基于异常序列剔除的多变量时间序列结构化预测
2018-05-15毛文涛蒋梦雪李源张仕光
毛文涛 蒋梦雪 李源 张仕光
在实际应用中,时间序列数据的变化往往受多种因素影响.传统的时间序列预测算法主要针对影响事物变化的某一种因素进行单个时间变量的预测.而若对事物变化趋势进行更加综合、准确的评估,则需对多个相关因素进行同时预测,即多变量时间序列预测.相比于单变量时间序列预测,多变量时间序列预测可同时预测多个变量的走势,同时可利用变量之间的相关信息提高动态预测的精度与稳定性,已得到越来越多学者的关注.但是,传统预测方法直接应用于多变量时间序列预测中,容易受变量之间冗余作用、误差累积和缺乏关联信息等特点的影响,无法取得令人满意的预测效果.因此,选择一个合适的建模方法对多变量进行更为准确地预测有着重要的理论价值和现实意义.
目前,多变量时间序列预测研究已取得一定的进展.传统的预测方法将多变量分解为多个单变量,利用支持向量回归机(Support vector machine,SVM)等方法[1]对每个变量单独进行回归建模.这种方法简单明了,但是重复建模增加了计算量,同时未能有效利用变量之间的结构信息.一种典型的改进方法是利用时间序列本身的系统特性信息和数据特点进行预测.其中,张勇等[2]利用最大Lyapunov指数理论,选取多个邻近参考点,实现了对多个混沌序列的同时预测;针对股指期货价格预测问题,Sun等[3]利用模糊C均值对数据进行预处理,并结合粗糙集算法建立模糊逻辑关系组,实现对多个变量走势的预测;韩敏等[4]利用主成分分析方法实现对输入变量降维,再将动态储备迟用作核函数充分映射多元混沌时间序列的动力学特性实现了避免过拟合,提高预测精度.另一种做法是围绕着多变量输出结构的算法改进.例如,Wang等[5]提出基于极限学习机的在线多变量时间序列预测方法,对多变量序列进行相空间重构后,建立极限学习机预测模型,实现在线预测;Han等[6]提出基于SCKF-γESN模型的在线多变量时间序列预测方法,利用平方根容积卡尔曼滤波算法更新γ回声网络参数,以实现对多变量序列的在线预测,同时在滤波算法中加入异常值的检测,使得预测结果更加稳定;Chen等[7]利用K近邻和互信息获取多变量时序数据的重要性表示,并据此重构样本,利用改进的加权LS-SVM进行预测.但是,这些方法大多通过多变量数据的简单融合构建预测模型,缺乏在算法结构上针对多变量序列特点的有效改进.
由上述分析可知,对多变量时间序列预测来说,预测效果的好坏直接取决于数据中蕴含的有效信息量.而实际应用多为小样本预测问题,若能有效利用变量之间的结构化信息,则可一定程度弥补样本数不足带来的信息缺失,有利于提高小样本下预测模型的稳定性和精度.因此,提升多变量时间序列预测效果的关键在于:1)如何有效挖掘序列之间的依赖关系等结构化信息?2)如何构建适用于多变量序列预测的预测模型?针对这两点,本文提出一种基于异常序列剔除的多变量时间序列预测方法.该方法首先给出基于模糊熵的时间序列聚类算法,实现对相似序列的初步划分,并引入主曲线,构建异常时间序列检测算法,对其中的异常序列进行剔除,最后采用多维度支持向量回归机(Multi-dimensional support vector regression,M-SVR)[8]对最终得到的相似序列进行多输出时间序列预测.M-SVR是一种具有多输出结构的支持向量机,不仅对小样本有快速和准确的回归预测效果,而且,利用超球损失函数度量多个输出端的的风险损失,可有效利用输出端之间的结构化信息,目前已在多步超前时间序列预测[9]等问题取得成功应用.但根据作者文献调研,尚未发现M-SVR在多变量时间序列预测中的应用.鉴于此,本文采用M-SVR作为基础建模算法,旨在利用M-SVR的结构化输出特性,选择具有相关性的序列同时进行预测,以达到更好的预测效果.此外,本文从理论上给出了异常序列剔除的信息损失上界和模型可靠度下界,从而证明所提算法的合理性.最后采用混沌时间序列数据与五个实际数据集数据进行仿真实验,实验结果验证了所提算法的有效性.
1 相关理论
1.1 层次聚类方法
层次聚类方法是一种常用的聚类方法,分为凝聚层次聚类方法和分裂层次聚类算法.该类算法的核心思想是递归地采用自底向上或自顶向下策略对数据对象进行合并或分裂.分裂层次方法是把一个给定的数据对象族迭代地分裂,进而形成更小的数据对象.该类算法的优点是能够获取到不同粒度的多层次聚类结构,但是算法的复杂度至少为O(n2).而凝聚层次方法从每一个数据对象开始,迭代地进行合并,形成更大的数据对象簇.目前使用的层次聚类方法多为凝聚层次聚类,中间的区别一般是定义的类间距离不同.此外,该类算法需要事先给定一个族合并或分裂的终止准则,并且某个族一旦完成合并或分裂步骤就无法撤消[10].层次聚类是一种嵌套聚类的方法,通用性强,适用于小数据集[11].
1.2 时间序列的相似性度量
时间序列的相似性度量是衡量两个时间序列相似的标准,其有效性直接关系到后续工作的性能.目前对时间序列相似性的度量主要有两种方法.
1)欧氏距离通过序列中对应值计算得到对应的相似性,其计算公式为
其中,i为序列中的第i个值[12].时间序列的欧氏距离需要两个序列等长,且要求序列的值一一对应.
2)动态时间弯曲(Dynamic time warping distance,DTW)距离[13]是一种通过弯曲时间轴来更好地对时间序列形态进行匹配映射的相似性度量方法.DTW 距离在两个时间序列之间寻找最小的映射路径,允许一个序列中的点对应于另一个序列中的多个相邻的点.DTW 不需要利用领域知识,只是假设相近的序列存在低消耗的平移匹配,并在时间序列分类上取得了广泛应用[14].DTW 距离是一种基于距离测量指标的算法,其基本假设前提为数据符合正态分布.设序列s的长度是M,序列c的长度是L,两个时间序列的DTW距离计算过程如下:首先计算矩阵中的(i,j)两点之间的欧氏距离:d(si,cj)=‖si−cj‖2,得到一个M×L的距离矩阵,然后将两个序列的规整路径定义为W=(w1,···,wk),其中wk=(i,j)k=d(si,cj).DTW 的目的是找到一个从(1,1)到(M,L)使取到最小值的单调增长路径[13].最佳路径是γi,j=d(si,cj)+min{γi−1,j−1+γi−1,j+γi,j−1}.
1.3 主曲线
主曲线是通过数据集“中间”的光滑无参数曲线,基于一定概率分布下曲线的“自相合”特性,能将数据信息保持好,有效勾勒出原始信息的轮廓[15],目的是找到一条通过数据分布“中央”并能够真实反映数据的形态的曲线,这意味着此曲线是数据集合的“骨架”,数据集合是这个曲线的“云”,所以主曲线对数据的信息保持性好.具体步骤如下[16]:
步骤1.令初始曲线f(j)(λ)为X的第一主成分,设j=0.
步骤2.对所有的x∈Rd,求投影指标
步骤3.定义在x上f的投影点为
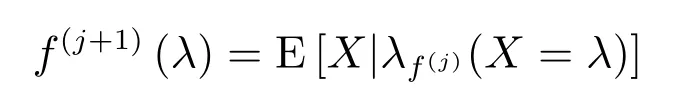
步骤4.如果1−Δ(f(j+1))/Δ(f(j))小于某个阈值,则停止(其中Δ(f(j))表示点x到曲线f的欧氏平方距离),否则令j=j+1,转步骤2.
2 基于异常时间序列检测的多变量时间序列预测
为提高多变量时间序列预测的准确度和稳定性,本文提出一种基于异常时间序列检测的多变量时间序列预测方法,步骤如下:
步骤1.计算各条时间序列的模糊熵,通过比较模糊熵值判断得到序列之间的相似度,选择层次聚类算法进行聚类以得到初步的相似序列;
步骤2.对各类别中的序列计算主曲线,根据各个序列到主曲线的距离求得异常因子,并据此进一步剔除聚类结果中相似性相对较弱的序列;
步骤3.将得到的相似序列作为输入,利用MSVR进行多输出建模.
整体算法流程如图1所示.
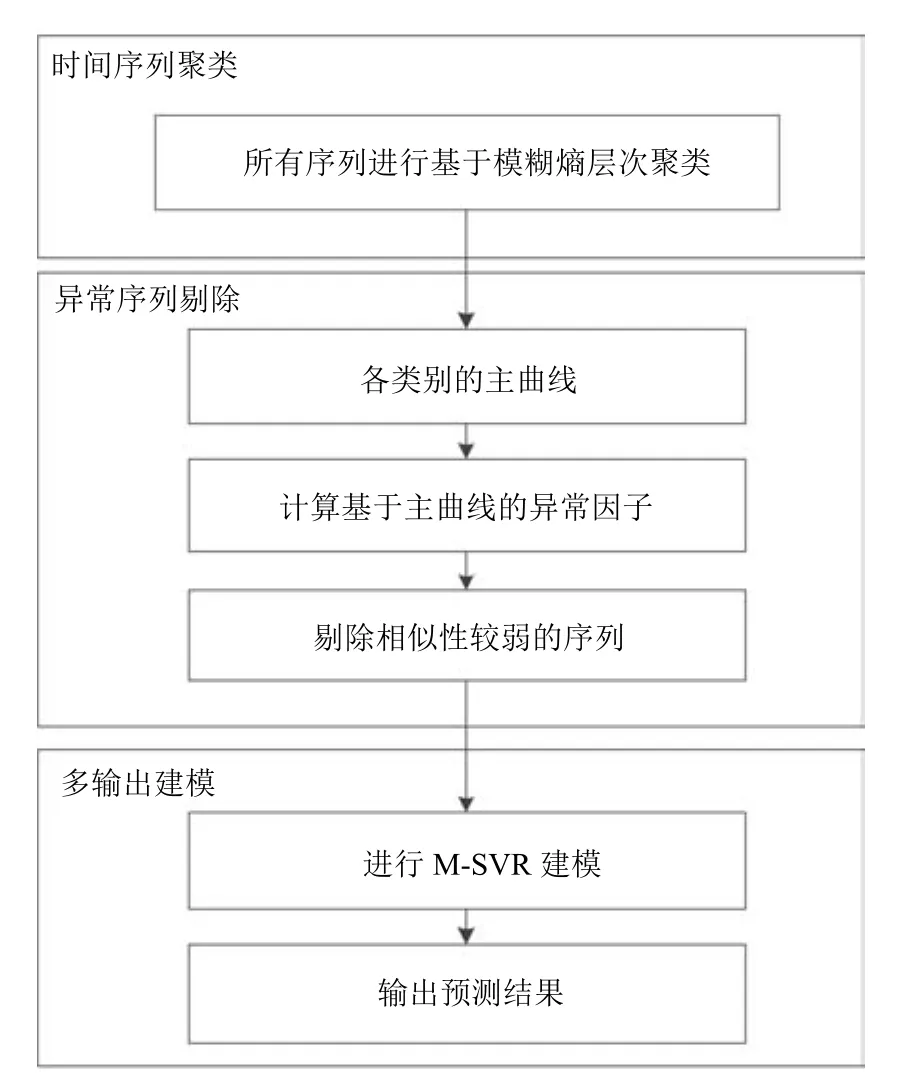
图1 算法流程图Fig.1 The flowchart of the algorithm
2.1 定义
对已知序列定义如下:{Xi},i=1,···,M,其中,Xi为{xj},j=1,···,N.M表示序列个数,N代表样本数.
