基于海量异构数据索引语义查询的关键模型研究
2018-06-13桑海翎郭文忠
桑海翎, 郭文忠
(1. 福建广播电视大学教学管理中心, 福建 福州 350013; 2. 福州大学数学与计算机科学学院, 福建 福州 350116)
随着互联网、 物联网等信息技术的发展, 数据资源呈现出指数式的增长[1]. 根据当前的数据应用情况, 互联网数据处理中心经过数据监测并进行了合理预测, 分析结果表明全球数据量将持续增加, 到2020年的总数据将达到35 ZB. 毫无疑问, 当今正在迎来一个大数据时代[2]. 作为大数据的主体, 非结构化数据也正在高速发展, 这对传统的非结构化数据管理提出了新的挑战. 大量的异构数据包括结构化和非结构化数据. 在以往研究中, 相应的索引以及语言的查询主要是针对某一种数据类型来进行设计和构建. 结构化数据一般使用SQL语言进行查询, 通常在一个或几个属性上建立索引来加速查询效率, 如B+树、 Hash等. 本研究基于海量异构数据特征模型, 通过对非结构化数据进行构建模型并将数据相关问题进行重点分析和研究, 如原始数据及特征数据的存储和查询问题、 数据的可视化问题、 如何选择特征空间等.
1 非结构化数据模式分析研究现状
基于非结构化数据特征, 可以开展非结构化数据的模式分析, 模式分析的结果是形成非结构化数据的相关性判断及浅层语义挖掘, 支撑数据的分类、 聚类、 推荐、 相关性搜索等各类应用. 为了应对海量数据的挑战, 并充分利用数据的规模效应产生更好的模式分析结果, 目前非结构化数据模式分析主要采用机器学习方法. 机器学习作为一门涉及多个领域且各个领域相互交叉的学科, 已经发展了将近20年[3]. 该学科的相关学者对其进行了分类, 有监督学习方法、 无监督学习方法以及半监督学习方法. 监督学习分别是集合的输入、 输出, 充分代表了监督学习的特征以及目标. 常用的算法主要是回归算法和统计算法, 通过对比有无监督学习发现, 无监督学习可以进行聚类且不会被人为地进行标示[4]. 介于它们之间的就是半监督学习法, 其兼具了有无监督学习的特点. 机器学习在不断的发展, 特别在针对不同业务场景、 不同行业特征的相关算法整合优化利用上, 其仍是学术界和工业界研究的重点.
在过去几年, 作为互联网搜索、 机器翻译、 语音识别等应用的核心技术基础, 自然语言处理及机器学习方法在互联网等行业得到了广泛应用, 且已经被证明是目前最有效的非结构化数据分析和挖掘方法[5]. 在企业内部, 各业务系统产生的海量非结构化数据目前尚未得到有效利用. 基于主流的自然语言处理和机器学习算法, 可结合企业非结构化数据特点, 实现覆盖海量非结构化数据. 从数据特征提取到可视化分析等相关技术, 形成的技术成果能够为各业务系统基于非结构化数据研发的决策支持、 趋势预测、 风险监控等类型的应用提供技术支撑, 有利于提升企业对海量非结构化数据的整体利用能力.
2 非结构化数据特征建模
构建非结构化数据特征模型, 主要的思想是构建三个主要的数据库, 即特征数据库、 原始数据库和特征空间[6]. 其系统中的各个数据特征对应一个处理类, 各个特征处理类按照业务需求各自实现数据的特征提取、 索引构建、 数据信息查询功能.
特征指某个或某些数据(database)具有的共性, 对于特征的定义可按业务需求或者依据数据自身的共性界定. 同样, 为了更好对海量非结构化数据进行搜索, 就需实现对数据对象进行快速定位和查询. 如何保障和提高数据特征的索引速度和准确性是解决这一问题的关键.
要想描述一个数据对象, 将多维度的指标项进行梳理是很重要的, 从多维角度描述数据对象特征, 即特征类型. 特征类型即描述特征项的含义, 包括取值空间和特征值域的度量关系, 这样就准确定义了一个特征值, 有利于准确理解和应用该数据[7]. 而描述一个数据的特征, 需具备三方面的条件: 第一, 在某种方式基础上, 数据对象能够进行特征类型特征数据的抽取; 第二, 特征数据抽取具有描述意义; 第三, 取值特征数据时, 要保证其处于特征类型的取值空间中.
