基于DWT的可恢复数字语音取证算法
2018-04-27刘正辉祁传达信阳师范学院计算机与信息技术学院河南信阳464000
刘正辉, 孙 芳, 祁传达(信阳师范学院 计算机与信息技术学院, 河南 信阳 464000)
关于数字多媒体安全方面的研究,已有相当丰硕的研究成果[1-4]。如在数字音频取证方面,文献[5]分析了AMR编码量化对录音的影响,得出AMR压缩波形中存在显著的样本重复情况。然而该情况在其他压缩格式(如MP3、WMA等)中并不存在。基于此文献[5]给出了样本重复率的计算方法,并以此为特征提出了一种AMR压缩录音的检测方法。为解决基于公开特征的水印取证算存在的安全隐患,文献[6]选择保密的特征来嵌入用于取证的水印信息,提出一种抗特征分析替换攻击的数字语音取证算法。该方案从一定程度上提高了取证水印的安全性。
在一些应用场合,人们不仅需要验证语音内容的真实性,还渴望获得被攻击部分要表达的含义,即对被攻击内容的篡改恢复。对图像可恢复技术的研究已较为成熟[7-11],而关于可恢复的数字语音取证技术则鲜有报道[12]。可恢复的数字语音取证技术,能够恢复被攻击的内容,挖掘攻击者有意掩盖的事实,为推断攻击者的意图提供有益的参考。考虑到可恢复数字语音取证技术的实际需求,本文提出一种基于离散小波变换DWT(Discrete Wavelet Transform)的可恢复数字语音取证算法。首先给出了基于DWT的语音压缩和重构方法。基于该方法,本文将原始信号压缩为少量的DWT近似分量,验证了由DWT近似分量在保持语义前提下,对原始信号的重构能力。将帧号和压缩信号作为水印,采用基于分块的方法嵌入语音信号中。帧号用于定位被攻击的内容,压缩信号用于重构被攻击的信号,并进行篡改恢复。
1 基于DWT的语音压缩和重构
对于长为N的语音信号A,q阶DWT的结构见图1。其中,ACq和DCq分别表示q阶的近似分量(低频)和细节分量(高频),|ACq|和|DCq|表示ACq和DCq的长度。从某种程度上语音信号的低频包含了该信号的主要部分,而高频部分起到的是修饰作用。从获取语音信号要表达含义的角度讲,仅保留低频部分即可,基于此本文给出了基于DWT的语音压缩和重构方法。
