基于AHP的全文搜索算法优化
2018-05-02李臣龙窦易文
李臣龙,陶 皖,窦易文
(安徽工程大学 计算机与信息学院,安徽 芜湖 241000)
0 引言
随着互联网+时代到来,信息的高速增长,人们对信息获取的要求越来越高.传统的搜索引擎提供的搜索服务往往是基于广度的,对个个行业领域的专业性搜索传统的搜索引擎很难直接有效地满足用户需求.另外由于各部门对信息的保密性的个性化等要求,对于局域网内部资料的搜索,传统搜索引擎的信息抓取也往往被禁止,因此企事业单位的内部信息资源搜索系统的设计,对于优化内部信息资源检索显得尤为重要.其主要应用是面向特定领域定向采集信息,对这些信息进行加工后再以用户需要的形式快速地返回给用户.
针对上述需求,本文设计并开发了针对企事业单位局域网的桌面搜索引擎.系统采用一款高性能的、可扩展的信息检索(IR)工具库Lucene[1],实现了对常见文本格式(word/pdf/txt)的分析转换、索引查找和排序功能.通过分析Lucene默认文档相似度排序算法存在的问题,重点优化了二次检索排序算法,并通过SSH框架实现用户管理、文档索引管理和文档搜索.
1 基于Lucene全文搜索引擎系统架构
基于Lucene全文搜索系统可架构在单机或分布式系统中,服务器端分为文件服务器、搜索服务器,本系统依据服务器性能,把搜索服务和文件服务架构在同一服务器,局域网客户端可以通过SSH框架分权限实现对文档索引存储和搜索服务.其中索引服务根据用户上传文档的实时动态,监控索引文档路径,定时抓取实现文档的索引存储,如图1所示.

图1 全文搜索引擎系统架构
系统采用Lucene实现文档的索引存储及搜索功能.Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供.Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻.因此Lucene在近年来已经成为最受欢迎的开源信息检索工具库[2].Lucene主要的源码子包和功能如表1所示.
Lucene实现检索的过程如图1,整个检索系统可以分为信息的索引存储、信息检索两大模块.实现信息的索引存储,首先检索系统通过第三方工具包对原始文档(word、pdf)转换构造为 Document对象,然后通过org.apache.lucene.analysis包对Document语言分析与分词,再次,org.apache.lucene.index包对所有文档分析得出的语汇单元创建索引,最后通过org.apache.lucene.store实现存储.信息检索模块的流程主要是,用户输入检索表达式,org.apache.lucene.analysis实现语法分析与分词;org.apache.lucene.Se-arch实现信息搜索;org.apache.lucene.Similarity完成检索结果排序算法[3].Lucene检索流程如图2所示.

表1 Lucene开发子包功能

图2 检索流程图
3 Lucene的检索模型与文档排序算法
使用Lucene框架能够高效构建全文检索系统,但在检索文档相似度的算法方面存在不足.Lucene的相似度算法采用向量空间模型.lucene的相似度计算公式如公式1所示,
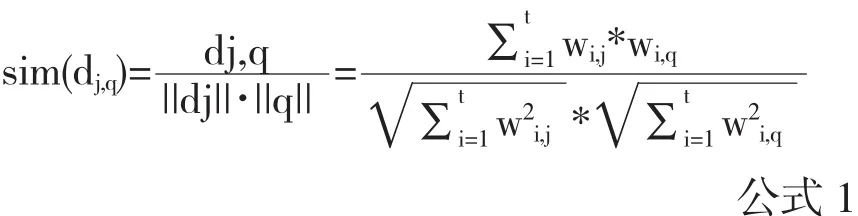
其中dj和q分别是文档j和查询矢量,Lucene相似度得分的核心是比较所有文档集中每篇文档矢量与查询矢量相关度,依据文档的相似度得分排序搜索结果集.对于文档得分的实际计算公式如公式2[4][5]所示.
在中小型企事业单位,由于网络信息资源的复杂性,对文档的搜索排序要求,除了考虑Lucene文档自身得分因素,还需要考虑以下因素:
1.搜索文档的下载量与最后更新时间
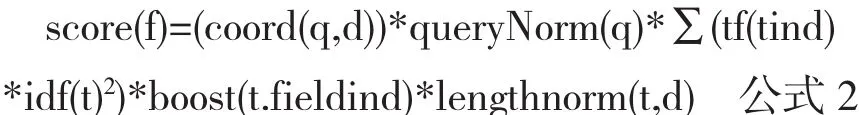
公式2中主要的参数因子含义如下[7]:q表示一个用户查询,通过分词处理建立q矢量;f表示文档,通过分词索引建立文档矢量;矢量由若干t词项组成.
tf(t in d)表示词项t在文档d中出现的频率数值,一般频率高重要性大,但也存在词频过高的情况,如果词频过高则可能该词普遍性强,则通过idf(t)(invert document frequency)即与文档频数成反比的值来降低该词在文档集中的重要性.boost指的是在对文档建立索引时,赋予文档的激励因子.lengthNorm:长度归一化(Length norm):基于域的一个归一化因子.其值由给定域中Term的个数决定(在索引文档的时候已经计算出来了,并且存储到了索引中).域越的文本越长,因子的权重越低.这表明Lucene打分公式偏向于域包含Term少的文档.
基于lucene的排序算法的特点是,文档与查询的相似度主要取决于词频重要性,与查询q中的词在文档中出现的位置无关,如果一个文档d中所包含的查询q中的词项越多,那么文档d的排序得分就越高,反之得分越低,所以Lucene得分的主要缺点是仅仅考虑了文档索引词项的词频重要性,忽视了词项的位置特征、语义特征以及网络链接操作的重要性,不能体现专业个性化[6].
4 Lucene文档排序算法优化
4.1 文档排序算法得分因子
文档的下载次数体现了文档的查看和使用度,在全文搜索中,它的权值比查看率更为重要;另外,文档的修改时间体现的是文档的最新执行,往往对文档质量有很大影响,所以结合两种因素,采用Download-throughRank(DTR)算法,来提升文档更新时间和下载数量对搜索结果的影响.Download-throughRank(DTR)算法公式 3:

其中f为检索文档,DTR(f)为文档f的重要性得分,T(f)表示文档f被检索到的周期次数,1/T(f)越小说明文档最新检索;C(f)表示文档上一周期检索下载量;C(f)MAX表示上一周期文档集中检索下载最大量值.公式3较好的解决了下载量与更新时间的矛盾.
2.搜索文档标题字段搜索词的加权
一般情况下,文档的标题是针对文档具体内容的精准概括,文档的详细内容与标题必然相关,所以搜索词在标题当中,应该比在文档内容当中出现更为重要.
3.搜索文档的查看率
搜索文档的查看次数往往反应文档的关注度和重要性,在搜索排序时应该考虑适当加权.
4.2 优化的排序算法
结合Lucene原有的向量相似度排序算法,修改后的文档得分排序公式如公式4所示:
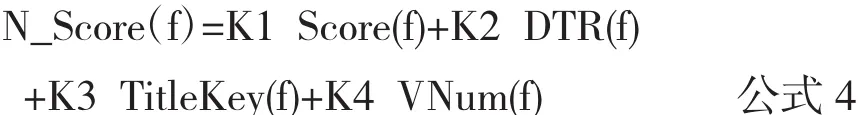
其中N_Score(f)为文档f最终文档排序得分,Score(f)为文档f的Lucene向量空间算法得分,DTR(f)为文档下载量和更新时间得分,TitleKey(f)为文档f标题加权得分,VNum(f)为文档f浏览量得分.K1,K2,K3,K4为每一项的权重系数.
2.基于AHP的权重系数设计
在多因素的综合评估问题中,各个因素对评估目标的影响程度有大小之分,因此需要对不同因素赋予不同权重.层次分析法将定性与定量分析相结合,特别适应于系统中某些因素缺乏定量数据或者难以用完全定量分析方法处理的政策性较强或带有个人偏好的决策问题[7].其基本思路是分析复杂问题所包含的因素及其相互关系,将问题分解为多个层次和多个要素,并在每一层次按照一定准则对该层元素进行比较,再按标度定量化形成判断矩阵.通过计算判断矩阵的最大特征值以及相对应的正交化特征向量,得出该元素对该准则的权重.本文采用AHP方法确定公式4中四个因子系数K1,K2,,K3,K4 的权重,具体步骤如下:
(1)分析系统各因素间的关系,建立递阶层次结构.如图4.1
最高层设计成总目标的比重程度;准则层的准则分别设计为:Lucene向量空间算法得分Score(f),文档下载量和更新时间得分DTR(f),文档f标题摘要加权得分TitleKey(f),文档f浏览量得分VNum(f).最低层为由4个准则而计算出来的的不同权重系数向量.

图4.1 层次结构模型
(2)对同一层个元素关于上一层中某一准则重要性进行两两比较,构造判断矩阵;根据表4.1的准则可以得到判断矩阵A.

