基于部分实例重判的二分K-means算法
2018-06-13吴清寿刘耿耿郭文忠
吴清寿, 刘耿耿, 郭文忠
(1. 武夷学院数学与计算机学院, 福建 武夷山 354300; 2. 福州大学数学与计算机科学学院, 福建 福州 350116)
0 引言
聚类分析是无监督学习的重要方法. 聚类分析能够发现数据集自身隐含的内蕴结构信息, 其在模式识别与数据挖掘等研究方向有着广泛的应用. 根据数据集中数据的积聚规则和应用这些规则的方法, 可以将聚类算法大致分成层次化聚类算法、 划分式聚类算法、 基于密度和网格的聚类算法以及其他聚类算法[1].K-means聚类算法是划分式聚类的典型代表.K-means算法的首要问题在于对初始质心的选择是敏感的, 文献[2]提出了一种基于最大最小距离法确定初始质心的方法, 文献[3]利用聚集度函数和层次聚类来获取初始质心. 针对K-means易于收敛到局部最小值而非全局最小值的问题, Ding等[4]提出一致性保留K-means算法(K-means-CP), 可实现全局聚类目标函数优化. 作为K-means算法的重要变种, 二分K-means也得到了广泛的应用和研究. 文献[5]提出以极大距离点优化二分K-means初始质心的方法, 并对算法进行并行化处理. 文献[6]将二分k-均值与SVM决策树相结合, 用二分k-均值在低维数据空间中聚类, 取得了良好效果.
在各类研究中, 对文献[1]所提出的一个问题未予以解决, 即二分K-means算法存在再分配能力差问题. 问题具体表现为: 若在某个阶段把一些实例(instance)误划分给某个簇, 这些实例将失去回归原应归属簇的机会. 本研究通过引入目标簇和候选簇的概念, 在候选簇中选出若干距离目标簇最近的实例作为召回实例, 并对召回实例进行重判, 让部分误判实例有机会回归, 从而提高聚类的精确度.
1 K-means算法
K-means算法把数据集X划分成k个聚类(也称为簇)C=(C1,C2, …,Ck), 数据集X定义为{x1,x2, …,xn}, 其中xi=(xi1,xi2, …,xir)是一个向量, 表示数据集X中的第i个实例,r表示数据的属性数目. 每个聚类中有一个中心, 称作聚类质心(centroid), 表示为M=(m1,m2, …,mk). 定义簇Ck的质心mk为:
(1)
其中:xik是簇Ck的第i个实例,nk表示簇Ck中的实例数量. 簇内方差是簇中所有实例与簇质心的欧氏距离平方和, 整个聚类空间的误差平方和(sum of squared error, SSE)是簇内方差之和. 簇内实例与质心的欧氏距离公式:
(2)
式中:xikn表示簇Ck的第i个实例的第n个属性;mkn表示质心mk的第n个属性. 算法将SSE作为度量聚类效果指标[7], 可以定义为:
(3)
K-means算法的基本思想是将数据集中的所有实例划分到k个簇中, 通过不断地迭代质心, 使簇中的所有实例到该簇质心的距离最小, 并使得SSE最小.
K-means算法的终止条件可设定为以下几种情况之一[8]: 1) 没有(或最小数目)数据实例被重新分配给不同的簇; 2) 没有(或最小数目)质心发生变化; 3) SSE达到最小值(可能是局部最小).
K-means算法易于实现, 时间复杂度为O(tkn),n是数据集中实例总数,k是聚类的个数,t是迭代次数. 一般情况下,k,t值通常远小于n, 故K-means的时间复杂度对x是线性的. 以下主要讨论算法存在的不足之处: 1) 算法只能应用于均值能够被定义的数据集上, 文献[9]提出的k-modes是K-means的一种变体, 解决了K-means仅适合于数值属性数据聚类的局限性, 适用于分类属性数据聚类; 2) 需要预先设定聚类数目k, 文献[7]和文献[10]对这个问题都提出了解决方案; 3) 对噪音点较为敏感[11].
2 二分K-means算法
二分K-means算法基本思想[12-14]: 首先, 初始数据集的所有实例归属同一个簇, 计算该簇质心; 之后, 利用K-means算法将该簇进行二分, 以最快速度降低SSE的值为划分依据, 从现有簇中选择一个簇继续进行二分; 不断重复以上步骤, 以簇的总量达到要求为终止条件.
