内存计算环境下基于索引结构的内存优化策略∗
2018-05-15英昌甜王维庆国冰磊
英昌甜,王维庆,于 炯,卞 琛,国冰磊,祁 雷
(1.新疆大学电气工程学科博士后科研流动站,新疆乌鲁木齐830046;2.新疆大学软件学院,新疆乌鲁木齐830046;3.新疆大学电气工程学院,新疆乌鲁木齐830046;4.乌鲁木齐职业大学信息工程学院,新疆乌鲁木齐830002)
0 引言
近年来,互联网社交、电子商务等应用取得令人瞩目的发展.包括应用的用户基数、在线、应用数都取得突飞猛进的增长;另外随着开放的深入,还有越来越多的第三方选择数据中心的平台开发应用.这些外部条件的变化对技术平台而言,也带来了新挑战.为了解决数据访问延迟问题,研发人员和研究者们提出了各种解决方案.其中基于内存的存储技术能够很好的满足在线密集型应用的需求,例如memcached,Redis,Bigtable等.Google和Yahoo!将所有Web搜索索引存储在DRAM中;Facebook使用memcached缓存TB级的数据在DRAM中以提高访问性能;Bigtable也允许将整列加载至内存中[1,2].而 Berkeley团队则提出了一种新的解决方案——Tachyon.与Facebook和Bigtable不同,Tachyon并不将DRAM 作为缓存,而是存储所有数据在DRAM中.由于DRAM无可比拟的优越性[3,4],Tachyon可以提供与磁盘存储系统相比较高的吞吐量,以及较低访问延迟.它能够很好的满足社交网络、信息检索和电子商务等在线数据密集型应用的需求.另外,随着非相变内存及超级内存技术的出现,为Tachyon的应用提供了广阔的前景.
目前国内外关于键值对存储问题的研究很多,已有相当数量的文献提出了各自的见解[4−8].现有的存储结构问题解决方案可分为两类:通用方案[4−6]和针对具体应用的方案[7,8].通用方案主要提出新的数据结构,存储二进制键值对.针对具体应用的方案则在不同应用情境下,通过合并已存储的数据并建立索引的方法来解决问题.这些方案都为进一步研究内存云下的存储策略提供了很好的参考价值,但通常是针对传统的数据中心以及存储在磁盘中的文件进行处理,且需要对系统架构进行修改,并不完全适用于该架构.
因此,为了解决哈希存储结构所带来的问题,文章基于开源的内存存储系统Tachyon,提出了适应于内存计算环境的优化存储结构,在不改变系统原有存储结构的基础上,设计基于熵编码的排序存储(ECSS,Entropy-Coded Sort Storage)策略.为了保证存储写入效率和高吞吐量,在写入和更新数据时,使用哈希存储结构顺序写入,并建立哈希索引.而在系统空闲时段,将哈希存储结构转换为访问高效的排序存储,并建立排序索引.从而实现写入效率、访问效率以及内存利用率的有效均衡.
1 相关工作
内存计算存储层通常使用键值对(key,value)存储,存储时按照哈希结构将数据写入内存.哈希结构存储是一类写性能较高的键值对存储,能够独立处理添加(PUT)和删除(DELETE)操作.虽然哈希存储结构能够为内存计算提供较好的写入性能,但仍存在较多问题,需要对内存计算的存储进行优化.存在的问题是由于哈希表存储时,索引表项所需内存空间较大.因此在存储大量对象时,将会产生大量索引表项,浪费宝贵的内存空间资源.目前国内外关于存储结构的研究很多,已有相当数量的文献提出了各自的见解.许多内存系统利用哈希表来实现快速全局ID到本地地址的转换,例如Trinity、RAMCloud[9]和Tachyon[10].然而,当负载率较低或负载率高导致访问冲突概率增加时,哈希表会浪费大量内存.最严重时会招致哈希表急剧增大,且所有表项都需要重新映射.另外,哈希表需要存储键值对在每个表项中,从而找到正确的key,避免访问冲突.因此,需要降低元数据管理的开销.
