消除属性间依赖的C4.5决策树改进算法
2018-04-18唐耀先余青松
唐耀先 余青松
(华东师范大学计算中心 上海 200062)
0 引 言
近年来,先进的数据存储技术使人们能快速地搜集和存储海量的数据信息,促进了数据挖掘技术的飞速发展。分类是数据挖掘中的重要研究方向之一,主要的分类算法有决策树、贝叶斯、人工神经网络、K-近邻、支持向量机等[1]。其中,决策树以其预测准确率高、稳定性好、直观易懂等特点得到广泛应用和研究[2]。应用如文献[3]利用决策树进行水质建模测试;文献[4]利用决策树处理流量分类问题;文献[5]利用决策树探究人体测量。研究上如文献[6]在1993年提出的C4.5算法解决了连续属性值的处理问题和多值偏向问题;文献[7]把线性分类器和决策树结合在一起减少决策树的层数提高了决策树效率;文献[8]通过控制高维数据噪声来优化C4.5算法。但上述算法在构造决策树模型的过程中,选择分裂属性时仅仅只是考虑了属性对类的影响,却忽视了属性之间的相互影响。
在数据集的属性中,并非所有的属性都包含相同的信息量,有些属性包含较多会影响分类的信息量,而另外一些属性包含较少会影响分类的信息量[9]。同样,在数据集中选择一个待分裂属性后,剩下的属性集中,有的属性包含较多会影响待分裂属性取值的信息量,而另外一些属性包含较少会影响待分裂属性取值的信息量。例如学生有“年龄”和“年级”两个属性,年龄“大小”会影响到学生的年级“高低”,所以这两个属性之间有一定的影响,即它们有一定的依赖关系。上述例子只是一个极端的例子,本文认为任何两个属性或多或少都具有一定的依赖关系,并且定义这种依赖关系为依赖度,而依赖度会成为选择分裂属性的影响因素之一,忽视这种影响因素会对构造决策树模型产生不良影响。
本文针对上述问题,提出一种消除属性依赖的C4.5决策树改进算法,称之为DTEAT算法。DTEAT算法通过计算属性间的信息增益率来量化属性间的依赖度,在构造决策树的过程中把待分裂属性与其他属性间的依赖度均值作为选择分裂属性时的主要度量标准之一,从而消除属性间依赖关系对选择分裂属性时产生的影响,以达到提高最终模型分类准确率的目的。
1 C4.5决策树算法
1.1 决策树介绍[10]
