基于内存数据库的三维模型管理方法
2017-10-21刘天漪钟志农甘麟露
刘天漪,钟志农,熊 伟,甘麟露,陈 荦
(国防科技大学 电子科学与工程学院,湖南 长沙 410073)
0 引 言
三维场景是三维地理信息系统的重要组成部分,如何实现三维场景的流畅显示是目前三维地理信息系统的重要问题。三维模型是组成三维场景的主要元素,每个模型同时包含顶点、纹理和语义等多种信息,其结构复杂,内容丰富,数据量大。就一个城市场景而言,三维模型的数据量少则几个GB,多则上百GB。在面向Web的三维可视化应用中,由于三维模型数据量大,造成磁盘I/O和网络传输时间较长,浏览器端等待绘制的时间也会增加,可视化效率会降低。因此,为实现三维场景的流畅显示,需要对三维模型进行高效组织管理。
目前,三维模型的格式和来源多样,并在数据组织和管理上没有统一的标准。现阶段常用的管理方法与二维数据类似,主要有文件管理方式[1]和关系数据库管理方式[2]。采用文件系统管理方式,三维模型未得到有效的组织,数据冗余量大。而基于数据库的管理方式则主要管理三维模型的元数据信息,侧重解决模型的存储、检索等方面的问题,较少涉及对三维场景可视化效率的研究。两种方式在实际Web应用中,均存在存取模型速度慢、响应时间长、可视化效率低等问题。为克服上述问题,本文提出了一种基于redis内存数据库的三维模型管理方法。实验结果表明,采用该方法管理三维模型,能较大提高三维场景可视化的效率。
1 相关核心技术
1.1 glTF三维模型
在通过浏览器浏览三维场景时,三维模型数据是网络传输的主要内容,传输效率直接影响模型可视化效果。因此,需要一种占用空间小、传输速度快、与图形绘制接口良好对接的三维模型数据格式。
glTF是一种专为WebGL设计的,利于高效传输和加载三维场景的三维模型格式[3]。它描述三维模型全场景,包含模型的网格结构、纹理图片等信息,其结构如图1所示。一个完整的glTF模型共分4个部分:.gltf文件,.bin文件,.glsl文件和.jpg或.png文件。其中,.gltf文件是整个模型的核心,它存储模型的节点层次、材质、相机等信息;.bin文件是二进制几何文件,主要存储模型的顶点坐标和坐标的索引等信息;.glsl文件是着色器文件,主要存储图像渲染所需的顶点着色器和像元着色器;.jpg或.png文件是模型的纹理贴图文件。在实际应用中,为降低前端浏览器的并发请求数,可将着色器文件、二进制几何文件和贴图文件利用Data URL技术,以base64字符串格式内嵌到glTF文件中,成为一体。
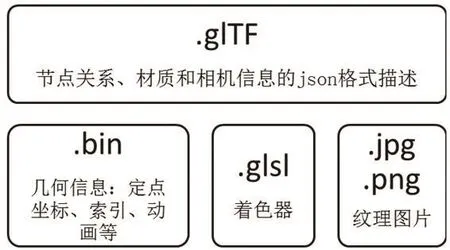
图1 glTF模型Fig.1 glTF model
将贴图文件以base64编码的方式内嵌到glTF中,在使用时还需要另外解码,且三维模型文件大小增加了30%左右。为解决上述问题,Khrono组织官方引入Binary glTF扩展[4],它既能够将所有glTF资产整合到一个文件中,又能够解决base64位编码带来的损失。Binary glTF文件结构如图2所示。它由三部分组成:20位的头文件(20-byte header)、json格式的场景描述(content)以及二进制块(body)。其中二进制块是最关键的部分,它包含所有的顶点、索引、图片和着色器信息,将所有的整型、单精度浮点型的顶点数据以四字节的数组编码。

