基于多特征的静态软件胎记提取算法
2018-05-21王曙燕赵鹏飞孙家泽
王曙燕,赵鹏飞,孙家泽
(西安邮电大学 计算机学院,西安 710121)
0 引言
随着计算机技术及计算机网络的迅猛发展,软件已经成为日常生活中不可或缺的一部分,它不仅为生活带来了极大的便利而且为社会带来了数以亿万记的经济效益。然而软件作为一种数字产品在有着传输便利性的同时也为其版权保护带来了相当的难度,许多别有用心的人可以轻易地在网络上获得目标软件并且通过一些技术手段来将其破解并且以低廉的价格再发行出去,为软件的开发者带来重大损失。
程序胎记(BirthMark)这一概念较早是在由剑桥大学出版社出版的《程序识别》[1]一书中提到的。软件胎记之所以被称为“胎记”,是指在程序中一些“与生俱来”的东西,即使经过了软件混淆或加密也会保持不变的东西。
而静态软件胎记提取技术与其他软件抄袭检测和软件保护技术相比主要有以下两点优势:第一,其技术主要是对源码或中间码进行分析而无需额外插入任何代码,减少人为插入代码导致程序被恶意分析的可能性;第二,与动态提取软件胎记技术相比,这种方法可以更全面地覆盖软件的执行路径,而动态执行通常只能覆盖软件的一部分执行路径,增强了胎记的可信度,并且若软件需要频繁交互,提取动态胎记所花费的时间与用户体验代价要比静态胎记大得多。这两方面的优势使静态软件胎记技术在盗版检测、代码抄袭等方面更具有实用性。
通过程序胎记进行抄袭检测主要可分为两个步骤:第一步从程序中提取某些特征形成胎记;第二步通过比较两个胎记来确定程序之间是否存在抄袭行为。文献[2]提出了一种使用k-gram算法得到软件胎记的算法,这种算法使用软件的指令序列作为胎记提取的特征,首先提取Java程序中的字节码指令序列,随后使用k-gram算法对字节码指令序列进行分割形成胎记,通过对这种胎记的对比来确定两软件之间是否存在抄袭行为;文献[3]研究了利用程序的应用程序接口(Application Programming Interface, API)生成软件胎记,通过提取不同层级包、类、方法的API调用形成API调用流图和调用序列进而生成软件胎记。
然而,以上方法存在以下两个缺陷:1)使用k-gram算法产生的静态软件胎记的弹性较弱,因为该算法对软件指令序列是机械切割分片的,所以由这种算法产生的胎记存在严重的语义丢失,导致其弹性弱。2)使用程序调用的API生成软件胎记可信性较弱,由于这种胎记仅由程序的API特征生成,没有考虑多特征,故而该胎记的可信性较弱,并且这种胎记也需要考虑源程序与待测程序之间是否是同一系统平台编写,故也存在一定的局限性。
文献[4]研究了一种基于系统函数调用频率与指令基本块的软件胎记的方法,并且验证了其效果不弱于传统的k-gram胎记,说明了使用多特征生成软件胎记是可行的。
本文采用一种新的算法生成软件胎记,可以克服原有程序胎记的缺点。在从程序中提取胎记时,综合了API和指令序列两方面特征,使提取到的胎记可信性比原有胎记更强,并且在提取软件的指令序列特征使用了最长公共子串(Longest Common SubString, LCS)算法,使胎记的弹性比使用k-gram算法提取的胎记更强。
1 预备知识
一个完整的软件对比程序主要使用以下两个公式[5]:
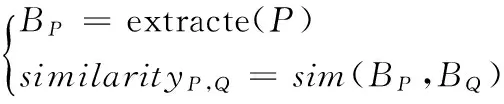
(1)
其中:extracte是软件胎记提取公式;BP表示程序P的胎记,由程序P通过特征提取函数所得到的。sim是两软件胎记的相似度计算公式[6],程序P和程序Q之间的相似度则需要通过对比BP和BQ来得到。
1.1 软件胎记的可信性和弹性
衡量一个软件胎记的好坏有以下两个标准。定义[2,7]如下:
定义1 软件胎记的弹性。令P′表示对P使用语义保留的混淆技术生成的派生程序,BP为P的胎记,BP′为P′的胎记,sim()表示胎记的相似性计算函数,如果sim(BP,BP′)≥1-θ,则表明该软件胎记具有很好的弹性,其中θ表示相似性阈值。
定义2 软件胎记的可信性。令P和Q表示两个完全独立的软件,如果sim(BP,BQ)<θ,则表明称该软件胎记具有很好的可信性。
1.2 最长公共子串算法。
为了方便说明算法,以下使用字符串来举例,假定有两个字符串A和B:
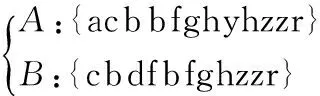
可发现其中有3个相同的长度大于1的字串。

表1 串A与串B的所有公共子串Tab. 1 All common substrings of string A and B
根据文献[8-9]提出的一种计算最长公共子串的算法,对算法步骤描述如下:
记字符串A的长度为l1,字符串B的长度为l2,构建一个规模为l1×l2的矩阵,矩阵的值按照以下两条规则填写:
规则1 若矩阵该元素对应位置上两字符不相同,则置矩阵元素值为0。
规则2 若矩阵元素对应位置上两字符相同,且不在第一行、列上,则矩阵该元素值为其左上角元素值加1;若在第一行、列上,则将该元素值置为1。
按照以上规则填充矩阵,得到记录了串比较信息的矩阵(图1)。
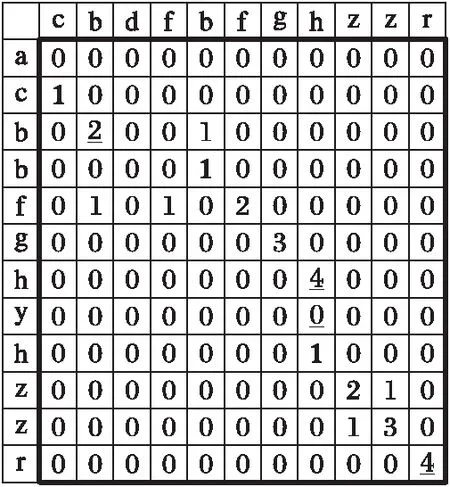
图1 LCS算法动态规划矩阵 Fig. 1 Dynamic planning matrix generated by LCS algorithm
其中2,4,4三个数字表明了公共子串的长度,而从这三个元素出发向其左上角一直追溯到元素值为1的元素的横纵坐标表明了这个公共子串在串A和串B中的起始位置。
1.3 k-gram软件胎记提取算法。
k-gram软件胎记(StaticK-gram Birthmark, SKB)提取算法最早是受到自然语言处理中n-gram算法[10]的启发而产生的算法,其定义[11]如下:
定义3k-gram碎片集。记A={a1,a2,…,an}是一个序列,(aj+1,aj+2,…,aj+k)是A中的一个k-gram碎片,则序列A的k-gram碎片集记为seg(A,k)={(aj+1,aj+2,…,aj+k)|0≤j≤n-k},其中k为k-gram算法中滑动窗口的长度。
定义4 SKB。记p为一个程序,A(p)为p的操作码序列,那么p的静态k-gram胎记为SKB(p,k)=seg(A(p),k)。
提取一个k-gram胎记的步骤为:
步骤1 提取程序中的操作码序列;
步骤2 对操作码序列进行k-gram分割得到长度为k的操作码子序列,称为k-gram碎片;
步骤3 将程序中k-gram 碎片的集合作为软件胎记。
例如,对于Java程序字节码指令序列{aload_0,iload_1,invokevirtual,aload_0,invokevirtual,return},其k-gram胎记中k取值为3时软件胎记为:
{(aload_0,iload_1,invokevirtual),(iload_1,invokevirtual,aload_0),(invokevirtual,aload_0,invokevirtual),(aload_0,invokevirtual,return)}
当我们计算两个k-gram胎记的相似度时,其公式如下:


2 基于多特征的静态软件胎记提取算法
一个程序P可以提取的特征包括:API调用集合、程序控制流结构、程序指令序列、程序调用栈依赖关系等,在使用extracte函数时可以选择提取其中的某些特征,本文所用的程序胎记的特征包含程序指令序列和API调用集合。