Trinity图引擎是一个分布式内存图数据库,目的在于支持算法在上亿节点上支持图算法处理.它基于内存云,利用C#实现键值对数据模型存储.每个节点存储一些相同大小的Trunk(块).为了找到一个键值对,Trinity使用一个两级哈希散列表.首先用散列函数查找Trunk.节点通过全局共享地址查找到块所在节点.然后,在这个节点上使用另一个散列函数获取Trunk内键值对的偏移量和大小.为此,每个Trunk都有自己的哈希表来存储适当元数据.
作为一个分布式内存系统,RAMCloud将所有数据都存储在DRAM的存储系统.在RAMCloud中,Master(主节点)和Backup(从节点)都以日志方式存储数据,日志结构中清理机的垃圾回收也使内存管理更加高效.为实现Master中对象的随机访问,Master为片中最新版本的对象存储一个包含<表标识,对象标识>键值对的哈希表.哈希表被用于在执行存储操作时查找对象,以及在清理过程中确定对象的版本是否最新.如果在清理过程中,查找哈希表未发现片中的某个对象的记录,则意味着这个对象已经被删除.Master记录日志的空闲空间,这些空间是由于存储对象的删除和重写造成的.回收空间是通过间隔一定时间调用日志清理机,读出多个区的活动数据,并在日志头上进行重写,然后清除数据并使其成为空闲片,从而保障空闲区的连续.RAMCloud提供基本的操作来创建和删除表,或在表中增、删和查询对象.从64位全局ID到虚拟地址的映射需要哈希表来实现.另外,RAMCloud还需要存储至少26字节的表标识符、版本号、时间戳、检验和、key长度和key本身.
Tachyon实现层次化存储,能够将数据根据访问频率或用户需求存储在不同的存储介质中,将热点数据存储在内存中.分级存储时,内存作为第0级,SSD为第一级,磁盘作为第二级.Tachyon中存储的文件以树形结构组织,并通过路径做唯一性标识.每个文件分配一个全局唯一性标识,称为FID.Tachyon提供一组API函数用于文件的基本操作,比如create、open、read、write、close和delete等.Tachyon通过master的备用节点进行master的容错处理.Tachyon Master将自身每一步的操作以日志的形式都持久化存储在持久层之中,当Tachyon Master节点出错的时候,备用节点通过读取日志将自身更新成之前master的状态.
2 问题分析
这一小节简要分析现有存储结构带来的问题:(1)描述Tachyon的存储结构;(2)分析访问延迟并阐述存在的问题.为第3节内存优化策略提供理论基础.
2.1 内存文件系统Tachyon
Tachyon是基于内存的分布式文件系统,能够为内存计算框架提供高效的文件访问和共享,为Spark的子项目[11,12].图1为Tachyon的部署结构.Tachyon可以为计算框架Spark和MapReduce提供内存级存储服务,并且可以基于磁盘文件系统HDFS或S3使用其磁盘存储服务.如图2所示,Tachyon部署结构是masterslave主从结构,每个Tachyon存储节点(Tachyon worker)负责对本地存储的内存块进行管理.每一个Spark计算节点(Spark Worker)上,都会部署一个Tachyon存储节点,Spark计算节点通过Tachyon客户端(Tachyon Client)对Tachyon文件系统进行访问,并执行数据的读写操作.Tachyon主节点(Tachyon Master)负责管理所有的Tachyon存储节点,Tachyon存储节点会向Tachyon主节点定时发送心跳(Heartbeat),从而决定存储节点的工作状态以及可用内存空间量.

图1 Tachyon的部署

图2 Tachyon在Spark平台的部署
Tachyon Master类似HDFS的Name Node,负责存放所存储文件的元数据信息.元数据作为Inode,记录属于某个文件的所有块(Block)信息.在Tachyon中,存储的基本单位是块(Block).若块大小为64MB,所需存储文件的容量为1GB,则该文件会存储为16个块.在存储小文件时,尽管小文件占用的空间是实际大小,但却需要占用一个BlockID和元数据信息.当存储大量小文件时,主节点内存需存储的元数据大小急剧变大.
