决策树和贝叶斯分类算法在学生专业录取数据中的应用研究
2017-12-12黄雪华
黄雪华
决策树和贝叶斯分类算法在学生专业录取数据中的应用研究
黄雪华
(湖南城市学院信息与电子工程学院,湖南 益阳 413000)
分类算法是数据挖掘中最重要的挖掘理论之一,广泛应用于天气预测、反垃圾邮件、疾病诊断等应用中﹒通过介绍应用最广泛的两类分类算法决策树和贝叶斯理论及算法,并应用于湖南城市学院专业招生录取数据中,结合SQL server及ASP.NET,获取每个专业的学生性别预测,获取每个专业生源省份预测,并对预测结果和实际结果进行比较,得到误差率分别在0.01和0.2以内﹒
分类;决策树;朴素贝叶斯;ASP.NET;SQL Server2014;专业录取
分类算法是预测离散数据的分类标号﹒最著名的例子如韩家炜的AllElectronics邮寄清单数据库[1],根据顾客姓名、年龄、收入、职业和信誉度,可对他们是否购买计算机建立分类模型,并预测未知顾客所属分类;再如银行中预测贷款是否存在风险,客户信用卡等级划分,这样可以降低银行信贷的风险,减少资金的流失;又如文本分类、网络异常检测、垃圾短信过滤等应用﹒
1 决策树相关理论及算法分析
1.1 决策树定义
从数据结构来看,决策树是一颗倒立的树﹒从树的根节点到叶节点的路径实际就是决策的过程,确定数据样本所属类标号的过程,它是一个递归地从上到下确定分支节点和叶节点的过程﹒叶节点存放的是数据样本所属的类标号;分支节点根据数据样本的某个合适的属性值进行数据集划分﹒
1.2 决策树构造步骤
决策树的构造分为2个步骤:第1步是建立决策树阶段,通过样本数据建立决策树;第2步是树剪枝阶段,对决策树减去不必要的分枝以及过度拟合,主要是处理噪声数据和异常数据﹒
1.3 决策树算法分析
决策树算法有很多种,最为著名的有ID3[1],C4.5[2]﹒决策树建立的差异主要在属性值的选取上﹒ID3的分支节点属性选择是通过计算属性的信息增益值来选择的﹒C4.5算法是对ID3算法的改进﹒ID3算法只能针对离散数据进行样本分类,C4.5扩充了连续数据的分类方法﹒
设是个数据样本的集合,假定类标号属性具有个不同值,定义个不同类C(=1,…,),又设S是类C中的样本数,样本分类期望信息为

P是任意样本属于类C的概率,用S/估计﹒设属性A具有个不同值{1,…,a},属性A将样本划分为个子集{1,…,S},S是子集S中类C的样本数﹒根据A划分子集的熵由式(2)和式(3)给出﹒


然后计算每个属性的信息增益,在属性A上的信息增益为Gain(A)=(S,…,S)-(A),以具有最高信息增益值的属性作为划分属性,并为每个值创建分支且迭代划分样本﹒
2 贝叶斯定义及算法理论
2.1 贝叶斯定义
贝叶斯分类方法是另外一种著名的分类算法,它主要是根据后验概率来预测数据所属的最有可能的分类﹒
2.2 朴素贝叶斯概念
贝叶斯分类算法有多种,其中比较著名的是朴素贝叶斯分类,它假定每个属性值对分类的影响是相互独立的﹒
2.3 贝叶斯算法[3-5]
假设A1,A2,…,A是数据集的个属性,C,C,…,C是数据集的个分类,={1,2,…,x}是一个具体的样本对象,这个样本对象属于类C的概率可以利用贝叶斯公式(见式(4))计算出来﹒
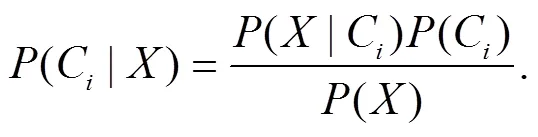
当(C|)大于(C|)时,认为该样本对象属于类C,因此需要求出最大的(C|)值,而对于所有分类,样本的概率()可以视为常数﹒因此只需(|C)(C)最大,如果类的先验概率未知,则通常假定(1)=(2)=…=(C),否则按(C)=S/计算,其中S是属于类C中的训练样本数,是训练样本总数,且假定各属性之间是相互条件独立的,则可得

对于每个类C,只需求出最大的(|C)(C)值,则样本属于该类﹒
3 算法应用
3.1 学生专业录取数据说明
我校的招生录取数据,共15 734条数据,原始数据分散在4张EXCEL表中,包含2013年、2014年、2015年、2016年的新生录取情况,由考生号ksh、学生姓名xm、性别xb、录取专业lqzy、高考分数grade、投档线pass grade及省份sf构成﹒部分录取原始数据样本见表1﹒

