中文电子病历中的时间关系识别
2018-05-21高大启殷亦超
孙 健,高大启,阮 彤,殷亦超,高 炬,王 祺
(1.华东理工大学 信息科学与工程学院,上海 200237; 2.上海中医药大学附属曙光医院,上海 200021)
0 引言
时间关系识别研究在问答系统、文本提取等自然语言处理领域有着重要的作用。在电子病历文本中,时间关系是临床叙事中的一个重要维度,对于研究患者的病情发展和治疗效用至关重要,许多临床事件只有在特定的时间背景下才有显著意义。例如,症状发展的顺序,不同的治疗时间,以及药物的持续时间和用药频率,都会对最终病情的发展产生影响[1]。这里的时间关系,就是文本中事件之间、时间之间、事件和时间之间的时序关系。2012 i2b2 Challenge将电子病历文本中的时间关系抽取作为任务纳入评测,并将时间关系分为两类:1)事件和文档创建时间之间的时间关系;2)句内时间关系和句间时间关系,其中,句内时间关系包括句内事件-事件和句内事件-时间的时间关系,句间时间关系即是句间事件-事件的时间关系[2]。
时间关系识别存在如下难点:1)在识别句内时间关系的过程中,虽然事件之间存在时序关系,但当句内不存在时间词时,容易出现识别错误。如“第三次化疗时出现腹泻、脱水、电解质紊乱等严重毒副反应,停服希罗达。”中,腹泻、脱水和电解质紊乱这些副反应发生的时间有重叠,但是因为没有给出停服希罗达的时间,容易使(腹泻,希罗达)等实体对的时间关系也被错认为是重叠关系。事实上,通过语义分析可以发现希罗达是在发生副反应之后停服的。2)由于句间事件之间跨度远,若没有显式的时间词出现,很难确定句间事件-事件的时间关系。如“患者于中山医院行Dixon术,病理示(直肠)溃疡型腺癌,分化Ⅱ-Ⅲ级,侵及肠壁全层及周围脂肪组织,切缘阴性,检出肠旁淋巴结9枚,未见癌转移,另见癌结节一枚。术后化疗‘艾力200 mg d1+5FU0.5 d1-5+CF0.2 d1-5’方案化疗6次,无明显异常。”中,“Dixon术”和“艾力200 mg d1+5FU0.5 d1-5+CF0.2 d1-5”分别属于不同句子中的事件,事件之间隔了多个分句且这两句话中都没有给出显式的时间词,给识别带来一定困难。
对于中文文本中时间关系,已有不少学者从不同角度展开研究。王昀等[3]采用基于转换的错误驱动学习来确定时间关系;林静等[4]考虑汉语文本的特点充分抽取蕴含于语法语义层面中的时间关系,并制定了一些与文本无关的时间关系推理原则;王风娥等[5]分析影响时间关系识别的语言特征,使用基于最大熵(MaxEnt)的方法进行识别;刘莉[6]抽取词法特征、时间事件关系特征和语义特征进行时间关系的识别。
2012 i2b2 Challenge将电子病历文本中的时间关系抽取作为任务纳入评测。对于英文电子病历文本中的时间关系识别,大多利用不同的语言特征和不同的分类模型。D’Souza等[7]针对不同类别的时间关系提出了不同的解决方法。他们将事件和文档创建时间的时间关系识别转化成一个序列标注问题,并训练了4个不同的分类器去识别句内和句间的时间关系。Nikfarjam等[8]利用启发式规则识别句间事件和事件的时间关系;对于句内时间关系的识别,将句子转化成独立的时间有向图并且训练两个不同的支持向量机(Support Vector Machine, SVM);同时,训练了一个SVM分类器去识别事件和文档创建时间之间的时间关系。Cheng等[9]为了识别句内时间关系,基于cTakes的输出生成特征训练最大熵分类器,并使用基于规则的方法识别句间时间关系。随着深度学习的兴起,Do等[10]使用卷积神经网络(Convolutional Neural Network, CNN)进行时间关系分类,Cheng等[11]使用基于依存路径的双向长短期记忆网络(Long Short-Term Memory, LSTM)进行时间关系分类,Dligach等[12]则比较了CNN和LSTM在不同设置下的时间关系抽取性能。然而由于深度学习需要训练大量的参数,在训练文本较少时容易出现过拟合现象。