2.2 访问延迟分析
从内存文件系统Tachyon读取文件时,文件下载时间包括以下几个部分:(1)如果Tachyon Client没有缓存元数据,则需要发送读请求到Tachyon Master,其时间开销记为τcm;(2)Tachyon Master查找元数据的缓存,时间开销记为τmetadata;(3)缓存返回到Client,时间开销τmaster;(4)Tachyon Client发送读请求到相关Tachyon Worker,其时间开销记为τcw.(5)Tachyon Worker负责将所请求的文件数据从内存中取出,时间开销记为τmemory;(6)将文件返回给Tachyon Client,时间开销记为τnetwork.
其中,τcm和τcw可以看做常数,因为是发送请求的开销.而τmetadata不能看做常数,因为元数据缓存大小可能会很大,这与元数据大小有关.同样的,τnetwork与文件大小FS,以及网络传输率ratetrans有关.因此,τnetwork可定义为fnetwork(FSi/ratetrans).若有m个小文件,文件大小分别记为SS1,SS2,...,SSm.因此,下载m个文件的总时间为:
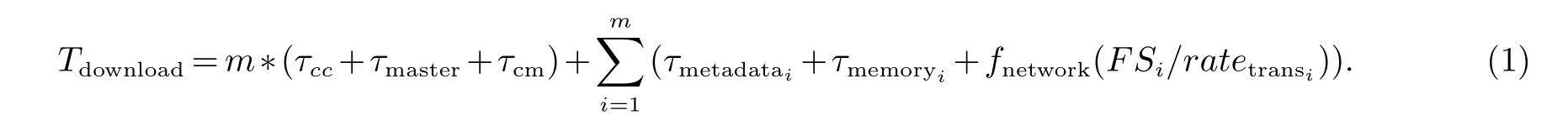
由公式1可知,影响访问开销的因素有:(1)Tachyon Client和主节点之间的通信开销;(2)查找元数据的时间开销;(3)传输文件的网络开销.
2.3 存在问题
现有的存储方式中,使用较多的为哈希存储和排序存储.内存存储系统中主要使用哈希存储,针对读、写优化,但是内存开销大.排序存储:读性能较高,但比哈希存储弱,内存开销极小.虽然内存存储系统与基于磁盘的存储系统相比,能够提高系统吞吐量,降低访问时间.然而,现有的哈希结构存储的查询操作却成为系统的瓶颈.因此,哈希存储结构在为内存存储系统提供较好的写入效率的同时,也存在较多的问题:
(1)访问速度.哈希存储结构有利于写操作,可以有效的提高系统的性能,但却不适合访问查询和搜索.事实上,对于数据密集型应用而言,用户更关心的是系统访问效率和读取所需要花费的时间.如何在更短的时间内为系统提供查询服务,是内存存储系统需要解决的重点.因此,在访问查询时,需要为其建立一个能在尽可能短的时间内响应用户的请求的索引.
(2)索引对内存的占用.目前有较多索引能够满足访问速度快的要求,但同时索引表项也会带来较多的内存开销.当系统有较多小文件或对象存入时,则会占用较多的宝贵内存.
因此,文章对内存计算环境下的存储结构进行优化,提出了一种索引结构存储优化策略.并利用该策略在系统空闲时段,将哈希存储中的数据转换为排序存储并为其建立排序索引,有效的解决访问速度和索引内存占用的问题.
3 索引结构存储优化策略
为了解决哈希存储结构带来的读取访问效率低、索引开销大的问题,提出了存储优化策略.该策略在不影响原系统性能的情况下,利用基于熵编码的排序存储,在系统空闲时段,将哈希存储中的数据根据key进行排序,并为其建立排序索引和查找树.不仅使系统能够在较短时间为用户读取访问提供较好的服务,也能够降低系统的内存回收开销.本小节阐述适应于内存存储系统环境的存储优化策略,一是提出基于熵编码的压缩索引存储算法,二是描述存储优化策略.
