基于语义相似度的本体概念更新方法研究
2018-05-03李婉婉张英俊潘理虎
李婉婉 张英俊 潘理虎,2
1(太原科技大学计算机科学与技术学院 山西 太原 030024) 2(中国科学院地理科学与资源研究所 北京 100101)
0 引 言
本体通过形式化表达将特定领域的知识组织起来,形成统一的认识。随着各种领域本体的构建以及广泛应用,本体的发展也面临着一些阻碍。本体的构建主要依赖于人为构建,耗时且容易出错,并且资源有限导致本体构建过程中可能丢失一部分实体及关系[1]。此外,随着信息的不断变化,已经构建好的本体也需要适应性地更新[2]。本体更新就意味着本体中缺乏某些概念,为了使本体得到最大程度的利用,本体应该尽可能地包含该领域的全部实体和关系。目前,本体更新时添加新概念的方法大致可分为依靠专家人为添加或利用算法自动添加[3]。依靠专家人为添加的方法效率低且容易出错,为了减少对领域专家的人为依赖,促进本体应用领域的信息化、自动化建设,本文给出一种基于语义相似度的本体概念更新方法。
语义相似度是判断概念间关系的重要依据,可根据给定本体的分类体系来计算两个概念间的语义距离或者利用大型语料库统计共现率来度量概念间语义相似度[4]。WordNet是一个被广泛使用的英文语义词典,它将所有的术语和概念都以同义词集合的形式表示。针对每一个同义词集都有一个简短的定义描述以及该同义词集存在的语义关系记录[5]。WordNet将同义词集按照上下位、整体、部分、同义、反义、因果等关系组织起来,为每一个术语提供了一种层次结构,因此适用于度量语义相似度[6]。
目前,国内外许多学者依据WordNet提出了大量相似度算法,大致分为4类:基于路径、基于信息内容、基于特征以及混合算法[7-9]。基于路径的基本思想是考虑两个概念在分类树中的位置,并用一个关于二者路径距离的函数来定义相似度[10]。Rada等[11]把本体看作是有向图,概念间主要是通过is-a关系相互联系,概念间的距离越远,相似度则越低。Hao等[12]提出从概念间的距离和深度两个角度计算相似度,但无法区分最小公共父类处于同一层次的概念对之间的相似度结果,降低了算法的准确性。基于信息量的方法是Resnik[13]于1995年提出的,通过统计概念及其下义词在语料库中出现的频率来表征概念的信息量,概念出现的次数越高,信息量则越少。对于两个给定的概念,相似度主要取决于二者共享信息的程度,共享的信息越多越相似[14]。1998年,Lin[15]对Resnik的基于信息量的方法进行了改进,Lin认为概念间的相似度不仅取决于二者共享的信息量,还和概念本身所携带的信息量有关。Jiang等[16]将概念间的距离计算转换为信息量的计算,提出了通过计算信息量表征的语义距离来映射语义相似度,用距离的倒数来表示语义相似度。文献[17]提出一种综合概念关系类型、强度、信息量、节点密度等多个因素的计算模型,相似度计算的准确性虽有一定提高,但计算复杂性过高。基于特征的方法假设用一组特征描述概念,概念的相似度基于两个概念所共同具有的特征来度量[18]。特征集的定义至关重要,它包括本体中可以获取到的信息,比如同义词集,概念定义,概念间的关系等。混合方法综合考虑了影响相似度计算的多种结构化因素,例如路径长度、深度、局部密度等[19]。Zhou等[20]综合了前人在基于信息量的方法和基于路径的方法基础上的研究成果,提出了一种混合算法,改善了计算结果的准确性。文献[21]根据概念各自所处的层次以及概念属性综合度量相似度,但忽略了对概念之间的层次结构的考虑。目前,基于距离的相似度算法主要依据概念之间的距离或深度计算相似度,计算模型简单但考虑因素过于单一。基于信息量的方法通过语料库引入了概念的语义信息,但忽略了概念的层次信息,且不同的语料库计算结果可能不同。基于特征的方法考虑了概念共同拥有的特征,忽略了二者在本体树中的层次结构且特征的计算相对复杂。近年来,混合算法引起许多学者的重视,为了得到更为精确的结果,综合考虑了多种影响因素,但在算法性能以及效率方面难以达到平衡。
以上这些语义相似度计算模型只着重考虑了概念间的层次结构或者概念所拥用的信息量,未能将二者有效融合起来,从而导致一些有用信息的丢失,在一定程度上影响了算法结果的准确度。本文将借助于WordNet语义词典给出一种改进的综合多因素的相似度计算模型,并在分析研究改进相似度算法的基础上,给出了一种本体概念更新方法。最后通过实验验证了方法的可行性和有效性。