相比英文电子病历文本,对于中文电子病历文本中时间关系识别的研究比较稀少。Xu等[13]进行中文电子病历文本中的信息抽取时,只是利用时间覆盖规则去确定时间和事件之间的关系。
中文电子病历中的时间关系包括句内时间关系和句间时间关系。本文制定了高准确率的启发式规则,训练了两个不同的分类器确定句内时间关系,同时利用不同的语言特征训练了分类器确定句间时间关系。特别地,本文设计了基本特征、短语句法特征、依存特征和其他特征,缓解了句内时间关系识别错误;设计了基本特征、短语句法特征和其他特征,减少了句间时间关系识别错误。实验结果表明,该方法在句内事件-事件、句内事件-时间和句间事件-事件的时间关系识别上的F1值分别达到了84.0%、85.6%和63.5%。
1 问题定义与总体流程
所谓时间关系,就是文本中事件之间、时间之间、事件和时间之间的时序关系。在电子病历文本中,事件是指与病人临床治疗过程中相关的任何事情,包括疾病、症状、检查、药品、手术和化疗等;时间是指包含时间信息的短语,包括日期、时刻、相对时间和时间词等。时间关系的类型有:先于(before)、后于(after)、重叠(overlap)和不确定(unknown)[14]对于事件Eventi和事件Eventj,及事件Eventi和时间Timej,其先于、后于、重叠和不确定关系定义如下:
先于(before) 事件Eventi发生在Eventj之前或者事件Eventi发生在时间Timej之前;
后于(after) 事件Eventi发生在Eventj之后或者事件Eventi发生在时间Timej之后;
重叠(overlap) 事件Eventi发生的时间与事件Eventj发生的时间有交叉或事件Eventi发生的时间与时间Timej有交叉;
不确定(unknown) 事件Eventi与事件Eventj不存在时间关系或不确定时间关系,或事件Eventi发生的时间与时间Timej之间的时间关系不确定。
如“患者6.3服用替吉奥一疗程,后患者因胃部不适自行停药,门诊中药规则治疗。”中出现的事件有“替吉奥”和“胃部不适”,它们的类别分别是药品和症状;出现的时间有“6.3”,类别是日期;存在的时间关系有overlap(替吉奥,6.3)、before(替吉奥,胃部不适)和after(胃部不适,6.3),表达的意思分别为:服用替吉奥发生在6月3日,服用替吉奥先于胃部不适,胃部不适发生在6月3日之后。
又如“术后化疗‘艾力200 mg d1+5FU0.5 d1-5+CF0.2 d1-5’方案化疗6次,05年5月放疗一疗程。”中出现的事件有“艾力200 mg d1+5FU0.5 d1-5+CF0.2 d1-5”,类别是化疗;出现的时间有“05年5月”,类别是日期。由于只知道放疗的时间为05年5月,不知道化疗的时间,也就无法得到事件“艾力200 mg d1+5FU0.5 d1-5+CF0.2 d1-5”和时间“05年5月”的时间关系,即unknown(艾力200 mg d1+5FU0.5 d1-5+CF0.2 d1-5,05年5月)。
本文把时间关系识别转化成实体对分类问题,其形式化描述为:设有事件-时间对(Eventi,Timej)∈Event×Time,事件-事件对(Eventi,Eventj)∈Event×Event,时间关系类别relationk∈R。其中:Event={Event1,Event2, …,Eventn}表示已经识别出的事件表达式集合,Time={Time1,Time2, …,Timem}表示已经识别出的时间表达式集合,R={before,after,overlap,unknown}表示已经定义好的时间关系集合。时间关系识别就是为每一对(Eventi,Timej)或(Eventi,Eventj)分配一个时间关系类别标记relationk。