3.1 压缩索引存储算法
通过提出一种基于熵编码的压缩索引存储策略(ECSS)将哈希存储转化为查找效率高的排序存储.ECSS算法将内存中存储哈希存储中的键值对(key,value)的数据按key排序,为其建立一个前缀树的数据结构索引,再结合压缩技术进行编码.
该算法分为以下三个阶段:
(1)将key-value根据key进行排序.排序允许高效地将新数据整块插入,新数据可以排序并且可以顺序地合并到已有的排序数据中.由于目前已有许多效率较高的排序算法,因此排序部分在文章中不再赘述.
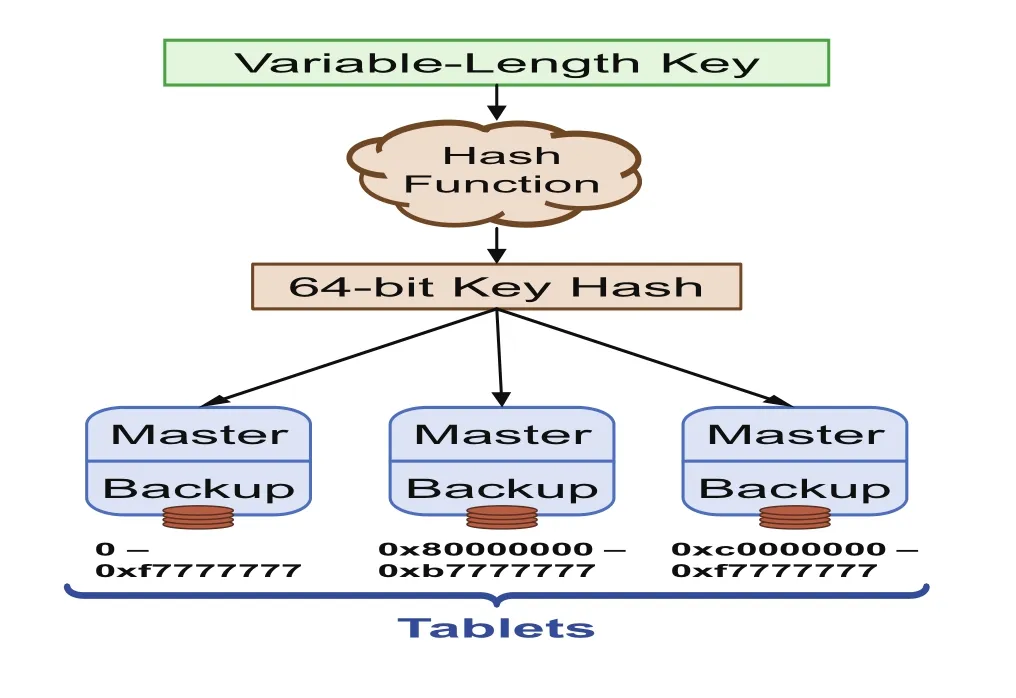
图3 通过哈希将变长的key转换为64位的key
(2)通过一个前缀树索引存储已排序数据的key,每个叶子节点代表一个key.key为可变长度,通常系统的key的数量相对于key的值域非常稀疏,因此前缀树可以减少内存开销.需要说明的是:为了简化问题,我们假设key是均匀分布的64-bit的hash,而变长的key可以通过哈希函数将变长的key映射,转变为64-bit的长度,如图3.此时,对key而言的最短前缀的字典树便作为这些排序数据的索引.一个键的最短唯一前缀是一个key能够与其他key区分开来的最短前缀.在这样一个字典树中,当查找目标key时,最短唯一前缀将会快速查找到一个具有直接索引的叶子节点处.
