医疗大数据平台数据高并发方案设计与关键技术分析
2018-05-23张伟
张 伟
(中国大唐集团科学技术研究院有限公司,北京 100040)
0 引言
中国人口老龄化加速、慢性病人数剧增以及社会生活水平的提高,人们对医疗服务的需求越来越高,同时医疗资源紧缺且分配不均,供需矛盾日益凸显,利用信息化手段提高医疗行业的服务范围和服务水平已经迫在眉睫。
医疗大数据平台是通过使用移动通信技术(例如 IPDA、移动电话和卫星通信)来提供医疗服务和信息。随着全球智能手机和新型创新连接设备普及率的日渐提高以及移动宽带网络和服务的拓展,医疗大数据平台无疑将在未来的医疗健康行业发挥重要作用。移动互联网、物联网等相关技术与预防及临床医学相结合,可以为广大民众提供随时随地的健康关爱服务。可以说医疗大数据平台的出现给整个医疗健康行业带来了前所未有的新体验,也促使着医疗健康行业面向信息化、移动化的方向发展。
医疗大数据应用是典型的面向互联网大众用户应用,因此大数据量和高并发的要求比较高。集群技术和负载均衡技术作为业界通用的高并发解决技术会有广泛的用武之地,但这些技术相对来说在开发、部署、运维等方面需要较高的人工成本和技术门槛。近年随着互联网技术的飞速发展,针对系统的高并发问题,涌现出越来越多的开源解决方案。这些解决方案在不同的行业应用中已经得到了生产环境的充分验证[1]。作为医疗业务应用来说,需要结合行业领域的数据和业务特点,有针对性地对技术进行选型。本文将结合作者近几年在移动健康业务系统开发领域的工作实践和对现阶段主流开源开发技术的应用,在对移动健康业务系统的数据和业务特点深入理解和分析的基础上,从开源技术角度对端到端的高并发问题详细描述技术选型和个人应用实践经验。
1 医疗大数据平台高并发需求分析
1.1 医疗大数据平台数据和业务特点
任何行业的互联网应用都面临着大数据和高并发的挑战,随着互联网技术的发展,针对高并发问题,业界各类互联网应用充分利用新兴互联网技术进行了非常有效的实践[2]。这些实践经验和技术成果对于我们开发移动健康业务系统有很好的借鉴意义。但同时也要看到,医疗大数据平台有自己特有的数据和业务特点,这些特点对我们解决高并发问题在技术选型上有重要的指导意义。医疗大数据平台的数据和业务特点如下:
(1)需要采集各种体征数据的医疗业务系统需要通过各类便携式终端采集用户的体征数据,如血压、血糖、心电、睡眠、运动情况等。业务系统基于这些信息提供各类业务功能给用户使用。移动健康业务系统需要解决好这些数据的高并发传输问题。
(2)数据库事务一致性需求。业务系统并不要求严格的数据库事务,对读一致性的要求很低,有些场合对写一致性要求也不高。因此数据库事务管理成了数据库高负载下一个沉重的负担。
(3)数据库的写实时性和读实时性需求。移动健康业务系统围绕体征数据展开各类业务流程,在对数据层的查询上一般是一次录入多次读取,相比其他业务系统如银行、网购等行业应用,业务系统在数据传输的实时性要求上也不需要太过苛刻。对关系数据库来说,插入一条数据之后立刻查询,可以很快读出来这条数据,但是对于移动健康业务系统来说,并不要求这么高的实时性。