中文电子病历中的时间关系包括句内时间关系和句间时间关系。其中,句内时间关系包括句内事件-事件的时间关系和事件-时间的时间关系;句间时间关系即是句间事件-事件的时间关系。通过对1 500份上海中医药大学附属曙光医院的电子病历进行分析,把时间关系识别转化成实体对分类问题。制定高准确率的启发式规则,并训练两个不同的分类器确定句内时间关系,同时利用不同的语言特征训练分类器确定句间时间关系。图1表示了本文方法的整个过程。
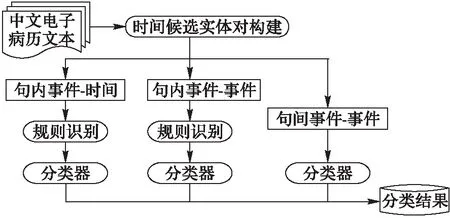
图1 时间关系识别的总体流程 Fig. 1 Workflow of temporal relation recognition
2 句内时间关系识别
句内时间关系考虑的是一句话中事件和事件、事件和时间之间的时间关系。观察电子病历文本发现:从语法结构来看,医生在记录临床叙事时具有一定的模式,例如:“第三次化疗时出现腹泻、脱水、电解质紊乱等严重毒副反应”“今查房,患者自诉乏力好转,手臂痒,胃纳可,夜寐尚安,二便调”,它们都满足Event1+(、|,)+Event2+(、|,)+Event3……”的模式,可得到overlap(Event1,Event2)、overlap(Event2,Event3)、overlap(Event1,Event3)等的时间关系,即事件1、事件2、事件3发生的时间有重叠。又例如:“患者2008年10月无明显诱因下出现大便带血”“2010.12.28于东华医院肝胆外科行肝穿刺胆道置管引流术”,它们都满足“Time+String+Verb+Event”这样的模式,可得到overlap(Event,Time)时间关系,即该事件发生在该时间下。因此,本文首先设计了一些高准确率的启发式规则,识别句内时间关系,当规则无法识别时,再训练分类器进一步识别。
2.1 基于规则的句内时间关系识别
针对每个规则,本文都给出了相应的例子来解释这个规则。其中,[^因]表示除了“因”之外的任何字;String{0,10}表示字符串最小长度为0,最大长度为10。
2.1.1 基于规则的句内事件-事件的时间关系识别
1)[^因] + Event1+ (、|,|+|并发|null) + Event2+ (、|,|+|并发|null) + Event3+ …… ⟹ overlap (Event1, Event2)、overlap (Event1, Event3)、overlap (Event2, Event3)等
例:患者入院症见:,,,。由上例得到的关系有:overlap (乏力,胃纳欠佳),overlap (乏力,无头晕),overlap (乏力,无黑便)和overlap (无头晕,无黑便)等。
2)因 + Event1+ String{0,10} + Event2⟹ before (Event1, Event2)
例:处理:患者因,予对症治疗。由上例得到的关系有:before (偶觉背部瘙痒,润燥止痒胶囊)。
3)Event1+ String{0,10} + (,) + (后|之后|以后|其后|后来) + String{0,10}(不包含标点符号) + Event2⟹ after (Event2, Event1)
例:患者服用一疗程,后患者自行停药,门诊中药规则治疗。由上例得到的关系有:after (胃部不适,替吉奥)。
2.1.2 基于规则的句内事件-时间的时间关系识别
1)Time + String{0,10} + (出现|觉|诉|患|患有|查|行|服用|给予|null) + Event ⟹ overlap (Event, Time)
例:患者于在我院查示:直肠肿块,于在我院普外科行。由上例得到的关系有:overlap (电子肠镜,2011年6月)和overlap (直肠癌根治术,2011.6.21)。
2)Time1+(、|,)+Time2+(、|,)+Time3+(、|,)+…+String{0,10}+Event ⟹ overlap(Event,Time1),overlap(Event,Time2),overlap(Event,Time3),…
