云储存海量数据的采集方法研究
2018-07-27邓文雯孙成明秦培亮
邓文雯 孙成明 秦培亮


摘 要: 针对传统数据采集方法主要通过数据特征采集,忽略采集过程对数据特征造成的影响,导致数据采集耗时长、误差大的问题,提出基于REID技术与F统计计量结合的云储存海量数据采集方法。在分析数据采集原理的基础上,对云储存的原始数据进行非线性补偿,设置参数对数据进行预处理,建立一种能够对内存进行直接访问的硬件机制,给出部分传输程序;采用聚类算法对云储存数据进行聚类,结合F统计计量进行检验所建立的判别函数的有效性,实现对云储存海量数据的采集。实验结果表明,采用改进方法进行云储存数据采集时,其采集结果相比传统方法精度及完整度均有提高,具有一定的优势。
关键词: 云储存; 海量数据采集; REID技术; F统计计量; 非线性补偿; 聚类算法
中图分类号: TN911?34; TP391 文献标识码: A 文章编号: 1004?373X(2018)14?0010?04
Research on acquisition method of cloud storage mass data
DENG Wenwen1,2, SUN Chengming3, QIN Peiliang2
(1. School of Accounting & Information Systems, Virginia Polytechnic Institute and State University, Virginia 24061, U.S.A;
2. Smart Agriculture School of Suzhou Polytechnic Institute of Agriculture, Suzhou 215008, China;
3. Agricultural College of Yangzhou University, Yangzhou 225127, China)
Abstract: In allusion to the problems of long time consumption and big error of data acquisition existing in the traditional data collection method, in which the influence of acquisition process on data features is ignored due to its data feature acquisition, a cloud storage mass data acquisition method based on the combination of REID technology and F statistical metrology is proposed. On the basis of analyzing the data acquisition principle, nonlinear compensation is conducted for the cloud storage original data, some parameters are set for data preprocessing to establish a hardware mechanism that can directly access the memory, and part of transmission programs are given. The clustering algorithm is adopted to cluster the cloud storage data, and the F statistical metrology is combined to detect the effectiveness of the established discrimination function, so as to realize the acquisition of cloud storage mass data. The experimental results show that the acquisition precision and integrity of the improved cloud storage data acquisition method are higher than those of the traditional data acquisition method.
Keywords: cloud storage; mass data acquisition; REID technology; F statistical metrology; nonlinear compensation; clustering algorithm
0 引 言
网络上的数据量随着互联网的快速发展而呈现爆炸式增长态势,也导致了数据存储成本高,存储可靠性低,大量数据管理困难等问题长期困扰企业[1]。这些困难导致许多企业开始考虑将数据存储从企业本身分离出来,交给专门的云存储服务供应商进行管理。云存储技术同时具备分步文献、网络技术、集群应用等系统功能,能够通过应用软件,将网络中的不同类型的存储设备急用运用,协调工作。其具有高可靠性、高通用性、高扩展性及大容量存储等特点,因此,其对数据采集提出更高的要求[2]。传统方法主要在各采集步骤采用以太网、TCP/IP网络通信协议,通过对标准网络协議进行改进、简化,减小采集出现延时的现象;但忽略了数据特征对采集结果造成的影响,导致采集耗时长、误差大的问题。因此,本文提出基于REID技术与F统计计量结合的云储存海量数据采集方法。