定义1.剔除序列过程中序列权重:构建已知序列集D的主曲线,则D中每条序列xi对应的序列权重定义为
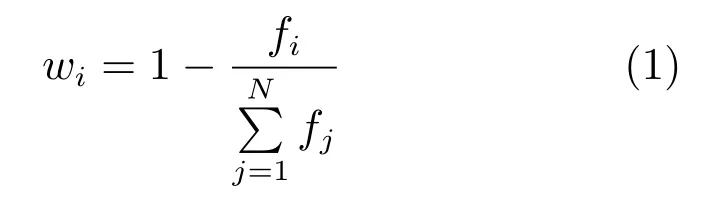
其中,fi为序列xi到主曲线的DTW 距离.由式(1)可知,序列xi到主曲线的距离越小,其对应的序列权重越大,反之fi越大,wi越小.
定义2.序列的CP-距离:通过距离参数衡量各序列在整个序列挑选过程中的相似度.
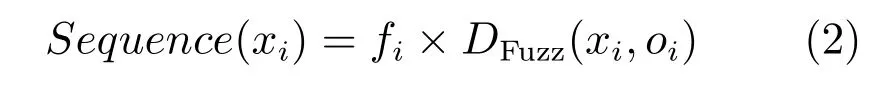
其中,fi为序列xi到主曲线的DTW距离,oi为聚类中心,DFuzz(xi,oi)为序列到聚类中心的距离.由式(2)可知,当序列到聚类中心和主曲线的距离越小,其对应的CP-距离越小.
定义3.整个序列挑选过程中序列权重:针对聚类和主曲线的内容可知,序列权重跟序列到主曲线的DTW 距离成反比,与序列到聚类中心的距离成反比,定义如下:
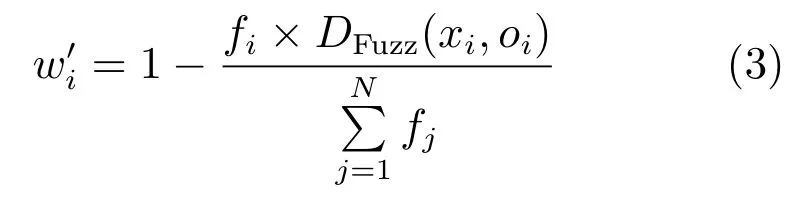
其中,N和分别为序列数和序列到主曲线距离之和.
2.2 基于模糊熵的时间序列聚类算法
为有效识别序列之间的相似程度,本文首先对时间序列进行初步的相似性划分.基本思想是利用时间序列的模糊熵的大小作为衡量序列之间相似性的标准,对时间序列进行凝聚层次聚类,建立初始模型.时间序列凝聚层次聚类将初始序列的每个对象看作一类,根据相似性度量准则计算类间距离进行合并,直至满足终止条件.该方法不需首先确定聚类中心,可以充分利用类间距离将相对相似的序列聚成一类.模糊熵采用模糊隶属度函数计算向量之间相似度,从而使得熵值连续平稳,对于不同的参数结果稳定,抗噪性强[17],因此适合用做层次聚类的类间距.该算法步骤如下:
步骤1.将已知各序列视为一类,计算每两个序列之间模糊熵的差值作为类间距离.
步骤2.根据步骤1中得到的类间距离将距离最近的两类合并成一类.
步骤3.用average-linkage衡量两类A与B之间的距离:
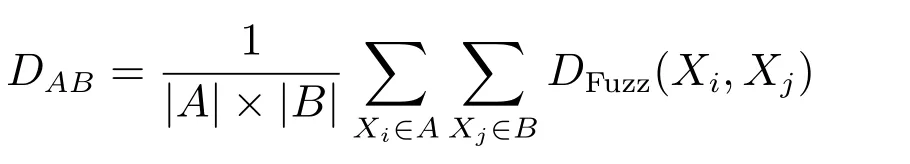
其中,1≤i,j≤M,ij,|A|和|B|分别代表类A及类B的大小.
步骤4.重复步骤2和步骤3,直到满足事先给定的聚类类别数,即聚类完成.
由上述过程可知,该时间序列聚类算法采用了模糊熵作为类间距离的衡量方式,可在整体上有效度量时间序列的相似度,从而实现对相似序列的初步划分.
2.3 基于主曲线的异常序列的检测
从实验结果可以看出,在第2.2节得到的相似序列中,往往会因为人为设置类别初始数目等原因,将一些相似性较弱的序列强制聚到某一类中.本文将这类序列定义为聚类结果中的异常序列.异常序列的存在会减弱序列之间的相似度,从而降低M-SVR的结构化预测效果.因此,有必要对初步的聚类结果进行进一步的筛选,剔除相似性相对较弱的异常序列.
根据第1.3节分析,主曲线具有可有效勾勒出原始信息的轮廓和对数据信息保持性好的优点[15].因此,本文在初始阶段聚类的结果上,通过计算类中序列数据的均值,找到距离均值距离最近的两条序列,求得这两条序列的主曲线作为本类的主曲线.
序列集合中,x序列到主曲线S的可达距离定义为
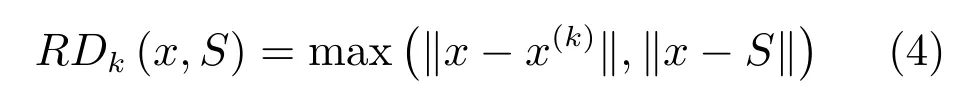
其中,x(k)表示样本中距离序列x的k近邻样本,‖x−S‖指从x到S的DTW 距离.基于式(4),x的局部可达密度为
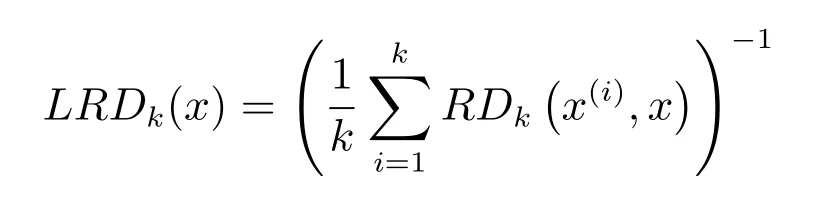
x局部异常因子可定义为x(i)的局部可达密度的平均值与x局部可达密度的比,即
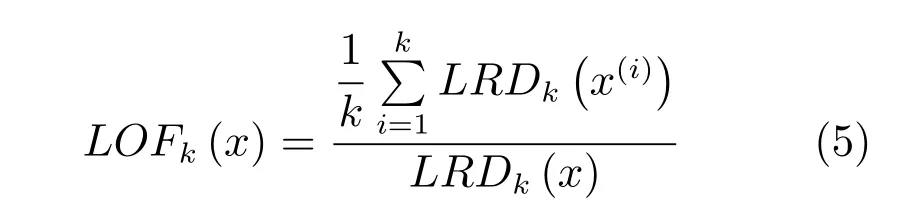
LOFk(x)的值越大,x的异常度就越大.当x(i)的周围密度较高,而x的周围密度较低时,局部异常因子变大,x被视为异常序列.相反,当x(i)的周围密度较低,而x的周围密度较高时,局部异常因子减小,x被视为正常序列.因此,可以根据LOFk(x)的值,从聚类结果中将异常序列进行剔除.检测异常值在统计学上已有多种方法,本文借鉴置信区间的概念,采用如下方法:若LOFk(x)>mean(X)+n×std(X),则视为异常序列,其中mean(X)为序列集合X的局部异常因子的均值,std(X)为其标准差.由于此处要剔除的通常为局部异常因子明显较大的序列,因此在本文实验中,n直接设为0.5即可有效识别各数据集中的异常序列.
2.4 M-SVR建模
通过以上步骤得到具有依赖关系的相似序列,根据这些序列构建输入样本集.
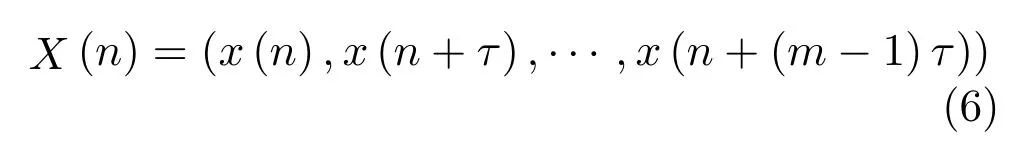
其中,n=1,2,···.相应序列的下一时刻值作为输出Yi=(x(n+mτ)),其中m为嵌入维,τ为时延,利用M-SVR实现对相似序列的多输出回归建模.其中M-SVR优化目标为[18]
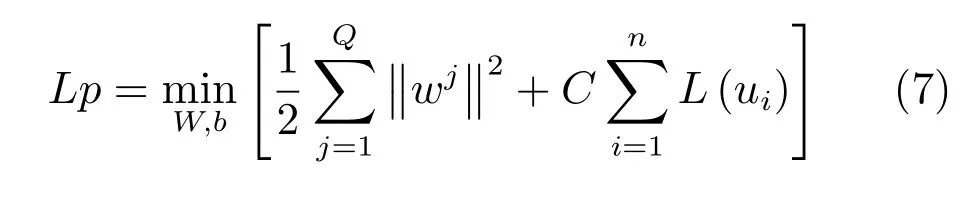
利用一阶泰勒展开式可得到其二次近似[18]:
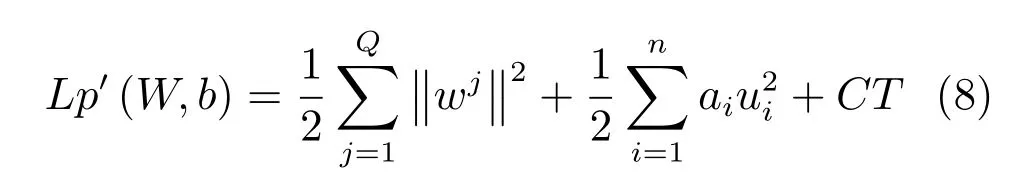
其中k为迭代次数,CT为独立的高阶项.
通过利用加权迭代最小二乘法(Iteratively reweighted least squares,IRWLS)连续迭代过程中线性搜索变量的下降方向,并收敛到最优值.由于以上求解可转换为对参数β和b的求解,过程如下[18]:
步骤1.设置初值k=0,βs=0,bk=0,计算和ai.
步骤2.计算βs和bs.