例:术后恢复可,于,,,,,行化疗,化疗方案:。由上例得到的关系有:overlap(mFOLFOX6,2010.7.20),overlap(mFOLFOX6,8.5),overlap(mFOLFOX6,8.19),overlap(mFOLFOX6,9.3),overlap(mFOLFOX6,9.19)和overlap(mFOLFOX6,10.5)。
3)Time+String{0,10}+(出现|觉|诉|患|患有|查|行|服用|给予|null)+Event1+(、|,|+|并发|null)+Event2+(、|,|+|并发|null)+Event3+…⟹overlap(Event1,Time),overlap(Event2,Time),overlap(Event3,Time),…
例:患者自觉,,,,,为求进一步中医药治疗,收治入院。由上例得到的关系有:overlap(乏力明显,近一周),overlap(无明显腹痛腹胀,近一周),overlap(无体重减轻,近一周),overlap(无头晕,近一周)和overlap(无黑便,近一周)。
2.2 基于机器学习的句内时间关系识别
虽然设计的启发式规则有着较高的抽取质量,但是它们并不能覆盖所有的时间关系,此时需要通过训练分类器作进一步识别,来为每一个候选实体对
2.2.1 基于机器学习的句内事件-事件的时间关系识别
本文设计了基本特征、短语句法特征、依存特征和其他特征训练分类器,如表1所示。
1)基本特征。
基本特征包含两个事件的类别、上下文特征、词性特征和位置特征。本文采用Unigram、Bigram和Trigram这三种上下文特征,上下文窗口大小为3。与上下文特征相对应,词性特征同样包含Unigram、Bigram和Trigram三组特征。对于词性特征,本文使用汉语言处理包HanLP[14]对病历文本进行分词和词性标注,将已经识别出来的事件和时间加入到用户自定义词典以确保分词的准确性。位置特征表明两个事件分别位于第几个分句中的第几个词。

表1 句内事件-事件的时间关系的分类特征Tab. 1 Classification features for within-sentence event/event TLinks
2)短语句法特征。
概率上下文无关文法(Probabilistic Context Free Grammar, PCFG)具有良好的结构化信息分析能力,经常用于句子和树结构之间的转换[15]。本文利用斯坦福大学自然语言处理小组开发的“Stanford Parser”工具[16]进行短语句法结构分析,选取chinesePCFG作为分析模型,分析结果包含句法结构树、短语信息、词性标注等。根据得到的短语句法树,设计短语句法结构层面的特征:如果当前节点为事件,当它的父亲节点是NP或VP时,得到父亲节点下的最左叶子节点;当它的祖父节点是NP或VP时,得到祖父节点下的最左叶子节点;Stanford Parser将词性标注结果为“VV”的短语视为动词,得到离事件最近的动词,确定该动词的位置以及与事件之间的间隔词数。
例如,对于“患者无明显诱因下反复出现大便颜色加深,查肠镜:降结肠MT。”,通过Stanford Parser得到短语句法树,如图2所示。事件节点“大便颜色加深”的父亲节点是名词短语NP,而NN只是说明节点“大便颜色加深”的词性为名词。由于事件节点“大便颜色加深”的父亲节点是NP,它只有一个孩子节点,故而NP的最左叶子节点就是节点“大便颜色加深”本身;事件节点“大便颜色加深”的祖父节点是动词短语VP,VP的最左叶子节点是“出现”。同理,事件节点“肠镜”的父亲节点是NP,NP的最左叶子节点是“肠镜”;事件节点“肠镜”的祖父节点是VP,VP的最左叶子节点是“查”。和事件节点“大便颜色加深”在同一个子句中且离事件最近的动词是“出现”,它是在事件的左边第一个词。当离事件最近的动词有两个时,取左边的动词。
3)依存特征。