数据若不具备结构化特征, 管理过程中, 必须统一管理全部数据. 不过, 从现有技术手段来看, 统一管理方法并不存在普适性, 即建设非结构化数据特征模型时, 关键问题在于统一管理数据, 对此, 本研究在确定管理方法时, 采用四面体数据模型.
数据类型属于特征集合, 其中包含的非结构化数据有多个[8]. 特征类型具有种类多样的特点, 实际应用中, 每个数据对象仅表示有限的意义, 但通常非结构化数据的分类特性却是清晰的. 总体上, 可以利用有限特征, 将映射从特征空间抽取出来, 便是特征集合. 建立非结构化数据特征模型时, 关键在于要对数据类型做出合理的定义.
3 建模相关关键技术研究
非结构化数据海量、 异构、 多元、 内容丰富且不容易描述, 目前能够有效提取实现非结构化数据特征抽取建模的标准化路径和自动化处理方法暂时没有或不具备. 要解决海量非结构化数据模型这一问题, 特征建模至关重要[9]. 若运用非结构化数据特征构建模型进行数据特征识别和选择, 需要注意选取特征的方式和特点, 如数据可视化、 信息识别以及语义查询等.
3.1 非结构化特征信息识别与抽取
所谓非结构化信息提取技术主要是通过某些具有代表性的一些日常行为提取出相关具有价值的消息, 再对消息进行深层次解析以便能自动为人们进行解答, 方便了信息获取, 该技术得到了广泛的应用[10]. 以Google公司为例, 其利用该办法通过网罗大量的互联网浏览信息, 对各种信息进行细致划分, 为各种搜索方式提供一个搜索依据, 如: 图片、 视频、 网页等搜索方式. 再例如Facebook这种社交平台也会根据所有用户的搜索及评论来进行有价值的信息提取, 通过信息的对比和分析可以了解客户需求来有针对性地进行广告弹出. 而逐渐衍生出的许多专门以提取信息为主要工作方向的公司, 知名度较高的有: Cymfony、 Linguamatics、 Bhasha、 Revsolutions, 这些公司甚至拥有独立的一套专利产品来进行信息提取.
3.2 在数据可视化方面的研究
随着计算机硬件的飞速发展, 使得人们可以构造更加复杂和规模更大的模型来分析日趋庞大的数据, 并且发展了更多的图形学技术和方法[11]. 如今数据可视化的内容已经相当丰富, 并且大致可以分为科学可视化和信息可视化两个方面. 前者主要关注对体、 面、 光源等的逼真渲染; 而后者则旨在研究大规模的非数值型数据的视觉呈现, 以期帮助读者更加直观地理解和分析数据. 在统计学中, 学界对统计图形的研究主要是限于数据可视化工作. 而数据可视化在统计学中的应用也主要是统计图形, 旨在利用图形将数据及其包含的各种信息以直观简洁的方式展现出来[12]. 故数据可视化在统计教学中的主要应用是指统计图形的应用. 一般说来统计图形在统计教学中的主要表现形式是散点图、 直方图、 概率图、 残差图、 箱线图、 饼图、 茎叶图等. 通过其可以直观地找出数据的分布特征、 变量间的大致关系等数据特性. 除了以上常用功能外, 统计图形在检验假设、 模型选择、 统计模型验证、 估计量选择、 关系确定、 因素效应判定以及离群值检出方面也有着不俗的表现.
图1 BirdEye数据可视化Fig.1 BirdEye data visualization
通用可视化工具方面, 最重要的应用工具是R语言, 随着R语言的兴起, 新的统计图形方法如雨后春笋般涌现出来[13]. 目前, 4种统计图形方法较具备代表性: 第一, graphics及grid, 为R的基础包; 第二, lattice图形, 该方法以Trellis图形为基础; 第三, ggplot2图形, 以Wilkinson为基础; 第四, 三维动态图形系统rgl包, 以OpenGL为基础. 这些工具均在工业界得到了广泛的应用. 另一方面, 随着Web逐渐成为应用界面的主流形式, 在Web可视化领域, 也产生了不少产品. 如开源领域的BirdEye以及商业产品FusionCharts、 IBM公司的iLog Exlixir产品. 图1为BirdEye数据可视化效果截图.
