基于分类树模型的高尿酸血症危险因素分析
2018-02-06胡梦妍刘锦波周春华李新莉
胡梦妍,刘锦波,周春华,李新莉
随着社会经济的发展、人民生活水平的提高、生活方式及饮食结构的改变,高尿酸血症发病率呈上升趋势[1]。长期嘌呤代谢异常可引起一系列高尿酸血症相关性疾病[2],高尿酸血症常伴有心脑血管疾病、代谢综合征等,与胰岛素抵抗密切相关[3-4]。高尿酸血症及其并发症严重影响人们的正常生活与身心健康[5],因此采取有效措施降低高尿酸血症发病率具有重要意义。
既往高尿酸血症的流行病学研究通常采用的是多元线性回归、Logistic回归或Cox回归模型进行危险因素的筛选,但这些方法对资料的类型和分布等均有较严格的限定和要求,易受到共线性问题的影响,不同程度地降低了统计分析效能。分类树模型作为一种新兴数据处理方式,可以快速、有效地识别影响疾病发生的主要因素,克服共线性问题,并通过树形图展现不同水平变量间的交互关系[6]。因此,本研究采用整群抽样方法对2012年7—11月桂林医学院附属医院体检中心的体检者进行横断面调查,包括问卷调查、身体测量、实验室检查和肝脏超声检查,并构建高尿酸血症发病风险的分类树模型,采用CRT法筛选高尿酸血症的危险因素,以便采取有效的防治措施降低高尿酸血症发病率。
本文创新点:
(1)本研究运用分类树模型CRT法筛选高尿酸血症的危险因素,以树形图的形式把结果直观地展现出来,提示具有何种特征的人群是高尿酸血症的危险人群。(2)分类树模型通过树形图提示三酰甘油(TG)分别与非酒精性脂肪性肝病(NAFLD)和体质指数(BMI)对高尿酸血症的发生影响重大。但是分类树模型的运用也存在一些局限性,当解释变量众多,自身分类也较多时,必须对过于庞大的树形图进行修剪。
1 资料与方法
1.1 一般资料 采用整群抽样方法进行横断面调查,纳入2012年7—11月在桂林医学院附属医院体检中心体检且资料完整的体检者(均为汉族)6 241例,年龄20~70岁,平均年龄(46.3±11.8)岁;其中男 3 271例、平均年龄(46.7±12.1)岁,女2 970例、平均年龄(45.8±11.4)岁。所有体检者签署知情同意书。调查当天,体检者接受问卷调查、身体测量、实验室检查和肝脏超声检查。排除标准:年龄<20岁、严重心肺脑疾病、肾功能不全、恶性肿瘤、近期服用影响嘌呤代谢的药物以及因资料不全而无法纳入分析者。本研究通过桂林医学院附属医院伦理委员会批准(YXLL-2012-11)。
1.2 方法
1.2.1 问卷调查 调查内容包括体检者的基本信息,如生活习惯、家族史、疾病史(包括高血压、高脂血症、糖尿病等)。
1.2.2 身体测量 体检者免冠、脱鞋、站直测量身高;体检者脱鞋、排空膀胱测量体质量;体检者安静休息5~10 min后坐位测量血压,连续2次测量右臂肱动脉血压,若2次测量差异大,则加测第3次,取多次结果平均值。体质指数(BMI)=体质量(kg)/身高2(m2)。
1.2.3 实验室检查 体检者隔夜禁食,次日抽取空腹静脉血,采用罗氏公司Cobas C501全自动生化分析仪检测生化指标:血尿酸(UA)、三酰甘油(TG)、总胆固醇(TC)、低密度脂蛋白胆固醇(LDL-C)、高密度脂蛋白胆固醇(HDL-C)及空腹血糖(FPG)。
1.2.4 肝脏超声检查 由专业超声医师采用迈瑞DC-6 Expert Ⅱ型彩色多普勒超声检查仪对体检者行肝脏超声检查。
