探究深度学习在脱机彝文字符识别中的应用
2018-05-18吉娃阿英
吉娃阿英
(四川大学计算机学院,成都 610065)
0 引言
字符识别因为其较高的实际应用价值,一直是模式识别领域的一个研究热点。随着计算机和相关学科的发展,文字识别的研究工作已经取得了较大的成功,一些文字识别的产品相继产生,并投入使用当中。特别是针对汉字和英文的光学字符识别产品已经比较成熟[1],在实际的应用中表现良好。然而,对于一些少数民族语言文字的研究却还刚刚起步甚至是空白。彝语是一门使用人数超过百万的少数民族语言,而对于彝文字识别的研究还处在起步阶段,还没有统一或者成型的彝文字识别方法和工具出现[2]。
目前虽然有少数的相关研究者对彝文字符识别做了初步的探索和研究,但是大都使用的是一些传统的人工设计规则来提取特征,再用模板匹配或者是分类的方法。这些传统的研究方法虽然在一定的条件和特定的数据集上可以获得比较良好的实验结果,但是存在着不足和缺陷[3]。例如,手工构造规则并提取特征对特定的数据集有效,但是在不同数据集或者实际应用中它会出现泛化能力不足的现象。另外,不同的特征选择算法和特征选择,对识别的效果影响较大以及特征选择困难,容易受数据集影响,算法对数据的噪声敏感,从而对前期原始数据的预处理要求就很高[4]。鉴于此,本文探究了深度学习在彝文字符识别上的应用,深度学习方法因能够自主从数据中学习和提取特征,能够大大弥补上述传统方法的缺点。经过实验验证,深度学习算法在彝文字符识别中具有良好的表现。
1 相关研究
彝文字符识别是一个新起步的研究课题,目前为止相关的研究还比较少。王嘉梅等人使用基于图像分割,手工构造规则和特征字典匹配的方法研究了彝文字识别的应用,并设计相关实验来进行仿真[4]。朱宗晓等人采用1024维周边方向贡献度作为彝文字符的统计特征,使用基于K-L变化的特征压缩算法和三级字典快速匹配算法,来实现脱机印刷体彝文的识别[5]。朱龙华等人应用弹性网格特征,方向线素特征,投影特征和笔画密度特征以及结合彝文字型的结构特征进行特征提取,最后通过多分类器集成的方法来输出识别结果[6]。贾晓栋初次提出了深度学习方法在脱机手写彝文字上的研究工作,并使用卷积神经网络在自建的包含100个类的手写体彝文字数据集上训练和测试,在此100个类别的手写体彝文数据集上获得不错的效果[3]。本文在更大的脱机印刷体彝文字符数据集上探索和验证了深度学习在彝文印刷体文字识别上的应用,实验结果表明,深度学习在彝文脱机印刷体识别上是有效可行的。
2 实验设计
2.1 数据准备

图1
本文收集了大量的脱机印刷体彝文字图片和扫描件样本,然后将彝文字图片数据经过文字切分,二值化和归一化处理。最后形成包含全部1165个标准彝文字符,每个字符对应20个不同图片,样本大小为23300张32×32小图片的彝文印刷体字符集。示例样本如图2:

图2
本实验设计的彝文字识别方法属于机器学习中的监督学习方法,需要让神经网络模型从训练数据中学习不同类别文字的模式,因此需要对彝文字符进行数据标注。本文采用Unicode彝文系统[7]的编码顺序来对彝文字进行标注,类别标号从0开始。Unicode彝文系统中彝文字符的编码范围为0xA000-0xA4c6,而0xA000编码对应的是字,所以该字的类别标号是0,同样地字的类别标号为10,依此类推。实验时从数据集中随机20000份样本作为训练集,剩余的3300份作为测试集。
2.2 实验实施
采用的网络模型如图3,包括多个卷积层和下采样层,原始图像数据输入模型,经过卷积层的处理产生多个输出(特征图),特征图再经过采样层max-pooling采样处理,最后特征图作为全连接层的输入来产生对应的输出。在此网络模型当中,卷积层经过学习输出多个特征图,这是一个特征学习的过程,跟传统算法的特征选择相似,但是卷积层能够通过多个卷积核对输入图像产生多个对应的特征图,相比传统人工设计和选择特征相比,能学习到更多更细微的特征,能够适应图像的旋转位移等变化[8]。下采样层类似传统方法中的特征降维处理,这样能降低网络模型参数的复杂度,提高模型的泛化能力。最后的全连接层类似传统方法中的分类器,把卷积网络学习到的高层特征作为模式输入,学习输出对应的分类预测结果。