表4.1 倒数标度法

(3)由判断矩阵计算被比较元素对于该准则的相对权重.方根法计算系数权重.第一,计算判断矩阵每一行元素乘积
(4)一致性检验.一致性指标CI=(λmax-n)/(n-1)=0.0741.CI≤0.10所以判断矩阵具有一致性.
5 测试环境及结果分析
本文实现的桌面搜索引擎系统,采用SSI(Struts2+Spring+ibatis)框架实现对用户的登录权限管理以及对搜索文档的索引维护管理;数据库采用mysql,主要实现用户信息存储以及文档索引数据等信息存储.检索系统基于lucene版本为3.6开发工具包,实现索引以及检索服务,文档解析word采用POI,PDF采用Xpdf实现,中文分词采用paoding,开发IDE为myeclipse10,开发java包为jdk1.6.检索系统分为前台一般、高级查询;后台功能主要包括索引初始化、pdf/word文档索引.文档以四篇包含 title、abstract、text、date、Download 等域进行索引查询.
为了测试修改后的排序算法对搜索结果的影响,本文企业搜索系统中的pdf文档为搜索集,在默认Lucene排序的前四篇文档进行对比分析,如表5.1所示
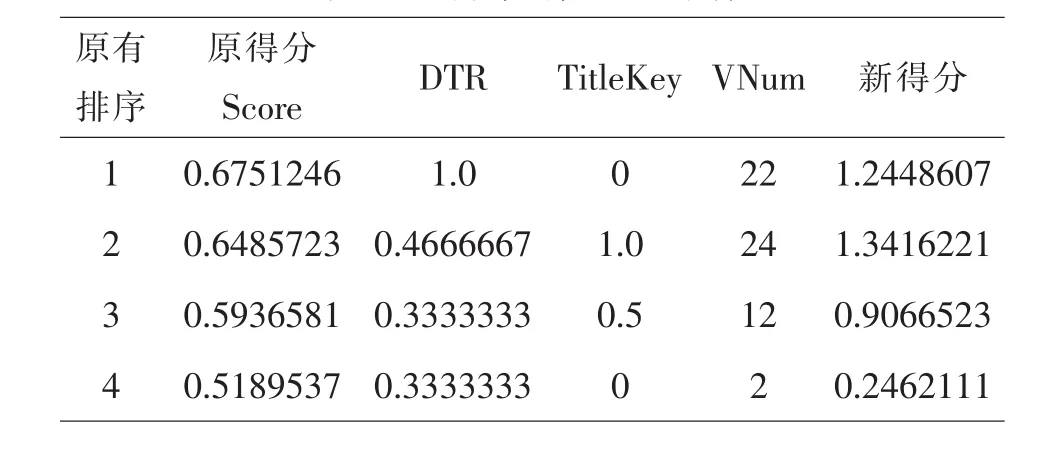
表5.1 排序得分主要指标
图3中,score为Lucene vsm原排序算法得分,DTR(f)为用户下载率评分,new_score为综合得分.按照测试前文档得分排序标记为f1/f2/f3/f4,加入用户因子DTR(f)后new_score为综合得分排序为f4/f2/f1/f3,其中对文档设定的下载次数通过后台数据库修改,分别为 8、5、15、50;从图 3 说明,改进后的算法对用户下载量较大的文档进行加权排名,排序结果因受到用户点击下载的影响提升了相关文档的相似度,较以前有较大改善改进后的搜索结果.

图3 两种算法对搜索结果排序的对比
图4为查询反馈页面,用户搜索关键词“搜索引擎”后,系统反馈的word文档排序页面,其中图中文档f4数据挖掘在只能搜索引擎中的应用由原来排名第4升为第1,排序达到了设计的预期目.

图4 搜索排序结果
6 结论
本项目基于Lucene架构,结合第三方开发工具实现了对文档的分词、索引存储与检索功能,优化全文搜索引擎先建立磁盘文件索引再进行搜索的机制的同时,重点优化了结果排序算法,实现了基于B/S的全文搜索引擎系统,能满足用户对站内搜的个性化功能需求,对比测试表明,搜索系统比一般搜索引擎更具优势.
参考文献:
〔1〕葛帅.开放源代码的全文检索引擎Lucene[EB/OL].http://www.lucene.com.cn/abou.t htm_Toc43005313,2010-08-15.
〔2〕百度百科.Lucene[EB/OL].http://baike.baidu.com/view/371811.htm·fr=aladdin,2012-08-18.
〔3〕(美)MichaelMcCandless等.Lucene 实战 (第二版)[M].北京:人民邮电出版社,2011.81-82.
〔4〕罗刚.解密搜索引擎技术实战[M].北京:电子工业出版,2011.396-400.
〔5〕王知津.信息存储与检索[M].北京:机械工业出版社,2011.115-119.
〔6〕孙宏才,田平,王莲芬.网络层次分析法与决策科学[M].北京:国防工业出版社,2011,6-7.