表1 学生专业录取原始数据
对这15 000多条数据进行处理,把4张EXCEL表导入到SQL Server中的表kaoshengdata中,并增加id字段,增加录取年份start year属性字段,增加考生分数与投档线分数差differ score字段﹒通过T-SQL编程,编写触发器等方法对数据进行处理,处理之后的部分源数据见表2﹒
3.2 决策树算法应用
在学校里,男女性别人数差异的问题可能会造成很多其他的问题,如宿舍分配、洗澡堂、卫生间等与性别相关的公共设施都将产生影响﹒采用决策树算法对每个专业学生性别的情况进行预测,学生的性别取值只有男和女两个值﹒因此可看做0和1的分类问题﹒在该考生的录取数据中,与学生的性别相关的属性主要是专业,专业本身的属性将会对学生所属学科及兴趣爱好有一定影响,而学生的分数、学生的考生号、投档线、考生所来自的省份都与性别无关联﹒因此对该数据建立决策树模型﹒根据样本集建立分类模型,再对测试数据进行预测其所属的性别标号﹒

表2 学生专业录取处理后的数据
在ASP.NET所编写的客户端应用程序中,根据所选择的专业,可以分析出该学生可能的性别及相应的概率﹒图1挖掘结果显示我校经济统计学专业的学生大部分是女生,是女生的概率为67.9%﹒对该预测结果进行验证,经济统计学专业录取的女生有30人,而该专业的总人数为50人,女生占比为34/50(0.68),预测值与实际值相差约为0.01;同样地对城乡规划专业进行预测,为女生的概率为51.2%,该专业总人数为281人,女生为144人,占比为51.2%﹒可见采用决策树预测算法对性别的预测准确率非常高﹒

图1 决策树数据挖掘结果
该预测涉及到的DMX语句如下:
select kaoshengdata.xb,predictprobability(xb) as [probability] from kaoshengdata natural prediction join (select '" + profession + "' as lqzy)as t
其中profession是要预测考生所属的专业﹒
ASP.NET中的C#语言通过连接字符串"Provider=MSOLAP.3;Integrated Security=SSPI;Persist Security Info=True;Initial Catalog=kaosheng;Data Source=."与SSAS建立连接,并显示出预测结果﹒
利用决策树算法预测专业的性别结果数据见表3(由于篇幅原因只给出一部分专业数据)﹒表3给出了每个专业学生性别的预测和实际结果,还给出了预测结果与实际结果的误差率,并得出其误差率在0.01以内,预测结果准确率非常高﹒

表3 决策树算法性别预测结果
3.3 贝叶斯算法应用
预测专业招生学生中最可能来自的省份,据此可制定相应高校招生策略,增加或减少该专业在该省的招生人数,如果在该专业中没有或很少的学生属于该省,那么可以减少在该省招生人数,否则增加招生人数﹒根据考生的属性专业、年份、分数,对考生所来自的省份进行预测﹒由于各属性之间对类别所属省份的影响是相互独立的,因此对考生数据建立朴素贝叶斯分类模型,并对测试数据进行预测﹒建立的贝叶斯模型见图2﹒
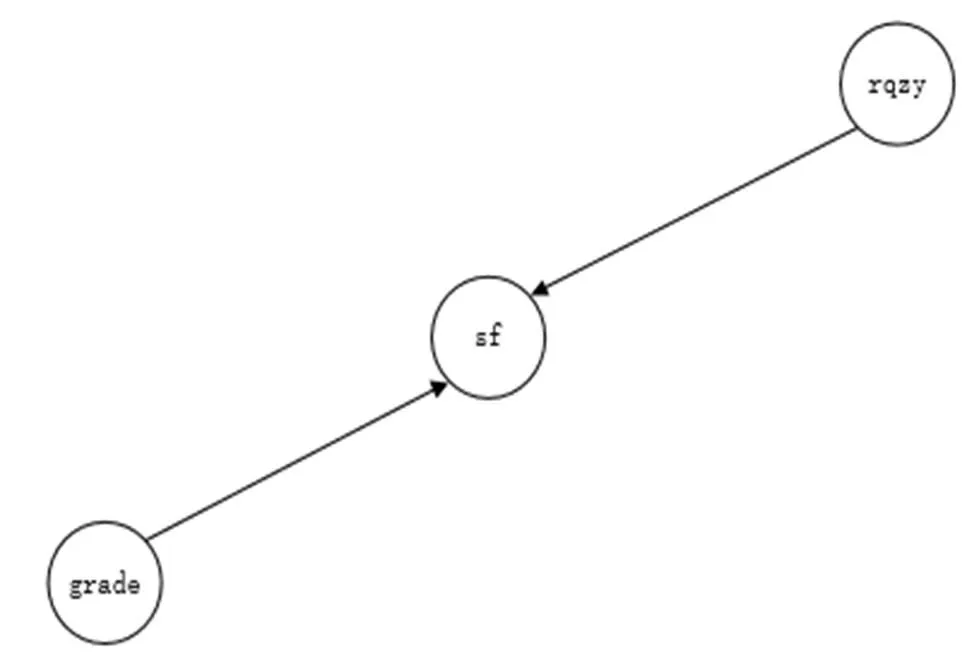
图2 贝叶斯模型
根据输入学生专业、录取年份及高考分数预测该专业录取的学生来自的省份及可能的概率﹒
该预测涉及到的DMX语句如下:
select kaoshengdata2.sf,predictprobability(sf) as [probability] from kaoshengdata2 natural prediction join (select '"+profession +"' as lqzy,'"+startyear1 +"' as startyear,'"+grade1 +"' as grade)as t
其中profession为学生的录取专业,变量startyear1为考生的录取年份,变量grade1为考生的高考成绩,预测结果见图3﹒2016年城乡规划专业的学生,最可能来自的省份为湖南省,其概率为55.3%﹒而在原始数据中城乡规划专业在2016年总共招收了81人,其中湖南的学生有54人;同年电子科学与技术专业总共招收了74人,来自湖南的58人,与预测的84%的电子科学与技术专业的学生来自湖南情况相吻合﹒
利用贝叶斯算法预测每个专业每年所来自的省份结果数据见表4(因篇幅原因只给出2016年部分专业生源数据)﹒表4给出了部分专业学生所来自省份的预测结果和实际结果,并得出其预测误差率在0.2以内,具有比较高的准确率﹒

