面向向量相似度计算的集群系统的研究
2017-12-01张禹尧毛腾李俊蒋玉茹北京信息科技大学计算机学院
张禹尧 毛腾 李俊 蒋玉茹 北京信息科技大学计算机学院
面向向量相似度计算的集群系统的研究
张禹尧 毛腾 李俊 蒋玉茹 北京信息科技大学计算机学院
在大数据时代,基于文本向量空间的分类、聚类、排序与相关性反馈都需要计算向量相似度。本文提供一种针对大规模向量相似度计算的方法。在该方法中,尝试利用Jetson TK1开发板构建了一个基于ARM的Hadoop完全分布式集群,并利用CUDA对单一结点进行提速,最终求得与目标词向量最相似的TopN。本文通过实验验证了该方法的有效性。
向量相似度 ARM集群 Hadoop CUDA
向量相似度,顾名思义是两个用向量表示的对象之间的相似程度,常用的向量相似度计算方案有内积、Dice系数、Jaccard系数和余弦系数。
随着计算机软件和硬件的发展,数据处理的量越来越大,数据的结构越来越复杂,越来越多的计算模型采用向量模型将非结构化数据转换成计算机能够处理的数据。由此,我们将能够计算个体间的差异,进而评价个体的相似度和分类。在实际运用中,我们可以将一个人的数据表示为具有身高、年龄、ID号等的向量。在处理文本内容时,我们也可将其转化为向量空间中的向量运算,并且用空间上的相似度表达语义的相似度。
本篇论文提出了一种对大规模向量相似度计算的方法,即利用基于ARM集群系统的GPU和Map/Reduce方法处理大规模向量相似度,并以计算词向量的相似度为例详细说明该方法的工作过程。
1 研究背景与潜在应用
在大数据时代,用向量模型表示的数据不仅数据量大,而且向量维度也在增加,相似度的计算变成了需要庞大的计算量的问题。高处理速度已经成为不可或缺的要求,而大数据处理平台(例如:Hadoop)的出现能够帮助解决这个问题。研究如何提高大规模处理数据的效率是非常有价值的。
2 研究内容
2.1 词向量
词向量是将语言中的词进行数学化的一种方式,也就是将词转为计算机能够理解的语言,是语义理解的基础。
本篇论文中采用的词向量方式是:深度学习中用到的分布式表示方法,其基本思想是:
通过训练将某种语言中的每个词映射成一个固定长度的向量,将所有这些向量放在一起形成一个词向量空间,而每一词向量则为该空间中的一个点,在这个空间上引入“距离”,则可以根据词之间的距离来判断它们之间的(词法、语义上的)相似性。
本篇论文中采用夹角余弦法来衡量向量的距离。两个词相关或者相似,在词向量距离上会更接近。词汇相似度识别便是建立在词向量基础之上的数据计算。用此法表示向量,如:“金鱼”和“鲤鱼”的距离会远远小于“金鱼”和“草地”。
词义相似度计算在各领域中都有广泛的应用,例如信息检索、信息抽取、文本分类、词义排歧、机器翻译等等。由于词的数目众多;存储词向量的文件较大;另一方面词向量相似度的计算可以拆分成多个并行的任务;目标词向量与其他词向量相似度的计算是大规模重复性计算(计算方法一致),因而可以采用Hadoop完全分布式集群和CUDA方法来处理词汇相似度计算问题。
2.2 Hadoop
Hadoop是提供以分布式方式存储和处理大数据的标准平台之一,是Apache的一个用Java语言实现的开源软件框架。Hadoop基于两个核心概念:Hadoop分布式文件系统(HDFS)和分布式处理框架Map/Reduce。HDFS以分布式方式处理文件的存储,Map/Reduce是分布式运行在Hadoop集群上的程序。目前,Hadoop已经被Yahoo,Facebook和其他大公司使用。
HDFS在两种类型节点的帮助下工作,Namenode和Datanode。Namenode是集群中存储集群上所有文件的详细信息的节点,包括整个文件系统的名字空间和文件数据块映射(Blockmap)的映像信息和对文件系统元数据产生修改的操作信息。Hadoop客户端通过与此节点进行会话,从数据节点读取和写入。Datanode实际上存储文件的一部分,它将HDFS数据以文件的形式存储在本地的文件系统中。