图2 binary glTF文件结构Fig.2 Binary glTF file structure
1.2 redis内存数据库
redis是一种键值对(Key-Value)数据库[5],它利用哈希表在键(key)与值(value)建立映射关系。键值对建立之后,通过key可以快速查找到对应的value。因此对于单个key的查找来说,Key-Value存储能够获得良好的性能。
利用redis数据库管理三维模型的优点主要有:
1)减少磁盘I/O,提高模型存取速度。由于redis是内存数据库,所有的数据不经过磁盘直接调用,对于加载数据量较大的三维模型,缩短了响应时间。
2)支持集群模式。单个计算机的内存容量有限,因此存储大数据量的三维模型受到限制。而redis提供Cluster集群方案,可以将内存容量扩展,并对数据分块存储。
3)持久化设计。redis作为内存数据库,能够在将数据加载到内存操作的同时,异步将其flush到硬盘中保存,以此保证服务器重启后数据不丢失。
4)丰富的数据结构。与其他非关系型数据库不同,redis中数据类型不仅限于字符串,还支持字符串列表、无序不重复的字符串集合、有序不重复的字符串集合以及key-value都为字符串的哈希表。
5)地理特性。Redis数据库可以存储地理空间信息,并进行简单的操作。
1.3 WebGL技术与Cesium三维引擎
WebGL诞生于2010年,是由科纳斯组织(KhronosGro up)开发和维护的一种基于 JavaScript免费的、跨平台的应用程序接口API[6]。它运用JavaScript脚本制作Web交互式三维图形程序,利用统一的OpenGL接口,通过底层图形处理硬件加速功能进行图形渲染。利用WebGL技术,可以无需插件,直接通过浏览器加速图形硬件,提高渲染速度。
Cesium是一个通过Web浏览器创建三维地球和二维地图的JavaScript库[7]。它无需任何插件,能够在支持HTML5标准的浏览器上运行。由于Cesium基于WebGL技术提供图形加速,因此在渲染较复杂的三维模型时可以显著提高性能,适合大范围三维场景的可视化。除此之外,Cesium还广泛收集库,能够在三维地球上执行各类地理信息分析。
2 基于redis的三维模型管理方法关键技术
2.1 三维模型数据格式转换
目前,glTF还未成为行业标准,各大商业建模软件还不支持直接以glTF格式导出三维模型,只能先以collada格式导出,再通过数据预处理过程转成glTF格式。还可根据需要,转成Binary glTF格式。
具体流程如图3所示。
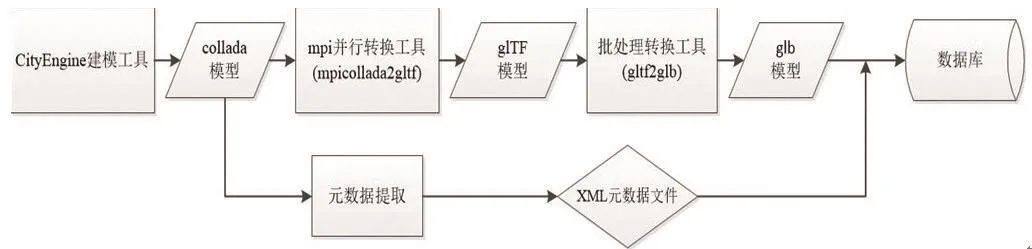
图3 数据预处理流程Fig.3 Data pretreatment process
1)利用建模软件CityEngine,建立费城地区大规模三维场景数据集,以collada格式导出。建模后的费城数据集共有collada模型文件412个,纹理图片125张,共41.5 M。