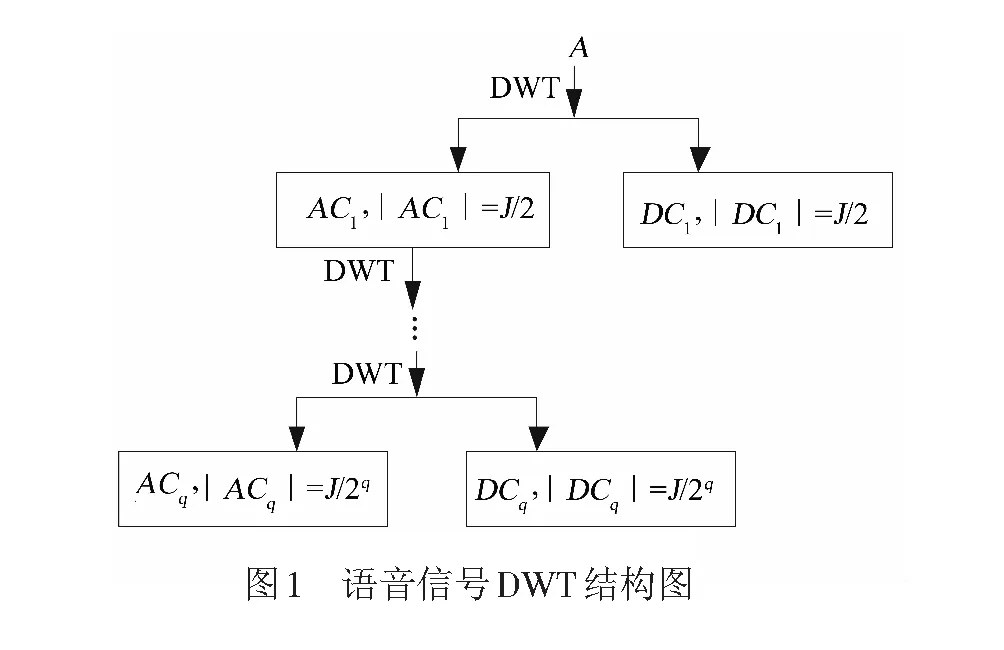
1.1 语音压缩
记原始语音信号为A={al|1≤l≤L},其中L表示语音信号的长度,al表示第l个样本点,压缩步骤为:
Step1将A分为P帧,第i帧记为Ai。
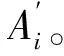
Step3对Ai进行D阶DWT(本文取3阶DWT),将最高阶DWT的近似分量作为压缩信号的一部分,记为C1i。
Step4将1到D阶细节分量置零,对C1i和置零的细节分量进行逆DWT,得到的信号记为R1i,将Ai和R1i做差,得到第i帧的残差信号Ei。
Step5对Ei进行2阶DWT,并将2阶DWT的近似分量记为C2i。C1i和C2i一起作为压缩信号,记Ci=C1i‖C2i,Ci即为第i帧的压缩信号。
1.2 信号重构
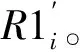
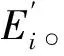
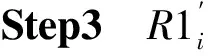
1.3 重构测试
(1) 本文压缩方法重构信号测试
随机选取一段长度为4 096,采样频率为44.1 kHz的语音信号,测试上述压缩方法的重构效果,步骤为:
Step1采用11.025 kHz的采样频率对语音信号进行重采样,采样后信号长度为1 024,见图2。
Step2对图2所示信号进行3阶DWT,然后对细节分量置零,逆DWT后得到的信号见图3。
Step3由图2、图3可得残差信号。对残差信号进行2阶DWT后,将细节分量置零,逆DWT得到的信号作为重构的残差信号,见图4。
Step4图3、图4合成的信号即为对1 024个样本点重构的信号,见图5。
(2) 不同压缩方法重构信号质量对比
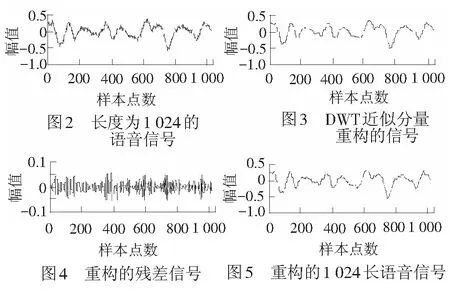
文献[12]给出了基于离散余弦变换DCT的语音信号压缩和重构方法。将语音信号DCT低频系数作为压缩信号,高频系数置零,并通过逆DCT来重构信号。图6、图7分别给出由文献[12]和本文方法重构图2信号和原始信号的残差(压缩信号样本点个数相等),并且图6信号能量大于图7信号。说明和文献[12]相比,本文所提方法重构信号的能量损失较小,更接近原始信号。