通常,Map/Reduce框架和HDFS是运行在一组相同的节点上的,即计算节点和存储节点通常在一起。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使整个集群的网络带宽被高效地利用。
Map/Reduce就是“任务的分解与结果的汇总”。在运行一个Map/Reduce计算任务时候,任务过程被分为两个阶段:Map阶段和Reduce阶段,每个阶段都是用键值对<key,value>作为输入(input)和输出(output)。而要做的就是定义好这两个阶段的函数:Map函数和Reduce函数。
Map函数:接受一个键值对(key-value pair),产生一组中间键值对。Map/Reduce框架会将map函数产生的中间键值对里键相同的值传递给一个Reduce函数。
Reduce函数:接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)。
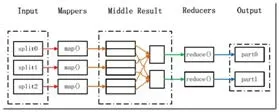
图1 Map/Reduce处理大数据集的过程Fig.1 The process of processing large data sets using Map/Reduce
用Map/Reduce来处理的数据集必须具备这样的特点:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。而向量相似度的计算符合这一特点,因此本篇论文利用Map/Reduce分布式处理的优点完成相关工作。
2.3 GPU
随着显卡的发展,GPU越来越强大,在计算上已经超越了通用的CPU。而NVIDIA推出CUDA,让显卡可以用于图像计算以外的目的。
CUDA(Computer Unified Device Architecture): 计 算机统一设备架构,是NVIDIA在2007年推向市场的并行计算架构。该架构使GPU能解决复杂的计算问题,它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算。通过CUDA,GPU可以很方便地被用来进行通用计算(类似在CPU中进行的数值计算等等)。开发人员可以通过调用CUDA的API,来进行并行编程,达到高性能计算目的。
在CUDA的架构下,程序分为两个部分:Host端和Device端。Host端是指在CPU上执行的部份;而Device端则是在GPU端执行的部分,又称为Kernel函数,也就是内核函数。Kernel函数描述单个线程的工作,并且通常在数千个线程上调用。在开发人员定义的线程块中,这些线程可以共享数据并通过内置原语来同步它们的动作。
CUDA运行时还提供用于设备内存管理和主机与计算设备之间数据传输的库函数。通常Host端程序会将数据准备好后,先将数据通过命令复制到GPU端已经开辟好内存的数组或者变量中,再由GPU端并行执行核函数程序,完成以后再由Host端将计算结果从GPU端中取回来。
总之,在CUDA工作过程中,CPU担任的工作为控制GPU执行,调度分配任务,并能做一些简单的计算,而大量需要并行计算的工作都交给GPU实现。本篇论文中利用CUDA可以大量并行运算的优点计算目标词向量和其他向量间余弦值。
2.4 实验目的
ARM坚持以较小的面积实现更高的性能,同时坚持高能效的策略。ARMG71可以提供最多32核心的GPU设计能为VR头盔提供极致性能表现。
3 方法实现
3.1 实验硬件环境
本系统使用了四台NVIDIA JETSON TK1开发板搭建ARM集群。Jetson TK1使用了NVIDIA最新发布的Tegra K1处理器,可以进行每秒326千兆的浮点运算。本系统利用其强大的运算能力,能够加快数据处理速度。

图2 集群配置网络拓扑Fig.2 The cluster configuration network