步骤3.采用线性搜索,计算βk+1和bk+1,并得到和ai,判断是否收敛至最优值.若不收敛,返回步骤2.
利用上述过程得到输出端的参数,可构建得到相应的回归模型.
3 理论分析
本文所提方法旨在利用M-SVR的结构特性,选择具有相似性的多变量时间序列同时进行预测,关键在于根据序列的异常因子大小进行异常序列的剔除,得到最具相关性的序列.为说明该方法的合理性,本文从信息熵的角度证明在异常序列检测剔除的过程中的信息损失存在上界[19].同时,为证明本算法的有效性,本文从模型可靠度[20]入手证明在整个序列挑选的过程中模型的可靠度存在下界.
3.1 异常序列剔除过程信息损失
设剔除序列集合为Ψ={(xj,tj),j=1,2,···,M−m},其中xj对应的序列权重为wj,则剔除序列集Ψ的总体序列权重之和为
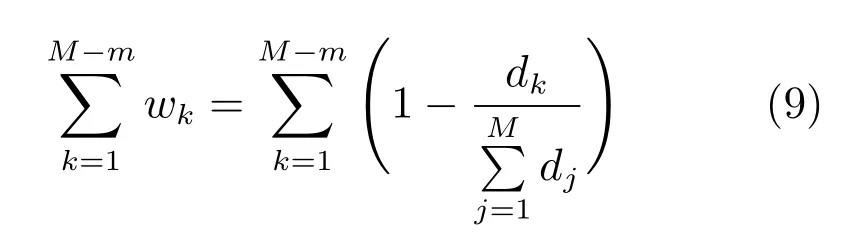
易知,表示序列集Φd中所有序列到主曲线的DTW 距离之和,对已知序列来说,为定值,故令则Ψ的总体序列损失权重之和为
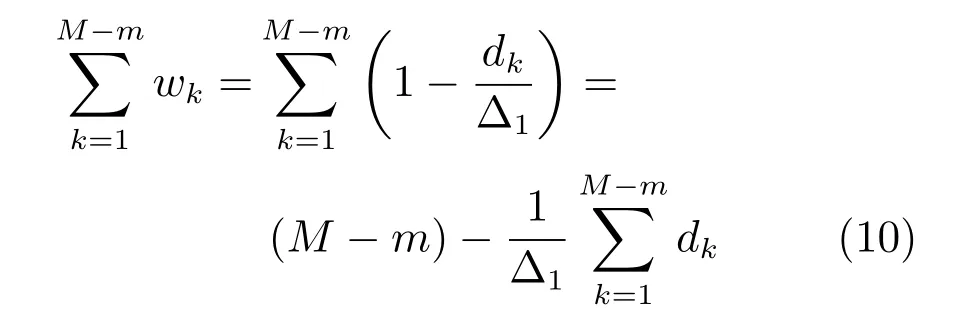
定理1.令H(Ψ)表示异常序列剔除过程中的整体信息损失,那么有
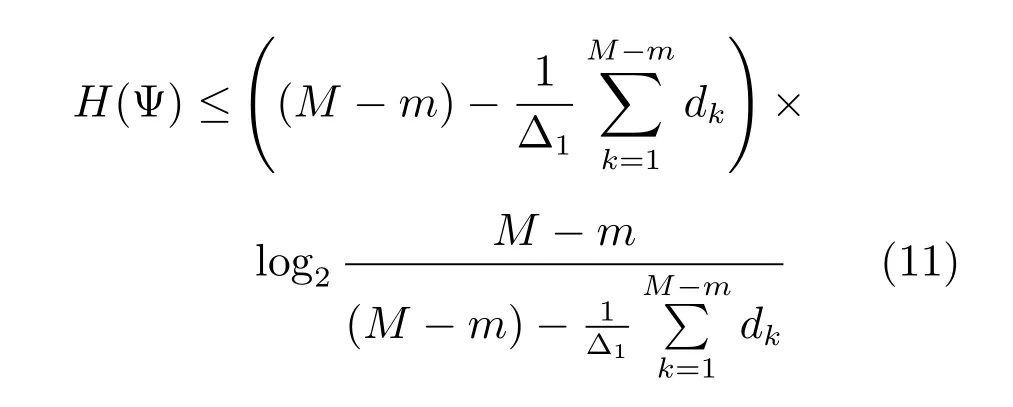
其中,整体信息损失大小H(Ψ)的上界仅与剔除序列集Ψ中所有序列到主曲线的DTW距离之和有关.
证明.根据熵的定义,有
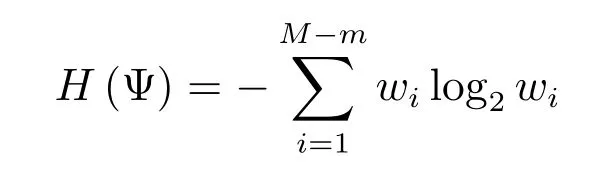
根据最大熵原理,当每一个wi都取相同的值时,H(Ψ)达到最大值.则有
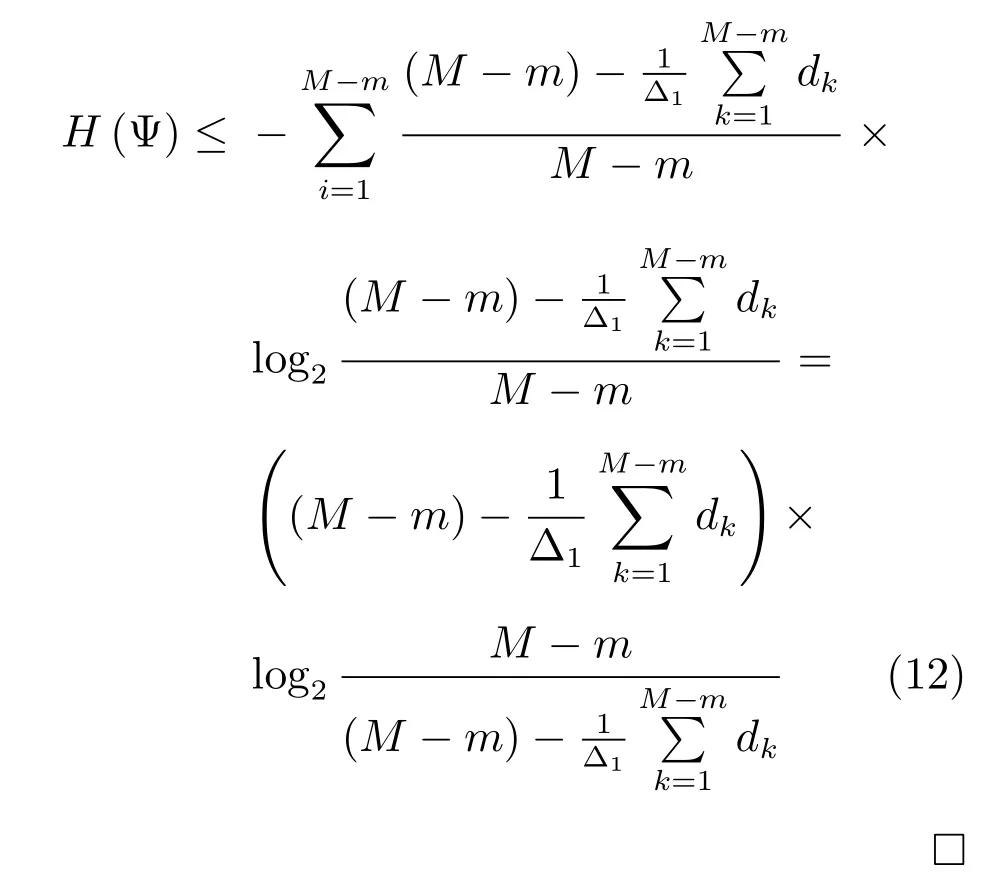
由式(12)可以看出,H(Ψ)上界仅和剔除的序列到主曲线的DTW距离有关,dk越大,该界越小.
定理1从熵的角度给出异常序列剔除过程中的信息损失存在上界,在理论上证明了根据序列到主曲线的DTW 距离剔除异常序列样本的可行性与有效性.考虑极端情况,若剔除的序列到主曲线的DTW 距离趋近于无穷大(即极端不相似),则对应的信息损失上界趋近于无穷小,这意味着该序列对整体信息几近可忽略不计,进一步证明了本文所提异常序列检测方法的合理性.
3.2 模型可靠度
根据上述对算法的描述可知,假设已知序列{Xi},i=1,···,M,其中,Xi为{xj},j=1,···,N.M表示序列个数,N代表样本数.挑选之后序列从原来的{Xi},i=1,···,M到选取得到的{Xj},i=1,···,n.整体摒弃的序列集为{Xt},t=1,···,M−n.已知序列xi的权重为wi,损失序列集合的总权重之和为
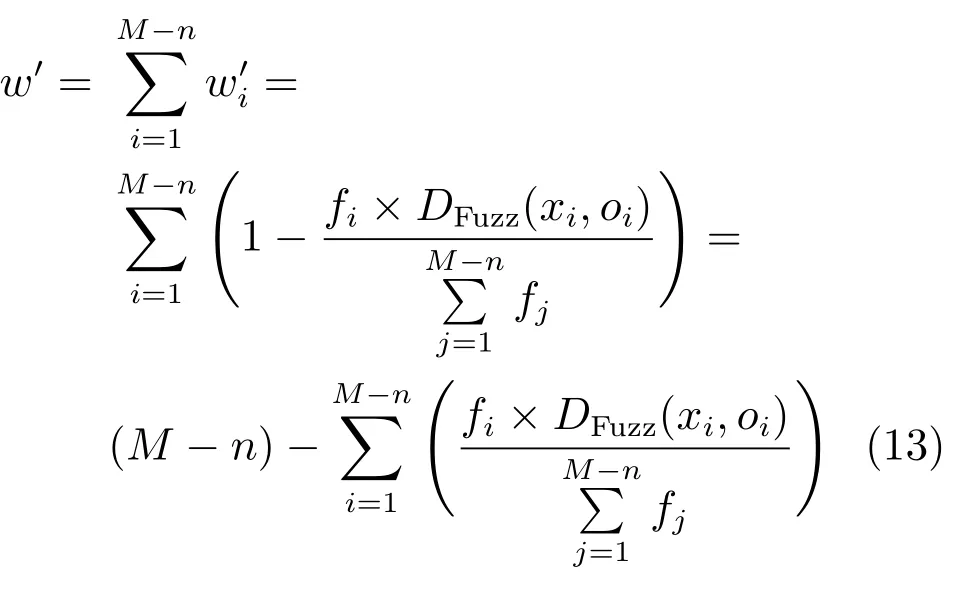
则预测值相较于真实值的偏离率
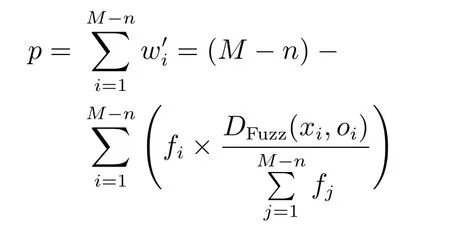
预测值与真实值的差值
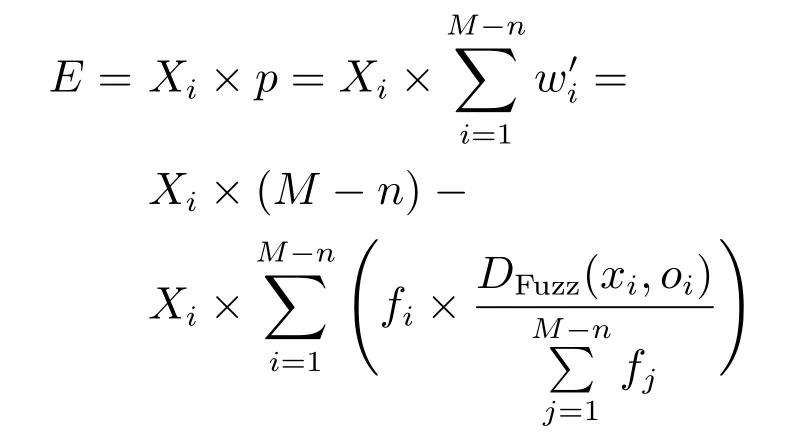
已知阈值θ的衡量预测效果,则预测值与真实值的差值E超出θ时为预测效果不理想的一类L,综上可知,L与p呈正相关关系.