(4)对复杂的SQL查询,特别是多表关联查询的需求。任何大数据量的Web系统,都非常忌讳多个大表的关联查询以及复杂的数据分析类型的复杂SQL报表查询,从需求以及产品设计角度,就避免了这种情况的产生。业务系统往往更多地只是单表的主键查询以及单表的简单条件分页查询,SQL的功能被极大地弱化了。
1.2 医疗大数据平台高并发需求
本小节对医疗大数据平台的体系架构进行简要描述,并对分层对高并发需求进行分析。医疗大数据平台典型体系架构如图1所示。
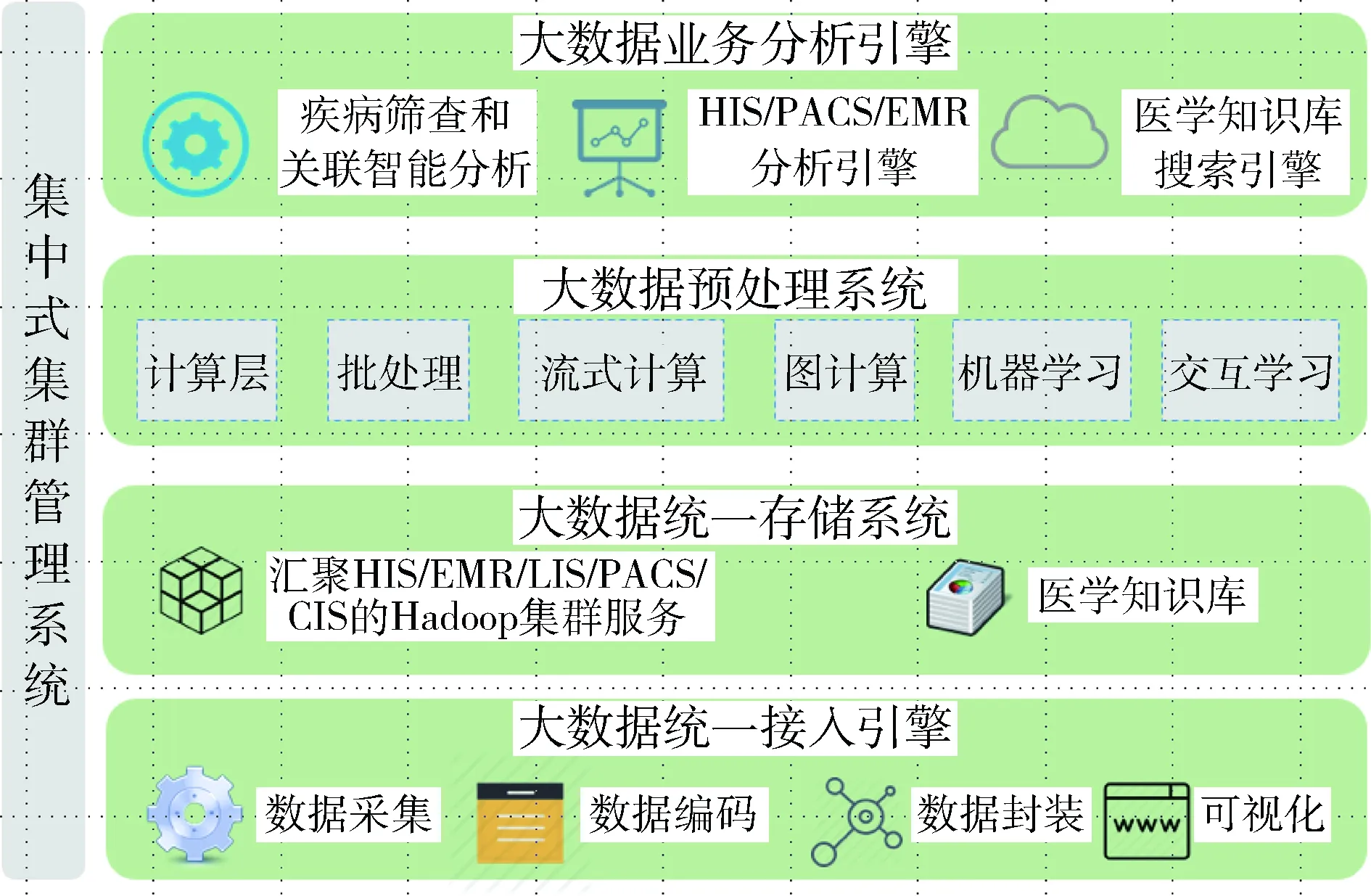
图1 移动健康业务系统架构图
图1中数据采集层、数据存储层、业务处理层是高并发问题最集中的三层,其高并发需求的详细分析如下:
(1)数据采集层:移动系统需求采集各类可穿戴设备的体征数据,这些设备包括计步器、血压计、血糖仪、手环、心电终端、智能手机等。从数据形式上来看,采集的体征数据有二进制格式和字符串格式,相应的数据采集层需要提供TCP/UDP或者HTTP协议的接口接收数据,并根据相应的权限对外开放查询接口供外部系统查询,或者传输数据到某个具体的业务应用。
本层的高并发主要在于数据量比较大。以计步器为例,不考虑重复上传和用户手动上传的情况,每个计步器每天需要自动定时上传5~6条简要包数据和24条分小时的详细包数据。这样算来,仅仅1万用户每天就需要上传近30万条计步数据,用户量大的时候,高并发需求凸显。
(2)数据存储层:数据存储层存储采集层接收到的各类体征数据以及业务处理层生成的各类业务数据,这些数据提供了数据挖掘和业务处理的支撑。数据量巨大是本层的主要特点。如果用户量比较大,在海量数据的基础上进行查询,数据存储层的查询效率将是一个很大的挑战,处理不好就会成为系统的性能瓶颈。
(3)业务处理层:业务处理层需要基于产品设计开发各类业务应用的访问接口,实现用户的各类业务需求。首先是海量用户的并发访问给业务处理层提出了挑战,需要充分利用良好的技术架构和缓存技术进行解决[3]。其次,业务处理层会有许多统计分析类功能,它们要在海量数据查询的基础之上进行大量耗时比较长的复杂运算,这些功能需要充分利用分布式并行技术提高运算效率。
2 医疗大数据平台高并发解决方案
2.1 数据采集层
2.1.1二进制数据接收
二进制数据需要通过TCP/UDP协议传输,通常的做法是利用socket编程来实现。然而不管采用TCP还是UDP协议的socket编程,可穿戴健康设备和数据采集层接口之间都是同步阻塞式 IO 的,每个传输由单独的线程实现。虽然可以通过多线程实现同时接收多个客户端数据,但随着并发量的增大,服务器开启的线程数目会增多,将会消耗过多的服务器内存资源,导致服务器变慢甚至崩溃。因此在大量可穿戴健康设备连接数据采集层接口的时候,高并发问题会凸显出来,导致大量的传输连接请求被拒绝。