2)采用mpi并行框架,编写多进程批处理转换程序mpicollada2glTF.py,将模型全部转化成glTF格式。同时利用python语言的xml解析模块xmlElementree解析collada模型,提取元数据信息,包括模型的名称、高度、底面中心坐标、底面中心坐标Geohash值及其他相关属性信息,名字作为下一步查询模型的索引,坐标信息用来决定模型在可视化过程中放置的位置。把所有模型的元数据信息写入一个xml元数据文件,作为下一步调度模型可视化的索引文件。
3)通过利用python语言编写的批处理程序gltf2glb.py把所有glTF模型转换为Binary glTF格式,并存入数据库管理,以便下一步调用。
2.2 基于redis的三维模型数据存储结构
根据空间数据库的一般组成结构和三维模型数据的特点,设计基于redis的三维模型数据库。它为三级存储结构,如图4所示。
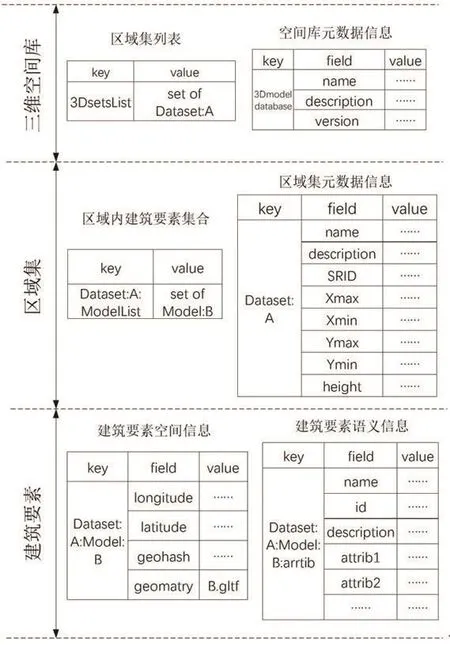
图4 基于redis的三维模型三级存储结构Fig.4 3-level store structure of 3D model based on redis
第一级为三维空间数据库,包括一个区域集列表和描述该空间数据库的元数据信息。区域集列表采用redis的set数据结构存储所有的区域集名称,key=3DsetsList,value为数据库内所有的区域集,利用redis的smembers命令可返回三维空间数据库中所有的区域集成员;空间数据库元数据信息采用redis的hash数据结构管理,包括数据库的名称(name),描述(description)和版本(version)。
第二级是区域集,按照区域将三维模型划分到不同的集合中。和上一级结构类似,区域集也包括两部分,即区域内建筑要素集合和区域的元数据信息。区域内建筑要素集合同样采用set数据结构管理区域内所有的建筑要素,key=Dataset:A:ModelList,value为区域内所有建筑要素,可通过keys命令获取区域内全部建筑,也可判断某建筑是否在该区域集内。利用geoadd命令可将区域集内建筑元素及其经纬度坐标信息全部添加,还可利用geopos命令获取建筑元素地理位置,方便在可视化过程中将模型放置在正确地理位置;区域集的元数据信息也采用hash数据结构,包括该区域的名称,包围盒范围(Xmax,Xmin,Ymax,Ymin),此外由于每个区域集建模的参考系不一定完全相同,所以还需要将坐标参考系信息(SRID)作为重要元数据信息存储。
第三级为建筑要素,不仅管理三维模型空间信息,也管理语义信息。用hash数据结构存储模型的经纬度信息、Geohash值和全部模型资产(.gltf文件)。Geohash 字段用来存储该建筑要素的空间编码,空间编码可将模型底面中心的二维位置坐标转化为一维的字符串,以string类型存储,它将是进一步研究中构建redis集群索引的基础。.gltf文件以string格式存储在geometry字段中,代表该模型元素的全部资产;建筑要素的语义信息较多,适合用hash数据结构存储,包括名称(name),id等其他属性信息。