1 改进的基于WordNet的相似度计算
传统的基于路径、深度的相似度算法计算过程比较直观,复杂性低,但依赖于预先构建好的概念间的结构层次网络图,并且有关相似度计算的影响因素考虑较少,导致计算结果出现偏差。基于信息量的相似度算法在理论上相对完善,但忽略了概念的层次信息,同时依赖于语料库中的统计信息,数据稀疏问题较严重。针对传统的相似度算法所存在的一些缺陷,本文将依据WordNet的分类体系结构以及一些统计信息,在基于路径的算法基础上,给出一种改进的相似度算法。
图1是WordNet概念分类体系的一个片断。

图1 WordNet分类片断
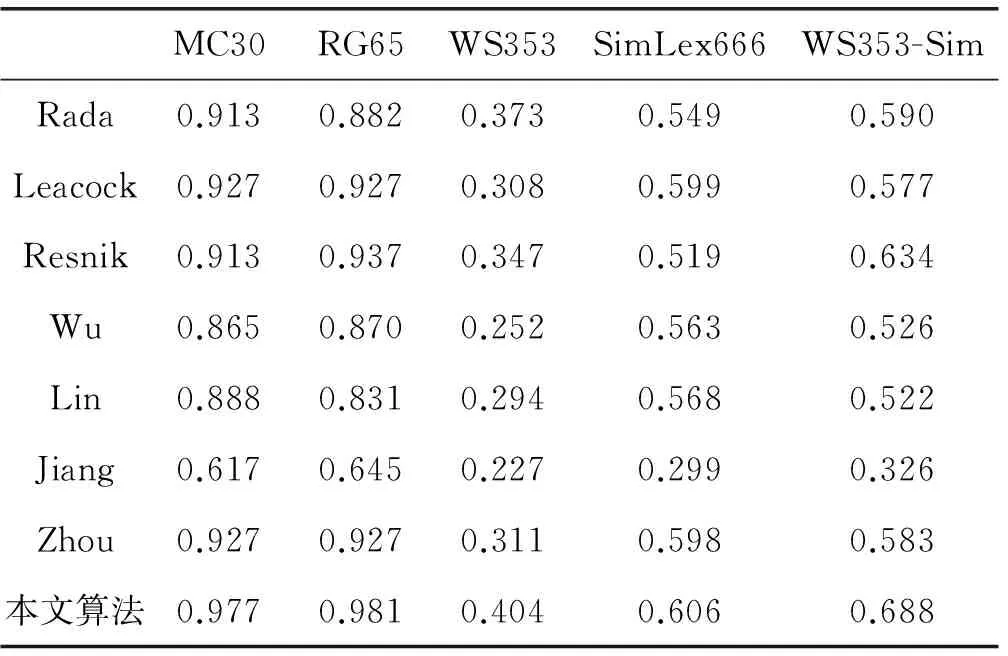
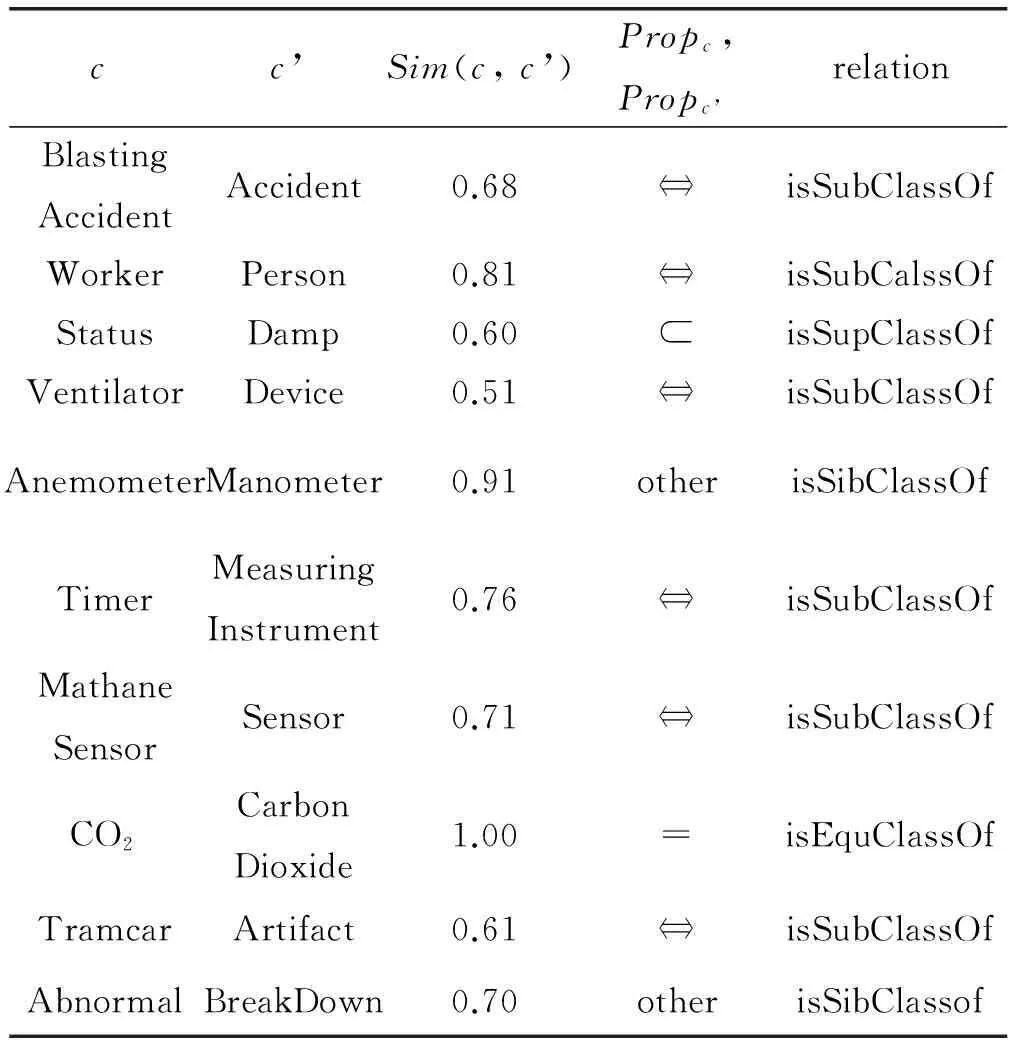
图中每个节点代表一个同义词集合即概念,WordNet根据概念的词义信息将所有概念按照树状结构组织起来,使得概念之间具有一定的语义联系,利用概念之间的层次结构关系可以度量相似度。概念之间的语义关系通过一个有向箭头连接表示,箭尾对应上位概念,箭头对应下位概念。下位概念继承了上位概念的全部特征,但又具有自身特有的性质,使其区分于其上位概念以及兄弟概念。基于WordNet的相似度计算通过WordNet的分类结构或概念统计信息映射得到一个数值,以此表示概念之间的语义相似度。利用图1中的分类片断,具体计算一些概念对实例的相似度,进一步比较分析传统的基于路径、基于深度、基于信息量以及混合相似度计算所存在的问题。例如对于概念对(yak’s milk, goats’ milk)和(yak’s milk, wine),yak’s milk和goats’ milk都属于milk,而wine属于alcohol,实际应用中就要求sim(yak’s milk, goats’ milk)>sim(yak’s milk, wine)。但是对于Rada、Leacock[22]等只考虑路径因素的相似度算法得出的结果却是相等的。同样地,sim(milk, alcohol)和sim(yak’s milk, goats’ milk),sim(hooch, wine),由于最短路径都为2,得到的相似度值也一样。Wu等[23]尝试考虑概念的深度解决这种缺陷。在分类体系中,下层结点比上层结点更具体、更详细,因此处于较大深度的下层概念对相似度也越大。从图1中可看出hooch、wine作为alcohol的子概念,所处位置更深,因此sim(hooch, wine)>sim(milk, alcohol)。尽管利用深度信息,算法的性能有所提高,但是对于许多处于同一层次的概念,仍会得出相同的相似度值,比如sim(yak’s milk, goats’ milk),sim(hooch, wine)。为了解决同等路径和深度所引起算法失效问题,Resnik、Lin、Jiang等引入了概念的信息量,每个概念都具有各自的信息量,比如milk的信息量为9.296,alcohol的信息量7.91。利用信息量计算相似度,算法思想是两个概念拥有的相同信息越多越相似,有学者通过计算两个概念的最小公共父节点所携带的信息量来反应二者的相似度,所以sim(yak’s milk, goats’ milk) 通过以上对传统的语义相似度算法的优劣性分析,本文在基于路径的相似度算法的基础上,充分考虑WordNet本体结构特征,利用信息量和深度弥补只考虑路径信息所带来的缺陷和局限,给出了一种结合路径距离、深度以及信息量的混合算法。相似度算法的计算模型定义为: Simstru(c1,c2)= (1) 式中:α是调整因子,取值为(0,1),α的值可通过多次实验确定,LCS(c1,c2)即为c1,c2的最小公共父节点,IC(c)用来计算概念c拥有的信息量。基于本文改进后的相似度算法的核心是利用概念间的最短路径以及各自的深度信息表征二者之间的区别。同时又利用最小公共父节点的深度和信息量作为二者的共性表示,从而避免了不同概念对距离、深度相同时所导致的相似度值相等的问题。比如距离相同的概念对(milk, alcohol),(yak’s milk, goats’ milk),(hooch, wine)不会得到同样的相似度值。当概念间的距离相等的时候,若二者共享的信息越多则越相似。