分析可穿戴健康设备上传的数据不难发现,单个客户端每次传输的数据并不大,需要的链接时间很小,但并发量比较大,非阻塞式IO传输正适合此类型的数据传输。作为TCP/UDP 协议级别的非阻塞式IO传输,目前比较流行的开源框架有Netty和Mina框架。这两个框架都是由同一个人开创的,在设计理念等方面比较类似,并发性能上都可以满足实际需求。
下面以 Mina 为例简述一下此开源技术是如何解决高并发问题的。Apache Mina 是一个网络通信应用框架,它主要是针对基于TCP/ UDP协议栈的通信框架,Mina可以帮助我们快速开发高性能、高扩展性的网络通信应用,提供了事件驱动、异步操作的编程模型。Mina是介于用户业务和底层的socket之间的中间层,它简单易用,帮助实现下层的NIO处理细节,让开发者把关注点放在具体的业务实现上。
2.1.2字符串数据接收
作为字符串形式的数据接收,一般需要高层通信协议,比如SOAP、HTTP等,通常的架构设计是采用RPC方式,如图2所示。

图2 RPC方式交互数据图
如果使用RPC方式建立可穿戴设备和服务器的连接,由于可穿戴设备必须阻塞式的等待服务器返回数据处理结果,在高并发情况下将会严重影响执行效率和资源使用率,给服务器造成很大压力。
分析此类数据不难发现,可穿戴设备要把数据传输给服务器,只需要把相关信息封装到数据中,不需要关心服务器对数据的接收处理细节,因此为了提高并发能力,需要采用图3所示松耦合的技术架构。
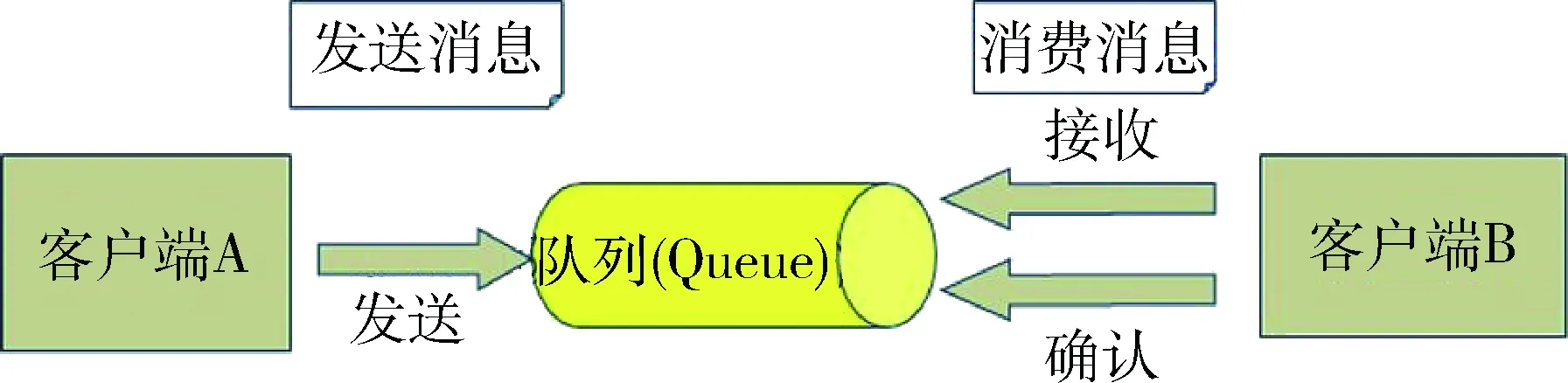
图3 消息队列方式交互数据图
客户端A向消息中介(Queue)发送一条消息,很可能一段时间之后,客户端B调用Queue来收取消息。任何一个应用程序都不知道对方是否存在,也不需要阻塞等待。这种通信方式大大缩减了维护开销,而且对于一个应用程序的修改对其他应用程序影响极小。基于这种松耦合的消息方式的开源技术有很多,比如ActiveMQ、RabbitMQ、ZeroMQ等。
以ActiveMQ为例,它是一种开源的实现了JMS1.1规范的面向消息的中间件,为应用程序提供高效、可扩展、稳定和安全的企业级消息通信。它支持两种截然不同的消息传送模型:PTP(即点对点模型)和Pub/Sub(即发布/订阅模型,并且可以持久化数据,保障数据的安全性)。
2.2 数据存储层
移动健康业务系统作为一个基于大数据高并发的互联网产品,数据存储层的选择非常关键,如何保障对业务处理层的高并发的数据支持是核心问题。目前数据存储层主要有关系型数据库和 NOSQL 数据库。下面将对两种数据库技术的优缺点以及使用注意事项等进行分析并给出实践经验。
2.2.1关系型数据库