本文使用汉语言处理包HanLP对病历文本进行依存句法分析,得到短语之间的依存关系。如果短语到短语之间存在直接依存关系或间接依存关系,则认为短语到短语之间存在关系链。以事件1和事件2之间的关系链为例,它是指从事件1(或事件2)出发,通过依存关系递归查找事件2(或事件1),得到依存关系即关系链。
例如,对于“患者昨日行‘替吉奥60mgBidpo’化疗,患者无恶心呕吐,无腹胀腹痛,胃脘部隐痛较昨好转”,通过HanLP得到句法分析结果,如图3所示。
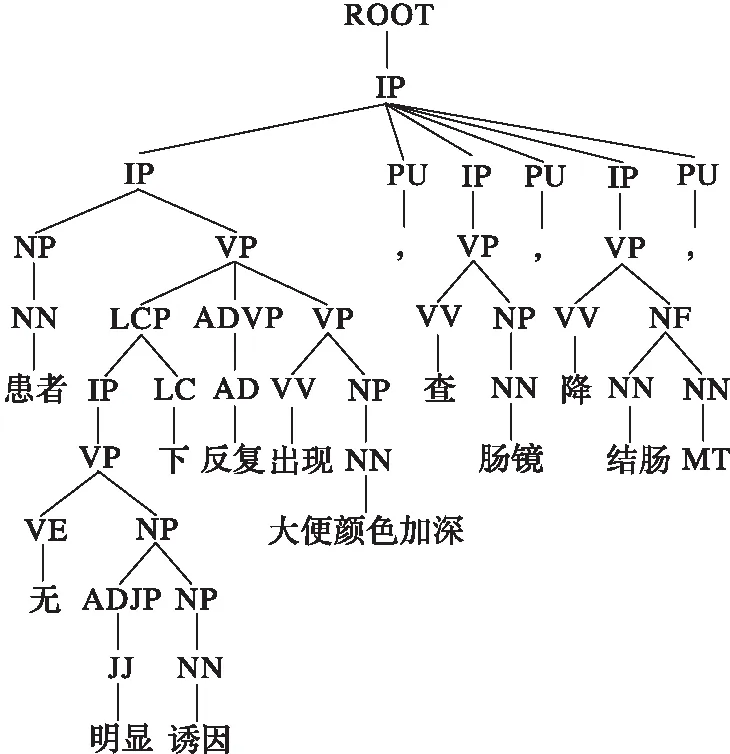
图2 时间关系识别的短语句法树示例 Fig. 2 Example of phrase syntax tree for temporal relation recognition
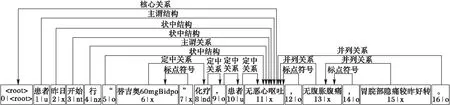
图3 时间关系识别的依存分析结果示例 Fig. 3 Example of dependency parsing for temporal relation recognition
对于候选事件-事件实体对(替吉奥60mgBidpo,无恶心呕吐),从“替吉奥60mgBidpo”出发,通过依存关系递归查找“无恶心呕吐”,得到关系链“替吉奥60mgBidpo→化疗→,→患者→无恶心呕吐”;而从“无恶心呕吐”出发,找不到依存关系可以递归查找得到“替吉奥60mgBidpo”。从离“替吉奥60mgBidpo”最近的动词“行”出发,得到关系链“行→无恶心呕吐”,而从“无恶心呕吐”出发,找不到依存关系可以递归查找得到“行”。
4)其他特征。
除了语言学特征外,本文增加了利于识别句内事件-事件的时间关系的特征。对于候选的事件-事件实体对
2.2.2 基于机器学习的句内事件-时间的时间关系识别
同样,本文选取了基本特征、短语句法结构特征、依存特征和其他特征训练分类器识别句内事件-时间的时间关系,如表2所示。
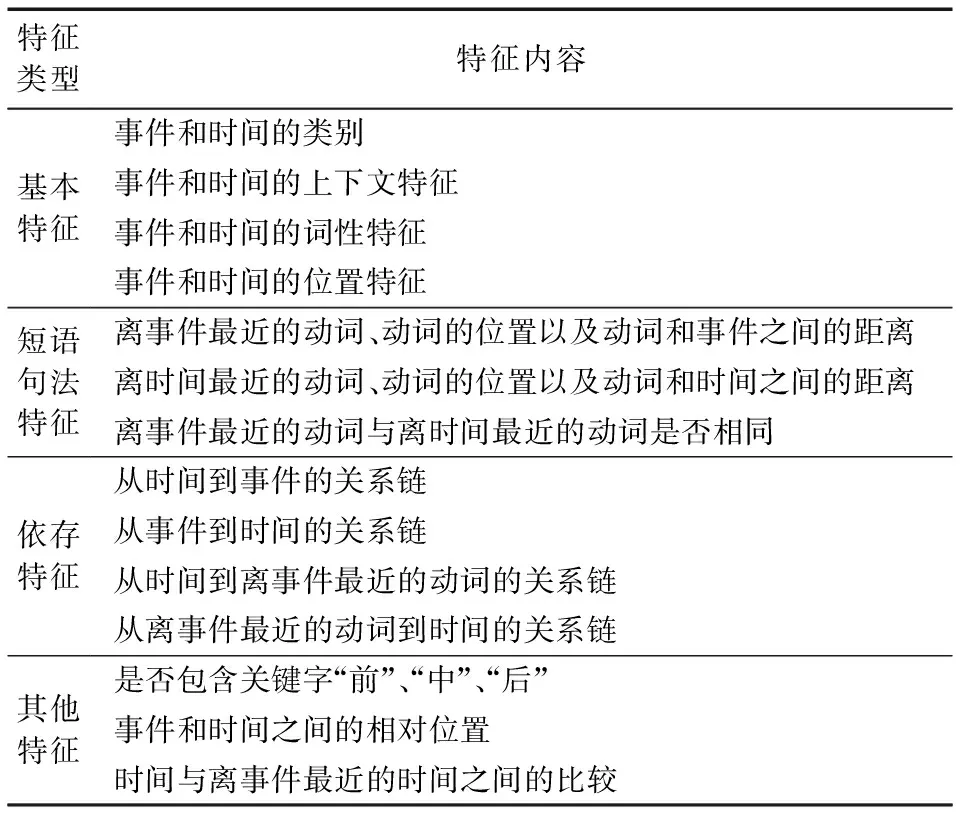
表2 句内事件-时间的时间关系的分类特征Tab. 2 Classification features for within-sentence event/time TLinks
3 句间时间关系识别
句间时间关系考虑的是一句话中的事件和另一句话中的事件之间的时间关系,本文主要考虑相邻句间的时间关系。设Eventi, j是第i句话中的第j个事件,Eventi+1,k是第i+1句话中的第k个事件,句间时间关系识别就是为每个(Eventi, j, Eventi+1,k)分配一个时间关系类别标记。如果当前句子中没有任何事件,则跳过这句句子。本文大体使用句内事件-事件的时间关系识别特征以训练句间时间关系分类器,只是作如下改动:句间事件-事件的时间关系识别特征以训练中,基本特征中的位置特征指的是两个事件分别位于第几句话中的第几个分句中的第几个词;而其他特征中,不考虑事件之间的相对位置特征,另外,其他特征中添加了关键词特征,判断句中是否包含“术前”“术中”“术后”“服药后”“检查后”等关键字。
4 实验与分析
4.1 实验数据集
本文对来自上海中医药大学附属曙光医院的1 500份病历文本进行时间关系识别。其中,每个患者的病历文本包均含以下记录:首次病程记录、首次主治查房记录、首次主任查房记录、主任查房记录、主治查房记录、交班记录、住院记录、日常病程记录、出院小结。这些病历存在大量的冗余信息,通过观察发现,出院小结中的信息最为完整地概括了住院过程中患者的病情随时间的演变,包括入院情况、医生诊断情况、检查情况、治疗情况、出院情况以及转归情况。所以,基于出院小结,可以为每一个患者生成一个综合病历。
为了更为准确地识别出中文电子病历文本中的时间关系,实验前首先对综合病历进行了人工标注。本文预先定义了电子病历文本中的事件类型和时间类型,事件是指与病人临床治疗过程相关的任何事情,包括疾病、症状、检查、药品、手术和化疗等;时间是指包含时间信息的短语,包括日期、时刻、相对时间和时间词等。将每句话中的事件和时间用特殊符号标记,再根据上下文信息,标注出句内时间关系和句间时间关系。