1.3 质量控制 调查员均为经统一培训合格的医学专业人员;血压计和体重计均经体检中心校正;问卷调查表均由调查员详细询问体检者后填写;使用EpiData 3.02软件输入调查数据,所有数据由双人两次录入及逻辑核查,并进行核对、校正,保证数据的准确性。对现场调查问卷、采样以及数据录入等各个环节进行质量控制。
1.4 诊断标准 高尿酸血症诊断标准为正常嘌呤饮食状态下,男性空腹UA>420 μmol/L,女性空腹UA>360 μmol/L[7]。高血压诊断标准依据《中国高血压防治指南2010》[8]:在未使用抗高血压药物情况下,收缩压≥ 140 mm Hg(1 mm Hg=0.133 kPa)和 /或舒张压≥ 90 mm Hg,或既往高血压,正服用抗高血压药。非酒精性脂肪性肝病(NAFLD)诊断标准参照中华医学会肝脏病学分会脂肪肝和酒精性肝病学组相关指南[9]。
1.5 统计学方法 采用SPSS 18.0统计软件进行数据分析,符合正态分布的计量资料以(x ±s)表示,两组间比较采用成组t检验;计数资料以相对数表示,两组间比较采用χ2检验。双侧检验水准为α=0.05。
高尿酸血症的危险因素筛选采用分类树模型CRT法。分类树模型可以根据自变量对因变量进行分类和检测,常用的分类树方法有CHAID法和CRT法两种。CHAID法仅适用于分析分类变量,而CRT法可用于检测连续变量和分类变量间的相互作用,其分类树模型生长的显著性水平为P=0.05,χ2值最大且有显著性意义的因变量逐次被分类树模型检测出来,作为子节点显示于树形图的各层,分类树模型可自动识别连续变量的最佳分界点并对其进行拆分,母节点和子节点的最小样本量分别为100和50(统计软件自动设置的默认值)以限制树的生长,绘制分类树模型的ROC曲线,以ROC曲线下面积(AUC)评价分类树模型的精确性,其区间为 0.5~1.0。
2 结果
2.1 不同性别高尿酸血症患病率比较 共检出高尿酸血症患者3 271例(男755例,女280例),高尿酸血症患病率为16.6%,其中男性高尿酸血症患病率(23.1%,755/3 271)高于女性(9.4%,280/2 970),差异有统计学意义(χ2=209.782,P<0.01)。
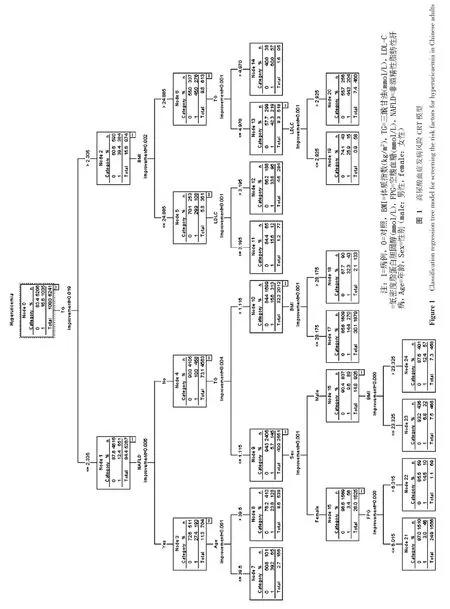
2.2 构建高尿酸血症发病风险的分类树模型 患高尿酸血症(病例)赋值为1,无高尿酸血症(对照)赋值为0,并对二分类变量(性别、高血压和NAFLD)进行赋值(见表1),其余连续变量(年龄、BMI、TG、TC、LDL-C、HDL-C、FPG)的最佳分界点由分类树模型进行识别及拆分,将所有变量选入分类树模型,根据分类树模型对根节点和子节点最低样本量,本分类树模型经过生长和修剪后共包含5层,共筛查出影响高尿酸血症的7个解释变量:年龄、性别(男性)、BMI、TG、LDL-C、FPG和NAFLD(见图1)。
分类树模型树形图结果显示,树型结构的第一层是按TG拆分的,TG是高尿酸血症最重要的危险因素,TG>2.335 mmol/L的人群高尿酸血症患病率(39.4%)高于TG≤2.335 mmol/L的人群(12.4%);BMI>24.885 kg/m2的人群高尿酸血症患病率(45.0%)高于 BMI≤ 24.885 kg/m2的人群 ( 29.9%) 。