(3)对该索引树进行压缩存储.一个典型的树形数据结构并不适合内存存储层,因为每个结点都需要占用大量内存开销的指针,每个占2到8字节.我们使用一个压缩递归来消除指针.前缀树的特性是,除了叶子结点,每个中间结点都必然有左右子树.
因此,一颗前缀树表达式可由下列公式(2)递归定义:

其中,L是其左子树,R是其右子树,/L/是左子树的叶子节点个数.
ECSS使用递归的方式对前缀树进行编码.生成前缀树编码的方法是按先序遍历的顺序,记录下每个中间结点的左子树的叶子结点个数.建立索引树以及生成编码的伪代码实现部分详见算法1,算法2.当然,查询时也需要解码和解压缩,如果生成排序存储后只有一颗前缀树,那么查询任何key都需要解压整个前缀树.为了保证查找时间,可以根据系统情况对于不同的内存分区建立多个前缀树,并给定相应的哈希表.每个分区内有一颗前缀树.查询一个key只需解压对应分区的前缀树.查找键查找key的工作由逐步读取前缀树表达式来实现,在此不再赘述.

为了能够更加清晰的阐述该算法,这里举一个简单的例子.假设一共有8个key,每个key长为6bits,且对应的数据已按照key的大小进行排序,如表1所示.找出这些key的最短前缀,由表1可知只需非阴影部分的bit就可以区分所有key,而阴影部分是不必要的.因此所有key被表示为前缀树,那么生成的前缀索引树应如图4,如000011被表示为0000.进一步对该前缀树进行编码存储,编码为4321311,除了叶子结点和根结点,每个中间结点都对应一个数字,这个数字是其左子树中叶子结点的个数.


表1 按大小排序后的key

图4 生成的前缀树
需要查询10010010时,自顶向下,找到100时达到叶子结点,因为在其前面有4个叶子结点,key在排序存储中的索引偏移是5(从1开始).读取偏移为5的key进一步确认是否匹配.
3.2 存储优化策略
为了实现高性能目标,哈希存储使用一个内存中的哈希表,将每个key映射到其文件的偏移处.对于基于哈希的内存分配,主要的瓶颈就在于清理器(log cleaner).碎片管理,或者说内存回收是非常昂贵的.特别是随着内存利用率的上升,回收的成本也越来越大.因为每个key都必须存储一个4字节的指针,哈希存储与排序存储相比,其索引仍可算为内存密集型.
排序存储使用一个编码压缩索引,按照排序键存储key-value数据.由于将单个项插入数据的开销较大,因此本文提出了存储优化策略,将多个哈希存储的块与排序存储的结果进行合并,构成一个新的排序存储,在整个过程中收集垃圾删除或重写键值.我们将内存分为两个分区,使key分布不相交,两个分区分别存储哈希存储和排序存储.
优化策略共包含两步:(1)排序哈希存储;(2)顺序合并排序的哈希存储数据和排序存储.首先,将哈希存储中所有数据进行排序,这个任务通过遍历每个哈希存储中的项来实现,并将其排序.随后,对排序后的哈希存储数据在排序存储中和已有的已排序数据一起顺序合并,生成一个新的排序存储.无论是复制或删除操作都会消耗key.例如,通过向前移动相应存储的指针,若没有动作应用于key,下一次比较时,现有的key仍然可用.
在每个步骤都完成后,已有的排序存储会由新的自动代替.在合并完成之后,无论是已有的排序存储还是新的排序存储都存储在内存上.另外,哈希存储和之前的排序存储在合并期间可为查找提供服务.
为了查询或访问key,在哈希存储和排序存储中按顺序搜索键值,并且在最新的存储中返回所查找的值.如果删除的未被找到,将会停止搜索并返回“未查出”.另外,根据经验,在凌晨0点到7点时段用户访问数较少,此时服务器负载较低.由于用户请求少,服务器负载低,服务器内存中存储数据的合并与生成压缩索引算法的执行并不影响用户体验.因此,可以选择系统空闲时段执行该算法.