本文改进后的算法通过将层次信息和信息量二者结合起来,保留了WordNet的结构信息和层次信息,概念对越具体、距离越近、信息量越高的概念,相似度值越大,避免了基于路径或基于信息量所带来的缺陷,有利于提高计算结果的准确性。 与Wordnet词汇分类体系中的概念不同,本体中的概念一般都有属性描述。属性特征提供了一定的语义信息并对概念加以区分和联系,两个概念拥有的共同属性越多,不同属性越少,二者越接近;若二者拥有的属性完全不同,则意味着两个概念毫无联系[24]。有效利用属性的语义相似度,能够改善本体概念相似度算法的性能。Jaccard相似度系数从统计的角度来衡量两个样本集的相似程度,计算模型为: (2) J(A,B)取值范围为(0,1),属性相似度的理论依据是拥有的共同属性越多概念越相似,本文将借鉴Jaccard系数计算属性间的相似度,计算公式如下: Simprop(c1,c2)= (3) 式中:Propc1,Propc2分别表示两个概念各自的属性集,Propc1∩Propc2表示二者所共同拥有的属性。 通过将属性相似度和基于WordNet本体结构的结构相似度进行合并得出综合相似度,综合相似度计算模型为: Sim(c1,c2)=γ×Simstru+(1-γ)Simprop (4) 式中:γ作为权重因子可通过实验进行调整。 基于语义相似度的本体概念更新方法SSOCUM的基本思想是对于一个新概念,依据WordNet语义词典计算其与本体中已有概念的结构相似度。然后通过计算概念间属性相似度对结构相似度进行补充和修正。最后根据二者加权得到的相似度计算结果,对新概念进行分类。 SSOCUM算法: 输入:新概念c,概念-属性矩阵X 输出:与新概念c最相似的本体概念c_best Begin 1) 从X中任选一个概念,设为c’,计算c与c’的结构相似度: Simstru(c,c’)= 2) 从X中分别获取概念c和c’所在行向量,记为Propc={p1,p2,…,pn},Propc’={p’1,p’2,…,p’n},计算c与c’的属性相似度: Simprop(c,c’)= 3) 计算概念c与c’的综合相似度:Sim(c,c’)=γ×Simstru+(1-γ)Simprop。 4) 反复执行1-3,直至X中所有概念循环完毕,得到c的综合相似度集合:ComSim[]。 5) 比较ComSim[]中的元素大小,确定相似度最大值对应的概念:c_best。 End 通过以上算法的执行,找到与新概念最相似的本体概念,本体概念产生一个新节点,新概念将自动加入到到本体中。 为了验证改进的相似度算法计算结果的准确性,本文采用一些公共的标准数据集评估改进的相似度算法与传统的相似度算法的性能。MC30[25]、RG65[26]、WS353[27]、WS353-Sim[28]、SimLex66[29]都是最常使用评估相似度算法的数据集,用三元列表来描述,每一对词汇都对应一个人工判断的相似度值。本文将采用以上所有的数据集进行相似度算法性能的比较测试,使实验结果更加全面、客观。 针对本文所分析的经典相似度算法以及改进后的算法,分别计算其计算结果与5个标准数据集对相似度的人工判断值之间的皮尔森相关系数。皮尔森相关系数用来度量人工判断和算法计算得到的相似度结果之间的线性相关程度,相关系数的绝对值越大,算法准确度越高[30]。结果如表1所示,相关系数越高,也就是值越接近于1,则相似度算法的计算结果越接近于人工判断结果。 表1 标准数据集相关系数比较 从表1中可以看出,本文改进算法在MC30和RG65数据集上得到的皮尔森相关系数都达到了0.9以上,算法性能有所提高。然而在其余数据集的效果却没有很好,原因可能是其余数据集的概念对样本数较多,影响了算法性能。但从整体上看,本文算法计算结果和人工判断结果之间的相关程度仍高于其他算法。由此得出,在基于路径的基础上,又融合了深度和信息量因素,综合考虑了概念的层次信息和统计信息,对于相似度计算结果的准确度有一定的改善。 本文以人工构建好的煤矿领域通风系统本体为实验对象,通过比较利用SSOCUM算法与人工添加新概念的结果是否相符。并借助Java WordNet Interface(JWI)开发包、Protégé4.3、Eclipse等工具来验证SSOCUM的有效性。目前有关煤矿领域的本体构建还不完备,本文研究的煤矿领域通风系统本体对煤矿安全生产及风险预警有重大意义。