基于聚类分析的协同过滤算法研究
2018-01-11颜颖
颜 颖
基于聚类分析的协同过滤算法研究
颜 颖
(福建水利电力职业技术学院,福建永安 366000)
电子商务推荐系统凭借着“智能感知”用户的兴趣和需求的能力,实现个性化商品推荐。传统算法以协同过滤作为主要技术手段实现个性化推荐功能,但是随着电商业务的发展,数据稀疏性和推荐的实时性倍受挑战。据此,结合聚类分析的优点,改进传统算法,提出一种聚类分析与协同过滤相结合的推荐算法。实验表明,改进后的算法具有较好的推荐准确性。
协同过滤;聚类;个性化推荐
推荐系统早就应用于电子商务领域,并获得了良好的发展。该系统是建立在海量数据挖掘基础上的一种高级智能技术,通过收集客户和商品信息及消费记录,研究兴趣需求,进行个性化推荐计算,从而将其感兴趣的产品推荐给目标用户。部分的电商平台、网站都提供了相应的推荐服务来引导用户进行购物。该推荐系统研究的关键是如何提高推荐算法的质量和效率,因此推荐算法是整个推荐系统的主体部分,推荐算法的优劣决定着推荐系统的性能。
1 相关算法介绍
目前在电子商务推荐系统中使用的推荐算法有:Bayesian网络、关联规则、聚类分析、Horting图、协同过滤推荐算法等。目前,商家应用较多、较为著名的一种推荐技术是协同过滤(Collaborative Filtering)。
1.1 协同过滤推荐算法介绍
协同过滤推荐算法是基于兴趣爱好相似的用户可能具有相似的购物行为的原理。它的实现过程是通过对用户历史行为数据的挖掘发现用户的偏好,在海量数据中挖掘出与目标用户品位最为相近的k个“邻居”,然后分析这些“邻居”的兴趣偏好,利用公式预测某些未浏览项目的评分值,从而形成关于该指定用户的喜好预测,并为其推荐喜好评分排序在前的N件商品。
协同过滤的实现过程主要要经过以下三个步骤:获取用户信息、选择近邻和预测推荐。
1.1.1 获取用户信息
在电子商务网站上,用户信息的来源有多种,每天服务器、代理服务器以及客户终端就会生成日志文件和Cookies,这些日志文件和Cookies记录了用户浏览电子商务网站的来源网站、对每个页面的访问次数、对某种商品单击的次数以及放入购物车的物品名称和数量等信息,从而搜集到用户的浏览行为与习惯。
通过获取的用户评价信息得到“用户——项目评分矩阵Rmxn(UI)”,如表1所示。在该矩阵中行表示用户,列表示商品即项目,元素rij表示用户Ui对项目Ij的评分值,一般用[1,5]的数值表示,分数越高则表示越喜欢这个项目。

表1 用户——项目评分矩阵表
1.1.2 寻找近邻
近邻是指与目标用户偏好最为接近的用户,协同过滤推荐的关键步骤在于准确定位目标用户的最近邻居集SNIu。确定近邻的基础思路是:依据公式计算目标用户u与数据库中其他所有用户v间的相似度sim(u,v),根据计算的 sim(u,v)值,选择值最大的前 k个的用户作为最近邻居集SNIu。因此相似性的准确与否对推荐精度有着关键性的影响。实验表明,皮尔逊相关系数能更好地衡量用户间的相似程度,相关系数越高,则两者的相似性越大;反之,则相似性越小。因此本文也采用皮尔逊系数进行实验对比分析。其计算公式如下:
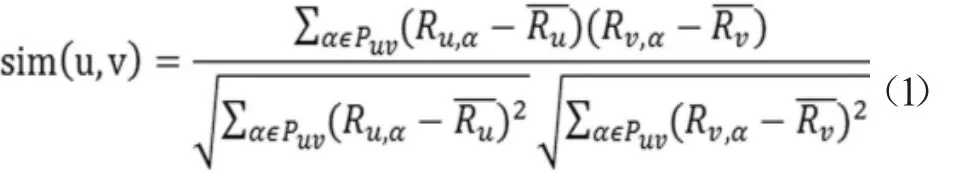
其中,PUV表示评分项目集合,Ru,α和Rv,α表示对商品项目α的评分,R表示平均分。
1.1.3 预测推荐
依据之前找到的目标用户u的最近邻居集SNIu,实现智能推荐功能。利用近邻v对项目i的历史评分值,预测目标用户u对该项目的评分值,其计算公式如下:

根据计算结果Pu,i的高低,选择评分值最高的前N项(top—N)商品作为结果向客户进行推荐。
相比于其他的推荐算法,传统的协同过滤算法考虑了历史行为数据,推荐过程是完全自动的,并且对推荐对象没有特殊要求,尤其是一些难以进行内容分析的抽象项目也能够实现推荐。但它过于依赖相似度的计算准确性,数据稀疏性和系统可扩展性仍然是它所面临的挑战。