2 本文算法
2.1 预处理
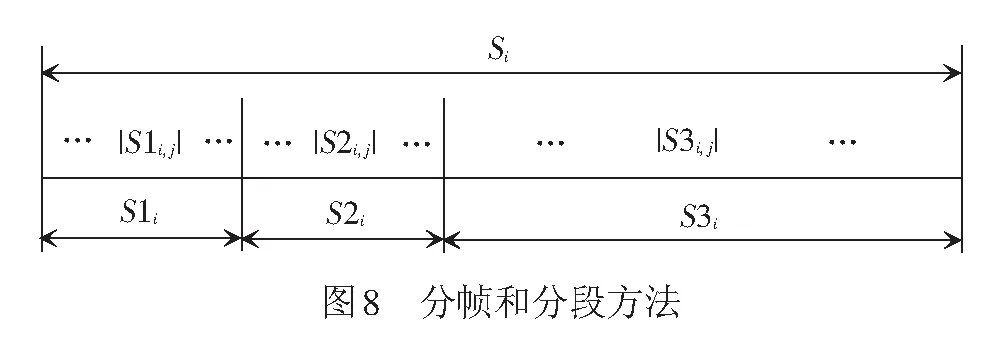
将语音信号A分帧、分段,方法见图8,具体步骤为:
Step1将信号A分帧,Ai表示第i帧,1≤i≤P。
Step2采用文献[6]中的方法,置乱Ai中的样本,并记生成的信号为Si。
Step3将Si分成3部分,用S1i,S2i和S3i来表示。将S1i和S2i等分成M个(3个样本为一组)子段,M表示用于篡改定位的整数序列的长度。第j段记为S1i,j和S2i,j,1≤j≤M。
2.2 帧号和压缩信号嵌入
(1) 帧号嵌入
Step1由式( 1 )将帧号i变换成M长的整数序列Yi={y1,y2,…yM}。yi作为第i帧的水印分别嵌入到S1i和S2i中。
i=y110M-1+y210M-2+…+yM
( 1 )
Step2将y1嵌入到S1i的第1个子段S1i,1中,并记S1i,1中的3个样本为s11,s12和s13。
Step3取s11,s12和s13小数点后第4位的值,记为v1,v2和v3。
Step4由式( 2 )令V=f(v1,v2,v3)。
f(v1,v2,v3)=mod(v1+v2×2+v3×3, 10)
( 2 )
Step5对比y1和V,量化v1、v2或v3。量化方法为v1±1、v2±1或v3±1,如文献[6]。以此完成y1的嵌入。
重复以上步骤,将Yi分别嵌入在S1i和S2i中。
(2) 压缩信号嵌入
根据本文篡改恢复的思路,如果第i帧的压缩信号嵌入到自身当中,在第i帧的内容被攻击后,嵌入其中的压缩信号也将受到攻击。这样就不能通过压缩信号来恢复该帧的内容。为解决该问题,首先将各帧生成的压缩信号置乱,使第i帧的压缩信号嵌入到其他帧中。如果第i帧的内容被攻击,可以从其他帧中提取压缩信号,来恢复被攻击的内容。
Step1将S3i,1的6个样本点分为6块,并记为B1,B2,…,B6,其中
Br=mod(⎣|10t·s31|,10)
3≤t≤5 1≤r≤6
