说话人识别中基于深度信念网络的超向量降维的研究
2017-10-26李为州杨印根
李为州 杨印根


摘要:在说话人识别系统中,为了精确地将说话人的特征表现出来,往往需要用到超向量,为解决在说话人识别中超向量维度高,运算量较大的问题,该文提出了基于深度学习的降维方法,利用通过多个受限玻尔兹曼机堆叠而成的深度信念网络对超向量进行降维。实验表明,深度信念网络方法在说话人识别中超向量降雏有着更好的效果,其分类的准确率高于传统的降维方法。
关键词:超向量;降维;深度学习;深度信念网络;受限玻尔兹曼机
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2017)22-0176-03
说话人识别技术,又称为声纹识别技术,它是生物识别技术的一个分支。因为每个人的声道形状,喉咙大小,以及其他发声器官的不同,所以每个人的声音各有特色。由于人与人之间存在这样的物理性差异,因此每个说话人都有独特的说话特点,说话人识别技术则是根据这些特点对说话人身份进行识别和辨别的一项技术。
进行说话人识别时,随着说话人样本规模的不断增加,系统对说话人识别的准确率则会随之衰减,为了提高说话人系统的识别性能,需要获取更精确的表征说话人信息的特征向量,因此超向量(SuperVector)的概念被提了出来。超向量的基本理念是通过特定的方法,将大量的说话人训练语音帧特征向量进行压缩、映射,从而构造成高维度的、固定维度的特征向量。具体来说,就是利用说话人识别中的经典模型——基于通用背景模型(university Background Model,UBM)的高斯混合模型(Gaussian Mixture Model,GMM),对于目标说话人,利用UBM并且采用最大后验概率fMaximum a Postteriori,MAPl进行自适应,得到一个与UBM大小相同的一个目标说话人GMM。训练中只更新GMM的均值,再将向量中的均值连接起来,得到GMM均值超向量,称为超向量。然而,在研究中发现超向量的维数比较高,高维度的信息并不都是有用的信息,有些有用的,能够反应说话人的信息,有些是不确定是否有用,暂时还不知道如何使用的信息,还有一些则是没用的,并且还有可能淹没有用信息的无用信息,这样并不利于后续分类算法的训练,因此需要对超向量进行处理。
在处理高维度数据的关键之处在于从众多的影响因素中寻找到最本质的因素,消除冗余,换句话说就是从高维度数据中寻求其低维表示,同时保留其必要特征的映射或变换过程,这就是降维。具体来说就是通过一个映射F,将一个数据集X={xi∈RN}变换为Y={yi∈Rn}(n 在过去的几十年里,有众多的降维方法被提出来,根据对数据处理方式的不一样,将数据降维算法分为线性降维和非线性降维。线性降维是指通过降维所得到的低维数据能够保持与高维数据点之间的线性关系,线性降维算法包括主成份分析(PCA)、线性判决分析(LDA)等。非线性降维有两种,一种是基于核的,它是将原始的数据隐式地映射到更高维的特征空间中,以便于在特征空间中利用线性的方法对数据进行处理,如核主成份分析(KPCA)、核独立成分分析(KLDA)等,另一种则是通常所提到的流形学习,即从高维采样数据中恢复出低维流形结构,求出相应的镶嵌映射,如等距映射(ISOMAP)、局部线性嵌入(LLE)等。 人工神经网络fArtificial Neural Network,ANN)是人工智能(Artificial Intelligence,AI)中的一个由大量神经元构成进行计算的自适应模型或计算数学模型。人工神经网络在其发展过程中经历了一些曲折,使得其发展停滞了长达数十年之久。直到2006年,Hinton在《科学》杂志上发表了一篇关于深度神经网络的论文,从此开启了深度学习(Deep Learning,DLl在学术界和工业界的浪潮。深度学习常用的方法和模型有,自动编码器(AutoEncoder,AE)、稀疏编码(Sparse Coding,SC)、受限玻尔兹曼机(Restricted Bohzmann Machine,RBM)、深度信念网络(DeepBelief Networks,DBN)等。本文所使用的降维方法则是基于多层受限玻尔兹曼机的深度信念网络,构建了一种数据降维模型,对超向量进行降维,然后将降维后的数据应用到说话人识别系统中进行验证。 1深度信念网络算法 本文在对超向量进行降维的时候,需要构建一个深度信念网络,深度信念网络是通过多个受限玻尔兹曼机堆叠而成。 1.1受限玻尔兹曼机的基本概念 受限玻尔兹曼机是一类具有两层结构、对称连接的随机神经网络,一层为可视层,一层为隐藏层。RBM的层间是全连接的,而层内是无连接的。受限玻尔兹曼机的结构如图1所示,上面为隐藏层,下面为可见层。 1.2构造受限玻尔兹曼机 假设一个首先玻尔兹曼机有n个可视单元和m个隐藏单元,用向量v和向量h分别表示受限玻尔兹曼机可视单元和隐藏单元的状态。