图3

图4
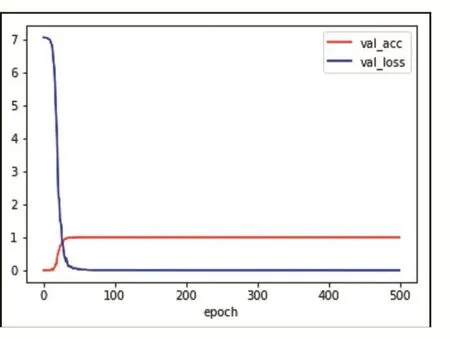
图5
图4和图5训练和验证误差曲线,横轴表示模型训练过程中的迭代次数,纵轴是对应准确率和误差。由图可以看到,随着训练迭代次数的增加准确率逐渐提高,误差逐渐减小,当模型迭代次数到达400左右的时候,准确率和误差趋于稳定。在验证过程中,情况与训练过程类似。虽然随着训练迭代次数的增加,模型预测的准确率也会相应地提高,但这可能会产生过拟合现象,为此,在本实验中,迭代次数选择350次,这样能在一定程度上提高模型的泛化能力。
3 实验结果与分析
由于彝文字符识别的研究尚不成熟,标准统一的数据集没有形成,目前为止很难做到相同条件下的实验结果对比,本文从数据集、识别率,以及特征提取方法等角度来对不同方法的比较。如表1。
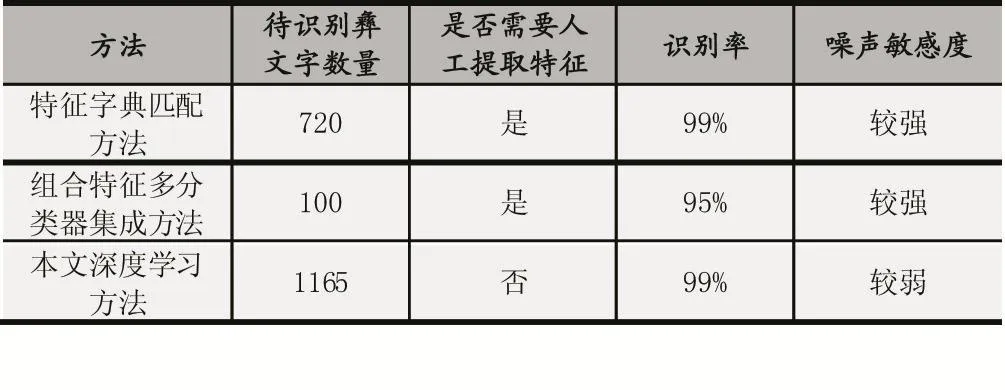
表1
从实验结果中可以看到,基于特征字典匹配,基于组合特征多分类器集成和本文深度学习的方法在识别率上都表现出较好的性能。但是,由于深度学习的方法对前期数据预处理的要求比上文两种方法低,也不需要人工构造和提取特征,而是通过数据学习获取相关特征。因此基于神经网络的方法不仅能提高识别的效率,其在不同数据集上的泛化能力也明显优于前者。
4 结语
彝文字符识别是一个具有现实意义的研究工作,然而目前尚处在摸索探究的阶段,大多数研究方法都还在沿用传统的手工设计规则和特征提取的方法。鉴于深度学习方法现在图像处理领域取得的巨大成就[8],本文探索了深度学习方法在彝文字符识别中的应用,实验结果表明,深度学习方法在彝文字符识别方面的应用是可行的,并且相比一些传统的方法,其具有一定的优势。
参考文献:
[1]孙华,张航.汉字识别方法综述[J].计算机工程,2010,36(20):194-197.
[2]朱宗晓,吴显礼.脱机印刷体彝族文字识别系统的原理与实现[J].计算机技术与发展,2012,22(2):85-88.
[3]贾晓栋.基于深度学习的手写体彝文识别技术应用研究.北京:中央民族大学,2017.
[4]王嘉梅,文永华,李燕青.基于图图像分割的古彝文字识别系统研究[J].云南民族大学学报:自然科学版,2008,17(1):76–79
[5]朱宗晓,吴显礼.脱机印刷体彝族文字识别系统的原理与实现[J].计算机技术与发展,2012,22(2):85-88.
[6]朱龙华,王嘉梅.基于组合特征的多分类器集成的脱机手写体彝文字识别[J].云南民族大学;自然科学版,2010,19(5):329-333.
[7]沙马拉毅.计算机彝文信息处理[J].凉山大学学报,2001,3:4-7.
[8]Alex Krizhevsky,Ilya Sutskever,Geoffrey E.Hinton.ImageNet Classification with Deep Learning Convolutional Neural Networks.International Conference on Neural Information Processing Systems,2012,60(2):1097-1105.