程序实质上是对数据的处理和变换,而一个程序的语义就体现在对数据的处理过程中,通过分析程序的指令序列,就可以很好地把握程序的功能和语义。而在现代软件开发中,几乎所有的程序都需要调用底层或其他人开发的程序,通过分析程序的API调用,可以快速地模糊定性一个程序的功用,这一点在大型的开发软件中体现得尤为明显。而想要通过分析程序的控制流结构或栈依赖关系来确定两个程序是否相似时,不可避免地要用到图或树的对比算法,而这一类算法的时间复杂度是指数级的。
针对现有软件胎记可信性弱、弹性弱的特点,本文提出一种新的软件胎记提取算法。该算法首先将程序进行分析得到程序元信息,通过元信息提取程序的API调用集合和指令序列,再将API调用集合和指令序列作为输出生成程序的程序胎记。通过构建比较模型,将源程序与可疑程序的程序胎记进行对比得到两程序胎记之间的相似度,根据相似度判断源程序与可疑程序之间是否存在抄袭行为。由以上算法提取的胎记记为多特征胎记(Multiple Feature Birthmark, MFB)。

图2 融合双特征的软件胎记生成与比较模型 Fig. 2 Dual-feature-birthmark generation and comparison model
使用软件胎记进行程序抄袭检测可分为两大步骤[12]。第一步是软件胎记的生成,而一个软件胎记的质量主要决定于如何对特征进行处理,针对不同的特征我们采用的特征提取算法是不同的,而对同一特征我们使用不同的提取算法提取出的胎记也是不同的。本文提出的多特征软件胎记提取算法主要对以前的胎记有以下两点改进;
一是本文在提取API和指令序列特征时都进行了解引用处理:对于API特征,若类A引用了类B,而类B引用了类C和D,那么类A的API特征不仅包含B,也会包含C和D。而对于指令序列特征;若一个方法MA的指令序列为a、b、c、d而b指令引用了方法MB,MB的指令序列为e、f、g,则最终MA的指令序列特征会被记录为a、b、e、f、g、c、d。
二是本文在构建软件胎记比较模型时没有使用k-gram算法而使用了LCS算法。使用k-gram算法比较两个指令序列时,是将两个指令序列进行机械固定粒度切割然后比较相同碎片在总碎片中的占比;而LCS算法因为是比较指令序列,存在语义关系,两个相同的片段保留了一定的语义信息。
2.1 Java程序的API特征提取
本文提出一种Java程序的API特征提取算法,描述如下:
步骤1 由用户在工程P中选定待提取特征的类C,设定迭代深度为d,建立集合SetAPI用于存储类C的引用类。
步骤2 找到类C除了本类和父类以外的所有引用类,将其添加至SetAPI中。
步骤3 遍历SetAPI中所有的项,记遍历过程中正在遍历的类为Ctemp,若Ctemp是一个在工程P中存在的类,则将Ctemp除了本类和父类以外的所有引用类添加至SetAPI中,并将其标记为已添加。遍历结束时d=d-1。
步骤4 重复步骤3,直到SetAPI中不存在未标记为已添加的类或d=0时,将SetAPI输出。
例如,在迭代深度为3时,对以下Java程序进行API特征提取。
class A {
public void function(int index) {
new B().function(index);
}
}
class B {
public double function(int index) {
return 1+
new C().function(index)/new D().function(index);
}
}
class C {
public long function(int index) {
return 2*index;
}
}
class D {
public long function(int index) {
return 3-index;
}
}
2.2 Java程序的指令序列特征提取
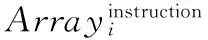
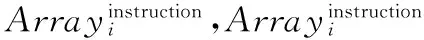