在TG≤2.335 mmol/L的人群中,筛选出的主要危险因素为NAFLD,其中有NAFLD且年龄≤39.5岁的人群高尿酸血症患病率(39.2%)高于年龄>39.5岁的人群(23.8%);在无NAFLD人群中,TG>1.115 mmol/L、BMI>28.175 kg/m2的人群高尿酸血症患病率(32.3%)高于BMI≤28.175 kg/m2的人群(14.4%);在 TG ≤ 2.335 mmol/L的 人 群 中, 无 NAFLD, 且TG≤1.115 mmol/L的人群,筛选出的危险因素为性别,如为男性且BMI>23.325 kg/m2,则其高尿酸血症患病率(12.4%)高于BMI≤23.325 kg/m2的人群(6.8%);如为女性同时FPG>6.015 mmol/L,则其高尿酸血症患病率(14.5%)高于FPG≤6.015 mmol/L 的人群(3.0%)。
2.3 分类树模型的评价 利用该分类树模型所得预测概率绘制 ROC曲线,AUC为 0.762〔95% CI (0.751,0.772)〕,说明该分类树模型精确性较好(见图2),分界点为0.16,灵敏度为78.9% 〔95% CI(0.763, 0.814)〕,特异度为58.9% 〔95% CI(0.575,0.602)〕,约登指数为0.378。分类树模型的错分矩阵和Risk统计量见表2。Risk统计量为0.163,表示使用该模型对高尿酸血症发病风险预测的正确率为83.7%,模型拟合效果较好。
3 讨论
高尿酸血症的致病因素复杂,目前其发病机制尚未完全清楚。本研究使用分类树模型CRT法分析高尿酸血症的危险因素,分析各变量具体影响的人群、提示具有何种特征的人群更易发生高尿酸血症,对高危人群进行饮食或行为干预,对降低发病风险具有重大的公共卫生学意义。

表1 分类变量及赋值Table 1 Categorical variables and assignments

图2 分类树模型的ROC曲线Figure 2 ROC curve of classification regression tree model

表2 分类树模型错分矩阵和Risk统计量表Table 2 Classification matrix and statistical risk for assessing the accuracy of classification regression tree model in screening the risk factors for hyperuricaemia
本研究结果显示,男性高尿酸血症患病率(23.1%)高于女性(9.4%),提示性别(男性)可能为高尿酸血症的影响因素之一。
构建高尿酸血症发病风险分类树模型,共筛选出7个解释变量,分别为年龄、性别(男性)、BMI、TG、LDL-C、FPG及NAFLD,与相关研究结果相符[10]。分类树模型预测高尿酸血症的AUC为0.762,说明该分类树模型对高尿酸血症发病风险的预测效果较好。分类树模型除可以筛选危险因素外,还可以提供更科学合理的信息。在分类树模型中,目标变量是按照统计检验所得的χ2值大小依次拆分,基于统计学意义的拆分点具有科学合理性。因此,位于主要枝干的解释变量对目标变量影响较大, 随着分枝的细化影响逐渐减小,所以分类树模型可以揭示各变量对模型的重要性[11]。本研究筛选出的与高尿酸血症密切相关的主干变量包括TG、BMI、NAFLD,提示高TG 、高BMI及有NAFLD与高尿酸血症密切相关。