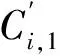
Step3计算B1中3个样本之和,记为sum(B1)。

如果BC1=-1(即Ci,1<0),且mod(sum(B1),2)=1,量化B1中最后一个样本加1或减1,使mod(sum(B1),2)=0。
Step4采用和帧号嵌入相同的方法,将BCt嵌入到Bt对应的样本中,2≤t≤6。
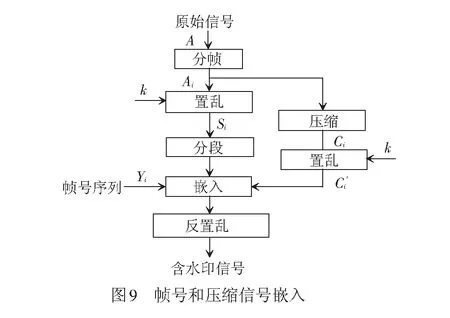
采用上述步骤,完成其他压缩信号的嵌入,并重复上述方法,将各帧帧号和压缩信号嵌入到对应帧中。并反置乱,来生成含水印的信号。帧号和压缩信号嵌入过程见图9。
2.3 篡改定位和篡改恢复
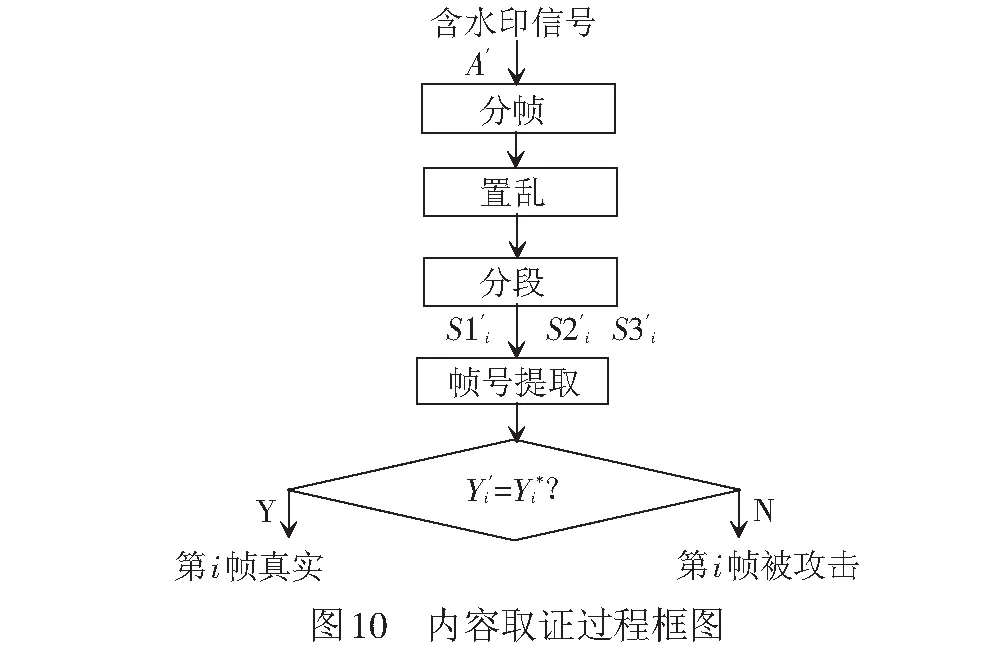
记A′为含水印信号,内容取证和篡改恢复过程分别见图10、图11,过程为:
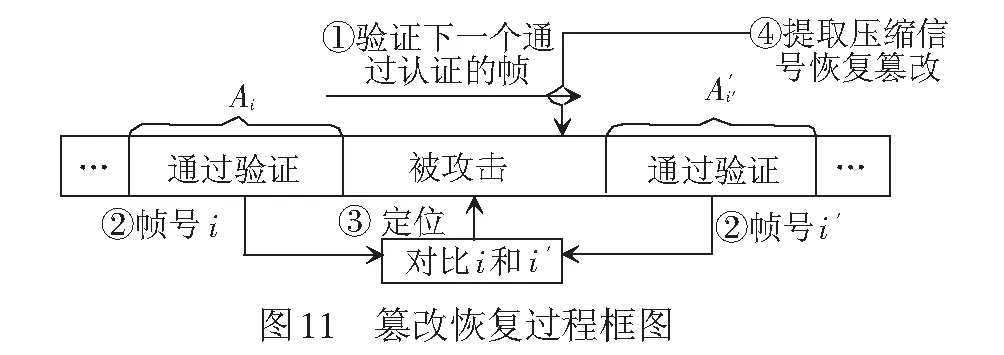
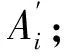
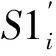
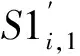
(4) 篡改定位和篡改恢复。假设含水印信号第1帧到第i帧的内容能通过验证,而紧接着的连续样本不能。对该部分的定位和篡改恢复过程,见图11,步骤为:
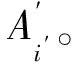
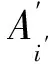
( 3 )
Step3第i帧和第i′帧之间的内容,即被定位到的被攻击内容。
Step4根据本文的置乱方法,找到被攻击内容对应的压缩信号嵌入位置,然后提取压缩信号,并重构被攻击的内容。
3 性能分析
考虑到实际情况,本文采用由录音笔在不同场景下录制的100个语音段作为测试信号。录制环境为寂静的会议室、讨论会现场、火车站和郊外,对应的样本类型分别标记为T1、T2、T3和T4。录制语音为单声道、采样频率为44.1 kHz的信号。其他用到的实验参数取值为L=245 760,P=20,f′=11 025 Hz,M=4;置乱系统中Logistic混沌映射的初值k=0.589 4,μ=3.934 2。