定理2.由上述描述可知,此时模型的结果服从二项分布,在给定置信度α的条件下,模型可靠度的求解公式为
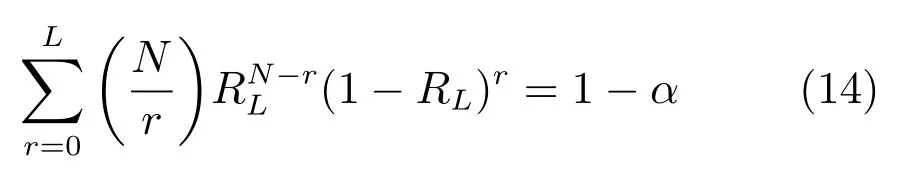
则模型的可靠度RL存在下限,且仅与序列CP-距离有关.
证明.由于已知序列个数固定,聚类之后聚类中心固定,序列到对应主曲线的投影距离和为定值,已知
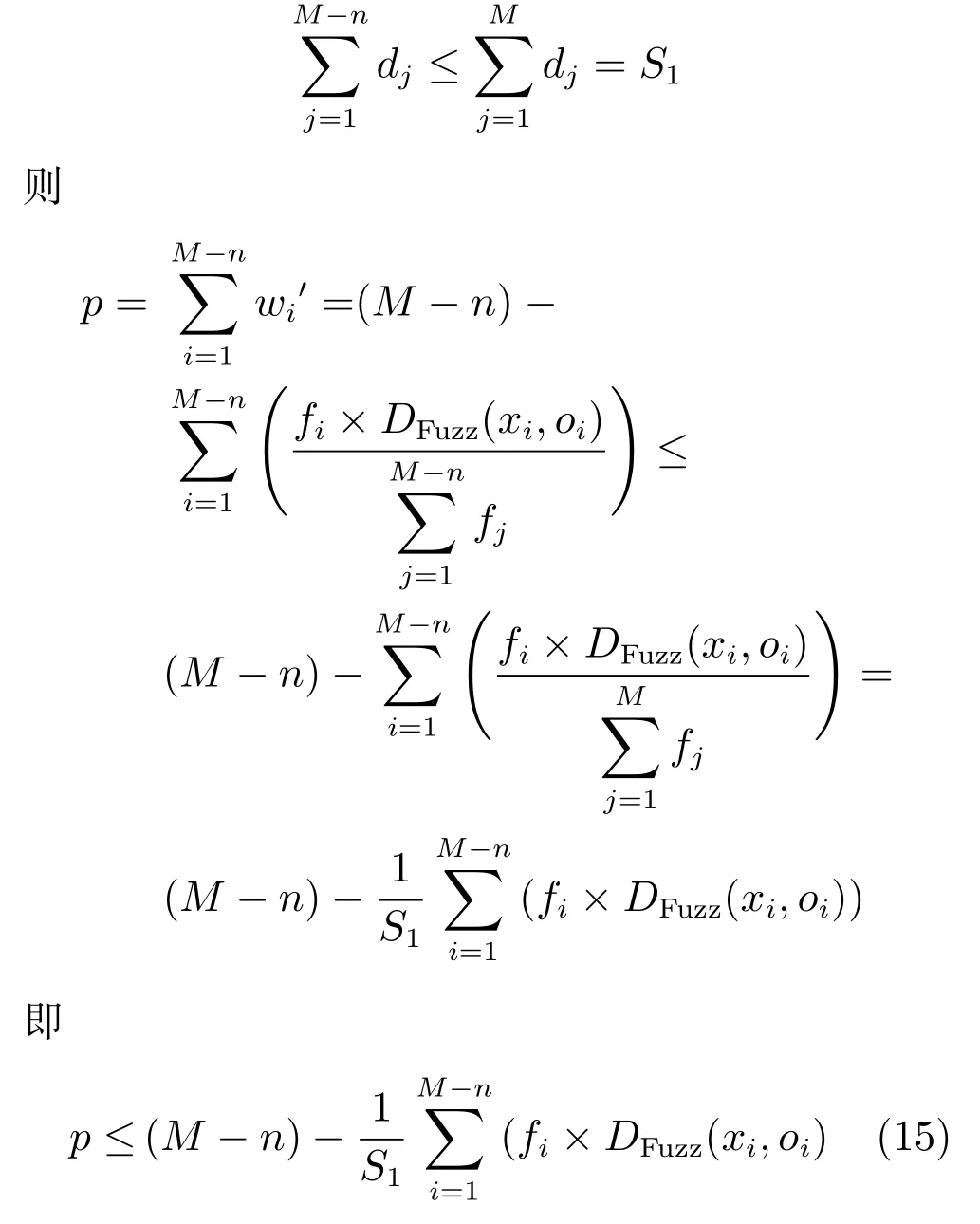
根据可靠度的定义式(14)可知,当α确定时,L与RL呈负相关,即p与RL呈负相关,p存在上限的同时可靠度RL存在下限,且结合式(15)可知,可靠度RL仅与序列的CP-距离有关,该值越小,L越小,可靠度RL越高,即若序列与聚类中心、主曲线的距离越近,则对应的模型可靠度越高,进一步表明本文所提算法的有效性.□
4 仿真与实验分析
为验证本文所提方法的有效性,分别引入混沌时间序列数据与五个实际数据集数据进行对比实验.为方便起见,本文所提方法简称为OE-MSVR(Outlier eliminating multi-dimensional SVR).
为进行定量比较,本文引入均方根误差(Root mean square error,RMSE)和平均绝对值误差(Mean absolute error,MAE)衡量预测结果.对应的表达式为
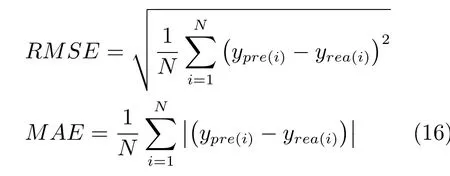
4.1 混沌时间序列预测
一般认为,混沌时间序列广泛存在于气象、天文和水文等领域,具有微观无序、宏观有序的特点.混沌预测方法就是在相空间中找到一个非线性模型去逼近系统动态特性.现有的预测方法多为只针对单独序列进行预测.若能利用混沌序列之间的结构特性实现对多条序列的同时预测,则可以提高预测效率,增强预测效果,更好地把握数据的下一步走势.
对比算法采用超限学习机(Extreme learning machine,ELM)和LibSVM.ELM是一种单层前馈式神经网络算法,具有良好的多输出回归能力[21];LibSVM是目前广泛使用的SVM工具包,需对每个输出单独建模[22].实验中,OE-MSVR和LibSVM均使用RBF核函数,核参数设为5,正则化参数C均为100,松弛变量ε为0.01;ELM隐神经元个数为400,激活函数为hardlim.实验开始前,所有的样本均归一化至[−1,1].
4.1.1 混沌时间序列数据生成
本文采用三种典型的混沌时间序列Lorenz[23]、Mackey-Glass[24]和Henon[25]系统进行实验.
利用上述三种混沌序列构造8条时间序列.其中Lorenz序列2条,序号为1,2,分别采用参数σ=10,r=28,b=8/3,初始值为y=[5,5,15],如图2所示.Mackey-Glass序列4条,序号为3,4,5,6,分别采用参数a=0.2,b=0.1,TAU=25,如图3所示.Henon序列2条,序号为7,8,分别采用参数a=1.4,x0=0.03,y0=0.02,如图4所示.
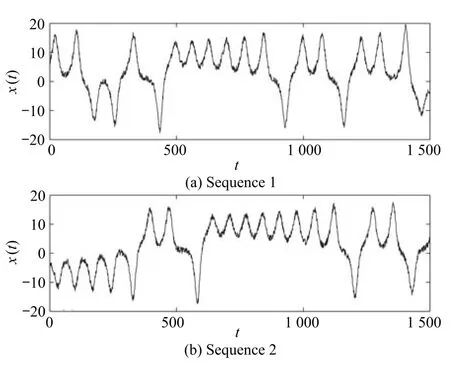
图2 Lorenz序列数据Fig.2 The Lorenz sequences
图3 Mackey-Glass序列数据Fig.3 The Mackey-Glass sequences
图4 Henon序列数据Fig.4 The Henon sequences
从几何形态看,Henon序列与其他两种序列差别较为明显.每一条时间序列分别产生1500个样本,其中前1000个样本训练,后500个样本用作测试.为使得实验场景更接近真实数据,这里在数据中加入均值为0、方差为1的白噪声.
4.1.2 实验结果与分析
首先,通过聚类方法得到初步的相似序列集.考虑到已知序列的数量较少,为模拟实际应用场景,将聚类的初始类别数设置成两类.利用提出的基于模糊熵的层次聚类算法进行聚类,结果如图5所示.可以看出,序列7和序列8被聚为一类,称为A类,其他6条序列为一类,称为B类,与几何图形的相似程度一致,由此可知本文所提时间序列聚类算法结果与预期一致,可较好区分不同类型的混沌时间序列.
其次,选择B类序列1∼6进行预测.由上述描述可知,序列本身添加了白噪声,因此可选择主曲线描述数据的分布特性.此处采用基于主曲线的异常序列检测算法进一步剔除序列中的异常序列(序号1,2).具体过程:计算B类序列的均值,并找到与其DTW距离最近的一条序列,定义该序列的主曲线作为B类序列的主曲线,如图6所示.由图6可知,主曲线能很好地反映数据分布的特性.