3.2 实验软件环境
在每个Jetson TK1开发板上安装ubuntu14.04系统和cuda6.5环境,同时利用hadoop2.5.2搭建了完全分布式集群环境。
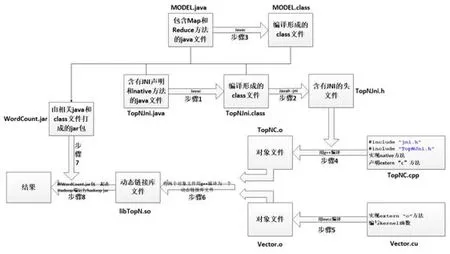
图3 系统框架图Fig.3 The Flow of System Framework
3.3 系统框架
步骤一:编写TopNJni.java,并将其编译为class文件。在TopNJni类中,主要是声明Jni和Native方法(即:MyMethod函 数):public native static String MyMethod(String goal,String data);MyMethod函数是在TopNC.cpp中用C语言实现的;
步骤二:用Javah一jni命令生成头文件TopNJni.h。在TopNC.cpp中需要调用TopNJni.h;
步骤三:编写MODEL.java,并将其编译为class文件。在MODEL类中分别实现了两个Map和Reduce函数;在第一个Map和Reduce中,查询目标词向量,并将结果放到Context中;在第二个Map函数中要调用TopNJni类中的Native方法(即:MyMethod方法),将当前节点获得的文件切片的起始位置和长度传给MyMethod方法,最后求得与目标词向量最相似的TopN;
步骤四:编写TopNC.cpp,用g++编译成TopNC.o。在TopNC.cpp中要声明调用Jni.h和TopNJni.h头文件,声明extern "C" float c_vectorcos(float h_A[Wordcount], float h_B[Wordcount])方法,该方法在vectorAdd.cu中实现;实现Native方法(即:MyMethod方法),在MyMethod方法对从Hadoop2CUDA.Java中传过来的文件切片进行处理,用二维数组记录多个多维词向量,同时调用上述c_vectorcos方法,传递处理好的二维数组,利用GPU计算词向量相似度;
步骤五:编写Vector.cu,用nvcc编译成Vector.o。在Vector.cu中,编写kernel函数:
__global__ void vectorMu(); 实 现 extern "C" float c_vectorcos(float h_A[Wordcount], float h_B[Wordcount])方法,在该方法中调用上述kernel函数,计算词向量间的相似度;
步骤六:利用g++将Vector.o和TopNC.o编译为一个动态链接库文件libTopN.so;
步骤七:将 MODEL.java、MODEL.class、TopNJni.java、TopNJni.class打成 jar包:WordCount.jar;
步骤八:将WordCount.jar和libWordCount.so放到Hadoop端运行,得到运算结果
3.4 程序分析
(1)Hadoop分配任务及汇总处理结果
本系统使用Hadoop基本框架,利用HDFS对原始文件进行切片,利用MapReduce实现分布式计算。
Hadoop为每一个切片创建一个任务调用Map计算,在Map中能够获得切片的详细信息(切片在原始文件中的起始位置、切片的长度等),Map会将这些信息传递给C文件,注意此信息并不是切片的具体记录,通过这样的方法能够减少数据传输量。
此系统会有两个Map/Reduce函数,第一个Map/Reduce用于目标词向量的获得,第二个Map/Reduce用于目标词向量与其他词向量的相似度计算。
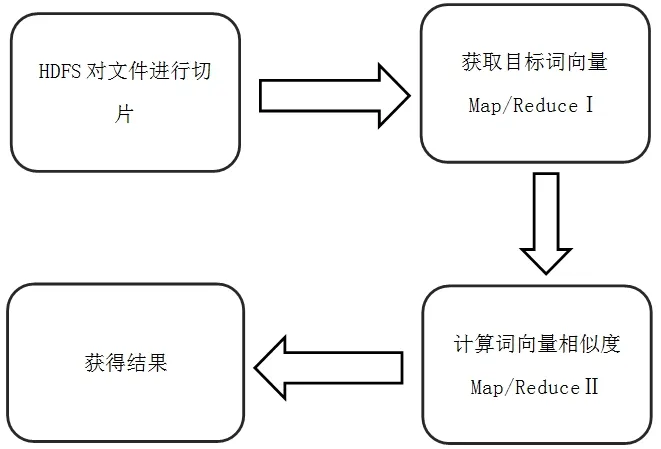
图4 Map/Reduce过程Fig.4 Map/Reduce Experiment
(2)目标词向量的获取(Map/Reduce Ⅰ)