在系统繁忙时段,使用哈希存储系统为其建立哈希索引,可提高用户写入数据的速率.在系统空闲时段,将哈希存储中的有效数据根据基于熵编码的压缩索引算法进行排序,并为其建立排序索引,在提高访问效率的同时,实现了对内存中空闲碎片的合并,减少了内存清理器的工作量.
4 实验评价与比较
4.1 实验环境
为了证明上述理论的有效性,文章展开一系列相关实验.实验集群工作节点配置如表2所示,共9个节点,8个节点作为存储服务器,1个节点作为主节点,连接在了同一个交换机上.其中每个节点为2GB内存,100G硬盘.磁盘上副本个数为3,备份服务器缓冲区大小默认为64MB.

表2 Worker节点配置参数
为了阐述提出的算法能够提高小文件在内存存储系统的内存利用率,对基准测试数据集YCSB Benchmark展开实验,并与未进行存储优化的内存存储系统吞吐量、内存开销和延迟的评价进行对比.
4.2 实验分析
采用不同的存储策略,分别对YCSB测试数据集展开实验,并对结果进行分析.我们使用YCSB来生成key-value负载:使用10%写入、90%读取作为高负载;以及50%写入、50%读取作为低负载,其中key为64bit,value大小为1000字节.实验对于单一哈希存储算法、单一排序存储算法以及ECSS策略进行评价.
(1)系统吞吐量
系统吞吐量的评价在于系统高负载和低负载时,系统能够提供的访问请求个数的评估.如图5所示,该存储策略以支持平均3 000次插入1KBkey-value对/s,同时支持33 000请求/s.在无写入请求时,SILT支持46K请求/s.在没有请求时,可支持写入率为23K写入/s.在删冗的负载50%的写,50%的读时,可以处理72K请求/s.具体表现在高请求负载(33K请求/s)和低请求负载(22.2k请求/s)时,1KB key-value对,表明在整个过程中,SILT忙于合并哈希存储到排序存储,从而优化其索引大小.其写入负载下的性能受到需要转换的合并数据时间的限制,后台的操作完成I/O资源,导致请求延迟和吞吐量的均衡.
内存开销主要体现在两方面:平均索引大小和总索引大小.图6为使用不同的存储算法,利用YCSB生成50%写入、50%读取负载上传数据到集群时,生成的平均索引大小的对比情况.

图5 使用ECSS策略时不同负载下系统的吞吐量

图6 不同存储策略下平均索引大小
从图6可以看出,在优化前的内存存储系统集群中,主服务器中平均索引大小较大.这是由于内存存储系统的哈希存储机制使得即使是几百KB以内的小文件与较大文件一样需要使用同样大小的索引,在内存中占用较多的空间.在使用排序存储方式时,数据集上传后所占的内存空间较少.

图7 不同存储策略下总索引大小

图8 不同存储策略下客户的平均访问时延
同样,图7为在整个建立索引的过程中,总索引开销的大小.哈希存储建立索引所占的总空间要远远大于排序存储方式和ECSS策略存储.ECSS居于二者之间,排序存储生成的索引占用的存储空间最少.
另外,需要强调的是:对于写入效率而言,哈希存储的效率最高,ECSS策略次之;排序存储的复杂度最高,且实施时开销较大.
(2)访问延迟
图8为在并发访问的客户端个数增加的情况下,随机访问数据集中100个文件,并计算得出的平均访问时延.由图8可看出,随着client个数的增长,文件的平均访问时延也在增加.结合图5、6、7可知,优化后的内存存储系统集群能够提高内存的利用率,同时降低文件的访问延迟.
文件平均访问延迟较为明显的是基于哈希结构的存储,由于哈希结构存储为按照文件写入时间顺序写入内存,因此需要额外添加一个哈希索引.但因为哈希索引文件的效率也有待提升,因此增加了访问时延.