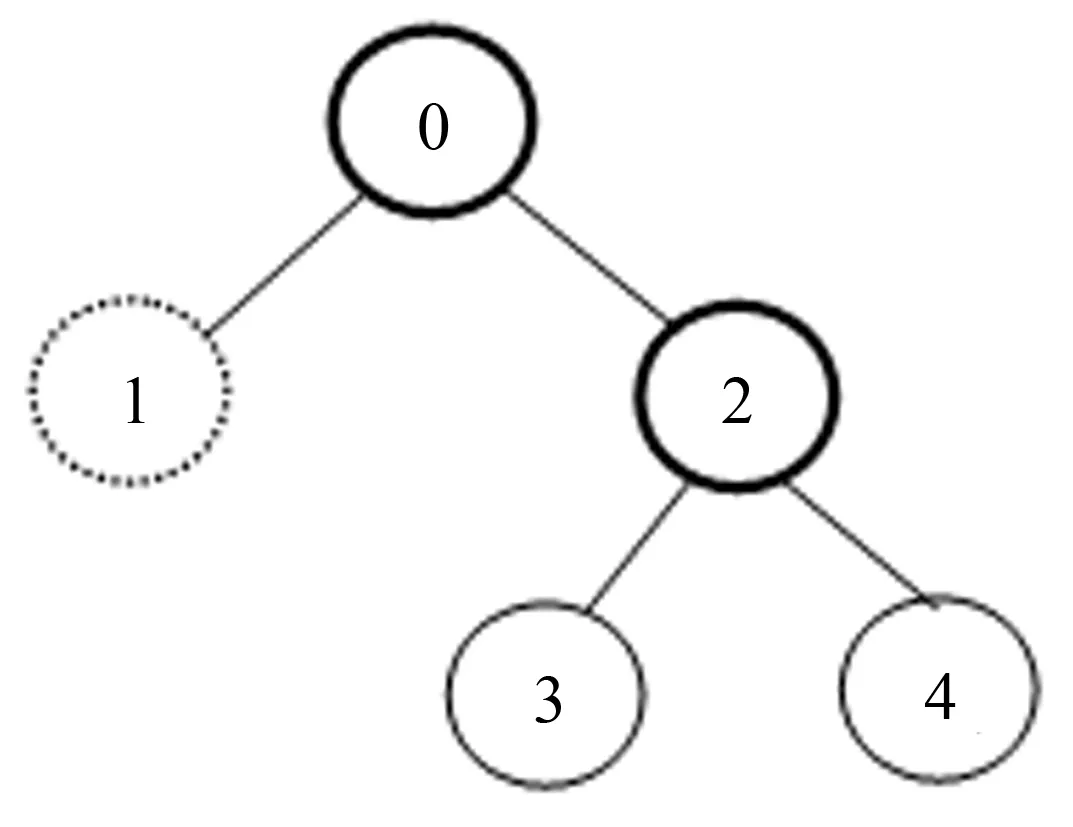
在二分K-means算法中, 度量第h簇划分质量的SSEh由两个部分组成: 当前簇的误差平方和SSEcurr和其余簇的误差平方和SSEother. 假设数据集X当前包含n(n (4) h0和h1表示簇号,i表示簇中的第i个实例. 其余簇即除了簇Ch之外的所有簇, 表示为(C1,C2, …,Ch-1,Ch+1, …,Cn), 其SSE计算式为: (5) 其中:U={1, 2, …,h-1}∪{h+1, …,n}. 则SSEh可表示为: SSEh=SSEcurr+SSEother (6) 二分K-means算法流程如算法1所示. 算法1.BiKmeans算法.Begin 将数据集X的所有实例当成第0簇 求第0个质心 根据公式(3)计算初始SSE While (总簇数 二分K-means算法得到了广泛的应用, 针对二分K-means算法的改进研究也取得了良好的效果[10]. 在众多研究中, 有一个问题没有得到足够的重视, 即二分聚类过程中, 部分实例可能会被划分到错误的簇中. 根据二分K-means的聚类规则, 实例一旦被错划, 就失去了回归正确簇的机会. 基于部分实例重判的二分K-means算法对上述问题提出了解决方案. 定义1在二分K-means算法执行过程中, 簇Ci被二分为簇Cp和簇Cq, 则称Cp和Cq互为兄弟簇,Ci称为Cp和Cq的父簇,Cp和Cq称为Ci的子簇. 将Ci二分聚类使得SSE最小, 则称Ci为目标簇, 若Ci和Cj互为兄弟簇, 且Cj从未成为目标簇, 则称Cj为Ci对应的候选簇. 定义2候选簇Cj中存在若干实例xuj, 在目标簇Ci二分为子簇Cp和Cq后, 计算xuj与Cj、Cp和Cq的质心mj、mp和mq之间的距离d(xuj,mj)、d(xuj,mp)和d(xuj,mq), 若d(xuj,mj) 图1 二分后的目标簇、 候选簇Fig.1 The object clusters and candidate clusters after bisecting 如图1所示, 根据定义1, 簇2为目标簇(用加粗表示), 簇1为候选簇(用虚线表示). 若簇1中存在召回实例, 通过判断实例与簇3和簇4的质心之间的距离, 以决定将实例归入簇3或簇4. 其判断条件为若d(xuj,m3)>d(xuj,m4), 则将实例划入簇3, 否则, 将实例划入簇4. 从图1可以看出, 其包含两个目标簇(簇0和2)和一个候选簇(簇1), 表示需进行两次二分聚类并需要一次召回实例的重判. 候选簇中的实例并不需要全部参与判别, 通过对候选簇的样本进行排序, 设定一个阈值θ, 以控制参与重判的实例数量. 排序主要依据二分时计算出的样本与两个质心的距离. 两相比较, 作为候选簇中的实例, 其与候选簇质心的距离必然小于到目标簇的距离, 所以在两个距离中选择较大的距离并进行升序排序, 找到候选簇中距离目标簇最近的若干个实例作为召回实例的判别对象. 图2是二分K-means算法对数据集中全体实例的一次模拟二分聚类过程, 其划分过程与簇号生成遵循以下规则. 图2 二分K-means算法的二分聚类及簇号生成过程 Fig.2 The bisecting clustering and the cluster number generation process of the bisec-ting K-means algorithm 规则1. 目标簇Ci二分为子簇Cp和Cq时, 一个子簇保留父簇的编号, 另一个子簇编号为二分前簇的总量, 簇号索引从0开始. 规则2. 目标簇Ci确定后, 要判断其兄弟簇Cj是否为候选簇, 若Cj是候选簇, 则进行召回实例重判处理. 根据规则1, 图2所生成的簇号和图1中的簇编号不同, 是因为采用图1方便说明问题, 图2中的编号才是真正的簇编号生成方法. 图2所示的二分聚类过程为0->(0, 1), 1->(1, 2), 0->(0, 3), 1->(1, 4). 