3.3 数据检索的关键技术实现
以规范键值对数据本体进行存储, 可满足对单条数据提取的业务需求. 但实际应用过程中, 需要检索具备某类特征的系列数据, 一般是通过人工或系统辅助模式进行有效检索, 复杂而且费时费力. 为了提高数据检索速度, 需要优化相关技术, 即依据Map Reduce模型的相关理论, 构建能与Master-Slave模型并行的进行数据处理和选择的索引框架, 从而实现对指定数据对象的快速检索[14]. Master在管理Slave的同时, 可以兼具分解和分配检索调度的功能, 可实现高效的整合检索结构. Slave模块可以承上启下, 即能向Master上传具体的数据检索, 也能并行化处理检索结构. 图2为数据检索技术架构.

图2 数据检索技术架构Fig.2 Data retrieval technology framework
应用展示层: 功能包含检索(关联、 综合)、 可视化展现、 自动推荐, 数据可视化效果兼容浏览器时, 通过多种关键技术来实现, 如JSP技术、 Html技术, 促进用户体验增强.
接口层: 统一标准接口预留时, 采用方式为三种, 分别为Java APT方式、 WebService方式、 Http RestFell方式, 确保系统集成使用功能的实现.
服务层: 主要提供各种服务, 如基础公共服务、 搜索引擎服务、 分布式调度任务服务等, 各服务之间的隔离形式采取“微服务”, 柔性地支撑系统及应用层实现[15].
存储层: 用于存储各种数据, 主要包含三种, 分别为非结构化数据、 关系数据及索引数据.
数据集成: 集成多源异构系统数据时, 经统一集成接口实现.
3.4 基于查询语言的关键技术
通常, 人们进行搜索的方式为输入关键词, 这种方式的优点是快速、 方便, 但却存在一定弊端, 即对用户信息表达不够完整且准确度不够高, 对于相对复杂的数据分析与处理无法保障其全面性和准确性[16]. 在大数据时代, 为构建非数据化数据管理平台, 来充分表达用户的查询意图, 满足用户的各种搜索需求, 就需要根据非结构化数据特征的模型以及数据信息的具体情况, 使用一种查询语言, 即UQL.
UQL在对非结构化数据进行数据信息查询的同时也可以对查询信息进行分类和统计[17]. 基本搜索方式有以下几种: 原始语句信息属性及特点搜索; 多数据联动搜索; 通过分析数据某个基本特性来进行种类划分并作为关键词进行搜索; 对于多维数据、 类别分散、 聚拢等, 自动化搜索其搜索结果; 对数据做出定义, 统计数据分类等. 这些搜索方式主要依据语言的特性、 定义、 基础属性进行搜索. UQL能够复合使用各种检索方式, 实现综合检索数据.
此外, 基于XML具有极佳的扩展性, 通过XML这种特性可以准确地对四面体模型在表面特性和语言方式上面进行镌刻[18]. 以XQuery为例, 它具有数据语言查询功能, 因此能够广泛应用在XML之中. 而UQL因为不具备底层特征查询、 智能查询等功能, 所以它在XQuery中并没有被进行推荐应用. 为了使XQuery能够发挥应有功效, 本研究对XQuery加设了语句词条查询功能, 对其中无作用的文段进行人为省略, 将在XQuery之上提出来的UQL语言查询法, 通过扩充巴科斯 - 瑙尔范式 (EBNF)来进行对非结构化语言的描述. UQL在语句的查询、 统计、 分类几方面进行了定义, Query在UQL中应用最广, 它能更改XQuery中的FLWOR, 以达到语句完整性的目的. 其中省略let 语句和 orderby 语句, 增加 intelligence 和 filepath语句来定义智能查询和实例查询. Query语句的描述如下:
Query Clause ::= For Clause Where Clause Return Claus
e Intelligence Clause? File Path Clause?