例如,对于“患者2004.12无明显诱因出现便血,黄浦中心肠镜:结肠近肝曲占位, 2005.1黄浦中心医院已经行结肠癌根治术,术后病理:结肠腺癌(病理号不详)。”,其标注结果是“患者无明显诱因出现,黄浦中心:结肠近肝曲占位,黄浦中心医院已经行,术后病理:结肠腺癌(病理号不详)。”根据上下文信息,可得到的句内事件-时间的时间关系:overlap(便血,2004.12)、overlap(肠镜,2004.12)、overlap(结肠癌根治术,2005.1)、before(便血,2005.1)、after(结肠癌根治术,2004.12)等,以及句内事件-事件的时间关系:before(便血,肠镜)、before(便血,结肠癌根治术)、after(结肠癌根治术,肠镜)等。
4.2 评价指标
本文使用准确率(Precision)、召回率(Recall)和F1值(F1-score)3个指标来评价中文电子病历文本中时间关系识别的性能。它们的计算方法分别为:
其中:Numrecogmized是利用分类器识别出来的某种时间关系个数;NumrecogmizedCorrect是识别出来的某种时间关系中正确的个数,也就是Numrecogmized中正确的个数;Numcorrect是语料中某种时间关系的总数。对于时间关系的识别,本文分别对每一类时间关系计算其准确率、召回率和F1值,最后计算出各关系的加权平均值。
4.3 句内时间关系识别结果
本文使用汉语言处理包HanLP对病历文本进行分词和词性标注,同时将已经识别出来的事件和时间加入到用户自定义词典以确保分词的准确性;利用斯坦福大学自然语言处理小组开发的“Stanford Parser”工具进行短语句法结构分析,选取chinesePCFG作为分析模型,得到短语句法特征;使用汉语言处理包HanLP对病历文本进行依存句法分析,得到依存特征。基于开源的数据挖掘工具Weka[17],使用不同的语言特征分别训练Naïve Bayes、Random Forest和SVM分类器(其中SVM采用RBF(Radial Basis Function)核)识别句内时间关系,利用十折交叉验证。表3给出了句内事件-事件、句内事件-时间的时间关系识别准确率、召回率和F1值。
从表3可以看出:加入短语句法特征后,事件-事件的时间关系识别准确率略有下降;加入依存特征和其他特征后,事件-事件的时间关系识别准确率、召回率和F1值明显提高。训练的3个分类器中,SVM识别结果最好,其次Random Forest,最差的是Naïve Bayes,因为Naïve Bayes的特征条件独立假设在这里并不满足。综上,当语言特征选择为基本特征、依存特征和其他特征的组合,分类器选择为SVM时,结果最优,准确率、召回率、F1值分别为84.0%、84.2%、84%。
加入依存特征后,事件-时间的时间关系识别准确率略有下降;加入短语句法特征和其他特征后,事件-时间的时间关系识别准确率、召回率和F1值明显提高。通过观察数据发现,当使用汉语言处理包HanLP对病历文本进行依存句法分析时,时间和事件之间、时间和离事件最近的动词之间的依存关系经常识别不到,导致特征值大多为空,使得加入依存特征后识别效果不好。训练的3个分类器中,SVM识别结果最好,其次是Random Forest,最差的是Naïve Bayes,同样因为Naïve Bayes的特征条件独立假设在这里并不满足。综上,当语言特征选择基本特征、短语句法特征和其他特征的组合,分类器选择为SVM时,结果最优,准确率、召回率、F1值分别为85.7%、85.6%、85.6%。
4.4 句间时间关系识别结果