关系型数据库已经在信息系统开发领域被使用多年,它基于标准SQL语句实现了灵活的数据增、删、查、改、统计等操作,并提供了良好的事务处理机制[4]。用的比较多的关系型数据库有Oracle、SQL Server、MySQL等。在数据量比较大的时候,虽然数据库提供了分区、索引等技术提高查询效率,但性能上还是很难满足互联网业务系统的高并发要求。
在关系型数据库支撑高并发方面,需要充分使用好分区、索引、集群等技术。阿里巴巴公司对MySQL的使用非常成功,他们充分利用MySQL的集群技术形成了大型关系数据库集群,并开发了数据库和应用层之间的中间层,为应用层屏蔽了数据库层的复杂性。相对来说,关系型数据库的性能优化对技术的要求比较高,要做到大型关系型数据库集群是比较难的。在移动健康业务系统建设初期,用户量还不多,并发要求还不太高,为了快速开发上线系统,这时候可以优先采用关系型数据库。另外需要处理对于事务性要求比较高的业务时需要采用关系型数据库。
2.2.2非关系型数据库
随着互联网Web2.0网站的兴起,非关系型的数据库现在成了一个极其热门的新领域,非关系数据库产品的发展非常迅速,而传统的关系型数据库在应付Web2.0网站,特别是超大规模和高并发的Web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题。作为移动健康业务系统也是如此。
(1)对数据库高并发读写的需求
因需要根据用户个性化信息来实时生成动态页面和提供动态信息,所以基本上无法使用动态页面静态化技术,因此数据库并发负载非常高,往往要达到每秒上万次读写请求。关系型数据库应付上万次SQL查询还勉强顶得住,但是应付上万次SQL写数据请求,硬盘 IO 就已经无法承受了。
(2)对海量数据的高效率存储和访问的需求
对于大型网站,每天用户产生海量的用户动态信息,以国外的Friend Feed为例,一个月就达到了2.5亿条用户动态数据,对于关系数据库来说,在一张具有2.5 亿条记录的表里面进行SQL查询,效率是极其低下乃至不可忍受的。再例如大型Web网站的用户登录系统,例如腾讯、盛大,动辄数以亿计的账号,关系数据库也很难应付。
(3)对数据库的高可扩展性和高可用性的需求
在基于Web的架构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库却没有办法像Web server和app server那样简单地通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供 24 小时不间断服务的网站,它们对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移,使得公司业务中断,造成经济损失。
以上提到的“三高”需求是关系数据库难以克服的障碍,对于移动健康业务系统,关系数据库很难满足这些应用需求。而NOSQL数据库是近些年随着大数据技术的广泛应用发展起来的,因其易于扩展、大数据量高并发、高可用性等优势,目前已被知名的互联网公司广泛使用。例如,列存储数据库HBase、文档型数据库MongoDB、CouchDB,key-value数据库MemcacheDB、Redis等。