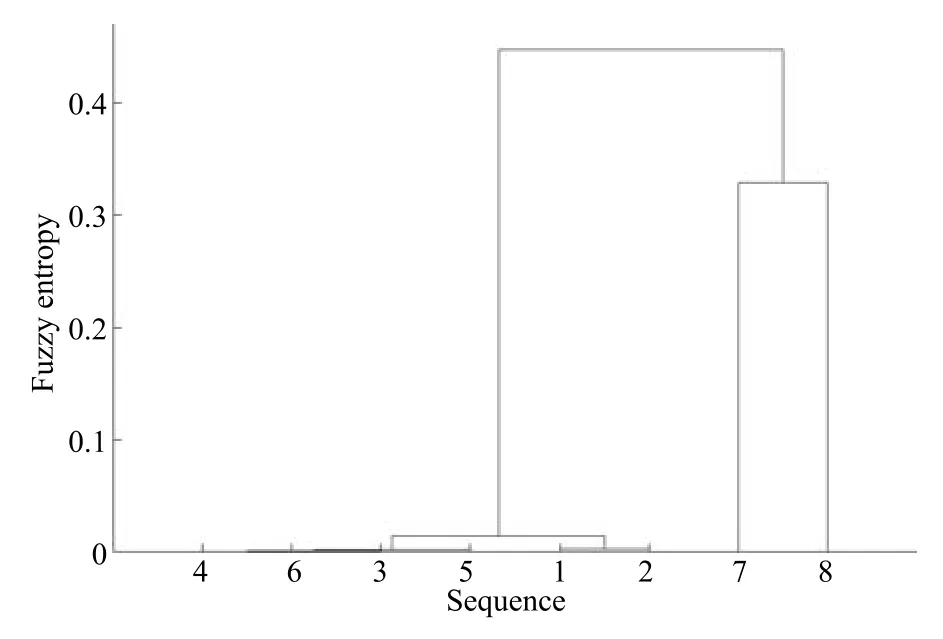
图5 初始序列聚类结果Fig.5 The result of clustering on original sequences
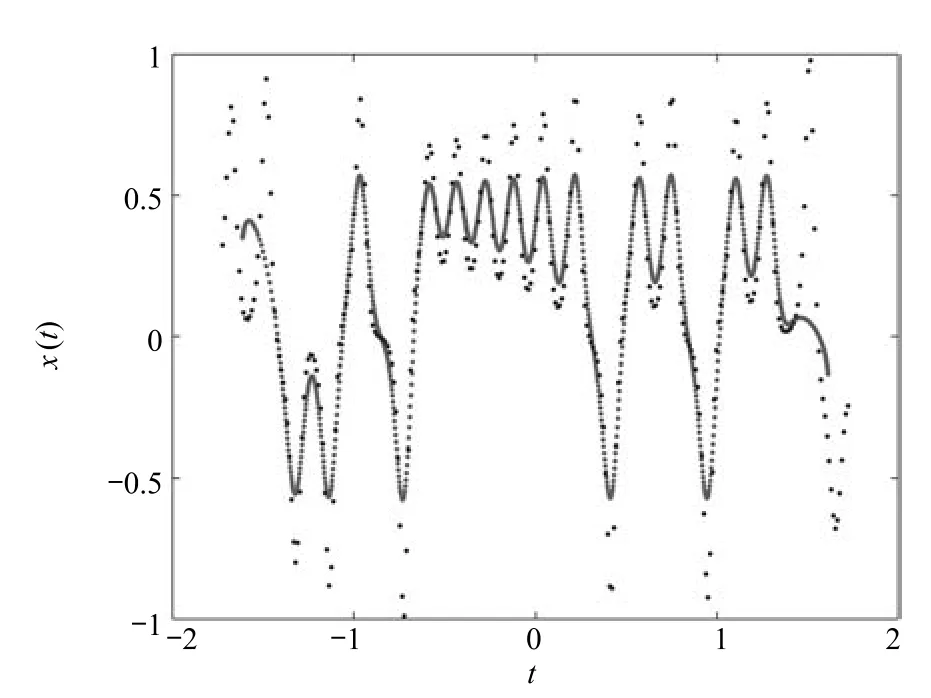
图6 B类序列的主曲线Fig.6 The principal curve of B class
再次,利用式(5)计算B类各序列基于主曲线的异常因子.由图7可以看出,序列1和序列2的异常因子明显高于其他四条序列,序列3∼6的异常因子基本趋于一致.因此可将序列1和序列2从该类剔除,与生成数据时的设置完全一致.
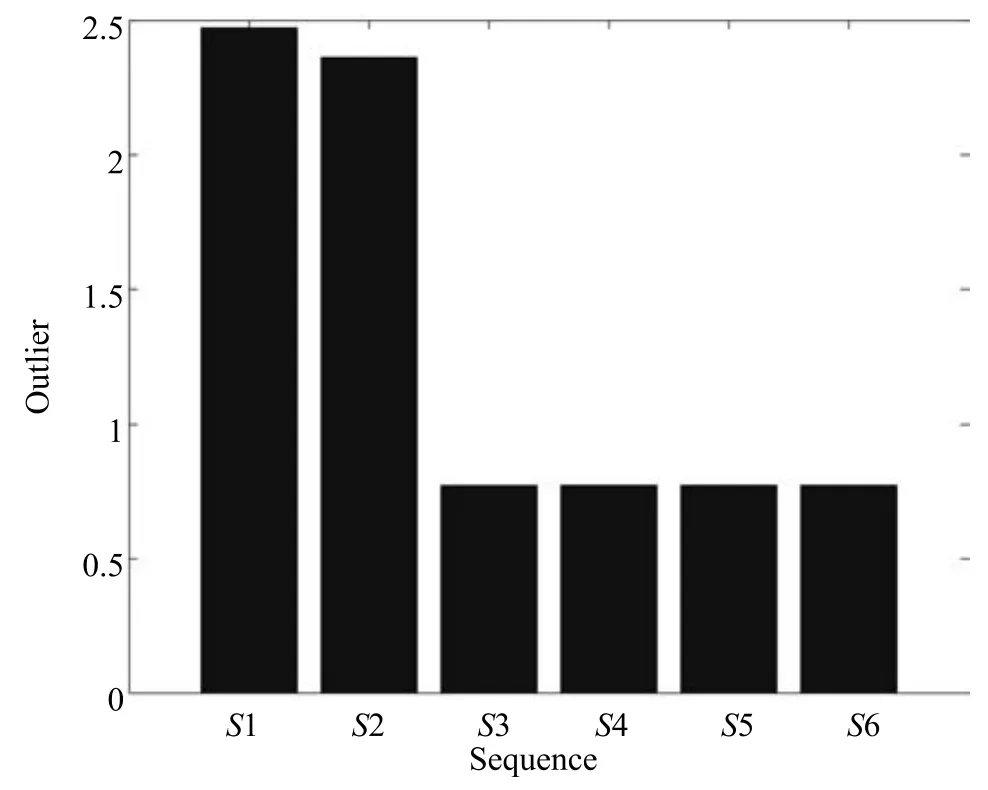
图7 B类各序列的异常因子Fig.7 Abnormal factor of every sequence in B class
为进一步分析本文所提方法的性能,本文对初始序列、聚类阶段及异常序列剔除三个阶段分别进行预测.限于篇幅,以序列3为例,预测效果如图8所示.嵌入维m为4,时延τ为1.其中,图8(a)是针对初始8条序列同时回归建模的预测效果图,图8(b)是对已知序列进行聚类初步划分得到的1∼6序列同时回归建模的预测效果图,图8(c)是在聚类初步划分后进行异常序列剔除挑选得到的序列3∼6同时回归建模的预测效果图.从图8可以看出,随着相似序列的一步步筛选,目标序列的预测效果明显变好,同时验证了M-SVR建模效果取决于输出端的相似性,越是相似的序列,利用M-SVR进行预测效果越好.
表1给出了3,4,5,6四条序列在三个阶段的预测效果.由表1可知,随着各个阶段序列相似程度的提高,预测精度明显提高,表明本文所提算法可以有效提高多变量时间序列的预测精度和数值稳定性,进一步验证了M-SVR可有效利用多个输出端之间的结构化特性,从而增加模型的信息含量,提高建模的精度及稳定性.
以序列3为例,图9∼11分别给出本文所提方法,SVR和ELM的预测效果及对应的局部放大图.
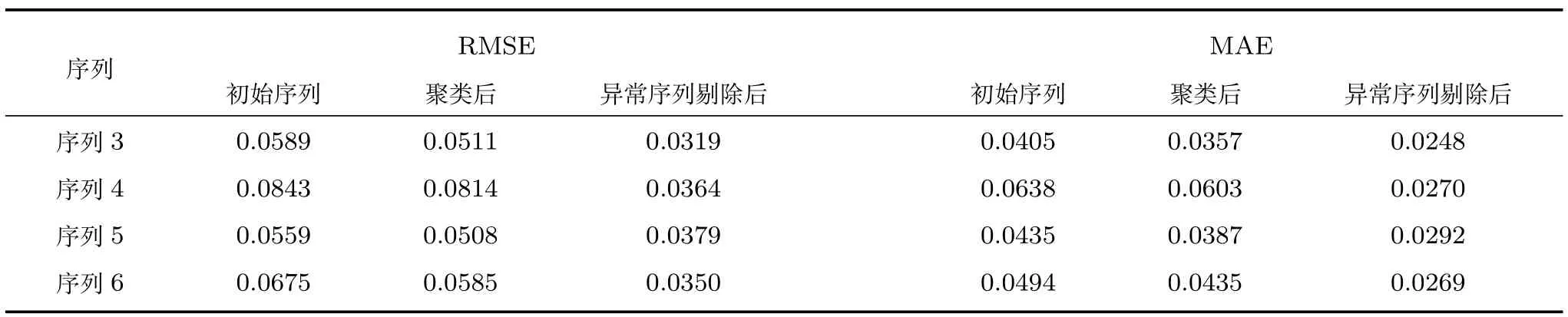
表1 各个阶段预测结果性能指标对比Table 1 Prediction performance parameters of capillary of three stages
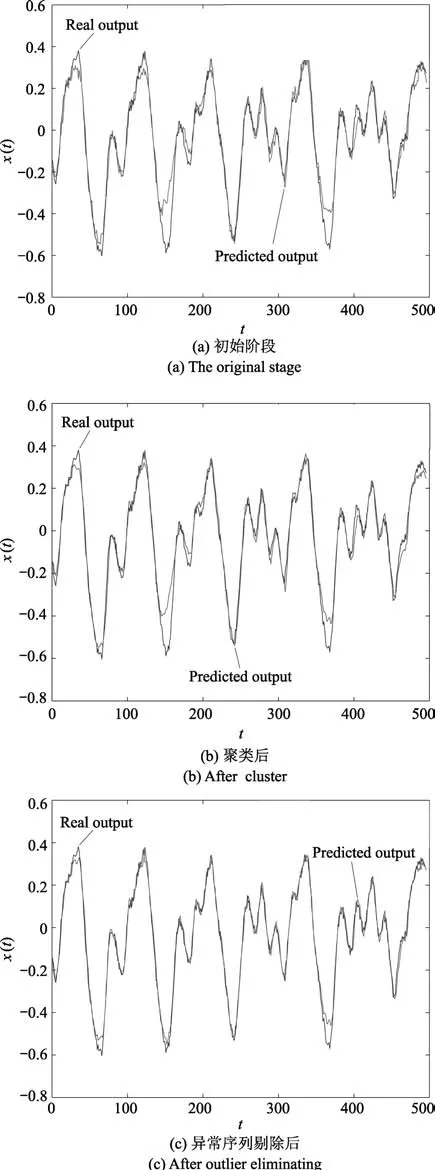
图8 OE-MSVR在三个阶段的预测效果Fig.8 The prediction of three stages with OE-MSVR algorithms
由图9∼11可知,OE-MSVR在整体上预测值与真实值最接近,除了少数的波峰和波谷外,大部分时间的预测曲线均贴近真实曲线;SVR算法的预测值与真实值的走势基本相同,但大部分时间点的预测值均与真实值存在偏差;ELM算法的预测结果不太稳定,相比其他两种算法与真实值的偏差相对较大.