1 数据采集原理及特点
目前的云储存数据采集技术多以使用成熟且价格低廉的条码技术为基础。由于数据云储存速度快,会遇到存储环境恶劣,条形码信息受干扰容易误读、漏读的现象[3],所以多采用REID技术。数据采集原理如图1所示,存储数据的无源电子标签进入磁场后,接收读写器发出的信号,通过数据感应模块获得云储存数据在芯片中存储形式,读写器接收数据储存解码后再传输给具体的采集系统,最终实现云储存海量数据的自动采集。
2 数据预处理
海量数据采集程序中写入FIFO中的数据,包括帧头、通道数、数据,再对原始数据进行提取处理。首先将这些原始数据进行非线性补偿得到理想的云存储数据[4]。然后截取部分数据进行计算,在循环计算中加入1个计数器,当读取出1个数时,计数器数值加1,直到获取足够用的云存储数据后停止。
LabVIEW FPGA软件提供了计算相位的控件及对应的计算方法。算法的参数可以在控件内进行设置[5]。控件中的算法具备数据量大,计算快速的性能特点,因此只需把SCTL所需的数据录入到空间中,就能够计算出经过选取后的结果特征,将计算出的数据特征写入到与之对应的存储器中[6?7]。再将存储器中的数据读取出来,在对应的计算控件中的数据特征点的对应位置输入这些数据,以此为依据截取中心频率点。而附近相对的频率点写入DMAFIFO中,完成海量数据预处理过程,整体框架如图2所示。需要注意的是,数据量与通道数量必须一一对应,否则上位机无法判断解调得到的结果属于哪个通道。
3 数据传输程序
在存储层上进行的存储器与数据之间的数据传输,首先将处理过的云储存数据输入到传输层。利用数据收集应用广泛的DMA,建立一种能够对内存进行直接访问的硬件机制,借助主内存与外围设备之间的链接直接传输到储存层[8],不需要再通过处理器进行进一步处理。当使用这种机制时,与设备之间传输量会得到很大的提高。由于海量数据传输的精确度高,在单一传输层内部的不同传输通道间借助FIFO进行数据传递难度较低,但海量云存储在不同传输层之间实现数据则较为复杂[9]。在采集过程中,云储存数据的特征直接影响数据采集速率,需要在采集过程中完整地读取出数据,防止出现云储存数据丢失的情况[10],因此须采用DMAFIFO方式,部分云储存数据传输程序代码如下:
} //数据采集结束
4 云储存海量数据采集方法优化
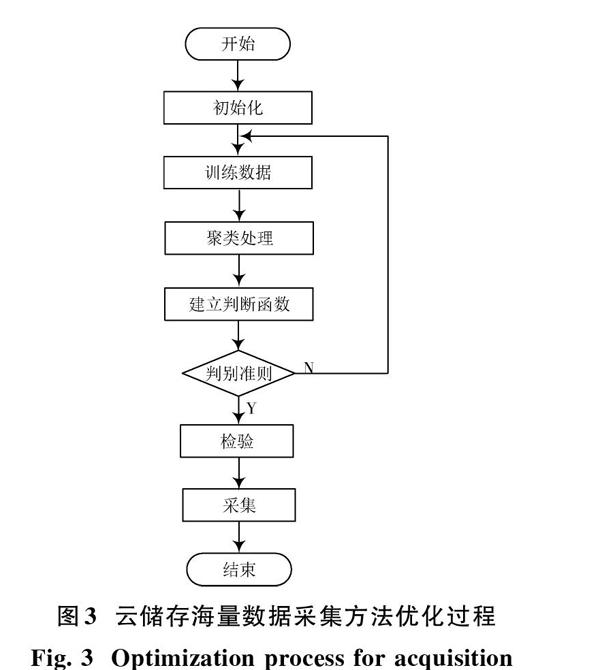
在对云储存海量数据进行预处理及传输的基础上,对其采集方法进行优化,详细步骤如下,流程图如图3所示。
1) 训练数据集。从云存储器中采集海量数据,除留下部分所需数据外,其余数据作为训练数据集参与相关的采集计算[11]。
2) 聚类算法。依据实际需要,采用k?medoids聚类算法,将训练数据聚成[k]个类。由于存储过程中会对云储存数据形成干扰,则在满足理想状态下,两个云储存数据分别为[f1=A+Bcos φ(t)],[f2=A+Bsin φ(t)]。其中,A为干扰参数,B为干扰篇频率,[φ(t)]为受干扰后的数据信息,[φ(t)=2kL(t)],[k=2π/λ1],[L(t)]为受干扰的时长。要进行聚类,得到[L(t)]只需要数据信息求得[φ(t)],提取干扰数据进行归一化得到[g1=cos φ(t)],[g2=sin φ(t)],并进行聚类,则云储存数据信息[φ(t)]为:
[φ(t)=01g1g2-g1dt] (1)
3) 依据训练数据集,及其聚类结果建立[fisher]判断函数,运用方差理论计算出判别函数。
4) 判别准则。将新测样本代入判别函数检验新样本[x]属于是否需要采集,即把具有[p]个指标的样本[x]代入判别函数,使得[λ(α)=(α′Aα)(α′Eα)]取极大值,此时对应的[yi=maxishskyh],则[x∈Gi]。假设数据受干扰时长为[L0],输入数量分别为[λ1],[λ2],要满足采集云储存海量数据的要求,云储存数据之间对应数据信息为[φ1],[φ2],则需要满足以下要求:
[φ1-φ2=4πλ2-λ1λ1λ2, L0=nπ+π2] (2)
式中,n=0,1,2,…。
5) 檢验采集判别函数有效性。运用F统计计量进行检验所建立的判别函数的有效性。如果有效,则可对云储存海量数据进行采集,反之寻找其他方法。
6) 采集结束。亦即将符合[yi=maxishskyh]的[x]进行采集。
5 实验结果分析
为了验证改进方法在云储存数据采集方面的有效性及可行性,采用改进方法与传统方法为对比,以数据采集量及完整度为指标,在0.5 cm×0.5 cm区域内进行对比分析,结果如图4、图5所示。
由图4、图5可知,在0.5 cm×0.5 cm区域内进行数据采集分析时,采用传统方法,在远离分割线越远,云储存数据采集多次出现不完整现象,且采集量过少,导致数据采集结果误差越大,耗时越长;采用改进方法相比传统方法,数据沿着分割线逐渐降低,但未出现数据不完整的现象,分割线左右呈现相对应的形式,且采集量较大,具有一定的优势。
6 结 论
本文提出基于REID技术与F统计计量结合的云储存海量数据采集方法,达到了降低数据采集能耗,提高采集效率的目的。在相同区域采用传统采集方法为对比,其采集误差降低、准确率提高,能够更完整地进行采集。改进数据采集方法主要针对云储存数据进行采集,对于数据特征处理及采集环境对采集结果的影响,有待进一步研究。
参考文献
[1] 董一兵,刘丽,杨锐,等.一种测震仪器数据实时接入中间件设计与实现[J].地震工程学报,2017,39(5):969?975.
