基于评论短句计算特征的观点挖掘
2017-10-16王倩乐山职业技术学院
文/王倩,乐山职业技术学院
基于评论短句计算特征的观点挖掘
文/王倩,乐山职业技术学院
为提高产品评论挖掘的准确率,本文通过计算细粒度属性词和程度副词以及情感词的词汇的语义倾向度,设计了一种结合权重和评论短句计算特征的粗粒度情感倾向分析方法,由细粒度到粗粒度判定web评论的情感倾向性。本文设计了一种基于评论短句计算特征的情感分析方法,把结合属性词和副词权重计算方法的结果进行二次分类,结果表明相对于直接分类或细粒度的情感分析结果,本文设计的结合权重和评论短句计算特征的情感分析方法,分类效果有所提升。
属性提取;评论短句;观点挖掘;语义倾向度
引言
随着互联网和计算机技术的快速发展,国内外电子商务公司也得到了迅猛发展,网络购物成为很多人购物的重要方式。在实际应用中,利用观点挖掘技术能发现顾客的喜好及商品的不足之处,能够使商家改善服务质量,提高商品性能,并且其他用户也可以根据分析结果进行是否购物的参考。在中文评论挖掘中,情感倾向分析一般有词典方式和分类算法两类。词典方式是根据词汇的语义倾向性加权扩展到整句,在语义的基础上研究;分类算法利用现成的工具提取特征,使用分类算法进行分类。基于词典的方法准确率较高,但依赖性较高。而基于分类算法的普适性相对较好,缺点是在分类特征不明显时,容易造成误判。单一采用上述的某一种算法的准确率不高,因此结合两种方法进行分析,,即使用评论短句这个计算特征,送到分类器中进行二次分类,提高判定结果的准确率。而在这个过程中,基于词典的情感分析方法通过对词汇的极性和权重的计算,谋求整句的情感倾向。因此,研究的开始,词汇的极性和权重成为研究的重点。
1 分析
使用TF或者TF-IDF算法作为属性词权重的方法忽略了属性词与属性词之间对于用户而言也存在着不同的重要程度,文献[1]采用出现次数的比例作为属性词权重的方式简单易行,忽略了当出现次数的比例较小时,容易趋向于0而导致属性词之间的区分度不高。程度副词的权重研究基本直接使用知网发布的情感词集bata版中的副词词典,通过根据语感直接对其赋值的方式进行。
2 前期准备
评论是使用网络爬虫下载的电商网站的评论,对评论进行初步去噪。本节主要介绍算法的前期准备工作,包含情感词、属性词、评论短句提取过程,为算法的实现提供重要的基础准备过程。1、提取情感词存入本地数据库中进行处理,主要有以下3类:评价性的形容词;情感动词;网络新词。2、属性词一般是名词或名词短语,在提取候选属性词时,对候选的属性词用频数模型进行筛选,出现的次数降次排列,滤除少于3次的名词。将附近位置存在情感词的属性词提取为候选属性。实验表明窗口长度阈值选为5。
3 提取评论短句
评论短句则指忽略次要因素,从纷杂的词汇群中直接取出能够明确表达评论者的情感倾向和主观感受的句子。中文评论挖掘领域的研究者通过分析中文表达方式,从短语搭配的角度考虑提取过程。如侯敏等人[1]归纳总结出的普通词和评价词的组合搭配问题,分析了评价词语的情感倾向。林政等人[2]则考虑了句子的位置信息,将句子分为关键句和细节句,从他们的研究工作得到启发,结合商品评论的短文本分类的特点,本文采用规则模板的方法提出评论短句。通过对评论句的详细归纳和归总,提取以下四种规则模板:
(1)情感词单独成句、情感词叠加
模板的表达方式:sent,sent+sent;如“不错”、“小巧可爱”;
(2)包含属性词、程度副词及情感词的规则模板
模板的表达方式:feature+adverb+sentiment,adverb+senti⁃ment+feature;
经典的表达模式,涵盖了描述对象、强度修饰、情感表达三个方面的内容。如“外观很漂亮”、“很不错的东西”等;
(3)包含属性词、情感词的规则模板
模板的表达方式:feature+sentiment,sentiment+feature
如“产品不错”、“粗糙的做工”等;
(4)包含程度副词和情感词的规则模板
模板的表达方式:adverb+sentiment,adverb+sentiment;
常用的表达模式,涵盖了强度修饰、情感表达的两方面的内容,尽管没有直接出现属性词,隐含了描述的对象为产品本身,因此需要提取。例如“很喜爱”、“不好”等;以上四种规则模板表达方式可以提取八种表达方式,涵盖了大部分的中文评论的表达方式,对于相对表达比较规范的商品评论而言,能够提取大部分的中文表达。
4 权重设置
4.1 属性词权重设置
属性词的权重设置主要解决分句的极性一正一反时,情感极性的倾向值。如对于评论句“相机像素很差,但是价格很好”类型的句子,使用均一的权重衡量方式就不能正确的检测出来,判定的结果为0;本文设计的属性方法可以判定出其极性倾向值。
4.2 程度副词权重设置
本文在侯敏等人研究的基础上进行改进。首先对知网情感词典中的程度级别词语进行人工赋值,以此作为基准副词。对于给定副词,作如下考虑:先查找基准程度副词表,若该副词存在表中,直接取出其权重;若不存在,则使用语义相似度计算,先计算该副词与全部基准副词的语义相似度,取计算的语义相似度值最高的10个值(Top10)的均值,作为该副词的权重。
4.3 评论短句极性计算
根据我们在第2节的采取的规则模板方法提取出的评论短句,在数据库中查询各评论短句对应的相关词汇的权重,计算评论短句的极性,最后加权求和得到最后的整句的情感倾向,有以下规则:
(1)如果是在评论短句之内的,也就是处在同一个评论短句之内的词汇的权重值进行加权乘积,如果在一个评论短句内的词语数为m个,分别找出它们的权重值wt(wordj),进行加权乘积:

其中,word(j)指评论断句中的第j个词语,j=1,2,3…,m;m指该评论短句中包含的词语数,wt(word(j))第j个词语对应的权重值。
(2)由于在一个整句的评论句中,不止包含一个评论短句,设有n个评论短句,依照公式1分别求出每一个评论短句对应的极性值,wt(fs)1、wt(fs)2…wt(fs)n,对这些评论短句加权求和,最终得到整句的情感倾向计算值Wt(sentence)为:

其中,Wt(sentence)指整句的最终情感极性倾向值,n指一个整句中所有评论短句的个数,wt(fs)i指第i个评论短句的情感倾向权重值,i=1,2,3…,n。
5 利用fs计算特征的情感倾向分析
5.1 分类器特征提取
综合以上分析以上算法的优缺点,算法在普适性、分类的准确度方面有缺陷,且有人工参与,因此为了提高算法的普适性和分类的精度,减少人工干预度,从提取句子特征的角度对评论进行倾向性分析。归纳出了三类特征,这三类特征的来源的示意图如图1所示。
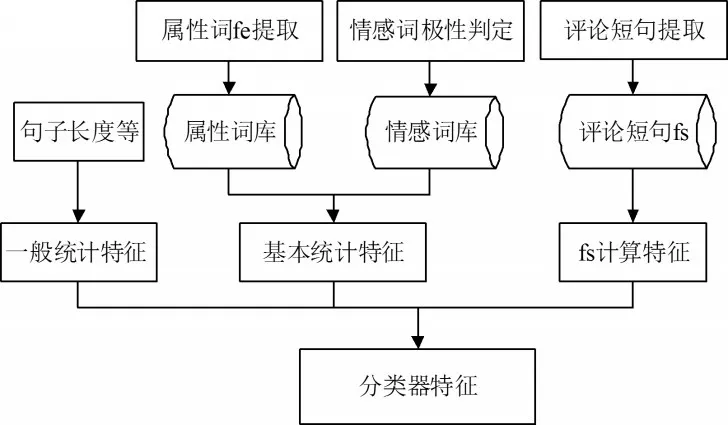
图1 分类器特征来源示意图
5.2 结果分析
5.2.1 数据集
实验使用的数据集Dataset1是从本地已下载评论中随机抽取的不同领域商品的评价信息,考虑了数据集的平衡性,各抽取正负极性的句子3016条,合计6132条。
数据集二Dataset2是混合数据集,包含COAE中文倾向性评测公开的微博的数据集和1000条电商网站的商品评论信息,共计3152条,混合数据集综合考虑了微博类和电商网站的商品评论信息,相对单一考虑电商网站的商品评论信息而言,更具有代表意义。
5.2.2 使用评论短句计算特征对结果的影响
在Dataset 1和混合数据集Datase 2上进行了实验验证,将评论短句计算特征作为分类算法的特征送入分类器中,结果如表1所示:实验结果表明,加上fs计算特征后,在各分类算法上分类都有所提升,说明我们提出的结合fs计算特征的有效性。

表1 评论短句特征在Dataset2上的影响
6 结论
本文主要研究产品评论情感倾向的判定,为了提高分类的准确率,本文中结合属性词和副词权重的情感倾向分析方法的基础上设计了一种利用评论短句计算特征的情感倾向分析方法,在不同的数据集上进行了实验验证,结果表明设计方法的有效性。本文设计情感倾向性分析方法仍然存在着不足之处,如在负面评价的判定上有着准确度不高的问题,规则模板提取评论短句的方法还存在着覆盖不全的缺点,对多极性的情感分析未能在其他数据集上进行验证等等问题,需要在未来的研究中进一步改进。
[1]侯敏,滕永林,陈毓麒.评价短语的倾向性分析研究[J].中文信息学报,2013,27(6):103-109.