本研究结果提示,TG作为第一个分类节点对高尿酸血症发病风险影响最大,TG>2.335 mmol/L的人群高尿酸血症患病率(39.4%)高于TG≤2.335 mmol/L的人群(12.4%),TG>2.335 mmol/L人群是高尿酸血症高危人群。因此,重点筛查高TG人群对降低高尿酸血症发病率具有重要意义。血脂异常导致高尿酸血症的可能机制为TG升高促进游离脂肪酸生成和利用,游离脂肪酸代谢增加可加速对三磷腺苷的利用,使UA生成增加[12-14]。同时,脂代谢异常可累及入球微动脉及出球微动脉,当病变血管狭窄甚至闭塞时,肾脏清除UA减少,进一步导致UA升高[15]。
其次在分类树模型中,BMI、NAFLD为第2层分支变量,其中BMI在第2层、第3层和第4层共出现3次,提示BMI、NAFLD与高尿酸血症关系较为密切。在第2层中,BMI拆分点为24.885 kg/m2,与我国超重或肥胖的标准基本相符[16],但该拆分点的确定是基于显著的统计学意义,不是凭借临床实践或个人经验,因此较人为设定的拆分点更为合理。结果表明高尿酸血症患病率在超重或肥胖人群中显著升高,这与其他相关研究结果一致[17]。因此对超重或肥胖人群应注意检测UA,及早发现有无高尿酸血症。
另外,NAFLD作为分支变量出现在分类树模型中的第2层,在TG≤2.335 mmol/L的人群中,筛选出的主要危险因素为NAFLD,其中有NAFLD的人群高尿酸血症患病率(27.4%)显著高于无NAFLD的人群(10.0%),提示NAFLD在高尿酸血症中的重要性。高尿酸血症和NAFLD同属代谢综合征(MS),其中心环节为胰岛素抵抗,胰岛素抵抗可以激活肾素-血管紧张素系统,一方面血管紧张素Ⅱ可以减少肾血流量,使UA排泄减少,另一方面通过加重氧化应激反应,促进UA合成。因此,应高度重视超重或肥胖及NAFLD人群有无高尿酸血症,同时改善其生活方式和膳食结构、严格控制体质量、积极改善肝脏胰岛素抵抗进而治疗NAFLD ,这对预防高尿酸血症意义重大。
分类树模型除了可以快速、有效地识别影响疾病发生的主要因素外,还可通过树形图展现不同水平变量间的关系。本研究结果显示,在TG>2.335 mmol/L的人群中,BMI>24.885 kg/m2的人群高尿酸血症患病率(45.0%)显著高于BMI≤24.885 kg/m2的人群(29.9%)。另外分类树模型中各层的分支变量基本为TG和BMI,提示TG和BMI作为主要候选变量,其与高尿酸血症关系密切。因此,对于肥胖人群,除需要控制体质量外,还需特别注意控制血脂水平,从而降低高尿酸血症发病率。
目前分类树模型正逐步成为分析复杂多因子疾病的有力工具[18],特别是对大样本量的病因研究。本研究样本量较大,适合应用分类树模型进行研究。
综上所述,年龄、性别(男性)、BMI、TG、LDL-C、FPG及NAFLD是高尿酸血症的危险因素,其中TG、BMI、NAFLD 是高尿酸血症主要的危险因素。应该提倡科学的生活方式,积极控制体质量、血脂、血糖,治疗NAFLD,进而降低高尿酸血症发病率,这对于降低高尿酸血症人群心脑血管疾病风险具有重要意义。
志谢:感谢桂林医学院附属医院体检中心提供数据及全体医护人员对本研究的大力支持。
作者贡献:胡梦妍进行研究设计、数据统计分析、撰写论文并对文章负责;刘锦波、周春华负责研究实施、资料收集整理;李新莉进行质量控制及审校。
本文无利益冲突。
本文不足:
(1)研究对象来源于中国桂林,存在选择偏倚。(2)影响高尿酸血症的因素还有许多,如种族、饮食习惯、生活方式、遗传及基因多态性等,上述因素与高尿酸血症的关系仍需进一步深入研究。
