实例的衔接不够,各统计方法间欠贯通,易局限于“一招一式”的教学模式中,难以形成一套简约、实用的“组合拳法”。希望借此系列文章,贯通各统计方法,并将统计方法与临床研究实例无缝对接。本系列后续文章将对基线信息的描述、效应大小的估计以及敏感性分析各部分,及其涉及的统计分析方法进行详细介绍。