通过参考《通风安全技术工人》以及煤矿安全管理标准相关书籍与文献,从中获取相关术语并设计了分类体系。利用Protégé4.3建模工具构建了煤矿领域通风系统本体模型(如图2所示),主要包括8个顶层核心类:事故(Accident)、措施(Measure)、风险(Risk)、风险因子(RiskFactor)、风险等级(RiskLevel)、预警等级(WarningLevel)、工作地点(WorkingPlace)、状态(Status),每个核心类又被进一步细化为若干子类。 图2 煤矿领域通风系统本体(部分) 为了保证实验结果的准确性,首先对通风系统本体中的概念进行预筛选,剔除掉8个顶层类以及风险等级类、预警等级类等,这些类的层次关系基本依赖人为确定。接下来针对收集到的其余123个概念以及104个属性,建立相应的概念-属性矩阵如图3所示。第一列列举了本体中所有的概念,第一行涵盖了本体中概念所具有的所有属性,1表示概念拥有该列属性,0表示概念不具有该列属性。 图3 概念-属性矩阵(部分) 利用SSOCUM分别对本体中所有概念重新分类,部分实验结果如表2所示。 表2 SSOCUM算法实验结果 为了体现SSOCUM算法的分类效果,在实验过程中,以表2中一组数据为例,CO2作为一个待添加的新概念c,属性集定义为PropCO2={hasParameterValue[Double],hasConcentrationValue[Double]}。通过相似度算法模型计算其与本体中所有概念的相似度值,发现其与概念CarbonMonoxide最相似,且相似度值为1,表明二者为同义概念,并且二者具有同样地属性集定义。因此将CO2作为CarbonMonoxide的等价类加入到本体中,与实际情况相符,表明利用本文方法可以实现本体新概念的添加并符合人的判断,同时避免了冗余概念的加入。 本文首先对传统的基于WordNet的相似度算法进行了改进,在计算过程中充分考虑WordNet本体结构中的语义信息。利用基于路径方法的优势,结合节点深度、信息量来计算相似度。此外,为了弥补改进的相似度算法没有考虑概念属性所携带的语义信息,引入属性相似度对其进行语义补充。在此基础上,给出了一种基于语义相似度的本体概念更新方法SSOCUM。实验表明,本文改进的相似度算法的准确性较传统算法有一定提高,能够满足一定的应用需要。选用实际构建的煤矿领域通风系统本体验证SSOCUM算法的有效性,结果表明,融合了属性相似度的SSOCUM算法能够达到预期的分类结果,有助于解决本体新概念添加的问题。 [1] Saia R,Boratto L,Carta S.Introducing a Weighted Ontology to Improve the Graph-based Semantic Similarity Measures[J].International Journal of Signal Processing Systems,2016,4(5):375-381. [2] Liu K,Mitchell K J,Chapman W W,et al.Formative evaluation of ontology learning methods for entity discovery by using existing ontologies as reference standards[J].Methods of Information in Medicine,2013,52(4):308-316. [3] 周运,刘栋.基于语义相似度的领域本体概念更新方法研究[J].计算机工程与设计,2011,32(8):2833-2835. [4] 刘龙历,薛勇,光洁,等.基于本体概念相似度的遥感信息服务匹配研究[J].计算机工程与应用,2016,52(8):13-18. [5] Zhu X.A novel WordNet-based approach for measuring semantic similarity[J].Journal of Information & Computational Science,2015,12(13):4919-4927. [6] Jiang Y,Bai W,Zhang X,et al.Wikipedia-based information content and semantic similarity computation[J].Information Processing & Management,2017,53(1):248-265. [7] 贺元香,史宝明,张永.