步骤3 重复步骤2,直到d=0或Arrayinstruction中任意一项的指令序列中都不包含指向工程P中存在的方法的指令时,将Arrayinstruction输出。
例如,图2中的类A,B,C,D中的function方法操作序列码分别为:
A.function(){new,dup,invokespecial,iload_1,invokevirtual,pop2,return}
B.function(){lconst_1,new,dup,invokespecial,iload_1,invokevirtual,new,dup,invokespecial,iload_1,invokevirtual,ldiv,ladd,l2d,dreturn}
C.function() {iconst_2,iload_1,imul,i2l,lreturn}
D.function() {iconst_3,iload_1,isub,i2l,lreturn}
在迭代深度为3时,最终得到类A中function方法的指令序列特征为:
public void A.function(int index) {
new,dup,invokespecial
void
//B的构造函数
aload_0,invokespecial,return
}
iload_1,invokevirtual
public double B.function(int index) {
lconst_1,new,dup,invokespecial
void
//C的构造函数
aload_0,invokespecial,return
}
iload_1,invokevirtual
public long C.function(int index) {
iconst_2,iload_1,imul,i2l,lreturn
}
new,dup,invokespecial
void
//D的构造函数
aload_0,invokespecial,return
}
iload_1,invokevirtual
public long D.function(int para1) {
iconst_3,iload_1,isub,i2l,lreturn
}
ldiv,ladd,l2d,dreturn
}
pop2,return
}
2.3 多特征胎记相似度计算方法
根据文献[13]提出的一种BP(Back Propagation)神经元输出模型,提出当待比较程序P和Q提取了n方面特征时,其相似度计算公式:
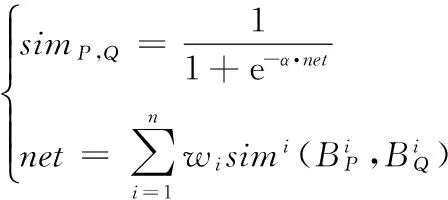
(2)
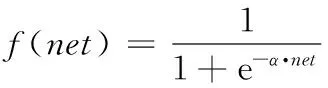
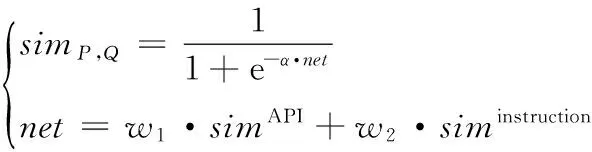
(3)
其中,API相似度的计算公式[14]为:
(4)
在比较两个程序胎记的指令序列特征时:
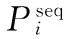
本文提出一种计算指令序列相似度的方法:
步骤1 用户输入本次处理的阈值为threshold,对源程序和可疑程序的指令序列,使用LCS算法寻找源程序和可疑程序的公共子串,将所有长度大于阈值的公共子串记录到集合Set中,其中Seti记录了一个子串的长度lengthi,其规模为n。
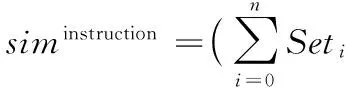

(5)
综上,最终得到比较两个提取了API和指令序列特征的软件胎记的比较公式:
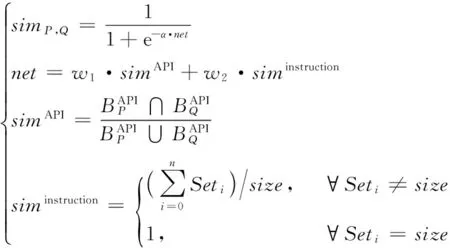
(6)
其中:w1,w2分别为相似度在API特征和在指令序列特征方面的权重。
2.4 根据软件胎记的相似度判定是否抄袭
检测程序P和程序Q是否存在盗版现象[15]步骤如下:

步骤3 设置检测阈值γ1、γ2,其中γ1>γ2。若simP,Q≥γ1,认为两程序之间是拷贝关系;若simP,Q≤γ2,认为两程序之间是独立开发;否则将认定为无法判定。最后输出两程序盗版检测结果。
对于盗版程序Q:
class FakeA {
public void f(int i) {new FakeB().f(i);}
}
class FakeB {
public double f(int i) {
return 1+
new C().function(i)/new D().function(i);
}
}
class C {
public long function(int i) {return 2*i;}
}
class D {
public long function(int i) {return 3-i;}
}

3 实验验证
3.1 实验对象及环境
实验将验证多特征胎记的可信性和弹性,并与SKB进行对比。实验在Windows 7系统下完成,迭代深度d=3,API和指令序列的特征权重分别为w1=0.3,w2=0.7,修正参数α=8,使用多特征胎记时LCS算法阈值为threshold=5,使用SKB将k-gram算法粒度为gram=5。设置检测阈值γ1为0.8,γ2为0.5。
本文实验使用Junit4.0-4.5,checkstyle4.2-5.2,findbugs4.2-4.7,soot-2.5.0共计19个jar包,6 720个类用于验证比较,其中Junit、checkstyle、findbugs均为代码测试工具,soot为代码分析工具。
3.2 多特征胎记的可信性验证
本文选择验证Junit、checkstyle、findbugs不同大小版本之间的同一类的相似度和Junit、checkstyle、findbugs与Soot之间随机抽取的类之间的相似度。同一程序的不同版本,对比版本1和版本2之间的软件胎记,应该得到较高的相似度;而由两支团队分别独立开发的程序,对比其软件胎记应得到较低的相似度。
以下用首字母代称验证程序。根据可信性定义,当两程序是独立开发的程序时,其胎记应不同,得到的相似度应低于检测阈值的下界。由实验数据可知,多特征胎记在判定两个独立开发的程序时,得到的相似度均低于0.5,即判定为独立开发;而对于同一程序的不同版本之间对比得到的相似度均高于0.8,即判定为抄袭程序。这说明由本文提出的软件胎记具有可信性。
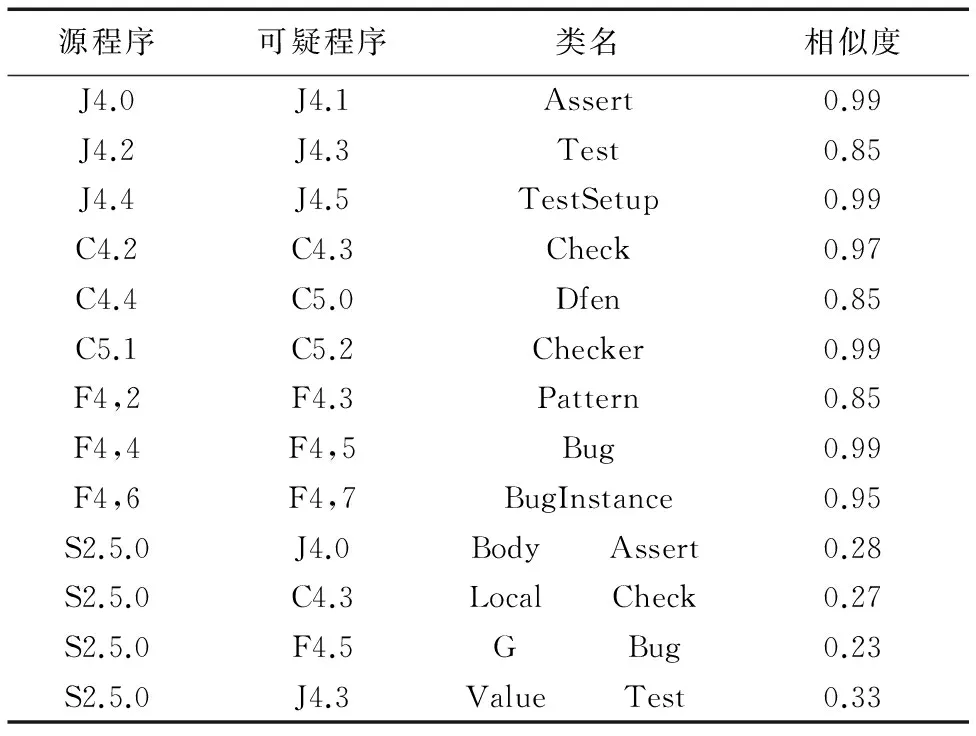
表2 使用多特征胎记得到的相似度Tab. 2 Similarity obtained by using multiple feature birthmark
3.3 在可信性上与SKB的对比
本次实验验证多特征胎记和SKB对相似程序和独立开发程序的识别效果。
Junit4.0到Junit4.5版本之间BaseTestRnuuer.class是一个几乎没有改动的类(以下简称BTR类),将Junit4.0版本的BTR类作为源程序,分别与Junit4.0到4.5版本的BTR类进行比对,首先使用多特征胎记进行比对,再使用SKB进行比对,由两种胎记对同一对类同程序的检测结果均为判定抄袭,说明多特征胎记在检测类同程序上的效果是不弱于SKB的。由两种胎记得到的相似度对比如图3所示。
Junit和Soot是两个完全独立开发的程序,将Soot-2.5.0-ByteType.class作为源类,分别与Junit4.0到4.5版本的Version.class类进行比对,首先使用多特征胎记进行比对,再使用SKB进行比对,由两种胎记得到的相似度对比如图4。

图3 两种胎记在检测类同程序上的表现 Fig. 3 Performance of two kinds of birthmarks in detecting similar programs