为保证建筑要素的key值唯一,需要将三维空间数据库、区域集、建筑要素3个部分组合起来,每部分的名称都需要保证全局唯一。以费城数据集某一建筑要素为例,设计其key为db1:phil:Shape1.gltf,通过主键索引,即可从数据库db1、区域phil、建筑名Shape1.gltf获得唯一建筑要素。采用这种方式组织三维模型,可以迅速检索所需空间数据库、区域集、建筑要素及其相关信息。通过这样的策略,在下一步的数据发布阶段,使得服务器端可以直接通过key定位指定模型,将数据返回浏览器前端进行绘制。
2.3 数据的发布与可视化
由于redis中的数据存储在内存中,而Cesium绘制引擎通过调用统一资源定位符(url)获得数据资源,因此需要建立Web服务,将内存数据库中的数据通过url发布。数据发布过程如图5所示,其基本流程如下:浏览器端先向Web服务发出Get请求,当Web服务收到Get请求后,从基于redis的三维模型数据库中调用所需模型,然后通过Web服务将请求的模型返回给前端,最终由Cesium引擎实现可视化。其中Web服务基于轻量级Web应用框架Flask编写,将自定义的get函数动态绑定到url上,可以实现前端通过url获取内存中数据的功能。而自定义的get函数,就是根据key从三维模型数据库中取得模型数据的过程。

图5 三维模型数据发布过程Fig.5 3D data publish process
3 实验结果与分析
为验证本文提出的方法对可视化效果的优化,进行了两组对比实验。一是对采用传统文件系统和本文方法管理的模型加载时间对比,二是采用本文方法管理glTF模型和带有Binary glTF扩展的模型加载时间对比。实验环境配置如下:浏览器端为Intel i5-4570 CPU,16G内存;服务器端为4个Intel Xeon E5-4620 2.2GHz CPU,529G内存。浏览器端操作系统为win7,安装有chrome浏览器;服务器端操作系统为centOS,安装有redis数据库。实验数据为费城某城市场景,经过预处理后生成的glTF格式的数据量大小为868.4 M,再转换为Binary glTF格式的数据量大小为868.4 M。
3.1 不同管理方法下模型的加载效率测试
前端分别对文件系统和本文提出的三维数据库请求50、100、200、300个模型,进行3次测试,取3次实验耗时的平均值。采用传统文'件系统和本文方法管理的模型加载时间对比如图6所示。
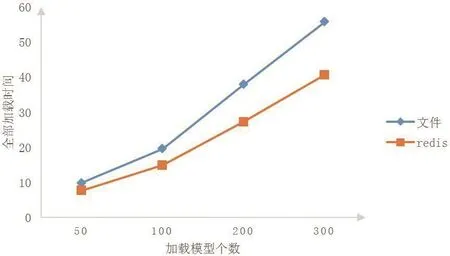
图 6 不同管理方式加载时间对比Fig.6 Comparison of different management approaches'loading time
不难看出,无论采用哪种管理方法,随着模型数量的增多,加载时间几乎都呈线性增长。采用本文方法管理的模型,全部加载时间小于从文件系统加载模型的时间,且两者的时间差值随着模型数量的增大而增大。
可视化情况对比如图7所示,图7(a)为从文件系统获取,图7(b)为从redis获取。相同时间内,浏览器界面上的模型数量存在明显差异。采用本文方法管理的模型比采用文件系统管理的模型数量多,可视化效率更高。

图7 加载模型情况对比图Fig.7 Comparison of visualization between different management approaches