1.2 聚类分析
聚类分析是基于“物以类聚”的原理,按照某种属性或规律(例如欧几里德距离)将一组个体划分成相对同质的群组(也就是簇)的统计分析技术。同一个簇内的对象具有较高的同质性,而不同簇间的对象有很大的异质性。因此同一簇中的元素可以互为近邻。其目标是在相似的基础上将数据划分到不同的类,聚类的结果使得同一类中的对象相似性尽可能大,而不同类间的对象相似性最小。因此通过聚类分析,可以区分具有不同特征的客户群,并且通过购买模式刻画不同的客户群的特征,并概括出每类群体的消费模式即消费习惯,进而为各个群体提供可行的营销方案与可靠依据。通过聚类,人们能够识别数据对象密集的和稀疏的区域,因而发现全局的对象分布模式,以及数据属性之间的相互关系。聚类基本操作步骤:
1)计算n个样品两两间的距离,得到样品间的距离矩阵;
2)初始n个样品各自看成一类,共有n类,此时类间的距离就是样品间的距离;
3)将类间距离最小的两类进行并类,其余不变,这时类的个数减少一个,即得到n-1类;
4)按照之前的计算方法,计算新类与其它各类之间的距离,再将关系最为密切的两类合并为一类,其余不变,即得到n-2类,如此下去直到最后所有的样品都归为一类为止;
5)画谱系聚类图;
6)决定分类的个数和各类的成员。
聚类算法的复杂度较低,因为基于聚类的推荐不是在数据库中搜索所有用户集和目标用户进行相似性比较,而是在相对小的范围内,只在包含有目标用户的簇中进行相似性计算,减少了异类数据间的相似性计算,提高了推荐速度。但是使用聚类分析时,用户只能属于一个单独的类别,不符合用户多兴趣的特点。另外当用户处于一个聚类的边缘时,推荐质量也比较低。聚类推荐将同一簇中的用户平等看待,但事实是簇中的用户间的距离是不同的。
2 问题陈述
协同过滤算法被应用在电子商务推荐系统中,但是随着电商业务的发展,网络平台上参与交易的用户和商品项数量较多,传统协同过滤算法的缺点开始显现出来,推荐质量落后于用户和商家的期望。
在协同过滤算法计算过程中,利用公式(1)求得两两间的相似性问题来寻找邻居,计算量会随着用户和商品的增加而呈线性增长。该算法理论上能为几千名用户提供较好的推荐服务,但是如今网络中用户数或商品数量通常都较大,在用户——项目评分矩阵中,用户U和项目I的维数都较大,海量用户数据模型势必对系统造成性能压力,给传统的推荐系统增加负担,无法满足存储空间的要求,传统的协同过滤算法的性能就开始急剧下降,很难满足用户实时性的推荐要求,面临着可扩展问题。
另一方面,在相似度计算公式(1)中,需要用到两个用户对共同的项目集合进行评分,但是我们知道,在网站中商品项目较多,用户的历史记录数据占整个商品集较小的一部分。因此在用户——项目评分矩阵中,每行用户只对较少的项目作出评分,这就面临着数据稀疏性问题。数据稀疏性导致两个用户共同评价的项目数量较少,因此利用公式(1)寻找最近邻居时,一方面会造成信息的丢失,另一方面计算时会耗费很大,使得推荐效果大打折扣。
以上两点正是传统的基于协同过滤技术在实际中所面临的挑战。任何单种的推荐方法总有它自身的优缺点,聚类分析过程是将目标用户的最近邻搜索空间局限在某一个簇中,对数据源进行“瘦身”,有效的减少了搜索空间,因此在扩展性和实现性能上比传统的协同过滤技术略显优势。
3 算法改进
单一推荐算法各有优劣,为了弥补协同过滤推荐算法所面临的可扩展性和数据稀疏性方面的缺陷,本文综合传统的协同过滤和聚类分析技术优点,提出了一种将聚类分析与协同过滤相结合的推荐算法,希望能够提升商品的推荐质量,从而达到扬长避短的目的。