文档型数据库MongoDB可以说是最像关系型数据库的 NOSQL 数据库,甚至可以从搜索网站上搜索到MongoDB和常用标准SQL的对应关系。因此本文重点推荐存储层用MongoDB 数据库。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富、最像关系数据库的。它支持的数据结构非常松散,类似JSON的BJSON格式,因此可以存储比较复杂的数据类型。MongoDB最大的特点是支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的所有功能,而且还支持对数据建立索引。它是一个面向集合的模式自由的文档型数据库。MongoDB 主要功能如下:
(1)完整的索引支持:包括文档内嵌对象及数组。MongoDB 的查询优化器会分析查询表达式,并生成一个高效的查询计划。
(2)复制及自动故障转移:MongoDB 数据库支持服务器之间的数据复制,支持主-从模式及服务器之间的相互复制。复制的主要目标是提供冗余及自动故障转移。
(3)高效的传统存储方式:支持二进制数据及大型对象(如照片或图片) 。
(4)自动分片和副本集技术支持云级别的伸缩性:自动分片功能支持水平的数据库集群,可动态添加额外的机器。
2.3 业务处理层
2.3.1数据缓存的使用
数据缓存技术是解决 Web 应用程序可扩展性、数据响应及时性以及减轻服务器负载、降低网络拥塞的主要手段之一。最常用的场景如下:
(1)缓存数据库的查询结果,减少数据的压力。
(2)缓存磁盘文件的数据。常用的数据可以放到内存,不用每次都去读取磁盘,特别是密集计算的程序,比如中文分词的词库。
(3)缓存某个耗时的计算操作,比如数据统计。
目前流行的应用层缓存技术有Squid、Varnish、nginx等,本文重点推荐内存数据库 Redis。Redis数据库中的所有数据都存储在内存中。由于内存的读写速度远快于硬盘,因此 Redis在性能上对比其他基于硬盘存储的数据库有非常明显的优势,在一台普通的笔记本电脑上,Redis可以在一秒内读写超过十万个键值。不过,将数据存储在内存中也有问题,例如,程序退出后内存中的数据会丢失。为解决这个问题,Redis将可以内存中的数据异步写入到硬盘中,同时不影响继续提供服务。
Redis可以为每个键设置生存时间,生存时间到期后键会自动被删除。这一功能配合出色的性能让Redis可以作为缓存系统来使用,而且由于Redis支持持久化和丰富的数据类型,使其成为了另一个非常流行的缓存系统Memcached的有力竞争者。
作为缓存系统,Redis 还可以限定数据占用的最大内存空间,在数据达到空间限制后可以按照一定的规则自动淘汰不需要的键。