决策树是一种类似流程图的树结构,其中每个内部节点(非树叶节点)表示在一个属性上的测试,每个分支代表一个测试输出,而每个叶子节点存放一个类标号。一旦建立好了决策树,对于一组未给定类标号的数据,跟踪一条由根节点到叶子节点的路径,该叶子节点就存放着该数据分类的预测。决策树的优势在于不需要任何领域知识或参数设置,适合于探测性的知识发现。图1就是一棵典型的C4.5算法对数据集产生的决策树。
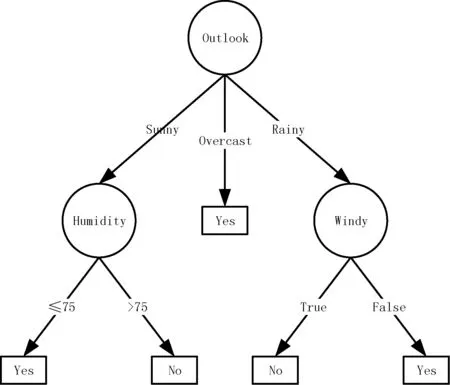
图1 决策树模型图
1.2 C4.5决策树生成
设有数据集D,|D|为D的样本总数。设类别C有m个不同的取值{C1,C2,…,Ci,…,Cm},|Ci|为D中属于类Ci的样本总数。设有n个不同的属性{Aj1,Aj2,…,Ajk,…,Ajt},属性Aj有t个不同的取值{aj1,aj2,…,ajk,…,ajt},|Djk|为D中属性Aj取值为ajk的子集Djk的样本总数,|Dijk|为在Djk中属于类Ci的样本总数。
一个数据集本身有很多属性,我们需要考虑属性进行判断的顺序,ID3算法引进了信息增益来量化属性对类别的影响程度,并将信息增益作为属性选择的度量标准[11]。在给定Aj的条件下,C在D中的信息增益计算公式为:
Gain(C,D|Aj)=Info(C,D)-Info(C,D|Aj)
(1)
式中:Info(C,D)为C在D中的信息熵,Info(C,D|Aj)为给定属性Aj的条件下,C在D中的信息熵:
(2)
(3)
则信息增益最终的计算公式为:
(4)
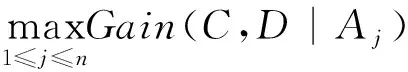
C4.5使用信息增益率来量化属性对类别的影响程度,并将信息增益率作为属性选择的度量标准,计算公式为:
(5)
式中:Info(Aj,D)为属性Aj在D中的信息熵:
(6)
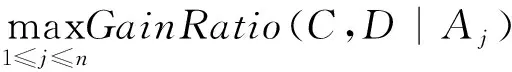
2 DTEAT算法
2.1 最优属性选择
属性选择使用BFS(Best First Search)算法对属性集进行搜索,在搜索的过程中使用CFS(Correlation-base Feature Selector)算法对属性进行评估选择。