分析两者性能差异原因,主要在于本文提出的方法基于redis内存数据库,数据存放在内存中,服务器在接到前端请求后,不需要先从磁盘取出数据,减少了磁盘I/O,缩短了响应时间。而传统的文件系统,数据存放在硬盘中,需要先将数据传输到内存中,请求才能得到响应。因此受制于磁盘I/O瓶颈,采用文件系统管理三维模型比采用本文方法管理三维模型加载效率低。
3.2 不同格式模型的加载效率测试
采用本文方法,分别加载普通glTF格式模型和Binary glTF格式模型,不同格式数据加载时间对比如图8所示。
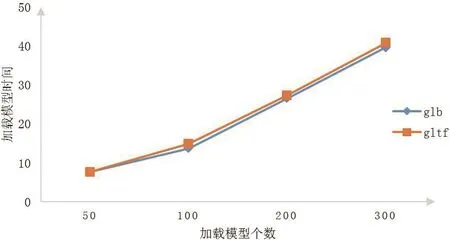
图8 不同格式模型加载时间对比Fig.8 Comparison of different format models of loading time
加载Binary glTF模型所需时间比加载普通的glTF模型略有缩短,但效果不够明显,加载300个模型的时间仅缩短1s左右。分析其原因,主要在于Binary glTF模型的数据量小于普通glTF模型的数据量,所以缩短了模型的内容下载时间。完整的模型加载时间包括排队时间、迟滞时间、网络连接时间、请求时间、等待响应时间、内容下载时间等,其中内容下载时间不是影响整个模型加载时间的主要因素。因此采用Binary glTF模型,不会显著提升模型的加载效率。
除此之外,在加载全部数量的模型时,采用glTF模型出现滑动鼠标不流畅、浏览器卡顿甚至崩溃的情况,而采用Binary glTF模型则可以全部加载。由此可见,采用数据量更小的Binary glTF模型对前端压力更小。
加载全部模型俯视图如图9所示,模型细节图如图10所示。
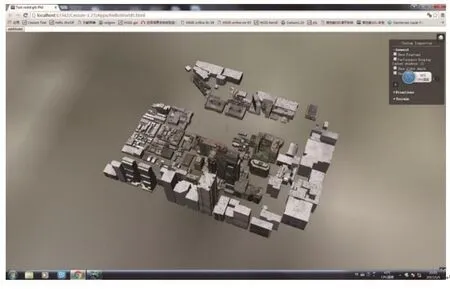
图9 费城数据集的全部模型Fig.9 All models of the Philadelphia dataset
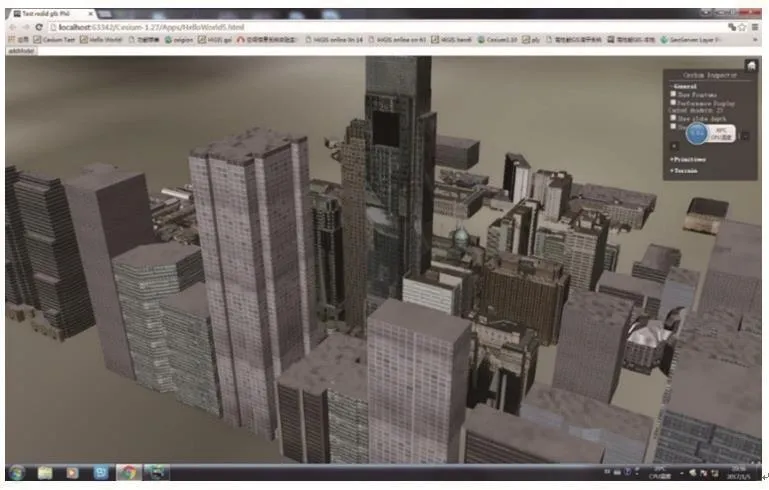
图10 费城数据集的模型细节Fig.10 The model details of the Philadelphia dataset
4 结束语
本文提出了一种基于redis内存数据库的三维模型管理方法,设计和实现了以redis为基础的三维模型数据库的分级组织结构,对普通glTF模型和Binary glTF模型进行管理。实验结果表明,较之常用的文件管理方式,该方法有效提升模型的加载效率。模型调用速度显著提高,模型加载时间平均缩短20%左右,可视化效果更加流畅。除此之外还发现,尽管数据量更小的Binary glTF模型在提升模型加载效率方面效果不明显,但其减小的数据量足够减轻前端的绘制压力,且减少了网络传输时间,也在一定程度上提高了可视化效率。因此,采用本文提出的基于redis的三维模型管理方法管理数据量小、适合可视化的Binary glTF模型,可以有效提高三维模型的可视化效率,优化可视化效果。
在下一步的研究中,还需要考虑更大规模的模型场景可视化效率。拟考虑对三维模型进行LOD分级,在一次性加载大规模的模型时根据视点高度选择合适层级的模型进行加载,进一步提高模型加载效率,减轻前端浏览器绘制压力,优化三维场景可视化效果;另外还可以采用redis集群,以geohash值作为索引,将地理临近的三维模型映射到同一节点中,实现高效率的范围查询。