本系统中,用户自主输入目标单词,系统在进行词向量的相似度计算前需要全局查找目标单词的向量表示。此工作是由Map/Reduce函数完成,其中Hadoop系统负责任务分配,即将目标文件切片。在每个Map中对当前获得的文件切片内容进行匹配,Reduce获得最终结果,并将结果写入Context。通过这种方式,将全局查找任务分成N个结点上分布式运行的小任务,提高查找速度。
(3)目标词向量相似度计算(Map/Reduce Ⅱ)
本系统需要计算目标词向量与所有其它词向量的相似度。此任务可以将所有词向量数据分解成N个数据集,在不同的结点上计算目标词向量和当前数据子集中词向量的相似度。
(4)CUDA计算词向量间相似度
CUDA的优点在于处理大量并行化的问题,而在本系统中需要计算的部分在于计算两个词的相似度,本系统采用夹角余弦法计算向量间的相似度,如公式1。
本系统中待处理的词向量有200个维度,为核函数分配N个区块(block)(N为当前节点需要计算的词向量个数),200个线程(200为词向量的维度)。在核函数中利用线程计算等待所有线程同步后,每个区块再利用for循环对做求和,然后求出夹角余弦值并获得最终结果。
另外,在利用CUDA做计算中,一般而言,Host端和Device端间数据的复制会消耗系统时间,影响计算速度。而本文采用的Jetson TK1开发板的优点在于Device端可以直接使用Host端的数据,无需进行Host端和Device端的数据传递。因此,在本文系统中,在数据节点利用GPU计算一个端中词向量的相似度,必然会提高系统的整体性能。
(5)TopN的计算
在大规模的词向量相似度计算中,全局有序是极其复杂的,并且会耗费集群中大量的资源。
本系统的Top N模式中不会对整个词向量数据集进行排序,而是每次找出同一个map实例中最高价值的词向量数据集进行记录,另外需要注意的是:每个Map中的TopN是在c文件中根据cu文件传回的计算结果去计算,这样会减少数据的传输量。
最后在Reduce阶段,合并每个Map中的TopN得到最终的TopN。在这种模式下,本系统减少了计算量和数据传输量,大大提高了效率。
4 实验结果
本文实验中使用的词向量是经过作者利用Word2Vec训练得到的,每个词向量有200个维度。训练中采用的语料主要来自于北京语言大学语料资源库,其中包括百科全书、大陆小说、港台小说、古典文学、名家小说、人民日报、外国文学、武侠小说。另外,本文构建了一个爬取和解析工具,用于获取百度百科中生物相关的文本内容,得到35,803个有效网页,共331,430个段落,约114.9M字节。
在实验中,若输入数据为:鳝鱼,实验结果如表1所示:
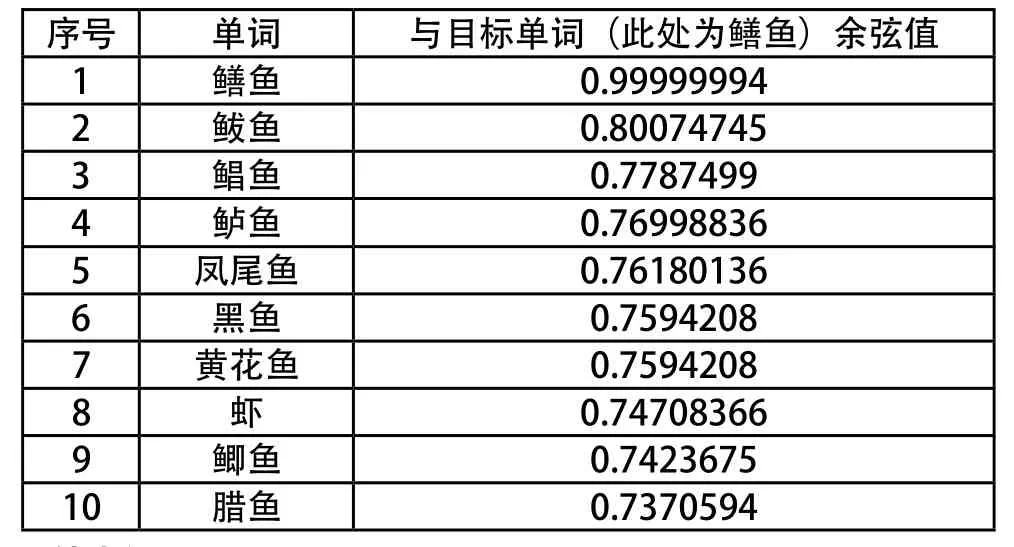
表1 “鳝鱼”的Top 10Table 1 Top 10 of “Eel”
5 结束语
本文利用Hadoop集群的分布式特点和Jetson TK1开发板的GPU特点,构建了一个面向向量相似度计算和提取最相似TOPN个词向量的系统。该系统的特点是:
①系统可以根据计算任务的规模弹性扩充,当计算资源不足的时候,可以随时向集群中增进计算节点,扩充系统的计算能力。
②利用Hadoop集群的特点完成文件的分发和与GPU的整合。
③利用GPU对批量的向量相似度计算任务进行加速。
④利用Jetson TK1的特点,避免了Host端和Device端之间数据传递的时延。
⑤利用MapReduce计算模式,加速了在大规模词向量中进行词向量检索和TOPN计算的过程。
[1]William B.Frakes,Ricardo Baeza—yates.Information retrieval:data structures and algorithms.Prentice—HallInc.USA.PP 420—441.