图4 两种胎记在检测独立开发程序上的表现 Fig. 4 Performance of two kinds of birthmarks in detecting independent development programs
3.4 软件胎记的弹性验证
使用代码混淆工具proGuard对程序进行加密混淆,记源程序中的类C经过proGuard混淆过的类为C′,对比由C和C′产生的胎记,应得到较高的相似度。本次实验选取Junit中6个类与其对应混淆类分别使用多特征胎记和SKB进行对比,相似度对比如表3。
SKB在对比C和C′时相似度平均值为0.52,多特征胎记对比C和C′时相似度平均值为0.84,可以看出多特征胎记在弹性上优于传统的SKB。

表3 两种胎记的弹性对比Tab. 3 Resilience comparison of two kinds of birthmarks
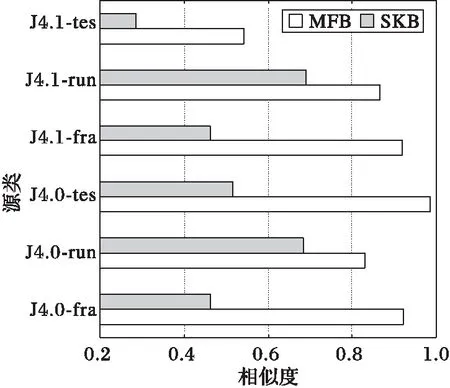
图5 两种胎记的弹性对比测试 Fig. 5 Resilience of two kinds of birthmarks
4 实验结果分析
实验首先验证了多特征胎记的可信性,验证类同程序得到较高的相似度,验证独立开发程序得到较低的相似度,以上两点说明使用多特征胎记进行抄袭检测,其结果是可靠的。
随后对比了多特征胎记与SKB在抄袭检测上的表现,在对比抄袭程序和独立开发程序时,两种胎记得到的结论是一致的。这说明多特征胎记在抄袭检测方面的可信性不弱于SKB。
最后验证了多特征胎记的弹性,由多特征胎记得到源程序C与其迷惑程序C′的相似度均值为0.84,而由SKB得到C与C′之间相似度均值只有0.52。由这两种胎记得到的检测结果完全不同,由SKB得到的相似度我们只能得出两程序的关系是无法判定的,而由多特征胎记得到的相似度可以得出两程序之间存在抄袭关系。这说明多特征胎记在检测经过迷惑的抄袭程序上表现要优于传统的SKB,即多特征胎记的弹性比SKB要强。
5 结语
本文提出了使用两个特征生成的多特征软件胎记MFB,MFB能够直接分析Java的字节码而无需使用源代码。通过提取程序中的API调用信息和指令序列信息来生成软件胎记,验证了多特征融合生成软件胎记这一模型的有效性。本文提出的算法主要侧重于克服SKB弹性弱的缺点,通过更换指令序列特征提取算法来克服由k-gram算法所带来的语义丢失问题,使得胎记的弹性增强,并且加入其他特征保证胎记的可信性,因此MFB对于语义保留的代码混淆和抄袭有很好的检测能力。下一步可以尝试融合其他方面特征来生成可信性与弹性更优的多特征胎记。
参考文献(References)
[1] GROVER D. Program Identification [M]. London:Cambridge University Press,1989: 119-150.
[2] MYLES G, COLLBERG C.K-gram based software birthmarks [C]// Proceedings of the 2005 ACM Symposium on Applied Computing. New York: ACM, 2005: 314-318.
[3] PARK H, CHOI S, LIM H, et al. Detecting Java theft based on static API trace birthmark [C]// Proceedings of the 3rd International Workshop on Security: Advances in Information and Computer Security. Berlin: Springer, 2008: 121-135.