基于本体的语义相似度算法研究[J].计算机应用与软件,2013,30(11):312-315. [8] 张思琪,邢薇薇,蔡圆媛.一种基于WordNet的混合式语义相似度算法[J].计算机工程与科学,2017,39(5):971-977. [9] Gao J B,Zhang B W,Chen X H.A WordNet-based semantic similarity measurement combining edge-counting and information content theory[J].Engineering Applications of Artificial Intelligence,2015,39(3):80-88. [10] 张沪寅,温春艳,刘道波,等.改进的基于本体的语义相似度计算[J].计算机工程与设计,2015(8):2206-2210. [11] Rada R,Mili H,Bicknell E,et al.Development and application of a metric on semantic nets[J].IEEE Transactions on Systems,Man and Cybernetics,1989,19(1):17-30. [12] Hao D,Zuo W,Peng T,et al.An approach for calculating semantic similarity between words using WordNet[C]//Second International Conference on Digital Manufacturing and Automation.IEEE,2011:177-180. [13] Resnik P.Semantic Similarity in a Taxonomy:An information-based measure and its application to problems of ambiguity in natural language[J].Journal of Artificial Intelligence Research,1999,11(1):95-130. [14] Meng L,Gu J,Zhou Z.A new model of information content based on concept’s topology for measuring semantic similarity in WordNet[J].International Journal of Grid and Distributed Computing,2012,5(3):81-94. [15] Lin D.An information-theoretic definition of similarity[C]//Fifteenth International Conference on Machine Learning,1998:296-304. [16] Jiang J J,Conrath D W.Semantic similarity based on corpus statistics and lexical taxonomy[C]//Proceedings of International Conference Research on Computational Linguistics,1997:19-33. [17] 吕欢欢,宋伟东,杨睿.基于领域本体的综合加权语义相似度算法研究[J].计算机工程与设计,2013,34(12):4209-4213. [18] Wei T T,Chang H Y.Measuring word semantic relatedness using WordNet-based approach[J].Journal of Computers,2015,10(4):252-259. [19] 郑志蕴,阮春阳,李伦,等.本体语义相似度自适应综合加权算法研究[J].