一种基于关联规则的网络软件缺陷预测方法
2018-05-23赵正伟
胡 柳,邓 杰,赵正伟,李 瑞
(1. 湖南信息职业技术学院 计算机工程学院,湖南 长沙 410200; 2.广西民族大学 信息科学与工程学院,广西 南宁 530006;3. 河北省眼科医院 信息科,河北 邢台 054000)
0 引言
随着信息技术和网络技术的发展,软件复杂程度不断提高,软件规模由单一的本地软件逐渐演化成为网络化软件,软件缺陷影响着人们生活的方方面面。良好的软件缺陷控制和预测机制可以帮助企业开发出高质量的软件产品,防止软件因系统缺陷而导致的严重后果,降低软件维护成本,并提高客户满意度。因此,软件开发过程和软件质量越来越受到重视,如何预测网络化软件系统缺陷成为当前研究的热点领域。
目前,国内外软件缺陷研究领域相关学者进行了深入的研究并取得了一系列的成果。主流的方法有基于统计分析学方法、基于神经网络的软件缺陷预测模型等。傅艺绮等人[1]提出了一种基于组合机器学习算法的软件缺陷预测模型,利用机器学习算法在不同评价指标上的不同优势,结合stacking集成学习方法提出将不同预测算法的预测结果作为软件度量并进行再次预测。熊婧等人[2]将Adaboost算法原理通过训练多个弱分类器构成一个更强的级联分类器,通过采用美国国家航空航天局(NASA)的软件缺陷数据库进行仿真实验,有效地提高了软件缺陷预测模型的预测性能。程铭等人[3]提出一种加权贝叶斯迁移学习算法,通过收集训练数据和测试数据的特征信息并计算特征差异,将不同项目数据之间差异转化为训练数据权重,并建立预测模型,在8个开源项目数据集上进行实验。张德平等人[4]借鉴Granger检验思想,利用GMDH网络选择与软件失效具有因果关系的度量指标,建立软件缺陷预测模型,并通过两组真实软件失效数据集,将所提出的方法与其他方法进行比较分析。马振宇等人[5]在BP算法建立模型的基础上,使用SC-PSO算法优化BP的参数值,通过十折交叉的方法对结果展开分析,结果表明该方法对软件缺陷预测有更大的帮助。
在软件缺陷预测研究中,针对软件缺陷数据具有代价敏感性且软件度量取值为连续值的特点,李伟湋等人[6]提出基于领域三支决策粗糙集模型的软件缺陷预测方法。针对软件代码背后隐藏的不同技术方面和主题问题导致的软件缺陷,张泽涛等人[7]提出一种基于主题模型的软件缺陷预测技术。针对软件可靠性预测模型在现实环境中的应用问题,李东林等人[8]对软件可靠性数据预处理进行了研究,蒋永辉等人[9]提出了软件过程的软件可靠性预测运作模型。
针对网络化软件缺陷预测中缺陷之间的显性关联关系和隐性关联关系,本文提出一种基于关联规则的网络软件缺陷预测方法。关联规则算法广泛应用于商业、网络安全及移动通信领域,通过对数据的关联性进行分析和挖掘,开展决策过程。本文将结合NASA的软件缺陷数据库进行仿真实验。
1 网络软件缺陷预测
1.1 网络软件缺陷预测存在的问题