[4] 张杏,徐江峰,李晓阳. 基于系统函数调用频率与指令基本块的软件胎记[J].计算机工程,2016,42(10):86-90.(ZHANG X, XU J F, LI X Y. Software birthmark based on system function call frequency and instruction basic block [J]. Computer Engineering, 2016,42(10): 86-90.).
[5] 王勇.基于Java平台的静态软件胎记技术研究[D].郑州:信息工程大学,2013: 4-6.(WANG Y. Study on static software birthmarking based on Java platform [D]. Zhengzhou: Information Engineering University, 2013: 4-6.)
[6] 黄寿孟,高华玲,潘玉霞. 软件相似性分析算法的研究综述[J]. 计算机科学,2016,43(S1):467-470.(HUANG S M, GAO H L, PAN Y X. Summary of research on similarity analysis of software [J]. Computer Science, 2016,43(S1): 467-470.)
[7] 范铭,刘均,郑庆华,等. 基于栈行为动态胎记的软件抄袭检测方法[J]. 山东大学学报(理学版),2014,49(9):9-16.(FAN M, LIU J, ZHENG Q H, et al. SODB: a novel method for software plagiarism detection based on stack operation dynamic birthmark [J]. Journal of Shandong University (Natural Science), 2014, 49(9): 9-16.)
[8] 王开云,孔思淇,付云生,等.两种基于双向比较的最长公共子串算法[J].计算机研究与发展,2013,50(11):2444-2454.(WANG K Y, KONG S Q, FU Y S, et al. Two longest common substring algorithms based on bi-directional comparison [J]. Journal of Computer Research and Development, 2013, 50(11): 2444-2454.)
[9] 张毅超,车玫,马骏. 求最长公共子串问题的算法分析[J]. 计算机仿真,2007,24(12):97-100.( ZHANG Y C, CHE M, MA J. Analysis of the longest common substring algorithm [J]. Computer Simulation, 2007, 24(12): 97-100.)
[10] 马志强,张泽广,闫瑞,等.基于N-Gram模型的蒙古语文本语种识别算法的研究[J].中文信息学报,2016,30(1):133-139.(MA Z Q, ZHANG Z G, YAN R, et al. N-Gram based language identification for Mongolian text [J]. Journal of Chinese Information Processing, 2016, 30(1): 133-139.)
[11] 陈林,刘粉林,芦斌,等.基于k-gram频数的静态软件胎记[J].计算机工程,2011,37(4):46-48.(CHEN L, LIU F L, LU B, et al. Static software birthmark based onk-gram frequency [J]. Computer Engineering, 2011, 37(4): 46-48.)
[12] 田振洲,刘烃,郑庆华,等.软件抄袭检测研究综述[J].信息安全学报,2016,1(3):52-76.(TIAN Z Z, LIU T, ZHENG Q H, et al. Software plagiarism detection: a survey [J]. Journal of Cyber Security, 2016, 1(3): 52-76.)
[13] 喻宝禄,段迅,吴云. BP神经网络数据预测模型的建立及应用[J].计算机与数字程,2016,44(3):482-486.(YU B L, DUAN X, WU Y. Establishment and application of data prediction model based on BP neural network [J] . Computer and Digital Engineering, 2016, 44(3): 482-486.)
[14] 王广南.基于系统调用依赖图的程序相似性研究[D].长沙:湖南大学,2009:27-29.(WANG G N. Similarity of programs based on system call dependency graphs [D]. Changsha:Hunan University, 2009: 27-29.)
[15] SCHULER D, DALLMEIER V, LINDIG C. A dynamic birthmark for Java [EB/OL]. [2017- 03- 02]. https://www.st.cs.uni-saarland.de/birthmarking/schuler-ase-2007.pdf.
This work is partially supported by Science and Technology Department of Shaanxi Province (2017GY-092).
WANGShuyan, born in 1964, Ph. D., professor. Her research intererts include software testing, data mining.
ZHAOPengfei, born in 1993, M. S. candidate. His research intererts include computer software and theory.
SUNJiaze, born in 1980, Ph. D. candidate, associate professor. His research intererts include intelligent optimization algorithm.