BFS是宽度优先搜索的扩展,基本思想是将节点表按据目标的距离进行排序,再以节点的估计距离为标准选择待扩展的节点[12]。在搜索的过程中使用CFS评估算法,评估从初始节点到达目的节点的最佳路径代价。
CFS评估算法评估每个属性的预测能力以及相互之间的依赖度,倾向于选择与类别依赖度高,但是相互之间依赖度低的属性。
通过属性选择,先剔除掉与类别依赖度低或者相互之间依赖度高的属性,提高算法的效率,并且完成一次属性依赖的消除。
2.2 DTEAT的改进思想
信息增益率表示的是在给定一个属性条件下,类不确定性相对于没有属性限定条件时的减少量,即类对该属性的依赖度。同理在给定属性Ax的条件下,另一个属性Aj在D中的信息增益率即可表示属性Aj对属性Ax依赖度。
根据式(5),属性Aj对属性Ax依赖度公式为:
(7)
则属性Ax与其他所有属性的平均依赖度公式为:
(8)
式中:E为不包含Aj的属性子集,|E|为集合E的属性总数。
在选择分裂属性的时候不仅要考虑该属性给类带来最大的信息增益率,也必须考虑该属性和其他属性有最小的信息增益率,即该属性与其他属性有最小的平均依赖度。本文提出新的选择分裂属性的信息增益率公式:
(9)

2.3 DTEAT的算法流程
假设D代表当前样本集,当前候选属性集用A表示,则DTEAT算法见算法1。
算法1使用训练数据集构建决策树
输入:训练样本D;候选属性的集合A。
输出:一棵决策树T。
步骤1创建节点N。
步骤2如果D中的所有实例都属于同一类别Ci,则将N标记为Ci类叶节点,构建T为只包含N的单节点树,返回决策树T。
步骤3如果A为空,或者D中所有实例在A上取值相同,则将N标记叶节点,其类别标记D中实例数最大的类,置T为只包含N的单节点树,返回决策树T。
步骤4对于A中的每一个属性,利用式(9)计算属性对类产生的信息增益率GainRatioNew(C,D|Aj),选择具有最高信息增益率的属性Aj作为节点N的待分裂属性。
步骤5如果待分裂属性Aj为连续型,则找到Aj的分割阈值。
步骤6对于属性Aj的每一个属性值ajk,从节点N生成对应的子节点,并从D中划分出对应的子集Dk。如果Dk非空,构建子节点Nk,将其标记为Dk中实例数最大的类别,由节点及其子节点构建决策树T,返回T。
步骤7对节点Nk,以Dk作为训练集,A-Aj为特征集,递归调用步骤1-步骤6,得到子树Tk,返回Tk。