网络软件缺陷预测中,由于数据分布、数据特征和软件质量等问题导致预测算法或模型难以在现实软件中进行有效的预测,而网络软件测试过程的数据包括有效数据样本和失效数据样本,在网络软件缺陷预测中如何有效利用失效数据进行预测才是重点。
目前,软件缺陷预测用到的主要方法和技术有神经网络算法、贝叶斯网络、机器学习法、支持向量机、主题模型及迁移学习等。研究者利用这些方法进行了软件缺陷预测模型的设计,并取得了较好的效果。但这些传统的算法模型并未全面考虑影响软件质量和可靠性的各项不确定性因素,未能很好地描述软件内部的缺陷。为了寻求最佳的预测效果,在有效数据和失效数据的获取过程中应从软件静态和动态两方面同时获取,使得其样本数据总量能最大限度地支持精细化预测,降低预测偏差。因此,本文在基于关联规则的基础上,采用关联规则算法对网络化软件缺陷预测方法进行分析与建模,以寻求获取较好的缺陷预测结果。
1.2 网络软件缺陷预测架构
网络软件缺陷预测模型的架构分为缺陷数据采集、缺陷数据预处理、引入预测算法、预测模型构建或训练、预测模型测试与验证五个部分,其模型框架如图1所示。
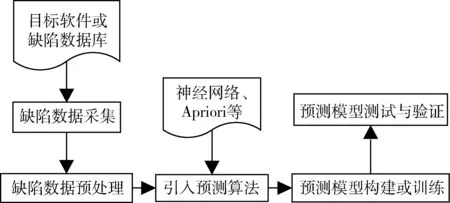
图1 网络软件缺陷预测架构
通过对目标软件的源代码或缺陷软件数据库中的样本进行采集,采用归一化、消零、权重处理、去重等数据预处理操作,引入关联规则算法对样本数据进行有效性计算,并生成预测模型,在算法中不断尝试参数值以获取最优的结果,最后对软件模块进行缺陷预测。
2 关联规则及关联分类器
2.1 关联分类法
关联分类法(CBA)结合了分类规则和关联规则的挖掘,支持将非监督学习方法用于监督分类,其任务是挖掘出用于区分实例类的关联规则,即分类的关联规则(CARs)。CARs能够反映出数据的描述性关联特性和可用于分类的特征。如关联规则X=>Y,其中X为前置事件,表示数据描述性关联规则,Y为后置事件,表示分类特征。如“respect>0.5127 or avg>0.2563=>result=1”中,前置事件为“respect>0.5127 or avg>0.2563”,后置事件为“result=1”。
CBA的基本过程为:
(1)数据的离散化处理。
(2)获取关联分类规则CARs。
(3)采用分类器构建算法构造分类器。
(4)利用构造的分类器开展实验研究。
2.2 关联规则生成算法
关联规则的生成算法可融入Apriori算法或FP-Tree算法,生成一系列由置信度c和支持度s的规则集合,前置的相关定理如下:
定理1 设X,Y是数据集中的项目集,如果X∈Y,则s(X)≥s(Y),且Y为大项目集时,X也为大项目集。其中s表示支持度。
定理2 强规则X=>Y对应的项目集(X∪Y)也一定是大项目集。
定理3 若R为大项目集,ē和e为其子集,ē∈e∈Y,则c(ē=>(L—ē))≤c(e=>(L—e))。其中c表示置信度。
关联规则的生成算法如下:
While所有k个项目的大项目集Lk(k≥2)
Hi={lastrs(Lk)}
Call fn{Lk,Hi}
I++
Wend
Procedure fn(Lk:k个项目的大项目集,Hm:m个项目的结论集)
Whilehm+1∈Hm+1
C=s(lk)/s(lk-hm+1)
Ifc≥mincthen
Print rule(lk-hm+1)=>hm+1,置信度=c,支持度=s(lk)
Else
Delhm+1
End if
Wend
通过遍历大项目集中的数据记录,对每一个记录进行关联规则的计算,最终形成结论集rule,以用于后期的分类关联规则生成。
2.3 分类器的构建
对于2.2节所得到的结论集,需要选择最小误差规则来构建分类器,如果某两条记录值的置信度c和支持度s符合下述条件:{c(a)>c(b)}或c(a)=c(b) ands(a)>s(b)或c(a)=c(b) ands(a)=s(b) andt(a)>t(b)},其中t(a)为记录产生的时间,则称a的优先级大于b。分类器的构建采用优先级较高的覆盖原有的数据集。
分类器构建算法步骤:
(1)将规则集中的规则按优先级排序,sort(Lk)。
(2)选择满足条件的规则集构建分类器,crea(Li∈Lk),其中Li满足优先级较高的条件。
(3)移除噪声记录clear(Li),参数Li指对提高分类精度无作用的记录。
3 实验过程
3.1 实验准备
为了验证基于关联规则及其算法在网络化软件缺陷预测中的应用有效性,缺陷数据集选用NASA的软件质量度量数据库。该数据库的数据集通过采集实际软件项目中的代码和运行质量过程而得到,每一条样本记录对应于软件功能模块的内部指标属性值。目前,多数软件缺陷预测模型使用该数据库,且对记录集进行了人工层面的筛选,以获取最优的预测效果。
实验环境为双核2.8 GHz CPU,内存4 GB,操作系统为Windows 7,平台软件为Eclipse 3.4、MATLAB 7.0。
通过对NASA的软件质量度量数据库记录进行有效性选择后,样本数据如表1所示。
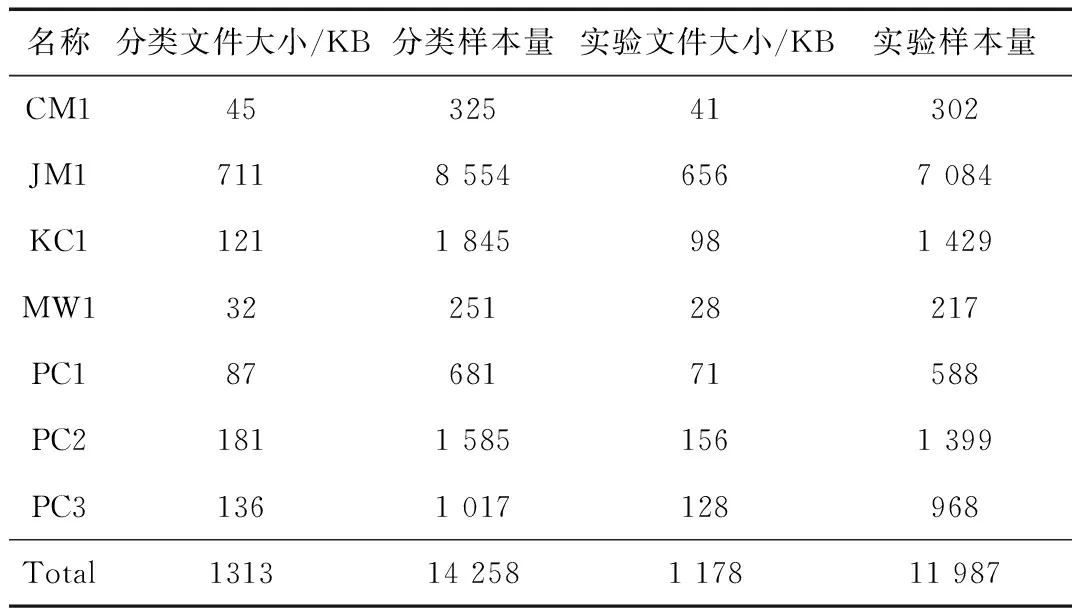
表1 样本数据集
3.2 评价标准
对于分类模型,本文采用传统的分类器性能评价指标:精确度、召回率和平均F值。指标设计为基于二分类数据集的混合矩阵,如表2所示。

表2 指标混合矩阵
精确度表示预测正确的样本量与总样本的百分比,召回率表示预测正样本量与实际正样本量的百分比。
精确度:p=TP/(TP+FP)×100%
(1)
召回率:r=TP/(TP+FN)×100%
(2)
平均F值:F=(2×p×r)/(p+r)
(3)
3.3 实验结果与分析