3.1 不可听性
本文采用主观区分度SDG(Subjective Difference Grades)和信噪比SNR(Signal to Noise Ratio)测试水印的不可感知性。SDG评分标准见表1,信噪比的计算方法为
( 4 )
式中:a(l)、a′(l)分别为原始语音信号和含水印语音的第l个样本点;L为信号长度。
表2给出了对100段信号测得的SDG值和SNR值,SDG值由15位听众打分得到。由测试结果可得,本文算法中水印是不可听的。
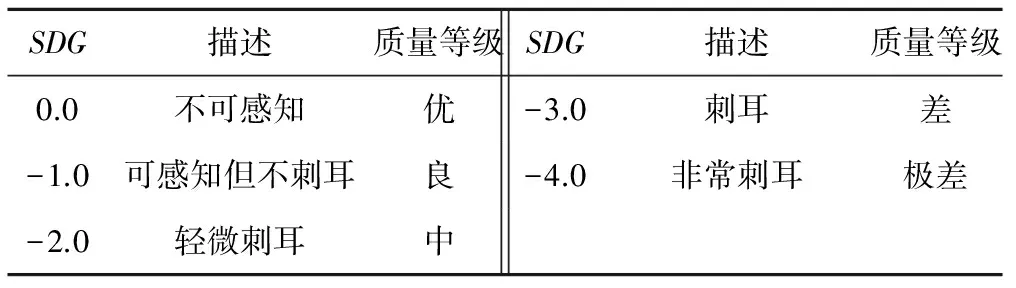
表1 SDG值的评分标准
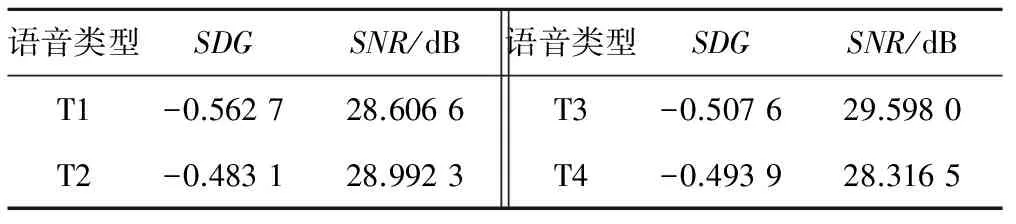
表2 不同类型语音信号的SDG值和SNR值
3.2 水印嵌入安全性
本文所提算法将水印嵌入在置乱后的样本中,通过反置乱来获取含水印的信号。本文中水印嵌入位置对合法用户(拥有系统密钥)才能获得。
如果在没有系统密钥的情况下,对含水印系统进行攻击,攻击内容能通过认证的概率为
( 5 )
式中:M越大(帧号映射整数序列越长),被成功攻击的可能性越小。
文献[13-14]指出,基于公开特征的水印算法存在安全隐患。式( 5 )给出了攻击者攻击本文算法的成功率Pv,Pv较小,说明攻击成功的概率较低。从而,和基于公开特征的水印算法[13]相比,本文在一定程度上提高了算法的安全性。
3.3 不同攻击的篡改定位和篡改恢复
随机选取图12中一段含水印信号,然后对其进行删除攻击、插入攻击和替换攻击,并给出篡改定位和篡改恢复结果,其中Ti=1对应的帧是真实的。
(1) 删除攻击
这里仅给出对删除攻击篡改定位和篡改恢复的详细步骤。由于篇幅原因,对于其他类型的攻击,仅给出相关的实验结果。
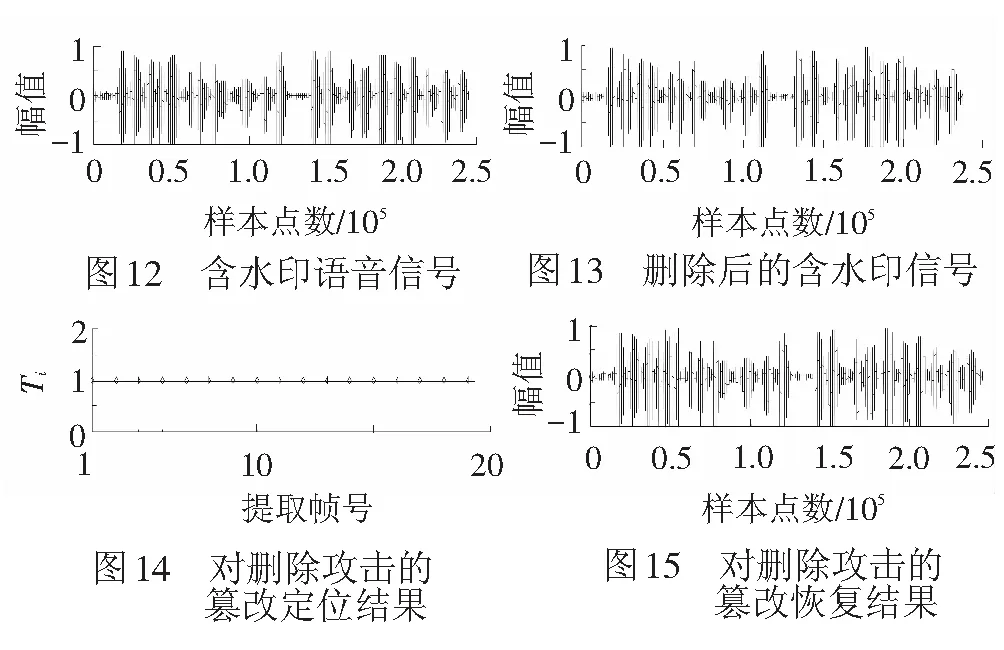
Step1删除含水印信号第45 601到第53 600个样本,攻击后的信号,见图13。