以1->(1, 2)为例, 这是第2次进行二分, 簇Ci(i=1)是目标簇, 当前簇数目为2(即簇0和1), 根据规则1, 两个子簇的编号为Cp(p=1, 父簇的编号为1)和Cq(q=2, 当前簇数目为2). 簇Ci(i=1)的兄弟簇Cj(j=0)是候选簇, 所以要进行召回实例的重判处理. 而在0->(0, 3)这次二分中, 因目标簇Ci(i=0)的兄弟簇Cj(j=1)已进行过二分聚类, 所以Cj(j=1)不是候选簇, 其所包含的实例无需进行召回实例重判. 表1 二分K-means算法的簇生成过程 为快速查找候选簇和目标簇, 需维护一个二维数组cluster, 见表1, 其与图2中簇生成过程存在一一对应关系. 表1包含两列, 第0列记录按顺序生成的簇号, 因数组索引从0开始, 所以簇号与数组行索引同值. 第1列记录第0列簇号对应的兄弟簇及其变迁过程, 初始簇没有兄弟簇, 不包含在表1中. 如表1所示, 第0列中的簇1对应的兄弟簇号序列为0/2/4, 其表示簇1的初始兄弟簇为簇0, 后续又经过两次二分聚类: 1->(1, 2), 1->(1, 4), 其兄弟簇号先后更新为2和4. 应用到算法中, 可用于快速定位候选簇. 规则3. 在cluster数组中, 因数组索引从0开始, 所以簇号与数组行索引同值. 目标簇Ci的兄弟簇为Cj, 则cluster[Ci][1]的值为Cj, cluster[Cj][1]的值为temp, 表示Cj的兄弟簇号; 若temp=Ci, 则说明Cj至今未进行二分, 是一个候选簇. 如1->(1, 2), 目标簇1的兄弟是簇0, 簇0的兄弟簇是1, 两者相等, 则簇0为候选簇. 若0->(0, 3), 目标簇0的兄弟簇是1, 簇1的兄弟簇已变更为2, 两者不相等, 则簇1不是候选簇, 簇中实例无需重判. 部分实例重判算法(partial instance rejudge, PIR)是作为二分K-means算法的一个组件存在, 算法2中对算法1的内容不再重复. 算法2.PIR算法Begin If Ci==cluster[cluster[Ci][1]][1] #根据规则3确定候选簇 过滤出候选簇Cj中的所有实例 对所有实例按照到目标簇的距离升序排序 根据阈值θ确定参与重判的实例集合newClust For each instance in newClust 计算实例与目标簇的两个子簇质心的距离D0、 D1 计算实例到候选簇的距离D2 根据定义2确定召回实例 将召回实例分配到相应子簇 End 在cluster数组中将两个子簇互标为兄弟簇 EndEnd 为验证分析算法, 对K-means、 BiKmeans及PIR-BiKmeans三种算法进行比较, 并从UCI机器学习数据集中选择Iris、 Wine和ADL中的Drink_glass三个数值型数据集进行测试. Iris数据集有150个实例, 每个实例有4个属性, 数据集分3个类别, 每个类别包含50个实例, 这是在各类算法中被应用最多的数据集. Wine数据集有178个实例, 实例有13个属性, 也是分成3个类别, 第一类有59个, 第二类有71个, 第三类有48个, 其聚类结构良好. Drink_glass数据集是从ADL中抽取部分实例构成的, 共484个实例, 实例有3个属性, 共分为5类, 每个类别分别包含140, 70, 90, 69和115个实例, 采用手工分类. 实验环境: 处理器Intel Core i5-3210M 2.5 GHz, 内存4 G, 操作系统为Windows7 64位, 编程语言为Python2.7. 分别用三种算法对三组数据进行聚类, 得到图3~4所示结果. 图3 不同算法对3个数据集进行15次随机实验的平均运行时间 4.1.1 时间性能分析 从图3可以看出, 对Wine数据集进行聚类花费的时间最长, 因为Wine数据集的实例有13个属性, 大于其他两个数据集的属性数量, 增加了算法的计算时间. 