步骤8对T进行剪枝处理。
3 实验结果及分析
3.1 实验环境及数据集介绍
实验使用Weka分类平台和UCI数据集。Weka是新西兰大学提出的基于Java的开源开发平台,集合了包括数据预处理、分类、回归、聚类、关联规则等大量的机器学习算法,并实现了交互式界面上的可视化[13]。UCI是加州大学欧文分校提出的用于机器学习的数据库,种类涉及生活、工程、科学各个领域。它已被学生、教育工作者和其他研究机器学习的研究者作为数据来源广泛使用。本文的实验环境如表1所示。

表1 实验环境
本文使用UCI官方提供的Audiology、Heart-c、heart-h、Labor、Soybean、Splice、Vehicle等7组数据集进行实验,各个数据的样本总数和属性总数如表2所示。
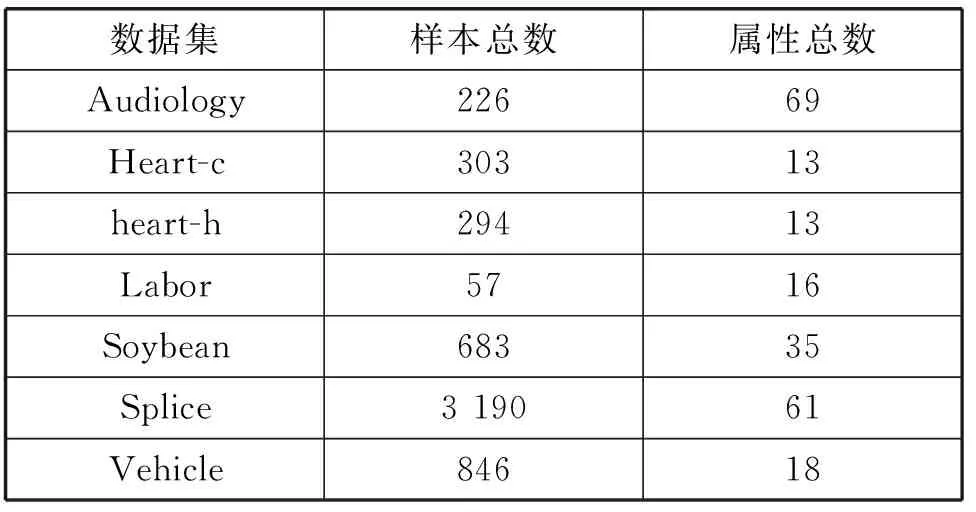
表2 数据集样本数和属性总数
3.2 实验结果及分析
实验一:对上述7组数据集进行属性选择。首先使用BFS算法进行属性搜索,然后使用CFS算法进行属性评估,选择最优的训练属性集。各组数据集剩余的最优属性总数如表3所示。属性选择是直接剔除掉一部分与类别依赖度低,但是相互之间依赖度高的属性,而剩下的属性之间依旧会有一定依赖度,因此在分类算法中消除属性间依赖度的影响还是很有必要。

表3 属性选择之后的数据集
实验二:数据集Labor具有57个样本,属性选择后具有7个最优属性,是一个二分类的经典数据集,只包含good和bad两种类别。本实验分别使用C4.5算法和DTEAT算法对属性选择后的该数据集进行分类,通过设置不同的阈值得到真正例率TP Rate和假正例率FP Rate,分别绘制C4.5和DTEAT两种分类模型的ROC平滑曲线图,如图2所示。
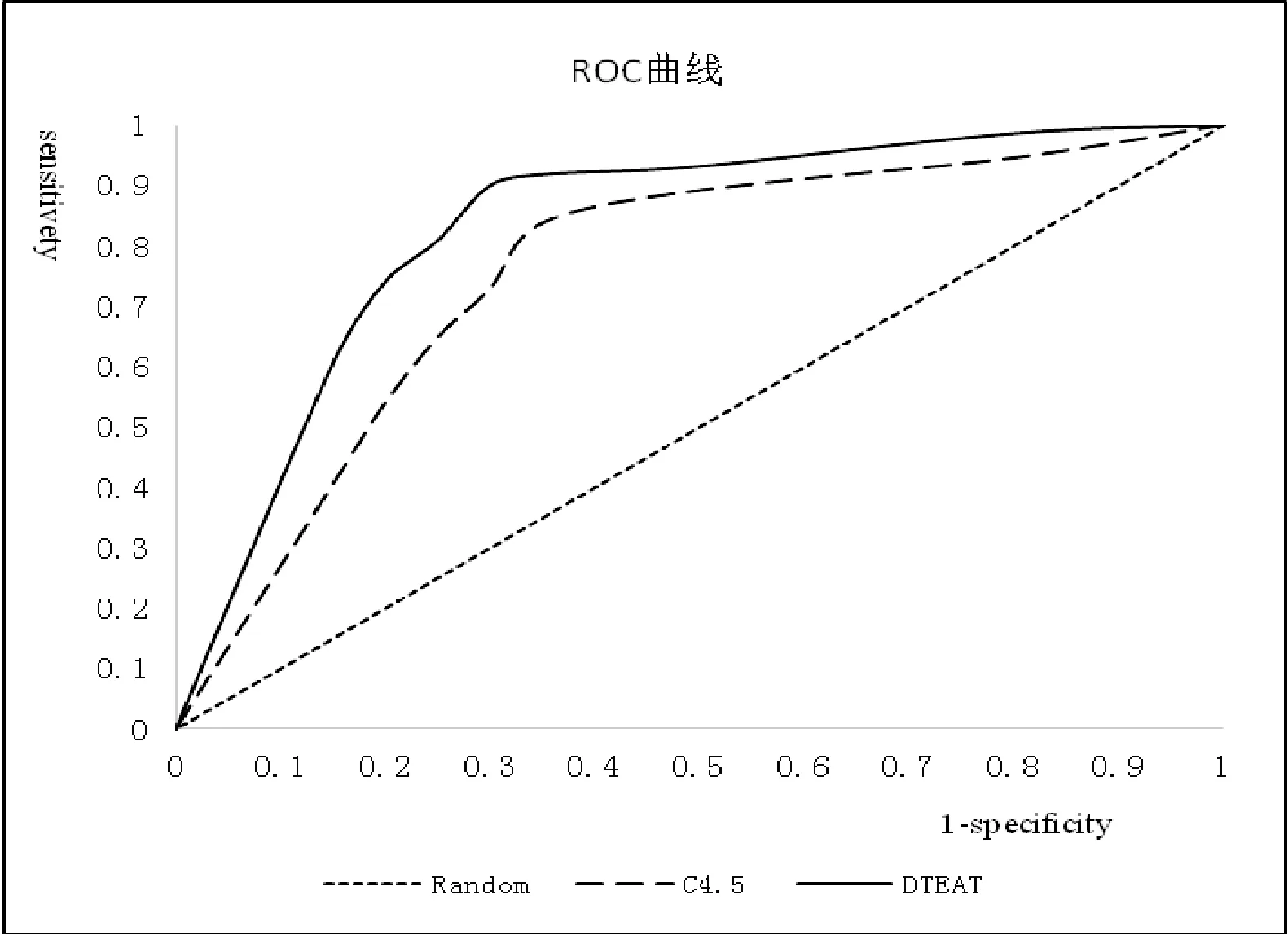
图2 ROC曲线图
ROC曲线即接受者操作特征曲线,表明了假正例率与真正例率之间的关系。ROC曲线可以用来判断分类方法的性能,ROC曲线下方包围的面积(AUC)越大,分类效果越好。本次实验计算出利用C4.5算法模型进行分类时,AUC的值为0.733 1,而利用DTEAT算法模型进行分类,AUC的值为0.812 9。DTEAT算法模型的AUC值明显大于C4.5算法模型的AUC值,由此可知DTEAT算法的分类效果比C4.5算法的分类效果好。