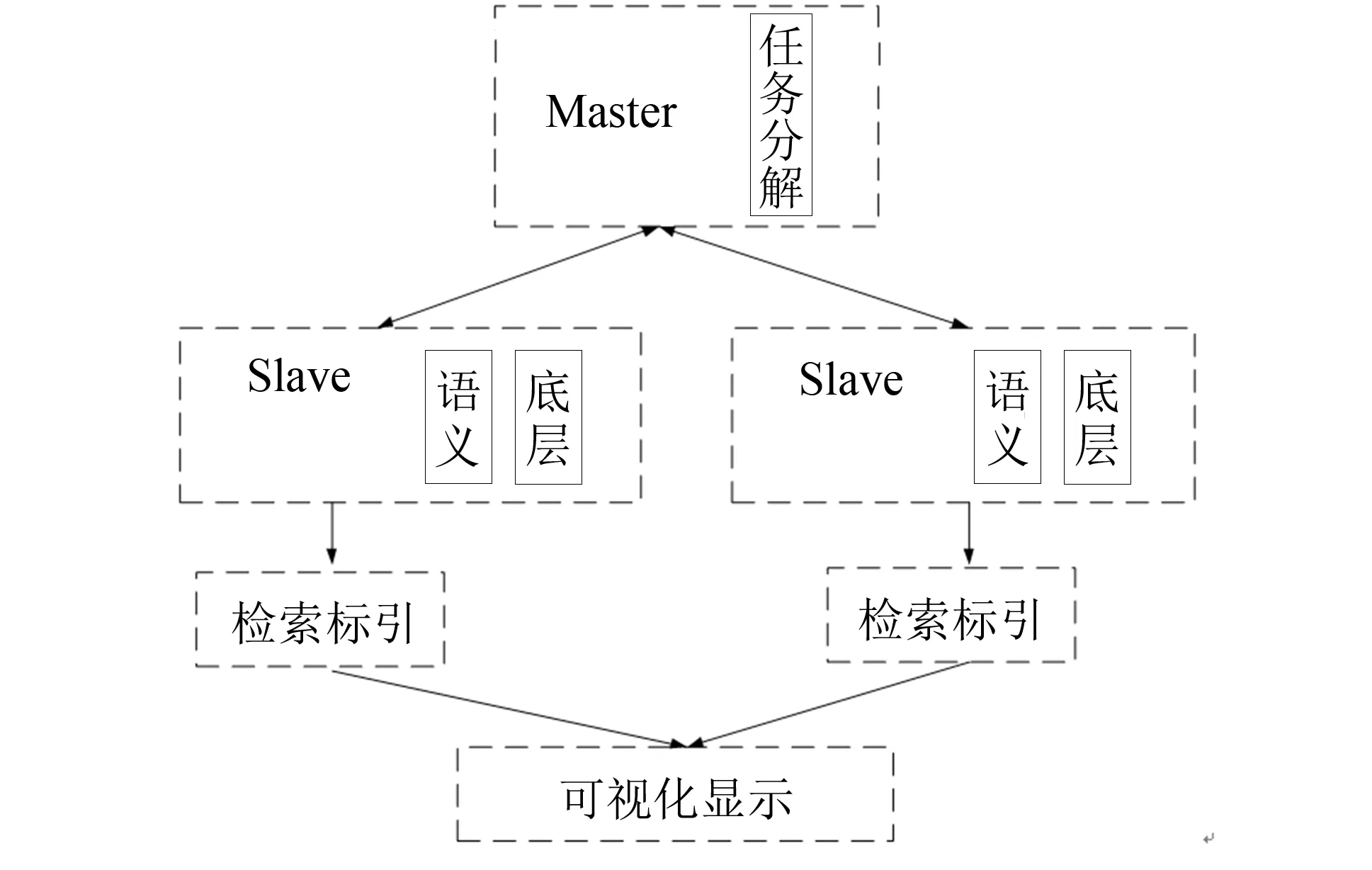
图3 非结构化数据的可视化处理框架Fig.3 Visualization framework for unstructured data processing
UQL数据查询语言说明: Define Clause数据定义, 主要定义数据类别及语义项字段信息, 对数据的个性化特征和要求采用xml描述基本属性和语义特征; 采用Count Clause语句进行数据统计, 包括统计类别、 基本属性等, 完成数据的统计功能. 将UQL数据查询语言与四面体模型相结合, 通过语义和底层特征来选取的特殊检索方式, 如关联检索和单项检索等, 引入智能化操作系统以达到实际应用目的.
3.5 可视化检索的关键技术
为了获得高效的检索结果, 需要对检索形式进行优化. 应该以Map Reduce模型进行并行化检索, 实现非结构化数据的批量处理(batch processing)[19]. Master-Slave检索框架可以将检索词条进行分解和整合, Master→Slav输出时, 可以进行任务分解, 而Slav→Master上传时, 可以进行检索优化. 图3所示为非结构化数据的并行处理框架.