用3种算法对同一个数据集进行聚类, 运行时间最长的是BiKmeans算法, 最短的是K-means算法, 特别是对Drink数据集聚类时, BiKmeans算法的运行时间是K-means算法的1.6倍. 这是因为将数据集分成3类时, BiKmeans算法调用K-means算法的次数是3次, 分成4类时, 要调用6次, 而分成5类时则是10次. 虽然每次调用要处理的实例数量减少, 但调用次数的大幅度增加是造成运行时间延长的主要原因. 运行结果显示, PIR-BiKmeans算法的平均运行时间小于BiKmeans算法, 其原因在于通过对召回实例的处理, 使得簇结构更为紧凑, 减少了聚类迭代次数, 从而提高了运行效率. 为了更加直观地展示算法, 表2对两个算法的迭代次数进行了分析. 通过表2可以看出, PIR算法的平均迭代次数明显少于BiKmeans算法, 相应地, 迭代次数决定了运行时间, PIR算法的平均运行时间也明显少于BiKmeans算法. 表2 不同算法对三个数据集进行15次随机实验的迭代结果 4.1.2 聚类准确率分析 图4中, 对三个不同的数据集, 改进算法PIR-BiKmeans的聚类效果都是最好的, 而原始算法K-means的效果都是最差的. BiKmeans算法不一定每次都能收敛于全局最佳值, 经过多次运行, 还是能够弥补K-means算法经常收敛于局部最小值的缺陷, 所以其在三个数据集中的平均聚类准确率都高于K-means算法. PIR-BiKmeans算法通过对前期误判的实例进行召回, 部分纠正了实例的分簇结果, 所以能取得良好的聚类效果. 4.1.3 与同类工作的对比 Iris和Wine数据集常用于各类聚类算法的测试, 此处将本研究算法的聚类结果与文献[7]和文献[11]中的相关算法进行对比. 文献[11]中对Iris数据集采用了三种算法计算其聚类准确率, 其与本研究算法的聚类准确率对比情况如表3. 表3 本研究算法与文献[11]的对比 文献[7]中对Wine数据集采用了两种算法计算其聚类准确率, 其与本研究算法的聚类准确率对比情况如表4. 表4 本研究算法与文献[7]的对比 Drink_glass数据集未见于其他文献, 无从比较. 通过对Iris和Wine两个数据集的聚类情况看, 本研究实现的算法与同类工作相比, 在聚类准确性方面有一定程度的提高. 在PIR-BiKmeans算法中, 阈值θ的取值关系到召回实例的有效率, 并最终决定聚类的整体准确率. 经对Iris等三个数据集进行实验验证,θ的取值在5%~20%之间能取得较佳效果. 表5对θ全部取值为6%, 关于θ取值的有关问题在下一节讨论. 为防止候选簇中实例数较少出现召回实例数量为零的情况, 此处将参与重判的实例数设为|Cj|×θ+1, |Cj|表示候选簇Cj中的实例数量, 并进行15次随机实验, 得到表5中的实验结果. 表5 PIR-BiKmeans算法对三个数据集进行15次随机实验的召回实例情况 图5 θ取值与聚类准确率的关系 Fig.5 Relationship between theta’s value and clustering accuracy 对于阈值θ的取值规则, 此处进一步予以说明. 在本次实验中, 对θ的取值范围设定为5%~20%, 并指定步长为1%, 对三个数据集分别用不同的θ值进行测试, 得到图5所示结果. 从图5中可以看出, 在不同的数据集中,θ的不同取值对聚类精确率并未呈现出统一的规律性, 如Iris数据集,θ的值为6%时聚类准确度最高, 而后θ取值越高, 其准确率越低(Iris本身的聚类效果较好, 参与重判的实例越多, 被误判的实例也就越多). 在Drink数据集上用不同的θ值进行测试,θ的取值越高, 聚类精确度也逐步提高. 而Wine数据集在θ取值为14%时达到较好聚类效果. 本研究引入目标簇及候选簇的概念, 通过维护一个二维数组简化了对候选簇的定位, 实现了对可能在划分过程误判的部分实例进行二次聚类判断, 提高了聚类精度和算法运行效率. 