那么受限玻尔兹曼机作为一个系统,它的可视单元和隐藏单元的联合能量公式为: 基于上述的联合能量公式,可以得到v和h的联合概率分布,其定义为: 由于RBM层与层之间有连接,而层内是无连接的,根据这一特性,可视单元状态确定时,各个隐藏单元的激活状态之间是条件独立的,令第j个隐藏单元的特征值取1的概率为: 再根据RMB的对称性,又可以得出第i个可视单元的激活概率: 通过激活概率,可以将可见层的数据进行重构,隐藏层再根据重构后的数据对自己的状态进行更新。对于权值的更新变化公式为: 2实验过程及结果分析 2.1實验设置 本文的实验是基于ALIZE平台,运行于Intel Xeon CPUE5-2620 v3 2.40GHz服务器环境下进行的,实验所使用的说话人语音是来美国国家标准技术研究院(National Institute of Stan-dards and Technology,NIST)说话人评测(Speaker RecognitionEvaluation,SRE)2008年的核心语音库。语音首先进行预处理和特征提取,语音帧长为20ms,帧移10ms,提取13维MFCC特征及其一阶、二阶差分组合成39维输入特征,GMM采用1024阶混合,用NIST SRE04、05和06年语音数据集数据分别训练出1024阶性别相关的通用背景模型UBM,并用最大后验概率(MAP)进行自适应,训练中只更新均值,再将向量中的均值连接起来,得到GMM均值超向量。
将得到的超向量通过深度学习的方法进行降维,训练出400维的i-vector,并将降维后的结果运用到说话人识别的实验中,实验结果通过等错误率(EER)和最小检测代价函数(minD-CF)进行评估。
2.2实验过程
使用多层RBM堆叠的深度信念网络对超向量进行降维时,是需要设置一些参数的,比如最大训练的迭代次数、隐藏层节点的数量、学习率、参数的初始值等。Hilton等提出通过RBM进行预训练,获取理想的实验参数。在预训练阶段,通过第一层的RBM进行训练,生成的数据将作为下一层RBM的可视层单元进行训练,这样一层一层的学习,重复多次。然后将降维得到的数据进行反向解码,生成高维数度,与原来的数据进行相似度对比,并调整RBM的参数,使其达到要求的精度。设置学习率的时候,学习率不宜过大,否则会导致重构误差急剧增大,权重也会变得非常大。设置隐藏层节点数量的时候,基于所得的数,选择低于这个数一个数量级的值作为隐藏单元的个数,如果训练数据高度冗余,则可以选择更少的隐藏单元。最大训练的迭代次数对实验结果也有影响,增加迭代次数可以提高结果精确度,但并不是迭代次数越大越好。进行预训练时,通过重构误差的大小来反应RBM对训练数据的似然度,重构误差的计算非常简单,只需要将重构数据与原数据的差值求平方,每次结果累加起来,就是重构误差。虽然重构误差不是完全的可靠,但是在实验过程中还是非常有用的。
2.3实验结果与分析
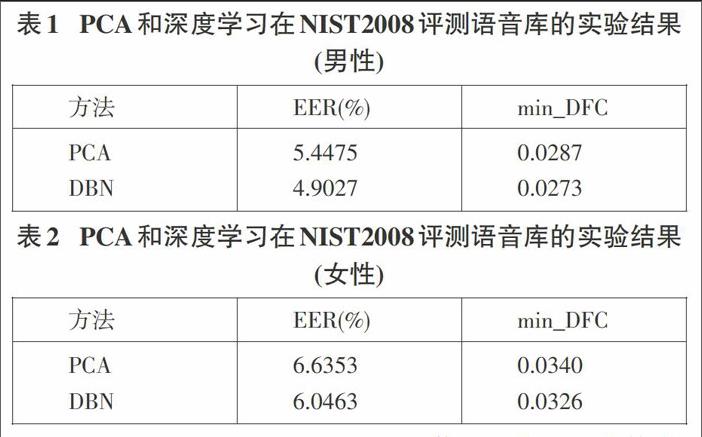
本文测试使用的超向量样本为6939对39936维度的男性样本和9552对39936维度的女性样本。使用上文所介绍的基于四层RBM堆叠的深度信念网络对其进行降维,将维度降低到400维。在实验中,最大迭代次数为50次,学习率设置为0.1,动量的初始学习率设置为0.5,当重构误差趋于平稳增加的状态时,动量的最终学习率设置为0.9。实验结果的评测方法使用的是等错误率(Equal Error Rate,EER)和最小检测代价函数(minimal Detection Cost Funcfion,min_DCF)进行评估。表1和表2分别为男性和女性的实验结果。
从表中的数据可以看出基于深度信念网络的方法等错误率有一定的提高,因此将深度信念网络方法应用于说话人识别中的超向量降维是可行的。
3結束语
本文针对在说话人识别中,超向量维度高的特点,提出了基于深度信念网络的降维方法。具体方法是,通过多个RBM堆叠成一个深度信念网络,超向量通过RBM进行一层一层的降维,每一层学习生成的数据将作为下一层RBM的可视单元进行训练,最终生成目标维度的数据,然后将生成的数据通过RBM进行反向解码,一层一层的还原为高维数据,并与原先的数据进行相似度对比,通过调整RBM里面的各项参数,提高精确度。在预训练过程中,通过重构误差的大小来反应RBM对训练数据的似然度,当各项参数调整好后,对生成的数据进行说话人实验。实验表明,深度信念网络方法在说话人识别中超向量降维有着更好的效果,其分类的准确率高于传统的降维方法。
尽管初步验证证明深度学习可以运用于说话人识别中的超向量降维,然而如何在保证准确率的前提下提高运行效率以及深度学习能否应用于说话人识别技术的其他方面,这些诸多问题还值得进一步的研究。endprint