本文采用随机选择方法采集NASA软件缺陷质量数据库中样本记录,共选取14 258个样本数据进行关联规则生成及分类规则生成、11 987个样本数据进行实验分类,以验证本文在网络化软件缺陷预测中的有效性,并与现有的BP神经网络法进行对比。关联规则算法直接利用Apriori算法进行数据挖掘及分类,依据支持度得出所有频繁项集,然后根据置信度产生关联规则,选择最小误差规则构建关联规则分类器,并对11 987个样本数据进行实验分类。
实验步骤如下:
(1)为了获取样本记录数据,采用随机方法对样本库中的记录进行提取。
(3)利用Apriori算法获取关联分类规则CARs。
(4)采用分类器构建算法构造分类器。
(5)实验分类。
为了获取构造分类器和实际分类时所消耗的时间,在程序设计中引入毫秒级时间记录量,采用关联规则方法对软件质量缺陷进行分类的结果如表3所示。
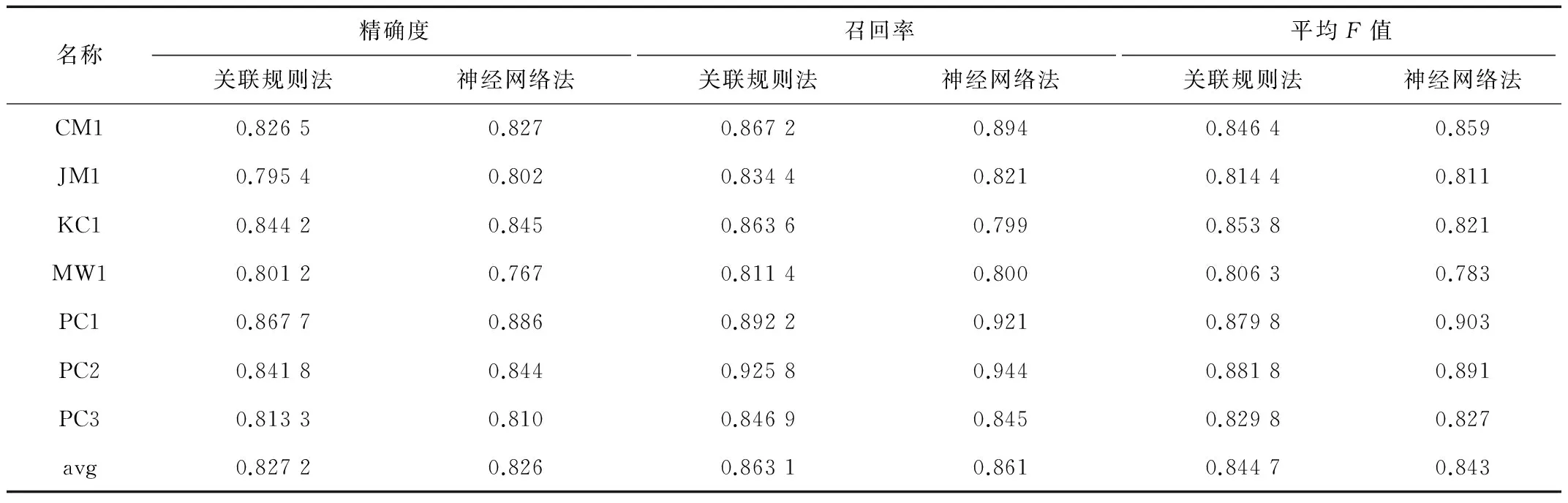
表3 基于关联规则的网络软件缺陷分析结果
从缺陷结果分析中可以发现,基于关联规则的网络软件缺陷预测方法在精确度和召回率上比传统的神经网络法略高,值得注意的是对于JM1、KC1、PC1等缺陷模块在精确度上比传统方法低,对于不同的样本选择和分类算法,在建立过程和统计上都存在一定的差异。
4 结论
本文提出了一种基于关联规则的网络软件缺陷预测方法,同时结合传统的神经网络方法对NASA软件缺陷数据库样本进行预测。从实验结果分析可以看出,在通用的缺陷预测条件下,关联规则法能有效提升预测的精确度,同时在召回率上也有一定的优势。本文创新地将关联规则方法应用于网络化软件缺陷预测中。由于样本数据选取的多样性,对软件缺陷的预测还需要有更多的分析模型进行全面的评估,以提高软件的质量。
参考文献
[1] 傅艺绮,董威,尹良泽,等.基于组合机器学习算法的软件缺陷预测模型[J].计算机研究与发展,2017,53(3):633-641.
[2] 熊婧,高岩,王雅瑜. 基于adaboost算法的软件缺陷预测模型[J].计算机科学,2016,43(7):186-190.
[3] 程铭,母国庆,袁梦霆. 基于迁移学习的软件缺陷预测[J].电子学报,2016,44(1):115-122.
[4] 张德平,刘国强,张柯. 基于GMDH因果关系的软件缺陷预测模型[J].计算机科学,2016,43(7):171-176.
[5] 马振宇,张威,毕学军,等. 基于优化PSO-BP算法的软件缺陷预测模型[J].计算机工程与设计,2016,37(2):413-417.
[6] 李伟湋,郭鸿昌.基于邻域三支决策粗糙集模型的软件缺陷预测方法[J].数据采集与处理,2017,32(1):166-174.
[7] 张泽涛,叶立军,程伟,等.一种基于主题模型的软件缺陷预测技术研究[J]计算机工程与科学,2016,38(5):932-937.
[8] 李东林,徐燕凌,蒋心怡.软件可靠性数据预处理研究[J].电子技术应用,2010,36(8):153-156.
[9] 蒋永辉,吴洪丽,王政霞.基于软件过程的软件可靠性预测运作模型[J].微型机与应用,2010,29(6):3-6.