实验三:分别使用传统C4.5决策树算法和消除属性依赖的DTEAT算法在进行属性选择后的7组数据集上进行分类实验,然后通过十字交叉验证法计算分类准确率,最后对比两种算法的分类准确率,如表4所示。

表4 C4.5算法改进前后的准确率 %
两种算法在7组数据集上的分类准确率对比如图3所示。
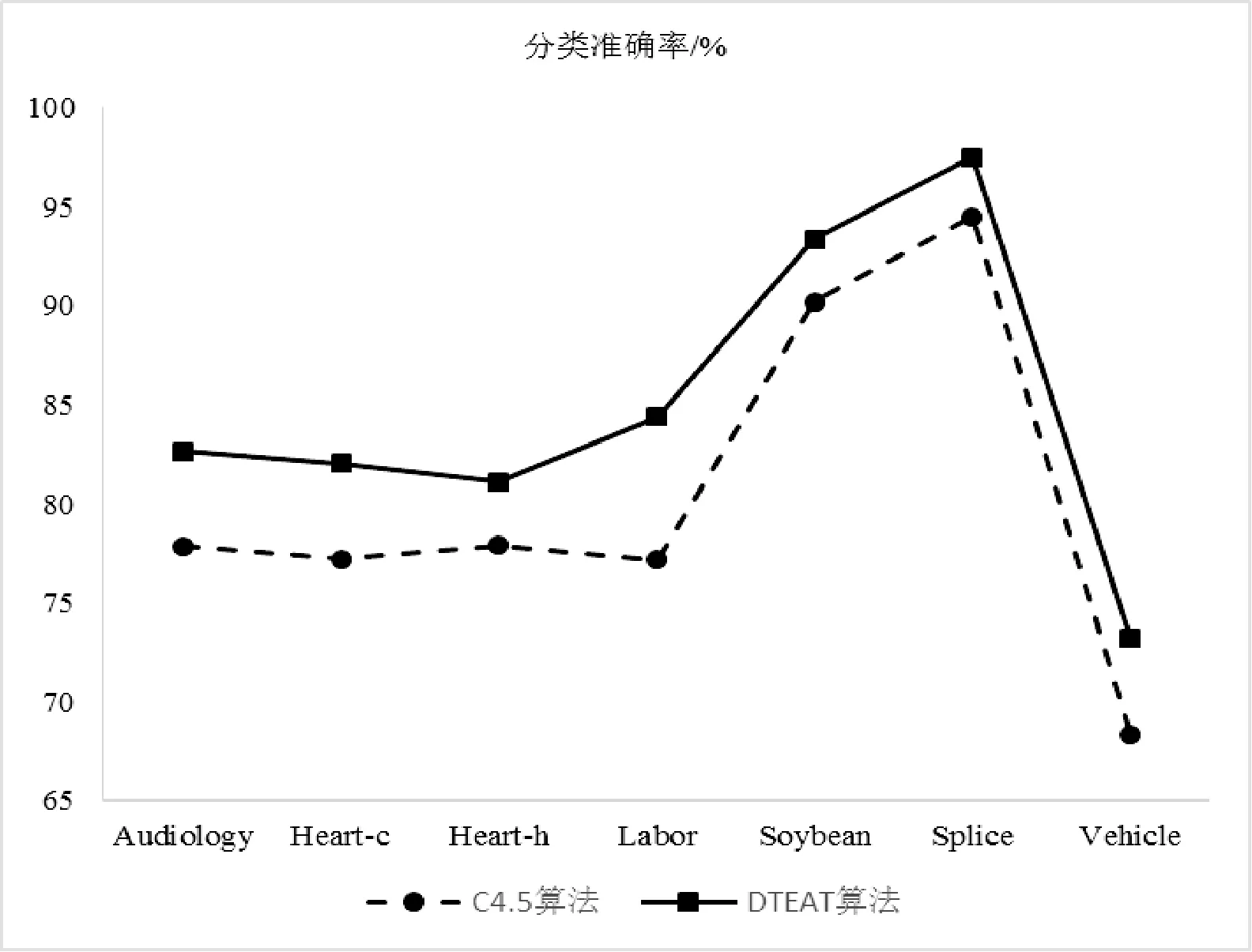
图3 C4.5算法改进前后准确率对比
根据图3的实验结果,可以看出DTEAT算法相对于C4.5算法准确率有了明显的提升,准确率最高提升了7.15个百分点,最少也提升了3.02个百分点,平均提升了4.43个百分点,即使是对于原算法准确率高达94.49%的数据集Splice仍然有3个百分点的提升。由此可知DTEAT算法通过计算属性间的信息增益率来量化属性间的依赖度。在构造决策树的过程中把待分裂属性与其他属性间的依赖度均值作为选择分裂属性时的主要度量标准之一。将属性间依赖关系对选择
分裂属性时产生的影响进行消除之后,有效地提升了分类的准确率。
4 结 语
本文是基于C4.5算法在选择分裂属性时忽视属性间的相互影响这一不足,提出了消除属性依赖的DTEAT算法。在构造决策树的过程中,通过计算待分裂属性与其他属性间的信息增益率量化属性间的依赖度,并且将属性间依赖度均值作为选择分裂属性时的主要度量标准之一。在Weka实验平台上对7组UCI官方数据集进行了实验,实验表明DTEAT算法在消除属性依赖后的分类准确率有了明显提升,即DTEAT算法减少了属性间依赖对分裂属性的选择产生的影响,从而提高了最终的分类准确率。目前,本文提出的消除属性依赖的改进算法每一次选择分裂属性时,都要多计算一次属性间的增益率,算法效率有所降低。如何在消除属性依赖提高分类准确率的同时兼顾算法的效率是需要进一步研究的问题。
[1] 周美琴.单位代价收益敏感决策树分类算法及其剪枝算法的研究[D].桂林:广西师范大学,2016.
[2] 姚亚夫,邢留涛.决策树C4.5连续属性分割阈值算法改进及其应用[J].中南大学学报(自然科学版),2011,42(12):3772-3776.