Step2根据本文的取证方法,逐帧验证其真实性,并提取能够通过验证帧的帧号,帧号提取结果,见图14。对于被攻击的帧,由于帧号不能被提取和重构,故图14中没有被显示的帧号对应的内容就是被攻击的部分。可知第4和第5帧被攻击。
Step3依据本文置乱方法,易得第4帧和第5帧的内容嵌入在第9帧和第18帧当中。从其中提取压缩信号,并重构被攻击的内容,重构结果见图15。
(2) 插入攻击
插入10 000个样本到含水印信号中,攻击的信号见图16。易得第11帧是被攻击的部分。从第13帧提取压缩信号,并恢复被攻击内容,篡改恢复结果见图17。
(3) 替换攻击
替换含水印信号第210 001到220 000个样本,见图18(第18帧是被攻击的部分)。从第6帧中提取对应的压缩信号,并进行篡改恢复,结果见图19。
表3给出了以上3类篡改恢复信号的SDG值,并和文献[12]所给算法进行了对比,从对比结果可见,基于本文算法篡改恢复的信号有更好的不可听性,从某种程度上而言,本算法篡改恢复信号的听觉质量高于文献[12]所给算法。
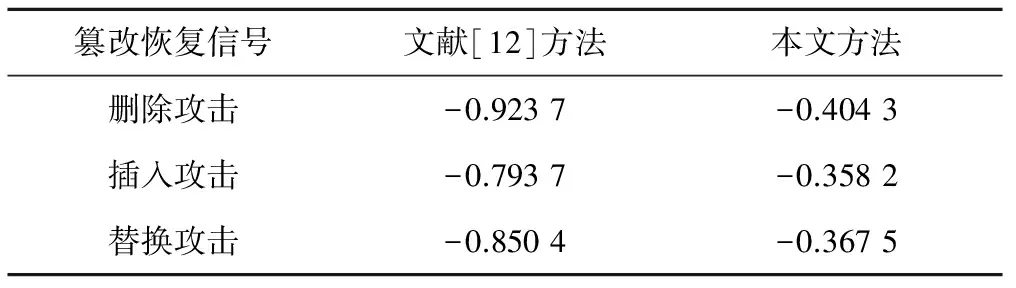
表3 不同类型攻击篡改恢复信号的SDG值
综合以上分析,本文所提算法嵌入水印具有较好的不可听性,提高了水印嵌入安全性,同时也提高了篡改恢复信号的听觉质量。
4 结束语
提出一种基于DWT的语音内容篡改恢复算法。给出了基于DWT的语音压缩和重构方法,并分析了重构信号的性能。将帧号作为各帧的标识和压缩信号一起进行嵌入。对被攻击信号,首先用帧号来定位被攻击的语音帧;然后,提取被攻击内容对应的压缩信号进行篡改恢复。本文算法提高了水印的安全性和篡改恢复信号的听觉质量。
参考文献:
[1] MARCO F,TIZIANO B,ALESSIA D R,et al.A Framework for Decision Fusion in Image Forensics Based on Dempster-shafer Theory of Evidence[J].IEEE Transactions on Information Forensics and Security,2013,8(4):593-607.
