可扩展的分布式矢量空间数据库集群原型系统研究
2017-10-17彭瑾,熊伟,吴烨,陈荦
彭 瑾,熊 伟,吴 烨,陈 荦
(国防科学技术大学 电子科学与工程学院, 湖南 长沙 410073)
0 引 言
随着空间数据的获取手段的不断丰富,基于海量空间数据的分析计算变得可行,时空大数据的时代已经到来[1-2]。针对每天以PB级速度在增长的地理数据集,传统的基于单节点的空间数据库服务模式已经不能满足大数据集的存储和查询处理需求,为此需要引入分布式系统对空间数据集进行存储和处理[3-5]。
如何对时空大数据集进行划分、存储,成为提高分布式空间数据库查询处理性能的关键问题。SpatialHadoop[6]使用的是HDFS的存储系统,它是将输入的数据或者文件默认的划分成64M的数据块,虽然这对于存储大量需批量处理的数据是一种好的解决办法,但是若对于文件大小不固定且小文件数量很多的情况增加了一定的开销,Hadoop-GIS[7]中,对这一方法进行了改进,首先它将矢量数据的点、线、面分开存储,并将其用均匀网格的方式划分,再计算每个网格中的密度,选定一个阈值,大于此阈值的数据再按照x或者y轴进行分割,但是该方法中网格大小需要根据数据集具体情况来确定。而在MongDB[8-9]中,是从数据集中选择一个键值(属性)对数据进行分片,利用这个键值来分割数据。但是这样的划分只考虑到了数据量大小的问题,并没有考虑到数据的空间特性,不能适应复杂的查询问题,没有很好的扩展性。中国科学院大学陈达伦采用数据库中间件方式实现分布式空间查询集群原型系统GeoMPP空间数据库,但是其查询性能通过中间件层有所消耗。
本文基于Share-Nothing的开源数据库Postgresql集群体系结构,设计并实现了基于Geohash的矢量空间数据分片存储方法,基于该分片方法实现了空间数据的并行导入,最后实现了分布式矢量空间查询处理。实验表明,并行导入大数据集至分布式数据库能提高其导入数据的性能,同时基于Geohash 划分方法进行分布式存储的空间数据库能够提升空间查询性能和并发访问性能。
1 扩展的集群体系结构
图1显示了由许多独立的计算机组成的Postgresql集群体系结构,这种结构具有高度可扩展性,可以在任意时间内增加集群的数量以提高查询的性能。同时,主节点保存从节点的元数据信息,当在主节点执行相关查询命令后,可以获得各个从节点的活动状态以及其存储的表信息。因此,当用户进行一个查询时,主节点将查询划分成若干查询片段,每一个查询片段能够独立地运行在从节点的相关表碎片上,利用相关从节点的处理能力来进行分布式查询。同时由于从节点是以表的形式存储数据碎片,因此,每个从节点均支持局部索引来提高其查询效率。最终,当从节点结束查询后将结果提交给主节点,由主节点进行合并并返回给用户完成一次查询。
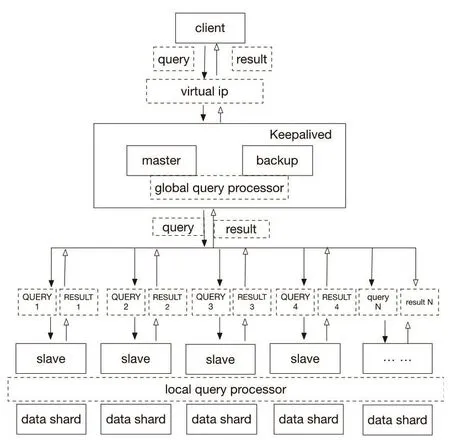
图1 Postgresql集群体系结构Fig.1 Postgresql cluster architecture
2 分布式空间数据库集群关键技术
2.1 空间数据分片策略
空间数据分片策略是根据Geohash算法对大数据集进行空间划分,利用集群对分片数据进行存储管理,当客户端向集群发送查询请求时,主节点将用户的请求分发到各个从节点上进行并行查询,从节点再将查询结果传回主节点,主节点接收返回的结果合并后提交给用户。
数据分片又称数据划分,是利用一定策略将较大的数据分割成n个不相交的数据块,为数据的分布式存储及并行传输提供基础。良好的空间数据划分策略应满足两个基本原则:逻辑的无缝保持性和空间对象的不分割性[10-11]。典型的空间数据分割方法主要是将整个空间区域分割成网格,并将空间对象根据其位置分配到不同的节点中。但是,由于空间对象不均匀分布的现象非常普遍,单个空间对象可能与多个网格相交,造成了分配方式的复杂性[12]。因此,本文主要是先根据单个空间对象的最小包围框求出其质心,再对其质心使用了Geohash算法得到其编码,对数据进行分片。Geohash是一种地理编码,它可以把二维的经纬度坐标按照精度要求对其编码成字符串。通过Geohash编码后的数据,空间上相邻的位置在编码上有相同的前缀,使之在解决区域搜索的问题上具有明显优势[13]。其过程如下:首先将经度范围[-180,180]平分成两个区间,如果经度坐标位于前一个区间则编码为0,否则编码为1,之后按照所要求的精度将区间进行若干次划分并更改其编码值,对纬度进行同样的算法进行编码。对于分别得到的经纬度编码进行合并,奇数位是纬度,偶数位是经度,最后用0~9、b~z(去掉a,i,o)这32个字母进行base32编码得到目标对象的Geohash值[14],然后对Geohash进行排序,得到预处理后的数据集。
2.2 空间数据并行导入方法
对于单个较大的空间数据,相较于普通数据,其导入性能往往较低。为了解决这一问题,主要是把按照一定策略分成逻辑片段的数据,通过传统的轮询、哈希、范围等方法将分片合并,并行地传输至不同的物理节点上。轮询方法首先将分片按行编号,然后使用轮询算法将分片映射到不同的物理节点,哈希方法与轮询方法一样,先进行按行编号,再用哈希算法将分片映射到不同的节点上。但是,对于空间数据,使用轮询方法和哈希方法可能将处于地理邻近的分片映射到不同的节点中,不利于保持数据的空间邻近性。而范围划分,是先对记录进行排序,然后按照排序码将其划分成n个区域,并使得每个区域大致含有相同数目的记录。这能较好地保证在某一属性上,值相近的数据能处于同一节点中[15]。利用范围划分方法的这一特点,本文通过对数据进行Geohash编码后,按照其值进行排序,根据范围划分的方法,通过程序将数据并行地分发至不同的物理节点,以提高大数据集的导入效率。上述方法保持了空间数据的地理特性,使得相近的空间数据尽可能地分布在同一个物理节点中。而最终的分片个数主要是由CPU的核数所确定,高效的算法应保证节点中每个CPU都发挥其作用。因此,区域的数目可估计为CPU核数的2~4倍。图2展示了对中国各省的面矢量进行数据划分、导入数据库的过程。