[3] Everaert G,Bennetsen E,Goethals P L M.An applicability index for reliable and applicable decision trees in water quality modelling[J].Ecological Informatics,2016,32:1-6.
[4] 徐鹏,林森.基于C4.5决策树的流量分类方法[J].软件学报,2009,20(10):2692-2704.
[5] Savall F,Faruch-Bilfeld M,Dedouit F,et al.Metric sex determination of the human coxal bone on a virtual sample using decision trees[J].Journal of Forensic Sciences,2015,60(6):1395-1400.
[6] Quinlan J R.C4.5:programs for machine learning[M].Morgan Kaufmann Publishers Inc.1993.
[7] 冯少荣.决策树算法的研究与改进[J].厦门大学学报(自然版),2007,46(4):496-500.
[8] 王伟,李磊,张志鸿.具有容噪特性的C4.5算法改进[J].计算机科学,2015,42(12):268-271.
[9] 王培,金聪,葛贺贺.面向软件缺陷预测的互信息属性选择方法[J].计算机应用,2012,32(6):1738-1740.
[10] 王凯华,蒋逸恒,李迪.基于WEKA平台的C4.5基因分类方法[J].信息化建设,2016(5):30-32.
[11] 董跃华,刘力.结合矫正函数的决策树优化算法[J].计算机应用与软件,2016,33(1):300-306.
[12] 杨青松.爬虫技术在互联网领域的应用探索[J].电脑知识与技术:学术交流,2016,12(15):62-64.
[13] 刘彩霞,方建军,刘艳霞,等.Weka平台上距离指数自动寻优的模糊C-均值聚类算法[J].北京联合大学学报,2016(4):53-57.