计算机科学,2016,43(10):242-247. [20] Zhou Z,Wang Y,Gu J.New model of semantic similarity measuring in wordnet[C]//International Conference on Intelligent System and Knowledge Engineering.IEEE,2008:256-261. [21] Abdul-Ghafour S,Ghodous P,Shariat B,et al.Semantic interoperability of knowledge in feature-based CAD models[J].Computer-Aided Design,2014,56(11):45-57. [22] Leacock C,Chodorow M.Combining local context and WordNet similarity for word sense identification[J].An Electronic Lexical Database,1998:265-283. [23] Wu Z,Palmer M.Verbs semantics and lexical selection[C]//Meeting on Association for Computational Linguistics.Association for Computational Linguistics,1994:133-138. [24] 丁博,苗世迪.制造资源本体的概念语义相似度研究[J].计算机应用研究,2016(1):28-31. [25] Miller George A,Charles Walter G.Contextual correlates of semantic similarity[J].Language Cognition & Neuroscience,1991,6(1):1-28. [26] Rubenstein H,Goodenough J B.Contextual correlates of synonymy[J].Communications of the Acm,1965,8(10):627-633. [27] Finkelstein R L.Placing search in context:the concept revisited[J].Acm Transactions on Information Systems,2002,20(1):116-131. [28] Agirre E,Alfonseca E,Hall K,et al.A study on similarity and relatedness using distributional and WordNet-based approaches[C]//Proceedings of human language technologies:the 2009 annual conference of the North American Chapter of the Association for Computational Linguistics.Association for Computational Linguistics,2009:19-27. [29] Hill F,Reichart R,Korhonen A.SimLex-999:Evaluating semantic models with (genuine) similarity estimation[J].Computational Linguistics,2015,41(4):665-695. [30] Adhikari A,Singh S,Dutta A,et al.A novel information theoretic approach for finding semantic similarity in WordNet[C]//TENCON 2015-2015 IEEE Region 10 Conference.IEEE,2016:1-6.2 基于改进相似度算法的本体更新方法
2.1 本体概念语义相似度计算
2.2 本体概念更新方法
3 实验及结果分析
3.1 相似度算法实验及结果分析
3.2 SSOCUM算法实验及结果分析


4 结 语