[2]Yang B, Kim H J, Shim J, et al. Fast and scalable vector similarity joins with MapReduce[J]. Journal of Intelligent Information Systems, 2016, 46(3):473-497.
[3]Salton G, Wong A, Yang C S. A vector space model for automatic indexing[J]. Communications of the Acm, 1975,18(11):273-280.
[4]Sharma T, Shokeen V, Mathur S. Multiple K Means++Clustering of Satellite Image Using Hadoop MapReduce and Spark[J]. 2016.
[5]Faruqui M, Dyer C. Non-distributional Word Vector Representations[J]. Computer Science, 2015.
[6] White T. Hadoop: The Definitive Guide[J]. O’reilly Media Inc Gravenstein Highway North, 2010, 215(11):1 - 4.
[7]http://www.cnblogs.com/davidwang456/p/5015018.html.2015-12-03
[8]J Dean,S chemawat.mapreduce:a flexible data processing tool[J].Communications of Acm,2010,53(1):72-77
[9]h t t p://b l o g.c s d n.n e t/o p e n n a i ve/a r t i c l e/details/7514146.2014-10-29
[10]Li Jian-Jiang,Cui Jian,Wang Ran.A review of parallel mapreduce research models. Journal of Electroni cs.2011,39(11):2635-2642
[11]https://my.oschina.net/nyp/blog/534003.2015-11-12
[12]http://product.pconline.com.cn/itbk/diy/graphics/1109/2521869.html.
[13]Ryoo S, Rodrigues C I, Baghsorkhi S S, et al.Optimization principles and application performance evaluation of a multithreaded GPU using CUDA[C]// ACM Sigplan Symposium on Principles and Practice of Parallel Programming,PPOPP 2008, Salt Lake City, Ut, Usa, February. 2008:73-82.
[14]李建江,崔健,王聃.mapreduce并行研究模型综述.电子学报.2011,39(11):2635-2642
国家自然科学基金项目(61602044);北京市教委科研计划面上项目(KM201411231014);北京信息科技大学2016年人才培养质量提高经费(5111610800);北京信息科技大学2017年人才培养质量提高经费(5111723400)
张禹尧,男,1996—,本科在读,研究方向为自然语言处理;毛腾,女,1995—,研究生在读,研究方向为自然语言处理;李俊,男,1994—,研究生在读,研究方向为自然语言处理;蒋玉茹,女,1978—,博士,讲师,研究方向为人工智能、自然语言处理。