[2] CHEN S D,TAN S Q,LI B,et al.Automatic Detection of Object-based Forgery in Advanced Video[J].IEEE Transactions on Circuits and Systems for Video Technology,2015,26(11):2138-2151.
[3] SOODEH A,SHAHROKH G,WANG Z J.A Sparse Representation-based Wavelet Domain Speech Steganography Method[J].IEEE Transactions on Audio,Speech,and Language Processing,2015,23(1): 80-91.
[4] LIU Q,SUNG A H,QIAO M.Derivative-based Audio Steganalysis[J].ACM Transactions on Multimedia Computing Communications & Applications,2011,7(3):726-742.
[5] LUO D,YANG R,HUANG J W.Identification of AMR Decompressed Audio[J].Digital Signal Processing,2015,37(2):85-91.
[6] 王静,刘正辉,祁传达,等.一种抗特征分析替换攻击的数字语音取证算法[J].铁道学报,2016,38(6):73-78.
WANG Jing,LIU Zhenghui,QI Chuanda,et al.A Content Authentication Algorithm for Digital Speech Signal Robust Against Feature-analyzed Substitution Attack[J].Journal of the China Railway Society,2016,38(6):73-78.
[7] SINGH D,SINGH S K.Effective Self-embedding Watermarking Scheme for Image Tampered Detection and Localization with Recovery Capability[J].Journal of Visual Communication and Image Representation,2016,38(5):775-789.
[8] HONG C Q,CHEN X H,WANG X D,et al.Hypergraph Regularized Autoencoder for Image-based 3D Human Pose Recovery[J].Signal Processing,2016,124(7):775-789.
[9] ROLDAN L R,HERNANDEZ M C,MIYATAKE M N,et al.Watermarking-based Image Authentication with Recovery Capability Using Halftoning Technique[J].Signal Processing:Image Communication,2013,28(1):69-83.
[10] DONG W S,SHI G M,WU X L, et al.A Learning-based Method for Compressive Image Recovery[J].Journal of Visual Communication and Image Representation,2013,24(7):1055-1063.
[11] QIN C,CHANG C C,CHEN K N.Adaptive Self-recovery for Tampered Images Based on VQ Indexing and Inpainting[J].Signal Processing,2013,93(4):933-946.
[12] LIU Z H,ZHANG F. Authentication and Recovery Algorithm for Speech Signal Based on Digital Watermarking[J].Signal Processing,2013,123(3):157-166.
[13] LEI B Y,SOON I Y,LI Z.Blind and Robust Audio Watermarking Scheme Based on SVD-DCT[J].Signal Processing,2011,91(8):1973-1984.
[14] LIU Zhenghui,WANG Hongxia. A Novel Speech Content Authentication Algorithm Based on Bessel-fourier Moments[J]. Digital Signal Processing,2014,24(1):197-208.