改进算法中还存在若干需要进一步研究的问题: 1)θ取值对不同的数据集是有所区别的, 尤其在大的数据集中, 取值的大小将影响大量的实例, 探索一个合理有效的θ取值规律和范围是一项有意义的工作; 2) 从候选簇中确定召回实例有一定的效果, 但还是不够全面, 特别是处在图2中叶子节点位置的簇还未充分判断. 参考文献: [1] 孙吉贵, 刘杰, 赵连宇. 聚类算法研究[J]. 软件学报, 2008, 19(1): 48-50. [2] TZORTZIS G, LIKAS A. The minmaxK-means clustering algorithm[J]. Pattern Recognition, 2014, 47(7): 2505-2516. [3] MA G W, XU Z H, ZHANG W,etal. An enrichedK-means clustering method for grouping fractures with meliorated initial centers[J]. Arabian Journal of Geosciences, 2014, 8(4): 1881-1893. [4] DING C, HE X. K-nearest-neighbor in data clustering: incorporating local information into global optimization[C]// Proceedings of the 2004 ACM Symposium on Applied Computing. Nicosia: ACM Press, 2004: 584-589. [5] 张军伟, 王念滨, 黄少滨, 等. 二分K均值聚类算法优化及并行化研究[J]. 计算机工程, 2011, 37(17): 23-25. [6] 裘国永, 张娇. 基于二分K-均值的SVM决策树自适应分类方法[J]. 计算机应用研究, 2012, 29(10): 3685-3687. [7] 成卫青, 卢艳红. 一种基于最大最小距离和SSE的自适应聚类算法[J]. 南京邮电大学学报(自然科学版), 2015, 35(2): 102-107. [8] LIU B. Web data mining[M]. Berlin: Springer-Verlag, 2009. [9] HUANG Z. Extensions to theK-means algorithm for clustering large data sets with categorical values[J]. Data Mining and Knowledge, Discovery, 1998, 2(3): 283-304. [10] 刘广聪, 黄婷婷, 陈海南. 改进的二分K均值聚类算法[J]. 计算机应用与软件, 2015, 32(2): 261-263. [11] 左进, 陈泽茂. 基于改进K均值聚类的异常检测算法[J]. 计算机科学, 2016, 43(8): 258-261. [12] WITTEN I H, FRANK E. Data mining: practical machine learning tools and techniques[M]. 2nd. San Francisco: Morgan Kaufmann, 2005: 253-261. [13] 李雯睿, 白晨希. 一种本体学习模型的设计与实现[J]. 河南大学学报(自然科学版), 2006, 36(4): 100-102. [14] 解小敏, 李云. 最小最大模块化网络中基于聚类的数据划分方法研究[J]. 南京大学学报(自然科学版), 2012, 48(2): 133-139.
3 基于部分节点重判的改进算法



4 实验结果与分析
4.1 聚类准确率与运行时间分析




4.2 召回实例正确率分析

4.3 阈值θ的取值问题

5 结语