排序存储和ECSS存储策略当中都包含了已按照key的大小进行排序的排序索引,通过前缀树能够较快的判断所需访问的key是否存在于内存中,并且能够快速定位数据.而ECSS策略中又包含了部分哈希存储的索引,因此相对于排序存储,访问时延略长一些.通过存储效率和访问效率这两个方面的对比,可以看出,通过ECSS存储优化策略,能够使内存存储系统集群的主服务器索引的内存利用率得到有效提高,同时较好的平衡查找效率与时间延迟的关系.
5 总结与展望
文章研究内存计算环境下存储层的哈希结构存储的问题,并提出优化策略:在系统繁忙时段,使用内存存储系统的哈希存储系统,为其建立哈希索引,提高用户写入数据的速率;在系统空闲时段,将有效哈希数据根据基于熵编码的压缩索引算法进行排序,并为其建立排序索引,在提高访问效率的同时,实现了对空闲碎片的合并.通过对基准测试集YCSB进行的实验对比,根据存储效率和访问效率两个评价标准的验证,这种策略能够有效的降低访问延迟,同时提高存储效率.
下一步将研究存储读取效率及参数优化问题.文中所提及的数据集负载大小的参数均可变,可根据实际负载情况动态调整为最适合的参数,以达到更好的内存利用效果.内存架构的工作模型需进一步研究和探讨,可以通过虚拟化技术的应用,其内存利用率仍有可能加以改善.
参考文献:
[1]张一鸣,彭宇行,李东升.面向在线数据密集型应用的分布式存储研究综述[J/OL].[2013-03-26].中国科技论文在线.http://www.paper.edu.cn/releasepaper/content/201303-838.
[2]Li M,Tan J,Wang Y,et al.SparkBench:a spark benchmarking suite characterizing large-scale in-memory data analytics[J].Cluster Computing,2017:1-15.
[3]英昌甜,于炯,鲁亮,刘建矿.基于小文件的内存云存储优化策略[J].计算机应用,2014,11(34):3104-3108.
[4]英昌甜,于炯,卞琛,等.并行计算框架Spark的自动检查点策略[J].东南大学学报(自然科学版),2017,47(2):231-235.
[5]Vamanan B,Sohail H B,Hasan J,et al.Timetrader:Exploiting latency tail to save datacenter energy for online search[C]//Proc of the 48th Int Symp on Microarchitecture.New York,NY:ACM,2015:585-597.
[6]Fan B,Lim H,Andersen D,et al.Small cache,big ef f ect:provable load balancing for randomly partitioned cluster services.[C]//Proceedings of the ACM Symposium on Cloud Computing,Cascais,Portugal,2011.
[7]Wang P,Sun G,Jiang S,et al.An efficient design and implementation of LSM-tree based key-value store on open-channel SSD[C]//Proceedings of ACM European Conference on Computer Systems,Amsterdam,the Netherlands,2014:1-14.
[8]孔兰菊,李庆忠,史玉良,等.面向SaaS应用基于键值对模式的多租户索引研究[J].计算机学报,2010,33(12):2239-2247.
[9]Zaharia M,Chowdhury M,Das T,et al.Resilient distributed datasets:a fault-tolerant abstraction for in-memory cluster computing[C]//Usenix Conference on Networked Systems Design and Implementation.Berkeley,CA,US:USenix,2012:141-146.
[10]Li Haoyuan,Ghodsi A,Zaharia M,et al.Tachyon:Reliable,memory speed storage for cluster computing frameworks[C]//IEEE Conference on SYSTEM-ON-CHIP.Piscataway,New Jersey,US:IEEE,2014:1-15.
[11]Li Haoyuan,Ghodsi A,Zaharia M,et al.Tachyon:Memory throughput I/O for cluster computing frameworks[C]//Proc of 7th Workshop on Large-Scale Distributed Systems and Middleware.New York:ACM,2013:1-6
[12]Zaharia M,Chowdhury M,Franklin M J,et al.Spark:Cluster computing with working sets[C]//Usenix Conference on Hot Topics in Cloud Computing.Berkeley,CA,US:USenix,2010:1765-1773.