从表1可以看出,随着剔除相似度较低的序列,OE-MSVR预测效果在不断提高,表明异常序列的存在影响着数据集整体内在的关联性,当筛选得到具有依赖关系较强相似性序列时,结构化数据中蕴含的有价值的信息得到了有效利用.结合图9∼11可知,在筛选得到的序列上进行操作时,OE-MSVR预测效果明显好于其他两种算法,进一步表明了OE-MSVR可以有效挖掘多变量时间序列的内在结构信息,使得预测精度更高,数值稳定性更好.
使用OE-MSVR,SVR,ELM 对序列3∼6等四条序列的预测效果对比如图12所示.由图12可知,本文所提算法在两种误差指标上明显比另外两种算法小,预测效果明显较好,再次表明本文方法对多变量时间序列的预测效果好,验证了此方法的有效性与稳定性.对于其他类别序列,本文方法具有类似的对比效果.
4.2 实际数据集时间序列预测
为验证算法的性能,选择不同规模的数据集对算法进行测试,并将本文所提算法与SVM[22],ELM[21],Fol-BP[26]及AR[27]算法进行对比.其中,Fol-BP是侯公羽等于2014年提出的多变量混沌时间序列预测算法,通过RMSE和MAE进行评估.实验设置与第4.1节相同.为消除ELM和Fol-BP算法的随机性,其结果为重复10次的平均值.与第4.1节不同,对于实际采集到的数据,事先并没有其内在结构的先验知识.
实验中,OE-MSVR均使用RBF核函数,在澳门气象数据数据集上的核参数设为2,正则化参数C为2−1,松弛变量ε为0.01;在A monitor system数据集上的核参数设为23,正则化参数C为25,松弛变量ε为0.01;在Italian air quality数据集上的核参数设为2,正则化参数C为25,松弛变量ε为0.01;在Istanbul stock exchange数据集上的核参数设为1,正则化参数C为25,松弛变量ε为0.01;在Gas sensor array drift数据集上的核参数设为22,正则化参数C为22,松弛变量ε为0.01;Fol-BP,LibSVM和ELM参数均为网络搜索得到最优值.实验开始前,所有的样本均归一化至[−1,1].
4.2.1 数据集
选定澳门气象数据,A monitor system,Italian air quality,Istanbul stock exchange和Gas sensor array drift五种真实的时间序列数据集对OEMSVR算法的性能进行验证.使用的数据集可在澳门气象局官网、UCI公共数据集下载得到.五个真实数据集信息见表2.
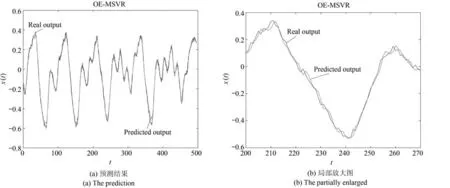
图9 序列3的OE-MSVR预测效果图Fig.9 The prediction of the third sequence with OE-MSVR algorithm

图10 序列3的SVR预测效果图Fig.10 The prediction of the third sequence with SVR algorithm
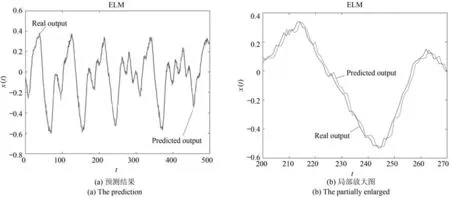
图11 序列3的ELM预测效果图Fig.11 The prediction of the third sequence with ELM algorithm
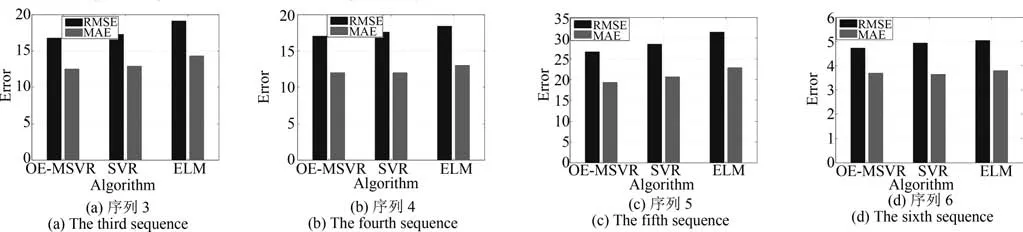
图12 三种方法下预测误差对比图Fig.12 The errors of three algorithms
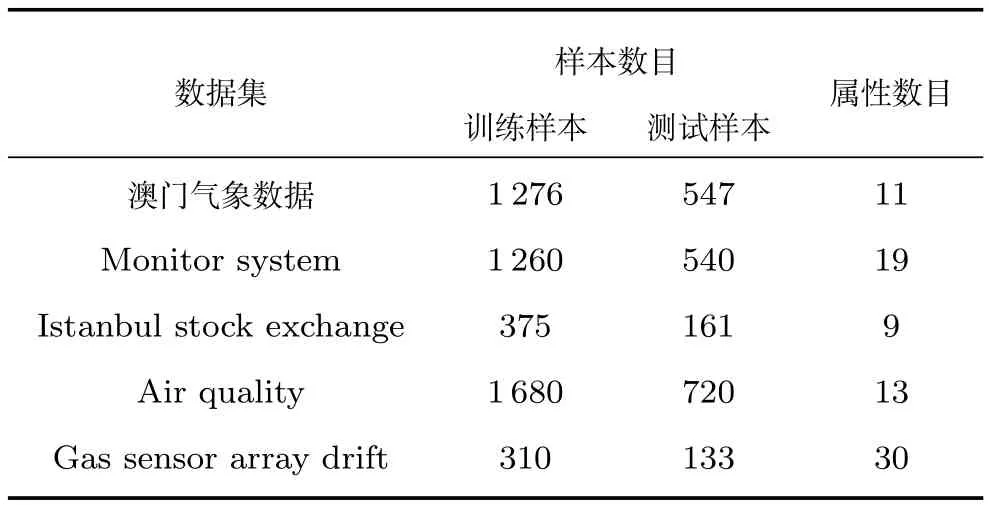
表2 实际数据集信息Table 2 Real datasets
本文首先选择澳门气象局官网提供的空气质量数据集做进一步对比实验.该数据包括影响空气质量的多种因素:PM10,SO2,NO2,O3,伽马射线(γ射线),气压(P),气温(T),湿度(H),风速(W),雨量(R),日照量(S),因此是一种典型的多变量时间序列数据.对这些指标的同时预测,具有明确的工程需求.具体为2002年∼2006年1823组大谭山的气象数据.
A monitor system,Italian air quality,Istanbul stock exchange和Gas sensor array drift数据集均来源于UCI公共数据集.其中A monitor system数据是安装在多人室中的监视器系统收集的数据,包括19个连续属性;Italian air quality数据是在意大利部署的气体多传感器收集到的空气质量数据,包括13个空气质量属性;Istanbul stock exchange数据集包括伊斯坦布尔证券交易所与七个其他国际指数的回报;Gas sensor array drift数据是描述在不同浓度情况下气体传感器的漂移数据,包括30个连续属性.它们均属于典型的多变量时间序列数据.
4.2.2 实验结果
以澳门气象数据为例,采用基于模糊熵的层次聚类对初始序列进行初步划分,其结果如图13所示.
从图13可以看出,聚类将序列1,3,4,7,8,9聚为一类,称作A类;序列2,5,6,10聚为一类,称为B类;序列11单独为一类,称作C类.
图13 初始序列聚类结果Fig.13 The result of clustering on original sequences
以A类为例,为得到相似度更高的序列,计算各序列的异常因子.构建A类序列的主曲线作为各序列异常因子检测的基准,如图14(a)所示;并利用式(5)计算A类各个序列基于主曲线的异常因子,如图14(b)所示.由图14可知,序列7和序列8的异常因子明显较大,故而将序列7和序列8从该类剔除.
利用筛选得到的序列构建模型,用前1276组数据训练,后547组数据进行测试验证.图15给出了五种算法的预测效果对比.由图15可知,虽然所提算法在较少序列上存在欠缺,但在整体上OEMSVR所提算法预测效果最好,表明在处理实际多变量预测的问题时,OE-MSVR有效提高了多条序列的预测精度,进一步验证了所提方法对多变量时间序列预测的有效性与稳定性,对实际多变量预测更具有实际的应用价值.对于B类序列也有类似效果.
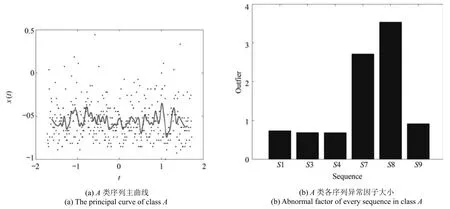
图14 异常序列检测过程图Fig.14 The detection of abnormal sequences
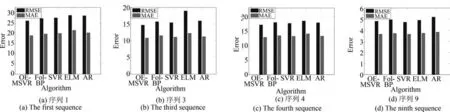
图15 五种方法下预测误差对比图Fig.15 The errors of five algorithms
针对A monitor system,Italian air quality,Istanbul stock exchange和Gas sensor array drift四个UCI实际数据集,其初始序列集在聚类阶段的结果如图16所示.由图16可知,A monitor system数据集中当聚类数目设置为4类时,其中序列1,2,4,5,6,7,10,11,17,18,19为一类,称作A类;序列3,8,9,14,15,16为一类,称作B类;序列12和序列13分别为两类,成为C类和D类.Italian air quality数据集中当聚类数目设置为2类时,其中序列1,3,4,11,12,13为一类,称作A类;序列2,5,6,7,8,9,10为一类,称作B类.Istanbul stock exchange数据集中当聚类数目设置为2类时,其中序列1,2,5,6,7为一类,称作A类;序列3,4,8,9为一类,称作B类;Gas sensor array drift数据集中当聚类数目设置为4类时,其中序列1,18,19,20,21,26,28,29为一类,称作A类;序列2,3,4,5,6,10,11,12,13,14,22,27,30为一类,称作B类;序列7,8,9,15,16,17,23,24为一类,称作C类,25为一类,称作D类.
针对各数据集的初始聚类结果,本文以A monitor system数据集的A类,Italian air quality数据集的B类,Istanbul stock exchange数据集的A类、Gas sensor array drift数据集的B类为例进行操作.通过构建各类序列的主曲线以衡量序列集内部各序列的异常因子,从而选取相似性高的序列集.图17为四个数据集相应类的主曲线.