图2 数据划分、导入总体流程Fig.2 Overall process of data partitioning and import
2.3 分布式空间查询处理算法
对于分布式的空间数据库而言,它是由N台高性能计算机所构成N个数据库节点,这些数据库节点构成并行的数据库服务器集群。但是对于客户端而言,则是作为一个整体提供空间数据库查询服务[16]。以空间范围查询为例,它是给定多边形查询区域R和空间对象集M,进行查询时就是查找M中所有与R相交或者被R包含的空间对象[17],其遍历算法伪代码,利用空间索引范围查询伪代码分别见表1,表2。

表1 遍历范围查询算法伪代码Tab.1 Traversing range query pseudo code

表2 范围查询算法伪代码Tab.2 Range query pseudo code
在分布式空间数据库中的并行处理空间范围查询主要是将集群分成一个主节点和若干个从节点,主节点不存储数据只是用来存储数据的元数据信息,当主节点接收到命令后,并行的分发到从节点中,从节点在各自的数据库中执行主节点分发的命令,并将结果返回至主节点,由主节点将结果汇总后返回给用户[18],图3展示了集群对于用户所给定查询的处理过程。

图3 查询处理过程Fig.3 Query processing
3 实验结果
为检验集群在处理空间数据集,尤其是范围查询方面的性能,实验针对两种不同的环境,即分别配置有5个节点的集群数据库和单节点的数据库,对比分析了上述两者在真实数据集以及虚拟数据集下的数据导入、空间范围查询、并发查询的性能。
3.1 测试环境与测试数据集
测试平台的集群机器是由4个从节点1个主节点组成,所有节点都在Centos7.1操作系统下运行。每个节点分别部署了Postgresql以及PostGIS空间数据库。实验采用了两个数据集:分别是某地区的面矢量数据集以及随机生成的点数据集,具体的硬件配置以及数据集具体参数分别参见表3及表4。
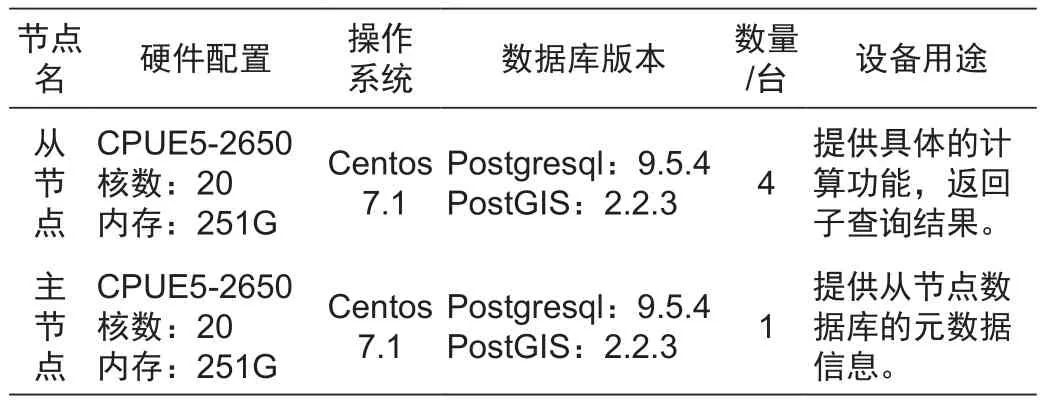
表3 测试环境Tab.3 Testing environment