图3 贝叶斯数据挖掘结果

表4 贝叶斯算法生源预测结果
4 总结
本文研究了决策树分类和贝叶斯分类的相关理论,包括其定义、相关概念及算法,用SQL Server2014为湖南城市学院学生专业录取数据建立模型并进行挖掘分析,采用DMX语句获取挖掘结果,为学校专业招生制定相应决策提供了数据支持,通过C#语言并采用ADOMD.NET对挖掘结果进行访问,最终把预测的结果显示在网页中﹒本文采用决策树分类算法对所录取的学生进行性别预测,预测值与实际结果的误差率大小在0.01以内;采用贝叶斯算法对所录取的学生可能来自的省份进行预测,预测值与实际结果的误差率大小在0.2以内﹒两者都具有较高的准确率﹒
[1]HAN J W, KAMBER M, PEI J, 等. 数据挖掘概念与技术[M]. 北京: 机械工业出版社, 2012.
[2]程斐斐, 王子牛, 侯立铎. 决策树算法在Weka平台上的数据挖掘应用[J]. 微型电脑应用, 2015, 31(6): 63-65.
[3]张轮, 杨文臣, 刘拓, 等. 基于朴素贝叶斯分类的高速公路交通事件检测[J]. 同济大学学报: 自然科学版, 2014, 42(4): 558-563.
[4]杨雷, 曹翠玲, 孙建国, 等. 改进的朴素贝叶斯算法在垃圾邮件过滤中的研究[J]. 通信学报, 2017, 38(4): 140-148.
[5]吕昊, 林君, 曾晓献. 改进朴素贝叶斯分类算法的研究与应用[J]. 湖南大学学报: 自然科学版, 2012, 39(12): 56-61.
(责任编校:龚伦峰)
Application of Decision Tree and Bayes Classification Algorithm in Student Enrollment Data
HUANG Xuehua
(School of Information and Electronic Engineer, Hunan City University, Yiyang, Hunan 413000, China)
Classification algorithm is one of the most important mining theories in data mining. It is widely used in weather forecasting, anti spam, disease diagnosis and other applications. The theory and algorithm of the most widely used decision tree and Bayes are introduced, and applied to student enrollment data of Hunan City University combining with SQL server and ASP.NET to get gender prediction for each major and predict the province students are from. Compare the predicted results with the actual results, it is found that the error rates are within 0.01 and 0.2 respectively.
classification; decision tree; naive Bayes; ASP.NET; SQL Server2014; student enrollment
TP301.6
A
10.3969/j.issn.1672-7304.2017.04.0014
1672–7304(2017)04–0064–04
2017-06-25
黄雪华(1983- ),女,湖南郴州人,讲师,硕士,主要从事数据库、数据挖掘研究﹒E-mail: 107531852@qq.com