DONG Yibing, LIU Li, YANG Rui, et al. Design and implementation of the middleware to access realtime stream of digitizers [J]. China earthquake engineering journal, 2017, 39(5): 969?975.
[2] 赵芳云,张明富.基于云存储的海量海洋监测数据平台设计[J].舰船科学技术,2016,38(13):143?148.
ZHAO Fangyun, ZHANG Mingfu. Based on monitoring data of vast ocean cloud storage platform design [J]. Ship science and technology, 2016, 38(13): 143?148.
[3] 徐立艳.基于ARM和LabVIEW的网络数据采集测试系统设计[J].现代电子技术,2016,39(5):24?27.
XU Liyan. Design of network data acquisition and test system based on ARM and LabVIEW [J]. Modern electronics technique, 2016, 39(5): 24?27.
[4] 韩立,刘正捷,李晖,等.基于情境感知的远程用户体验数据采集方法[J].计算机学报,2015(11):2234?2246.
HAN Li, LIU Zhengjie, LI Hui, et al. A method based on context?awareness for remote user experience data capturing [J]. Chinese journal of computers, 2015(11): 2234?2246.
[5] 赵妍,苏玉召.一种批量数据处理的云存储方法[J].科技通报,2017,33(7):81?85.
ZHAO Yan, SU Yuzhao. A cloud storage method of batch data processing [J]. Bulletin of science and technology, 2017, 33(7): 81?85.
[6] 周朝挥,蔡燕霞,鲁国瑞.信牌驱动式Web数据采集模型的应用[J].计算机应用,2016,36(z1):252?256.
ZHOU Chaohui, CAI Yanxia, LU Guorui. Applications of XINPAI?driven Web data scraping model [J]. Journal of computer applications, 2016, 36(S1): 252?256.
[7] 高梦超,胡庆宝,程耀东,等.基于众包的社交网络数据采集模型设计与实现[J].计算机工程,2015,41(4):36?40.
GAO Mengchao, HU Qingbao, CHENG Yaodong, et al. Design and implementation of crowdsourcing?based social network data collection model [J]. Computer engineering, 2015, 41(4): 36?40.
[8] 韩盈党,李哲.MEMS加速度传感器的数据采集和预处理[J].仪表技术与传感器,2015(2):16?19.
HAN Yingdang, LI Zhe. Data acquisition and pre?processing based on MEMS accelerometer [J]. Instrument technique and sensor, 2015(2): 16?19.
[9] 倪晓寅,冯志生,陈莹.2013年岷县6.6级地震前天水台磁通门秒数据异常提取分析[J].地震工程学报,2016,38(z2):203?207.
NI Xiaoyin, FENG Zhisheng, CHEN Ying. Extraction and analysis of anomalies of the second data from GM4 fluxgate magnetometer at Tianshui station before the 2013 Minxian MS6.6 earthquake [J]. China earthquake engineering journal, 2016, 38(S2): 203?207.
[10] 邱雪松,蔺艳斐,邵苏杰,等.一种面向智能电网数据采集的传感器聚合布局构造算法[J].电子与信息学报,2015,37(10):2411?2417.
QIU Xuesong, LIN Yanfei, SHAO Sujie, et al. Sensor aggregation distribution construction algorithm for smart grid data collection system [J]. Journal of electronics & information technology, 2015, 37(10): 2411?2417.
[11] 何茂辉.4G网络下的多终端建筑工程现场移动数据采集系统设计[J].现代电子技术,2016,39(15):25?27.
HE Maohui. Design of multi?terminal mobile data acquisition system utilizing 4G network for architectural engineering field [J]. Modern electronics technique, 2016, 39(15): 25?27.