改进后算法的基本思路:事先给定一个包含有n个样本对象的数据库,和要划分的簇的数目k(k<=n)。首先使用聚类算法对数据对象进行预处理,把项目划分到k个簇里面。项目分类后,选择该用户的兴趣簇作为数据源进行推荐计算。在这个兴趣簇中建立用户——项目评分矩阵。使用基于项目的协同过滤算法预测未评价项目的评分值,填充至用户——项目评分矩阵,获得密度更高的新的用户——项目评分矩阵。使用基于用户的协同过滤算法计算目标项的预测值,选取预测值排名前N项进行推荐。改进后的算法一方面有效解决了算法的可扩展性问题,又满足用户只对某几类商品感兴趣的特性。以下为算法的具体实现步骤:
3.1 数据预处理
该阶段主要针对初始的用户信息,对用户——项目评分矩阵里的所有项目进行聚类操作,原先的用户——项目评分矩阵被划分为几个子矩阵。
1)从初始数据中,获取n个项目集合;
2)从n个项目中任意选取k个项目作为聚类中心,执行聚类操作步骤中的3)和4)操作,最终确定每个聚类包含的对象。
3.2 降低数据稀疏性
上一步骤获取的子矩阵比较稀疏,针对数据稀疏问题,可以利用基于项目的协同过滤算法,对用户未评价项目进行预测评分,将预测结果填充进之前的子矩阵中,从而生成较为稠密的用户——项目评分矩阵。此过程的计算量比较小,可以获取较好的性能。
1)计算与目标项目相似度最高的前N项作为邻居;
2)根据相邻项的评分值,使用预测值公式计算未评价项的预测值,选取预测值最大的前N个预测值作为推荐评价集合;
3)将多个推荐评价集合进行合并,从这些推荐评价集合中选取前N个预测值组成最终推荐评价集合;
4)把推荐评价集合里的预测值填入该用户——项目评分矩阵中,形成新的较为稠密的用户——项目评分矩阵。
3.3 产生推荐
通过降低数据稀疏性处理可以获得较为稠密的用户——项目评分矩阵,使用基于用户的协同过滤算法,计算未评价项目的预测值。对预测值进行降序排列,选取前N项进行推荐。
1)找出目标用户a所在的用户——项目评分矩阵,对在该矩阵中目标用户a未评分过的项目j,采用预测值公式计算预测值Paj;
2)如果项目j属于多个类别则选取Paj=max(Paj1,Paj2,···,Pajk);
3)对每一类别的Paj值进行计算后降序排列,选取Paj最高的前N个项目作为top-N推荐集推荐给用户。
4 实验结果及分析
4.1 实验数据选取
本文采用GroupLens项目组提供的电源评价数据集作为本次实验数据。数据集中数据的分布情况如表2所示。该数据集包含了随机挑选了600个用户对1600部电影的7万条评价数据。这些评价以5分制为基准,即每部电影的评分范围为0—5分。将获取的这些评分数据转换成用户——项目评分矩阵,该评分矩阵密度为7.3%,是典型的稀疏矩阵。

表2 数据集中数据分布情况表
4.2 评价准则
平均绝对偏差(MAE)值用来反映推荐系统计算出的预测评分值与用户对该项目的实际评分值之间的平均偏差,常常用于刻画推荐系统的准确性,是较常用的度量推荐质量的方法之一。本文选取MAE指标作为度量本次实验输出结果优劣的标准。MAE值越小,说明对用户评分的预测更精确,推荐质量也相应越好。假设用户 i的预测评分集为{P1,P2,…PN},用户 i的实际评分集为{q1,q2,…qN},则 MAE 的计算公式如下:

4.3 实验结果分析
在本次实验中,我们设定用户聚类数k=12,推荐集合N=19,邻居集数量从10取到50,为了验证改进算法的有效性,分别采用传统的算法和改进后的算法进行实验,用MAE指标来评价算法的推荐准确性。测试结果如表3所示,两种算法在MAE指标中的比较情况如图1所示。
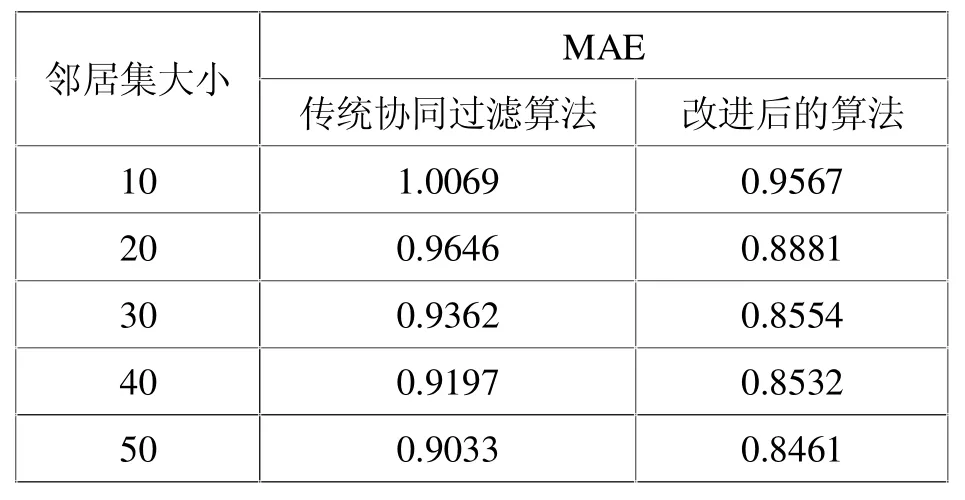
表3 最近邻居集大小不同所得的测试数据表

图1 两种算法在MAE指标中的比较情况示意图
通过上述的对比实验可以看出,在邻居集大小变化的情况下,改进后的MAE值整体小于传统算法的值,这说明改进后算法的推荐准确率优于传统协同过滤算法,并且改进后的算法受邻居集数量的影响稍大一些。但是不管采用哪种算法,MAE的值都随着邻居集数量的增加而逐渐减小,并且变化值会不断趋于平缓,也就是推荐的准确性也就越高。