3.6 可视化呈现技术
应用、 显示非结构化数据时, 要对接使用客户端. 通常, 人们利用静态可视化技术, 操作方式比较简单, 但是不能全面展示业务信息, 也不能帮助调度者进行复杂的数据处理[20]. 因此, 要进行基于大量非结构化数据检索的数据呈现, 必须要创立一种显示语言, 以满足实际业务的需求, 完成可视化作用. 针对四面体模型的非结构化数据, 进行可视化处理时, 本研究选择UQL这种非结构化检索语言以及SVG语言. UQL查询语言可以完成非结构化数据的多项查询, 还可以进行数据定义和统计. SVG属于一种置标语言, 可以进行二维矢量图形、 矢量点以及混合图形处理, 是目前一种全新的矢量图形规范语言. UQL可以进行基本属性和语义查询、 多模态关联查询、 多种类型及数据的查询, 而且可以显示数据统计结果. SVG语言支持无极缩放、 精准定位、 图层管理和动态交互、 参数查询等功能. 两者结合可以让可视化系统呈现出接线地理信息、 地理信息和XML格式数据源, 大大提高了非结构化数据的处理效率. Query为UQL定义的查询语句, 可以实现智能、 实例两种查询, 智能方式主要用于线路整体显示, 实例方式主要用于具体位置显示, 检索语句如下:
〈g Query Clause∷=For Clause Where Clause Return Claus
e Intelligence Clause * File Path Clause *
id=”*”
use transform=” translate(A,B) rotate(E,F,G)”
scale (1, 1)”fill=“rgb(H,I,O)”xlink: href=“#变电站a”stroke=” rgb(H,I,O)” xlink: show=”embed”
〈metadata〉
cge: ObjectID=“a” ObjectName=“C站”Plane=“1”AFMask=“G”/〉
〈/metadata〉
〈/g〉
基于XML模式的UQL和SVG语言, 通过Define Clause进行语言定义, 主要是数据类别和语义定义, 然后用Count Clause进行数据统计, 最后用xlink: show进行可视化显示. UQL和SVG语言结合四面体模型, 通过基本特征、 语义和底层特征的检索方式, 并结合SVG的矢量图形显示, 实现了非结构化数据的智能化上层应用操作.
3.7 全文检索
1) 综合检索. 跨业务检索通过通用的数据级权限模型设计实现权限数据的统一存储, 再结合业务信息和文档内容信息共同构建搜索引擎中的索引文件, 从而实现对外的跨业务系统检索, 同时提供标准接口与业务系统进行集成.
综合检索是针对信息源的基本检索功能, 包括精准检索、 模糊检索、 附件内容检索. 技术上采用全文检索技术实现, 支持按照标题、 关键属性、 文件类型进行检索, 支持同义词、 近义词纠偏, 支持搜索结果按照时间、 类型等进行排序和筛选功能.
2) 关联检索. 关联检索是在综合检索的基础之上, 构建信息点的关系图谱, 构建一个与搜索源及结果相关的完整的知识网[21]. 根据信息的关系程度, 形成关系度排序, 按照内外维度以图形可视化方式一层一层展现. 关联检索需开展以下5点主要工作. ① 算法分析. 开展文本命名实体识别、 分词、 特征值建模、 特征优选、 分类、 聚类、 时序分析、 相关性分析等相关算法的研究, 并确定具体算法适配的业务问题. ② 基础算法工程化. 将算法进行验证并进行参数调优. 同时引入工程化思维对业务问题进行约束和限制, 来提升算法的准确度. ③ 可视化展示. 引入可视化工具等展示序列化、 谱图化的检索结果. ④ 基于知识图谱进行展示, 对检索的关键词的相关领域进行谱图化展示, 以预测用户感兴趣的内容. 当用户点击相关词汇时展示二次检索结果. ⑤ 基于时间序列算法进行展示. 对检索结果按照时间序列的方式展示关键词命中的文档, 类似于大事记、 个人相册、 个人说说等展示形式.
3) 自动推送. 自动推送实现了主动式检索向被动式检索的转变, 改变了以往用户向系统主动发起请求的模式, 是系统智能化搜索的重要体现. 包括: I)实时信息推送, 系统通过用户订阅的信息或当前焦点信息进行推送, 通过统计搜索词频, 对热点信息进行推送, 推送信息可选择门户消息或邮件等形式; II)通过分类、 聚类算法, 对内容过滤且直接分析内容并对同类数据进行推荐; III)通过协同过滤算法进行系统自动推荐, 即找到指定的相似(兴趣)用户, 综合对某一非结构化数据的相似性浏览、 查询记录, 形成用户对该指定信息的喜好程度预测; IV)通过对浏览轨迹、 收藏行为、 检索行为以及关注行为等信息做忠实的记录, 并综合用户个人信息建立用户兴趣域模型, 根据用户兴趣域模型预测; V)根据用户身份进行自动推荐, 即获取用户所在岗位、 业务专长、 个人信息等数据, 判断用户可能对哪些文档感兴趣, 并进行推荐; VI)根据业务关联进行自动推荐, 即依据业务建模梳理的业务关系, 对文档业务元数据建立语义关联, 当用户检索某篇文档时, 依据此关系网给出相关推荐.