基于开源的数据挖掘工具Weka,使用不同的语言特征训练多个分类器识别句间事件-事件的时间关系,利用十折交叉验证,识别结果如表3所示。从实验结果中可以看出,在基本特征上,加入短语句法特征的效果优于加入依存特征的效果;而不同于句内事件-事件的时间关系识别结果,观察表3发现对于句间时间关系的识别,加入依存特征后识别效果明显变差。这是由于使用汉语言处理包HanLP对病历文本进行句法分析时,相邻句间的依存关系分析结果较差,很难找到前一句话中的事件、离事件最近的动词和后一句话中的事件、离事件最近的动词之间的关系链。还可以发现,当加入其他特征时,识别效果有较明显的改善。当语言特征选择为基本特征、短语句法特征和其他特征的组合,分类器选择为Random Forest时,结果最优,准确率、召回率、F1值分别为64.6%、63.9%、63.5%。
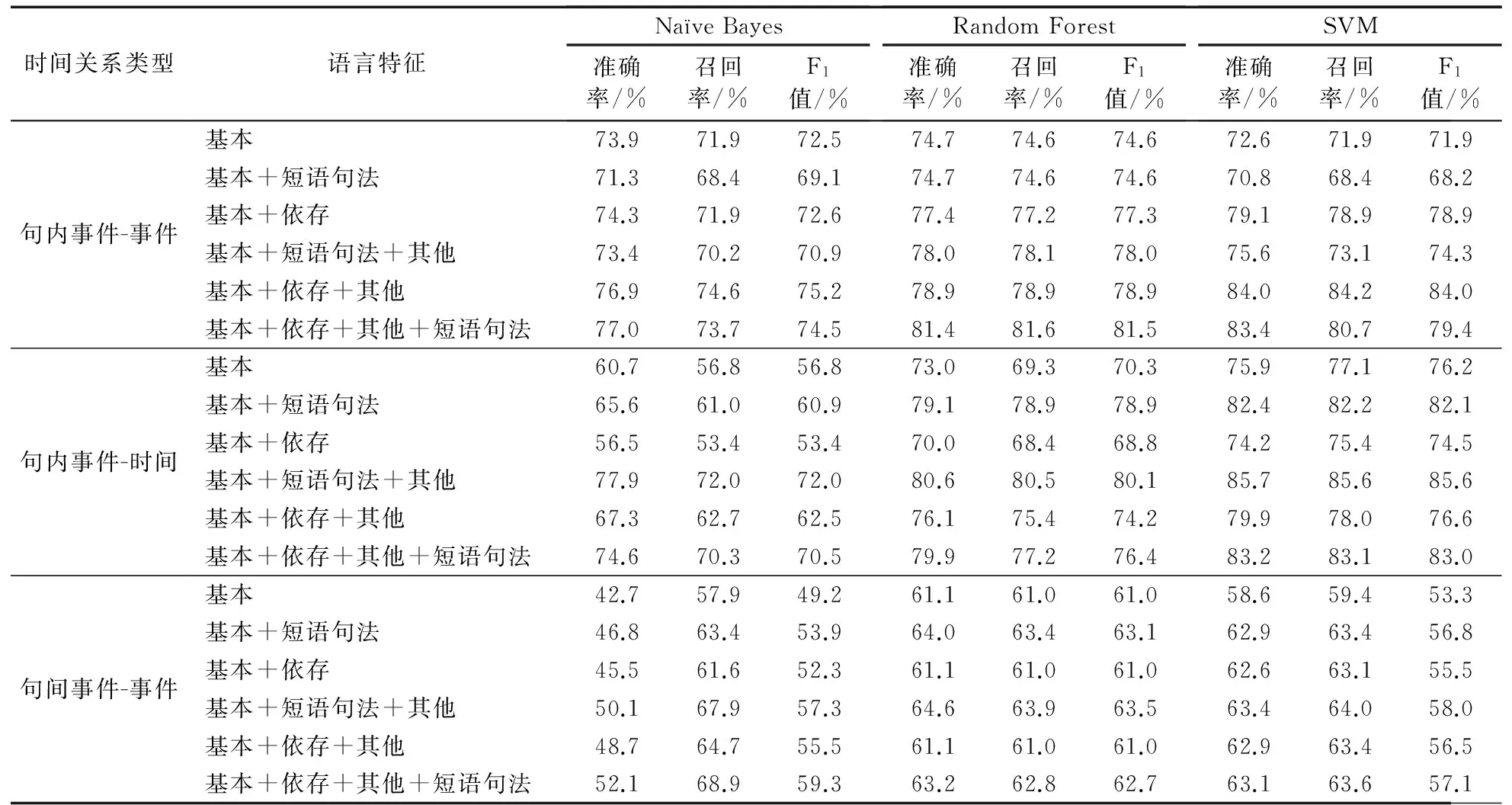
表3 不同时间关系类型的识别结果Tab. 3 Recognition results for different TLinks
4.5 与现有方法的比较
王风娥等[5]为了研究汉语文本中的时间关系,将时间关系分为句内事件-事件、句内事件-时间、句间事件-事件和事件-文档创建时间4种关系;他们分析影响时间关系识别的语言特征,使用基于最大熵的方法识别汉语文本中的时间关系。Xu等[13]研究中文电子病历文本中的信息抽取时,利用时间覆盖规则去确定时间和事件之间的关系。他们设计了如下规则:1)如果一句话中只包含一个时间,则这个时间覆盖了这句话中的所有事件;2)如果一句话中包含多个时间,当前时间覆盖了下个时间出现前的所有事件;3)如果一句话中没有时间,则前一句话中的最后一个时间覆盖了这句话中的所有事件。由于事件与事件之间的时间关系考虑的是事件发生的时间先后,故而利用Xu等[13]设计的时间覆盖规则可以识别出句内事件-事件、句内事件-时间和句间事件-事件的时间关系。表4给出了实验比较结果。
从表4可以看出,本文的方法在识别中文电子病历文本中的时间关系上取得了最好的结果。这是由于本文提出的识别特征比王风娥等[5]提出的更为丰富;另外,Xu等[13]设计的时间覆盖规则在识别电子病历中的时间关系时会发生错误,如对于“第三次化疗时出现腹泻、脱水、电解质紊乱等严重毒副反应,停服希罗达”,由设计的时间覆盖规则可知overlap(腹泻,希罗达),但事实上希罗达是在发生副反应之后停服的,即before(腹泻,希罗达)。
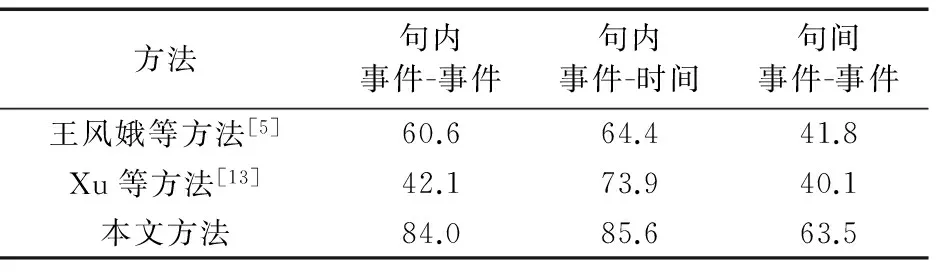
表4 本文方法与现有方法在时间关系识别上的F1值比较 %Tab. 1 Temporal relation recognition results (F1-score) of the proposed method and existing methods %
5 结语
时间关系是临床叙事中的一个重要维度,对于研究患者的病情发展和治疗效用至关重要。中文电子病历文本中的时间关系包括句内时间关系和句间时间关系。其中,句内时间关系包括句内事件-事件的时间关系和句内事件-时间的时间关系,句间时间关系即是句间事件-事件的时间关系。本文把中文电子病历文本中的时间关系识别视作实体对分类问题,制定了高准确率的启发式规则,并训练两个不同的分类器确定句内时间关系,利用不同的语言特征训练分类器确定句间时间关系。实验结果表明,当分别使用SVM、SVM和Random Forest算法时,本文方法在句内事件-事件、句内事件-时间和句间事件-事件的时间关系识别上获得的F1值最高,分别达到了84.0%、85.6%和63.5%。只是,本文方法在句间事件-事件的时间关系上的识别结果还不是特别好,需要更进一步的研究与提高。
参考文献(References)
[1] SUN W, RUMSHISKY A, UZUNER O. Temporal reasoning over clinical text: the state of the art[J]. Journal of the American Medical Informatics Association, 2013, 20(5): 814-819.