表4 实验数据集Tab.4 Experimental data sets
3.2 实验结果
3.2.1 空间数据并行导入性能比较
矢量数据的并行导入是利用单客户端多线程并发读取空间数据片段到从节点空间数据库中,对面数据集和点数据集使用不同的导入方法的性能比较如图4所示。

图4 数据导入性能Fig.4 Data import performance
图4 中,是串行导入和并行导入方法性能对比。从图中可以看出,两个数据集,并行导入性能提升约是串行导入方法的3倍,所以通过将大数据集分割后直接导入子节点中,可以降低数据导入的时间,提高数据加载的效率。
3.2.2 空间数据划分方法性能比较
对空间数据划分方法的性能比较,主要是比较了:按照地理坐标进行排序的范围划分,按照数据集本身的主键进行排序后的划分,对地理坐标值进行哈希划分以及对主键进行哈希划分这4种方式。图5(a)反映了对面数据集采用4种方法进行的20次随机大小的范围查询,图5(b)显示的是对点数据集进行20次随机范围查询所用的平均时间。为了减少其缓存的影响,对于每一个随机范围框查询均做了6次,去掉第一次的结果对后5次结果取平均作为其最终的执行时间。同时为了降低其他因素的影响,本次划分只将数据集分成了4份并行的导入到四台从节点的数据库中。
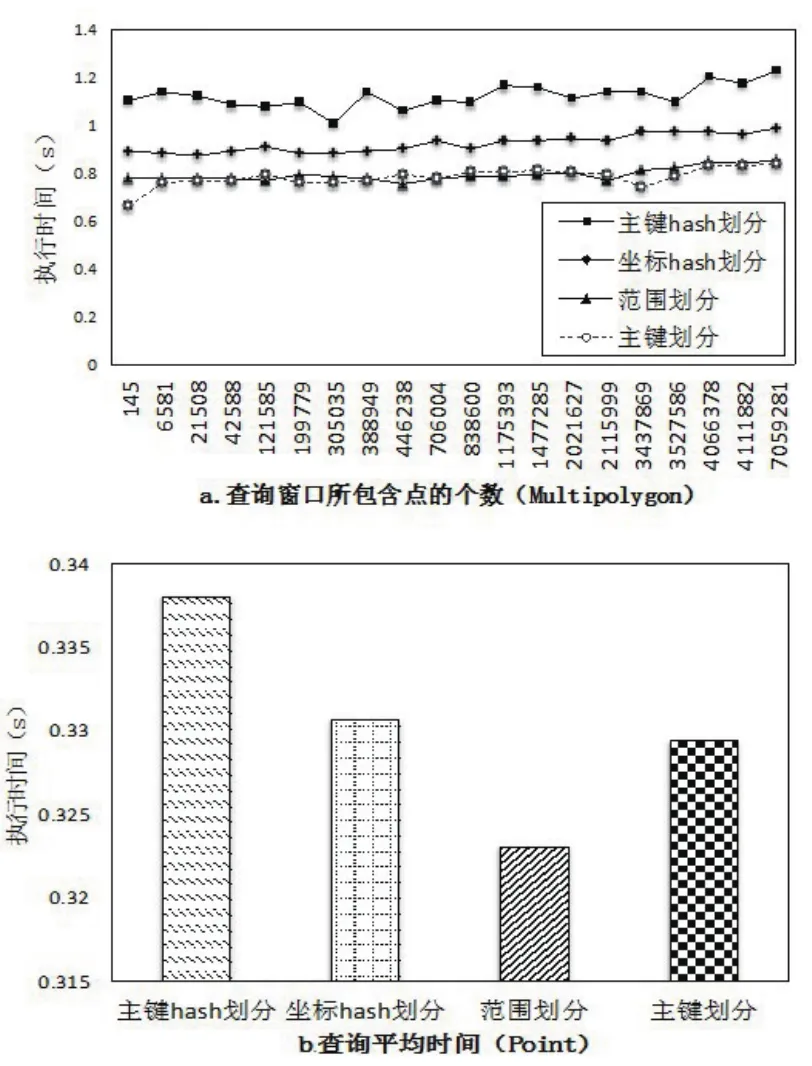
图5 数据分片方式对性能的影响Fig.5 Eあect of the data slice method on performance
根据图5可知,就范围查询而言,根据范围划分的分片方式要优于其他的分片方式。这是因为依据地理坐标的范围划分保留了数据的空间邻近性,所以当进行范围查询时,使得查询框落在了较少的节点中,减少了需要与主节点进行通信的从节点的数目,降低了其开销,使得其查询性能较高。
3.2.3 空间数据分片大小性能比较
图6反映了对面数据集以及点数据集使用范围划分的分割方法时,分片数目对其查询性能的影响。
由图6可知,对于面数据集而言,当分片数目是40~60个时,即CPU核数的3倍左右时,其查询性能最优,而对于点数据集而言,其性能最优处的分片数目可达CPU核数的4倍。这是因为单个CPU核可同时处理2~4个任务,所以,当分片数目是CPU核数的2~4倍时能够最大效率地利用CPU,使得其性能较优。