4 结语
综上所述, 将相关技术和理论引入非结构化数据特征模型的应用之中, 可以有效地解决网络大数据背景下的数据检索效率, 能够解决传统的非结构化数据模型的不足之处[22]. 与传统的数据模型进行对比, 能够更好地处理和解决具有海量特性的非结构数据, 尤其是对于无法准确表达和处理的非结构化数据来说, 效果则更加明显, 从整体上提高数据检索的速度和效率, 从而进一步满足客户的实际需求. 同时异构数据在非结构化数据中占据非常重要的地位, 有效地解决了非结构化数据特征建模的效率. 因此, 研究异构数据技术对数据研究十分重要.
参考文献:
[1] 董丽. 基于XML与中间件的异构数据源整合系统的设计与实现[D]. 武汉: 武汉科技大学, 2005.
[2] 姚丹丹. 面向旅游安全的地质灾害数据协同服务技术架构研究[D]. 成都: 成都理工大学, 2016.
[3] 张瑞斌. 基于SOA的异构数据源统一检索系统的设计与实现[D]. 武汉: 华中师范大学, 2008.
[4] 田万鹏, 王建民. 一种基于特征的非结构化数据演化管理建模框架[J]. 计算机研究与发展, 2010, 47(增1): 394-399.
[5] YUN H. Important developments for the digital library: data ocean and smart library[J]. Journal of Zhejiang University-Science C: Computer and Electronics, 2010, 11(11): 835-836.
[6] XIAO C, WANG W, LIN X,etal. Efficient similarity joins for near duplicate detection[J]. International Conference on World Wide Web , 2008, 36(3): 131-140.
[7] ZHANG J, WANG J, LI D,etal. A new heuristic reduct algorithm base on rough sets theory[C]// Proceeding of the 4th International Conference on Advances in Web-Age Information Management. Chengdu: [s.n.], 2003: 247-253.
[8] 郎波, 张博宇. 面向大数据的非结构化数据管理平台关键技术[J]. 信息技术与标准化, 2013, 346(10): 53-56.
[9] WANG L Z, TAO J, RANJAN R,etal. G-Hadoop: MapReduce across distributed data centers for data-intensive computing[J]. Future Generation Computer Systems, 2013, 29(3): 739-750.
[10] 吴纯青, 任沛阁, 王小峰. 信息网络中海量异构数据的组织搜索技术研究[C]// 中国互联网学术年会. 张家界: 中国计算机学会, 2013: 225-239.
[11] 赵晓昱. 物联网中基于用户信息的检索技术的研究[D]. 沈阳: 辽宁大学, 2014.
[12] 胡凯. 海量异构数据搜索的研究与实现[D]. 北京: 北京邮电大学, 2013.
[13] 邓振国, 贾宏, 柳寒冰, 等. 一种异构海量数据搜索方案[J]. 计算机与现代化, 2014, 221(1): 121-125.
[14] 王玮, 苏琦, 刘荫, 等. 基于云存储的异构海量数据搜索平台设计[J]. 信息技术, 2017(6): 166-169 .
[15] 徐凯. 智慧高速海量异构数据处理关键技术研究[D]. 重庆: 重庆交通大学, 2016.
[16] 王鸿蒙. 海量异构数据集成系统的设计与实现[D]. 北京: 北京邮电大学, 2010.
[17] 郝豫鲁. 基于海量异构数据处理的人口信息决策支持系统设计与实现[D]. 北京: 北京邮电大学, 2011.
[18] 吴纯青, 任沛阁, 王小峰. 基于语义的网络大数据组织与搜索[J]. 计算机学报, 2015, 38(1): 1-17.
[19] WU C Q, REN P G, WANG X F. Survey on semantic-based organization and search technologies for network big data[J]. Chinese Journal of Computers, 2015, 38: 1-17.
[20] XU Z, LIU Y, MEI L,etal. Semantic based representing and organizing surveillance big data using video structural description technology[J]. Journal of Systems and Software, 2015, 102(C): 217-225.
[21] 顾君忠, 陈民. 基于大数据分析的智能搜索引擎[J]. 软件产业与工程, 2015, 31(1): 25-29.
[22] 徐冰. 面向海量异构历史数据查询的索引管理系统[D]. 哈尔滨: 哈尔滨工业大学, 2013.