利用式(5)得到各序列基于主曲线的异常因子.从图18可以看出,A monitor system,Italian air quality和Gas sensor array drift数据集的各序列异常因子相对明显,Istanbul stock exchange数据的异常因子相对不明显.
完成对各个数据集中相似序列的筛选后,利用选择得到的序列集进行回归建模.选择各数据集的前70%组数据进行训练,后30%组数据测试验证,具体样本数见表2.其中,OE-MSVR,Fol-BPELM和SVR四种方法的嵌入维m为2,时延τ为1,AR算法的阶数为1.表3∼6分别给出了A monitor system,Italian air quality,Istanbul stock exchange和Gas sensor array drift四个实际数据集在5种算法下的预测效果对比.
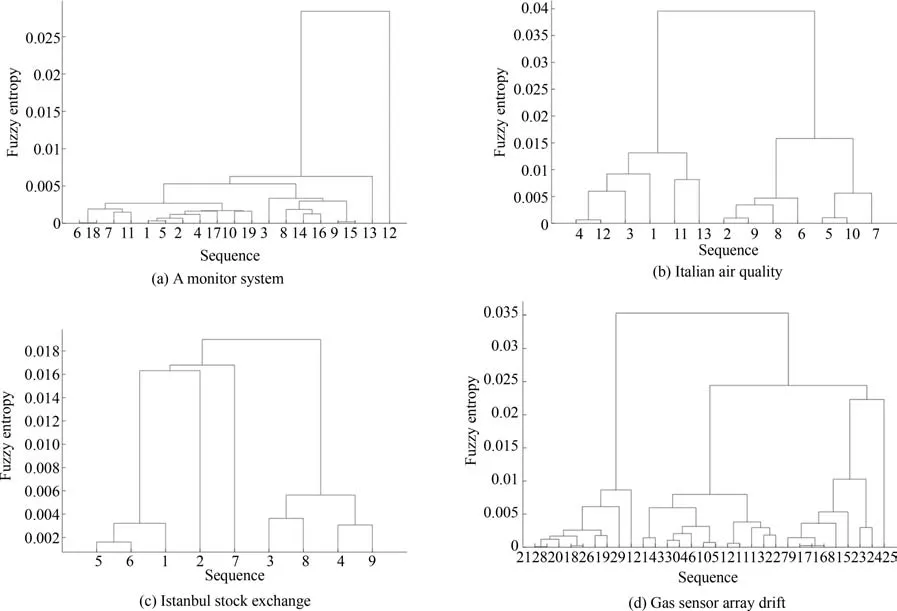
图16 四个数据集的聚类结果图Fig.16 The results of clustering on four datasets

图17 四个数据集对应类的主曲线结果图Fig.17 The principal curve of classes on four datasets
从表3、表4和表6可以看出,在大多数序列上,OE-MSVR均明显优于其他对比算法,尤其在表3的序列1,2;表4的序列2,9,10和表6的序列4,5,12,13,14上,本文所提方法均取得了较低的RMSE预测误差.不难发现,Fol-BP算法在数据集Italian air quality上取得了较好的整体预测效果,在序列2,7,9,10上的RMSE预测误差均小于ELM,SVR和AR,表明较好利用多变量序列之间的结构化信息有助于降低整体的预测误差,但由于该算法仅采用一阶局域法对多变量序列进行建模,并没有深入考虑其间的结构化信息,因此预测误差低于OE-MSVR.我们留意到AR在表3的序列5,19等序列取得了最低的RMSE误差,根据这些序列的图形走势可以看到,该序列较为平缓,波动不剧烈,AR易于取得较好的预测效果,而在序列波动相对较剧烈的表4中,AR的预测误差则要明显高于本文所提算法和Fol-BP,也略高于ELM,与文献[27]的观测结果一致.同时观察到,ELM在少数序列上(例如表3中序列6,19和表4中序列5)的RMSE预测误差低于OE-MSVR,但这种结果来自于大量的网格搜索后取的最优值,同时ELM 本身也带有多输出的网络结构,相比较而言,本文所提算法参数为直接指定,未做模型选择.SVR的预测效果在所有算法中相对较差,尽管其采用了网格搜索,但由于SVR本身只能做单输出的预测,因此在大多数序列上预测误差较高,从另一个方面验证了多变量时间序列预测的必要性.
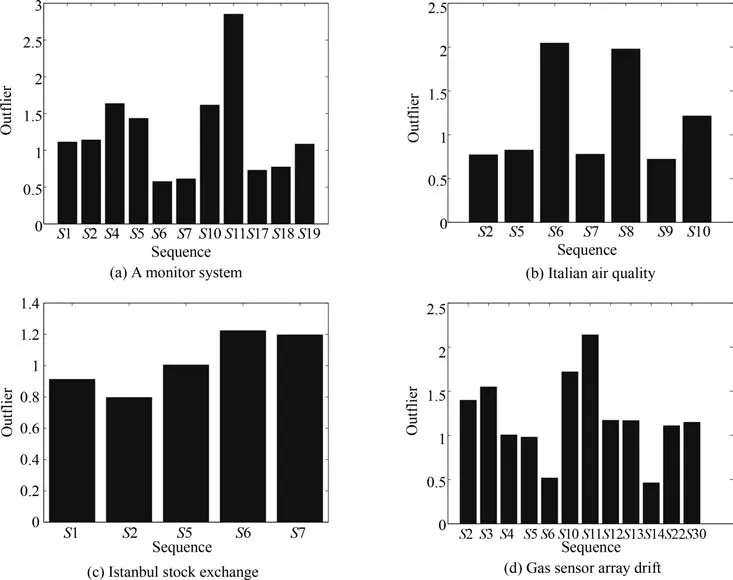
图18 四个数据集的异常因子结果图Fig.18 The abnormal factors of four datasets
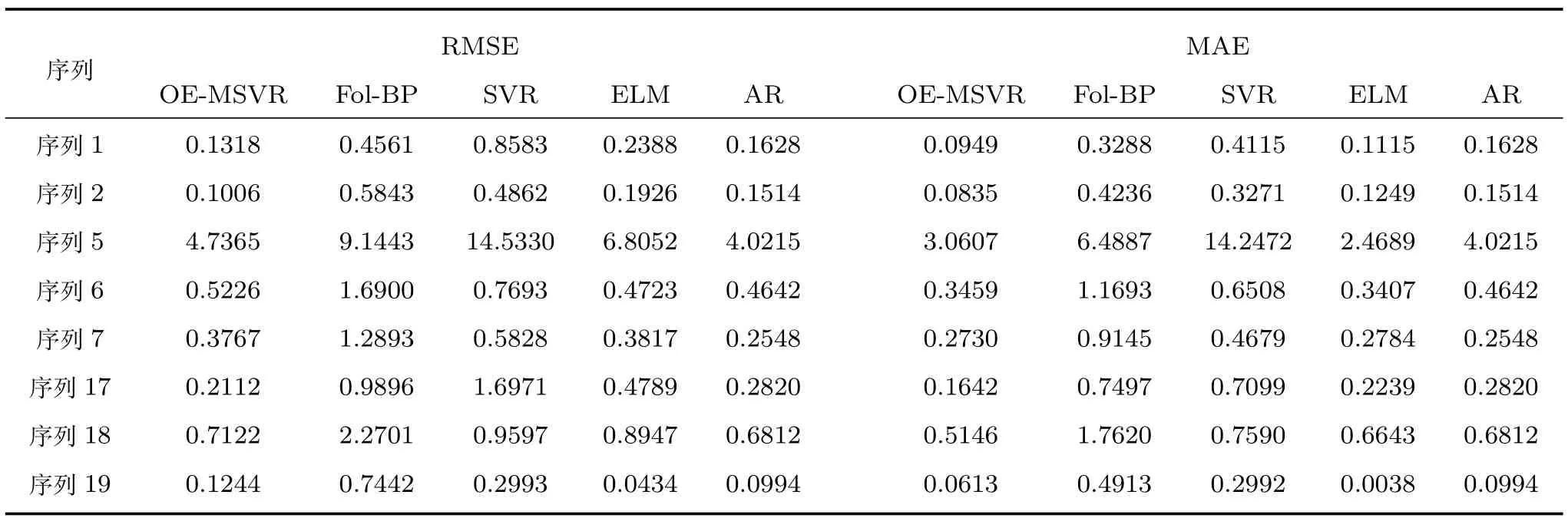
表3 A monitor system数据集预测结果性能指标对比Table 3 Prediction performance parameters of capillary of A monitor system dataset
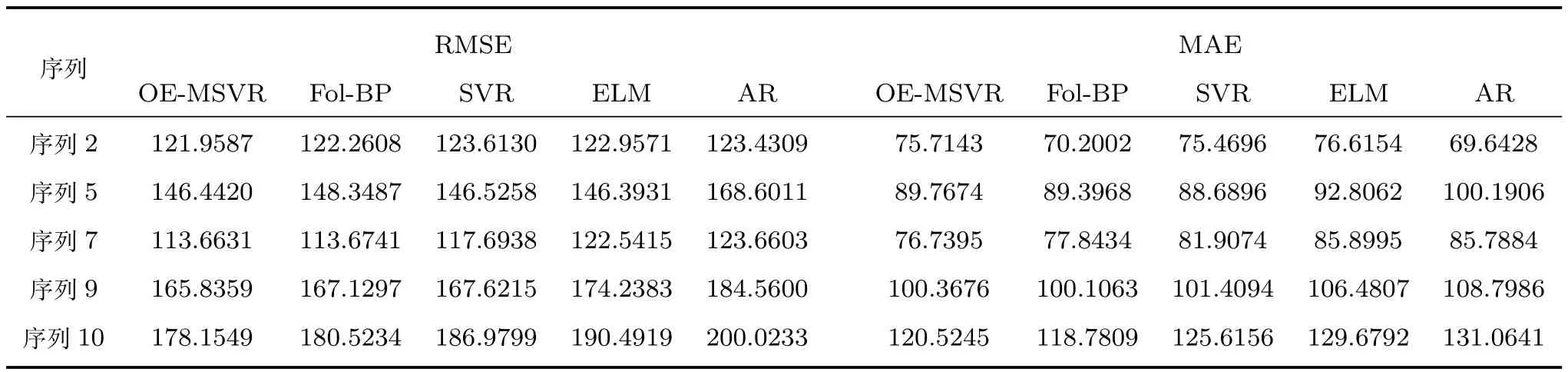
表4 Italian air quality数据集预测结果性能指标对比Table 4 Prediction performance parameters of capillary of Italian air quality dataset

表5 Istanbul stock exchange数据集预测结果性能指标对比Table 5 Prediction performance parameters of capillary of Istanbul stock exchange dataset
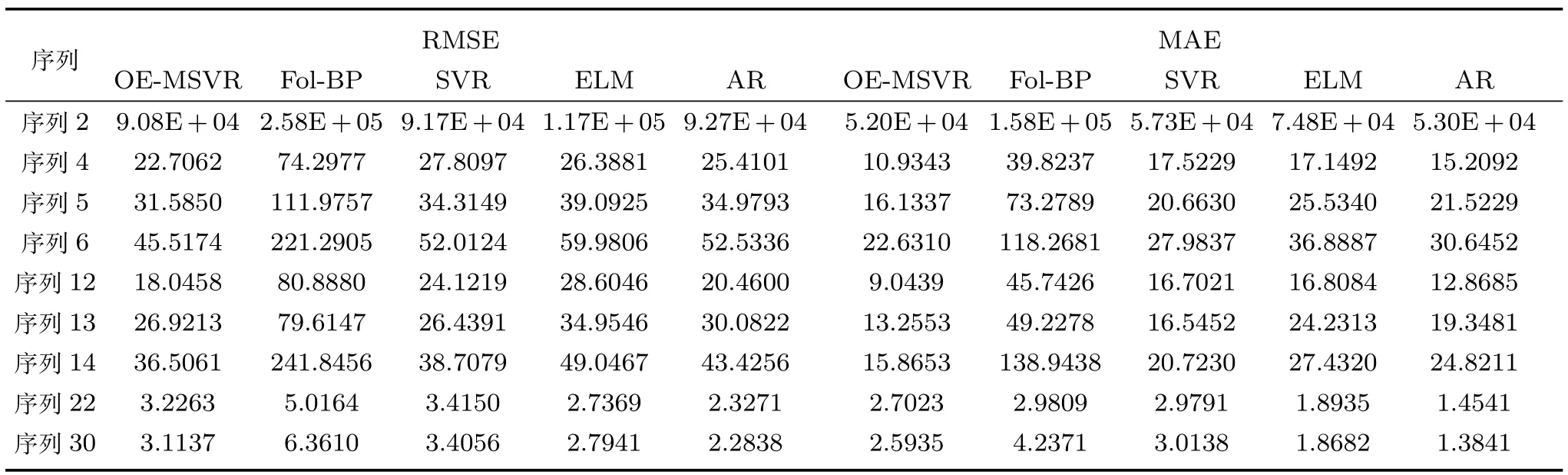
表6 Gas sensor array drift数据集预测结果性能指标对比Table 6 Prediction performance parameters of capillary of Gas sensor array drift dataset
表5的结果验证了异常序列剔除的作用.由图18(c)可知,与澳门气象数据(图14(b))和Italian air quality数据(图18(b))的异常因子分析对比,Istanbul stock exchange数据集各序列异常因子区别并不显著.当剔除具有相对较高异常因子的序列6和序列7后,OE-MSVR虽然取得了最低的预测误差,但是这种提高并不显著.经过大量的网格搜索,SVR和ELM 也取得了较好的预测效果.综合表3∼5的结果,我们发现,当异常因子存在较大差异时(如图14(b)和图18(b)),剔除异常序列后预测误差有显著下降(如图15和表4所示);而当异常序列并不显著时(如图18(c)),所提算法的整体预测效果与经过模型选择后的SVR和ELM等方法相仿,提高幅度并不明显,而这恰恰表明了异常序列在多变量时间序列预测中的负面影响.