此外,Redis的列表类型键可以用来实现队列,并且支持阻塞式读取,可以很容易地实现一个高性能的优先级队列。同时在更高层面上,Redis 还支持“发布/订阅”的消息模式。
Redis 提供了几十种不同编程语言的客户端库,这些库都很好地封装了Redis的命令,使得在程序中与Redis进行交互变得更容易。有些库还提供了可以将编程语言中的数据类型直接以相应的形式存储到Redis中(如将数组直接以列表类型存入 Redis)的简单方法,使用起来非常方便。
Redis支持五种的数据类型,针对移动健康业务系统来分析这五种类型的应用场景如下:
(1)字符串类型:每一行对应一个key,value值存可以统一存取的序列号的对象值(链表或散列存更方便),如文章阅读量等数据。
(2)散列类型:每行对应一个key,value值类似一个map
(3)链表类型:适合缓存实现链表和堆栈效果的数据,比如实现分页、限制某个IP的访问频率等功能比较方便。
(4)集合类型:适合缓存无顺序要求,并需要执行并、交、差等集合操作的数据,如页面的标签类型等信息。
(5)有序集合类型:适合缓存有顺序要求,而且需要执行集合操作的数据。
2.3.2并行计算技术的使用
在移动健康业务系统中难免有需要处理耗时较长的各类统计分析操作,为提高此类功能的运行效率,可以采用并行计算技术,如MapReduce。
MapReduce是一种编程模型,用于大规模数据集(大于1 TB)的并行运算。概念“Map(映射)”和“Reduce(归约)”是它的主要思想。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上[5]。当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
3 结论
医疗健康大数据和个人密切相关,其安全和隐私保护问题从保障技术和管理制度两方面都显得尤为重要。未来医疗大数据处理可以基于云计算平台实现,作为云计算平台的一种服务。基于云计算平台的开发和应用使得很多数据被存储在云端进行处理、查询和搜索[6]。因此,除了要解决医疗大数据搜索的可扩展性、可靠性和效率外,必须考虑数据搜索和使用的安全和隐私问题。
参考文献
[1] 刘智慧,张泉灵.大数据技术研究综述[J].浙江大学学报(工学版),2014,48(6):957-972.
[2] 王艺,任淑霞.医疗大数据可视化研究综述[J].计算机科学与探索,2017,11(5):681-699.
[3] 马灿.国内外医疗大数据资源共享比较研究[J].情报资料工作,2016,37(3):63-67.
[4] 宋波,杨艳利,冯云霞.医疗大数据研究进展[J].转化医学杂志,2016,5(5):298-300.
[5] 魏建兵.基于云计算的医疗大数据系统架构研究[J].电脑知识与技术,2016,12(7):21-23.
[6] 孙艳秋,王甜宇,曹文聪. 基于云计算的医疗大数据的挖掘研究[J].计算机光盘软件与应用,2015 (2):11-11.