[2] SUN W, RUMSHISKY A, UZUNER O. Evaluating temporal relations in clinical text: 2012 i2b2 Challenge [J]. Journal of the American Medical Informatics Association, 2013, 20(5):806-813.
[3] 王昀,苑春法.基于转换的时间-事件关系映射[J].中文信息学报,2004,18(4):24-31.(WANG Y, YUAN C F. A time-event mapping method based transformation [J]. Journal of Chinese Information Processing, 2004, 18(4): 24-31.)
[4] 林静,苑春法.汉语时间关系抽取与计算[J].中文信息学报,2009,23(5):62-67.(LIN J, YUAN C F. Extraction and computation of Chinese temporal relation [J]. Journal of Chinese Information Processing, 2009, 23(5): 62-67.)
[5] 王风娥,谭红叶,钱揖丽.基于最大熵的句内时间关系识别[J].计算机工程,2012,38(4):37-39.(WANG F E, TAN H Y, QIAN Y L. Recognition of temporal relation in one sentence based on maximum entropy [J]. Computer Engineering, 2012, 38(4): 37-39.)
[6] 刘莉.中文时间事件关系识别的方法研究[D].重庆:重庆大学,2012:33-35.(LIU L. Research on automatic identification of temporal relations between Chinese time expressions and events [D]. Chongqing: Chongqing University, 2012:33-35.)
[7] D’SOUZA J, NG V. Classifying temporal relations in clinical data: a hybrid, knowledge-rich approach [J]. Journal of Biomedical Informatics, 2013, 46: S29-S39.
[8] NIKFARJAM A, EMADZADEH E, GONZALEZ G. Towards generating a patient’s timeline: extracting temporal relationships from clinical notes [J]. Journal of Biomedical Informatics, 2013, 46:S40-S47.
[9] CHENG Y, ANICK P, HONG P, et al. Temporal relation discovery between events and temporal expressions identified in clinical narrative [J]. Journal of Biomedical Informatics, 2013, 46: S48-S53.
[10] DO H W, JEONG Y S. Temporal relation classification with deep neural network [C]// Proceedings of the 2016 International Conference on Big Data and Smart Computing. Washington, DC: IEEE Computer Society, 2016: 454-457.
[11] CHENG F, MIYAO Y. Classifying temporal relations by bidirectional LSTM over dependency paths [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2017, 2: 1-6.
[12] DLIGACH D, MILLER T, CHEN L, et al. Neural temporal relation extraction [C]// Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2017,2: 746-751.
[13] XU D, ZHANG M, ZHAO T, et al. Data-driven information extraction from Chinese electronic medical records [J]. PLOS ONE, 2015, 10(8): e0136270.
[14] HANKCS. HanLP [EB/OL]. [2014- 12- 23]. https://github.com/hankcs/HanLP.
[15] STOLCKE A. An efficient probabilistic context-free parsing algorithm that computes prefix probabilities [J]. Computational Linguistics, 1994, 21(2): 165-201.
[16] DAN K, MANNING C D. Fast exact inference with a factored model for natural language parsing [EB/OL]. [2017- 03- 03]. http://www.ling.helsinki.fi/kit/2008s/clt350/docs/KleinManning-lexpar03.pdf.
[17] HOLMES G, DONKIN A, WITTEN I H. WEKA: a machine learning workbench [EB/OL]. [2017- 03- 03]. https://researchcommons.waikato.ac.nz/bitstream/handle/10289/1138/uow-cs-wp-1994-09.pdf;jsessionid=0E603B1F904CF7546CF087199832DD44?sequence=1.
This work is partially supported by the National High Technology Research and Development Program (863 Program) of China (2015AA020107), the National Key Technology Research and Development Program (2015BAH12F01-05).
SUNJian, born in 1993, M.S. candidate. Her research interests include information extraction, knowledge graph.
GAODaqi, born in 1957, Ph. D., professor. His research interests include machine olfactory, intelligence theory, pattern recognition.
RUANTong, born in 1973, Ph. D., professor. Her research interests include information extraction, knowledge graph, data quality evaluation.
YINYichao, born in 1983, M. S., engineer. His research interests include hospital informatization.
GAOJu, born in 1966, M. S., chief physician. His research interests include hospital administration, hepatobiliary disease treatment by combination of traditional Chinese and western medicine.
WANGQi, born in 1993, M.S. candidate. His research interests include information extraction, knowledge graph, machine translation.