5 结论
基于结构化输出的多变量时间序列预测可通过挖掘变量间蕴含的领域信息同时提高多个变量序列的预测效果.其中的关键问题在于如何提取变量间的依赖关系.本文提出了一种基于异常序列剔除的多变量时间序列预测方法.该方法利用基于模糊熵的层次聚类对时间序列进行初步划分,提出了基于主曲线的异常序列检测算法,进一步检测并剔除异常序列,最终引入多输出SVR进行建模和预测,同时在理论上证明了该算法的可行性与合理性,最终利用混沌时间序列数据与实际数据集数据验证了算法的有效性.下一步的工作将集中在算法的泛化性理论分析和不同类型的变量间结构特性的建模.
References
1 Schölkopf B B,Smola A J.Learning with Kernels.Cambridge,Britain:MIT Press,2002,3:2165−2176
2 Zhang Yong,Guan Wei.Predication of multivariable chaotic time series based on maximal Lyapunov exponent.Acta Physica Sinica,2009,58(2):756−763(张勇,关伟.基于最大Lyapunov指数的多变量混沌时间序列预测.物理学报,2009,58(2):756−763)
3 Sun B Q,Guo H F,Karimi H R,Ge Y J,Xiong S.Prediction of stock index futures prices based on fuzzy sets and multivariate fuzzy time series.Neurocomputing,2015,151:1528−1536
4 Han Min,Xu Mei-Ling,Ren Wei-Jie.Research on multivariate chaotic time series prediction using mRSM model.Acta Automatica Sinica,2014,40(5):822−829(韩敏,许美玲,任伟杰.多元混沌时间序列的相关状态机预测模型研究.自动化学报,2014,40(5):822−829)
5 Wang X Y,Han M.Improved extreme learning machine for multivariate time series online sequential prediction.Engineering Applications of Arti ficial Intelligence,2015,40:28−36
6 Han M,Xu M L,Liu X X,Wang X Y.Online multivariate time series prediction using SCKF-γESN model.Neurocomputing,2015,147:315−323
7 Chen T T,Lee S J.A weighted LS-SVM based learning system for time series forecasting.Information Sciences,2015,299:99−116
8 Sanchez-FernandezM,de-Prado-CumplidoM,Arenas-Garcia J,Perez-Cruz F.SVM multiregression for nonlinear channel estimation in multiple-input multiple-output systems.IEEE Transactions on Signal Processing,2005,52(8):2298−2307
9 Bao Y K,Xiong T,Hu Z Y.Multi-step-ahead time series prediction using multiple-output support vector regression.Neurocomputing,2014,129:482−493
10 Han J W,Kamber M,Pei J[Author],Fan Ming,Meng Xiao-Feng[Translator].Data Mining Concepts and Techniques(3rd edition)(Computer Science Series).Beijing:China Machine Press,2012.297−301(Han J W,Kamber M,Pei J[著],范明,孟小峰[译].数据挖掘概念与技术(第3版)(计算机科学丛书).北京:机械工业出版社,2012.297−301)
11 Han Zhong-Ming,Chen Ni,Le Jia-Jin,Duan Da-Gao,Sun Jian-Zhi.An efficient and effective clustering algorithm for time series of hot topics.Chinese Journal of Computers,2012,35(11):2337−2347(韩忠明,陈妮,乐嘉锦,段大高,孙践知.面向热点话题时间序列的有效聚类算法研究.计算机学报,2012,35(11):2337−2347)
12 Lee H.The Euclidean distance degree of Fermat hypersurfaces.Journal of Symbolic Computation,2017,80:502−510
13 Hautamaki V,Nykanen P,Franti P.Time-series clustering by approximate prototypes.In:Proceedings of the 19th International Conference on Pattern Recognition.Tampa,FL,USA:IEEE,2008.1−4
14 Yang Yi-Ming,Pan Rong,Pan Jia-Lin,Yang Qiang,Li Lei.A comparative study on time series classi fication.Chinese Journal of Computers,2007,30(8):1259−1266(杨一鸣,潘嵘,潘嘉林,杨强,李磊.时间序列分类问题的算法比较.计算机学报,2007,30(8):1259−1266
15 Zhang Jun-Ping,Wang Yu.An overview of principal curves.Chinese Journal of Computers,2003,26(2):129−146(张军平,王珏.主曲线研究综述.计算机学报,2003,26(2):129−146)
16 Mao Wen-Tao,Wang Jin-Wan,He Ling,Yuan Pei-Yan.Hybrid sampling extreme learning machine for sequential imbalanced data.Journal of Computer Application,2015,35(8):2221−2226(毛文涛,王金婉,何玲,袁培燕.面向贯序不均衡数据的混合采样极限学习机.计算机应用,2015,35(8):2221−2226)
17 Sun Ke-Hui,He Shao-Bo,Yin Lin-Zi,A Di-Li·Duo Li-Kun.Application of fuzzyen algorithm to the analysis of complexity of chaotic sequence.Acta Physica Sinica,2012,61(13):130507(孙克辉,贺少波,尹林子,阿地力·多力坤.模糊熵算法在混沌序列复杂度分析中的应用.物理学报,2012,61(13):130507)
18 Mao Wen-Tao,Zhao Sheng-Jie,Zhang Jun-Na.Multi-inputmulti-output support vector machine based on principal curve.Journal of Computer Application,2013,33(5):1281−1284,1293(毛文涛,赵胜杰,张俊娜.基于主曲线的多输入多输出支持向量机算法.计算机应用,2013,33(5):1281−1284,1293)
19 Yuan P Y,Ma H D,Fu H Y.Hotspot-entropy based data forwarding in opportunistic social networks.Pervasive and Mobile Computing,2015,16:136−154
20 Tang Li-Dong,Song Bao-Wei,Li Zheng,Zheng Ke.A fuzzy reliability evaluation method for sub-sample products based on information entropy theory.Journal of Projectiles,Rockets,Missiles and Guidance,2005,25(S1):214−216(汤礼东,宋保维,李正,郑珂.基于信息熵理论的小子样模糊可靠性评定方法.弹箭与制导学报,2005,25(S1):214−216)
21 Mao W T,Zhao S J,Mu X X,Wang H C.Multi-dimensional extreme learning machine.Neurocomputing,2015,149:160−170
22 Chang C C,Lin C J.LIBSVM:a library for support vector machines[Online],available:http://www.csie.ntu.edu.tw/∼cjlin/libsvm/index.html.February 1,2016
23 Xu Mei-Ling,Han Min.Factor echo state network for multivariate chaotic time series prediction.Acta Automatica Sinica,2015,41(5):1042−1046(许美玲,韩敏.多元混沌时间序列的因子回声状态网络预测模型.自动化学报,2015,41(5):1042−1046)
24 Li Jun,Li Da-Chao.Wind power time series prediction using optimized kernel extreme learning machine method.Acta Physica Sinica,2016,65(13):33−42(李军,李大超.基于优化核极限学习机的风电功率时间序列预测.物理学报,2016,65(13):33−42)
25 Ma Qian-Li,Zheng Qi-Lun,Peng Hong,Qin Jiang-Wei.Chaotic time series prediction based on fuzzy boundary modular neural networks.Acta Physica Sinica,2009,58(3):1410−1419(马千里,郑启伦,彭宏,覃姜维.基于模糊边界模块化神经网络的混沌时间序列预测.物理学报,2009,58(3):1410−1419)
26 Hou Gong-Yu,Liang Rong,Sun Lei,Liu Lin,Gong Yan-Fen.Risk analysis on long inclined-shaft construction in coalmine by TBM techniques based on multiple variables chaotic time series.Acta Physica Sinica,2014,63(9):90505(侯公羽,梁荣,孙磊,刘琳,龚砚芬.基于多变量混沌时间序列的煤矿斜井TBM施工动态风险预测.物理学报,2014,63(9):90505)
27 Liu C H,Shang Y L,Duan L,Chen S P,Liu C C,Chen J.Optimizing workload category for adaptive workload prediction in service clouds.Service-Oriented Computing.Lecture Notes in Computer Science.Berlin,Heidelberg,Germany:Springer,2015.87−104