图6 数据分片数量对性能的影响Fig.6 Eあect of the data slice number on performance
3.2.4 空间范围查询性能
本实验旨在比较单机与集群在单个范围查询时的性能,因此将集群中的数据进行最优分配后,对单机以及集群中的数据集根据其地理坐标列构建了GIST索引,分别对单机无索引、集群无索引、单机有索引、集群有索引4种情况随机选取不同大小、位置的20个查询窗口,以验证其在空间范围查询上的性能表现。图7是对两个数据集进行了随机,不同大小、位置的查询窗口采用count(*)聚合函数作为返回结果的查询时间。

图7 空间范围查询Fig.7 Spatial extent query
通过上述实验可以看出在查询窗口所包含的对象数目较小时(对于面数据集选择率小于30%,对于点数据集则为小于25%时),在单机构建索引后的查询性能要略高于集群,选择率越小,查询性能差异越小。但是随着选择率增大,所返回点数的增多,并行查询性能较串行查询性能最多可提升接近10倍,而单机构建索引后的查询时间与未构建索引的单机相比并没有改善。
3.2.5 并发性能比较
本实验主要是编写程序来模拟多个用户对数据库进行并发的随机窗口查询操作,图8描述了两个数据集中的数据在集群中未复制,复制1份,复制2份进行分布后以及数据集在单机中分布后对并发查询的性能比较。
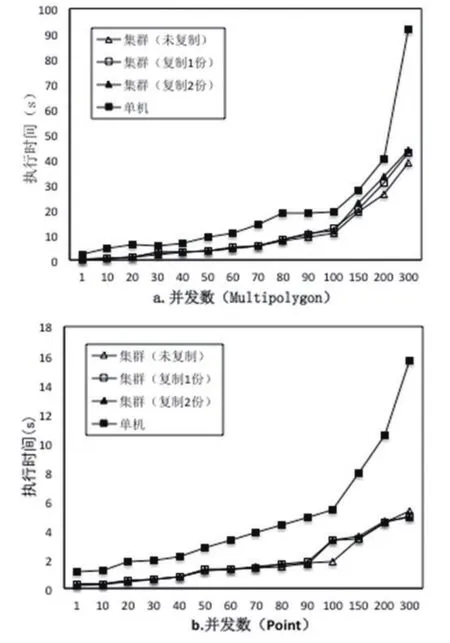
图8 并发性能Fig.8 Concurrent performance
从图8可以看出,不论是在面数据集还是点数据集中,集群因为在并发查询中分担了数据库的整体压力,所以其并发性能都明显优于单机,在相同并发请求时,集群查询响应性能至少为单机响应性能的2倍。但是为其创建副本后,并不会对并发性能带来更多提升,因此对数据进行副本复制操作,主要是提高了数据库的容错能力。
4 结束语
在空间数据库的基础上,设计并实现了基于Geohash划分方法的分布式空间数据库集群,基于该方法实现了空间数据在集群的并行导入。实验表明,并行导入方法具有良好的扩展性,随着集群节点数的增加,导入性能也相应增加。当选择率大于30%时,该分布式空间数据库集群的查询处理能力较单机数据库能够提升10倍左右,满足了在空间数据日益增长情况下对查询性能扩展性的要求。此外,4个节点的空间数据库集群的并发性能较单机数据库提升2倍,表明采用空间数据划分方法后有效提高了集群的扩展性。
下一步将结合分布式内存空间数据库,进一步提升集群的扩展性。实现更丰富的查询处理策略,以支持时空大数据背景下的高效空间分析。同时考虑合理的空间数据副本分布及部署策略,提高数据库集群的可靠性。