5 结语
任何单一的推荐算法总有它的优缺点,为了弥补单个算法的缺陷,一些学者将多种算法或推荐系统整合起来。本文在前人研究的基础上,结合协同过滤推荐技术和聚类分析技术的优势,改进传统算法。实验对照发现,对传统算法加以改进,推荐质量能获得显著的提高,一定程度上减少了数据稀疏性和可扩展性方面的弱点,达到较好的预期目的。但是在数据冷启动等方面仍然存在问题,有待进一步解决。
[1]何安.协同过滤技术在电子商务推荐系统中的应用研究[D].杭州:浙江大学,2007.
[2]杨芳.电子商务系统协同过滤推荐算法研究[D].天津:河北工业大学,2006.
[3]李聪.电子商务协同过滤可扩展性研究综述[J].现代图书情报技术,2010(11):37-44.
[4]邢琼香.基于信任的协同过滤算法在电子商务推荐系统中的研究[D].南昌:南昌大学,2014.
[5]李容.协同过滤推荐系统中稀疏性数据的算法研究[D].成都:电子科技大学,2016.
[6]王晓耘,钱璐,黄时友.基于粗糙用户聚类的协同过滤推荐模型[J].现代图书情报技术,2015(1):45-51.
[7]李清霞,魏文红,蔡昭权.混合用户和项目协同过滤的电子商务个性化推荐算法[J].中山大学学报(自然科学版),2016(5):37-42.
Research on coordination filtering algorithm based on clustering analysis
YANYing
(Fujian College ofWater Conservancyand Electric Power,Yongan,Fujian,China 366000)
The E-commerce personalized recommendation system relies on the ability of intellisense about the users'interest and demand to realize personalized commodity recommendation.The traditional algorithm takes coordination filtration as the main technical method to realize the personalized recommendation function.But with the development of E-commerce,data sparsity and recommendation timeliness are challenged.With the advantages of cluster analysis,the traditional algorithm is improved and a recommendation algorithm is put forward which combines cluster analysis with coordination filtration.The experiment shows that the improved algorithmhas a good recommendation accuracy.
coordination filtration;cluster;personalized recommendation
10.3969/j.issn.2095-7661.2017.04.013】
TP391.3;F713.36
A
2095-7661(2017)04-0040-04
2017-08-06
颜颖(1982-),女,福建永安人,福建水利电力职业技术学院实验师,硕士,研究方向:电子商务实践教学。
2016年福建省中青年教师教育科研项目(科技类)阶段成果(项目编号:JAT160777)。
