基于词包模型和SURF局部特征的人脸识别
2017-09-01刘翠响李敏张凤林
刘翠响,李敏,张凤林
(河北工业大学 电子信息工程学院,天津市 300401)
基于词包模型和SURF局部特征的人脸识别
刘翠响,李敏,张凤林
(河北工业大学 电子信息工程学院,天津市 300401)
针对传统人脸识别方法实时性差的缺点,提出了一种加速鲁棒性特征(SURF,speed up robust features)和词包模型(BOW,bag-of-word)相结合的人脸识别方法.图像经过预处理后,使用SURF算法自动提取图像的关键点和相应的特征描述符,再进一步用BOW方法将其编成视觉单词作为人脸的局部特征.最后,采用K最邻近结点算法进行分类识别.使用了2个数据集验证了提出的方法——标准CMU-PIE(卡内基梅隆大学——姿势、光照、表情人脸数据库)人脸库和采集的数据库,分别达到了97.5%和99.3%的识别率,而且特征提取的时间少于0.108 s,识别的时间少于0.017 s.结果表明,本文提出的算法不仅精确而且快速,具有更好的稳定性和有效性.
人脸识别;词包模型;SURF;局部特征;K-NN
由于人脸会受到姿势、面部表情或者光照等的影响,所以人脸识别是一项非常具有挑战性的技术.除此之外,人脸表示经常要求多个维度,这就更加加剧了人脸识别的艰巨性[1].
传统的人脸识别方法对表情、光照和尺度的变化非常敏感,当人脸图像发生较大改变(比如旋转)后,识别率就会急剧下降.近几年,研究者介绍了很多应用在人脸识别领域的局部特征提取算法,例如,尺度不变特征变换(SIFT,scale invariant feature transform)就曾得到广泛应用[2].尺度不变特征变换[3]作为一种局部特征描述算法,计算简单,识别有效,且具有尺度和旋转不变性.2006年后,SIFT算法被用于人脸识别领域[3-5];然而这种算法计算复杂度高,不能在实时系统中得到更广泛的应用,且非常容易受光照变化的影响[6].为此研究者提出了很多基于SIFT算法的改进算法,以便于该算法更能适用于实时系统.比如,kd树被应用在寻找K最近邻的领域,指出PCA可以减少SIFT算法提取特征的维数[7].但是,由于人脸的特殊位置尤其是人脸边缘的关键点很难被找到,从而得不到较高的识别率,所以这类方法仍然达不到实时系统的要求.为了解决SIFT算法计算复杂度高的问题,2006年,Bay等[8]提出了SURF算法,并将其用于图像匹配领域.该算法不仅在尺度、光照和旋转方面具有较强的鲁棒性,而且在速度上远远超出了SIFT算法.在对室外自然图像的匹配结果表明,SURF算法的运算速度比SIFT算法快将近3倍,并且整体性能有着SIFT算法不可比拟的优越性[9-10].2009年,Du等[5]首次将SURF算法应用在人脸识别领域,提出基于SURF算法的人脸特征方法.2010年,Kang等[10]利用SURF算法的旋转不变性,将待测试的人脸图像经过旋转处理后,形成了新的测试样本,使得人脸识别的效果得到有效提高,但这仅是对SURF算法的简单利用.总体来说,上述基于SURF提取人脸图像特征的方法,虽然都在一定程度上提高了人脸的识别率,但提取的人脸特征关键点分布不均,并且对光照变化鲁棒性较差.
词包模型(BOW)是最近几年常用的图像特征分析方法之一,最开始被应用在处理自然语言或者检索无序的词语归类以及词序的信息[11]中.最近,词包模型在计算机视觉中得到有效利用,比如目标识别、图像分类和图像检索[12-13].在词包模型中,用有序的视觉单词表来表示图像特征,实验检验证明,词包模型可以很好地应用在图像分类中.但是词包模型往往容易忽略图像的整体信息,以至于会对其分类的正确率造成影响,所以要想提高词包模型的准确率和鲁棒性,需要找到一个更好的特征提取方法.
基于此,本文提出了一种准确快速的人脸识别方法——基于SURF局部特征和BOW算法的人脸自动化识别研究.在对人脸图像预处理后,将人脸图像统一尺寸,用SURF提取局部特征.然后,将SURF算法提取的关键点和描述符用BOW重新编码作为局部特征.最后,在识别人脸类别时,将SURF和BOW提取的局部特征放入K-NN算法中,将K个最近邻构建新的判决空间,识别人脸的类别.在CMU PIE(卡内基梅隆大学)标准人脸数据库及在实验室采集的真实身份人脸库上分别进行了实验.结果表明,本文采用的SURF和BOW结合的方法不仅在特征提取时速度快,而且在匹配识别时也很迅速.在CMU PIE标准人脸库和采集的人脸库上分别达到了97.5%和99.3%的准确率,特征提取的平均时间为0.108 s,识别的平均时间为0.017 s,识别一幅图片的平均时间仅为15 ms, 满足实时系统的快速准确的要求.
1 基于SURF的人脸特征提取算法
1.1 SURF特征点检测
SURF是一种旋转和尺度都不变的局部特征检测子,由于引入了积分图像,大大提高了图像的特征提取速度.对于一幅二维图像,通过高斯核卷积来构造不同的尺度空间:
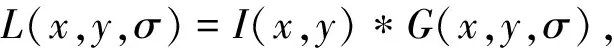
(1)
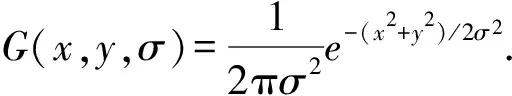
SURF特征点的提取使用的是精确高的Fast-Hessian检测子,在确定特征点的位置和选择尺度时,本文选择了相同的尺度.在图像中的点X处,尺度为σ的Hessian矩阵为
(2)
但SURF在计算H矩阵时,用箱式滤波器代替了高斯二阶导数,这样SURF算法在计算卷积时就可以使用积分图像,加快了计算速度.
对于积分图像中某点X(x,y),可以用图像中原点与点X形成的矩形区域内所有像素值之和来表示积分面积I∑(X),如式(3)所示.
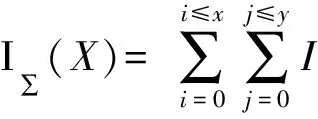
(3)
在如图1所示的积分图像中,用3个加减运算即可求得矩形区域G的灰度值之和,即G=D-B-C+A,与矩形G的面积无关.
为了更加准确地逼近高斯核函数,Bay等提出以盒子滤波来近似高斯的二阶微分.9×9的箱式滤波器如图2所示.
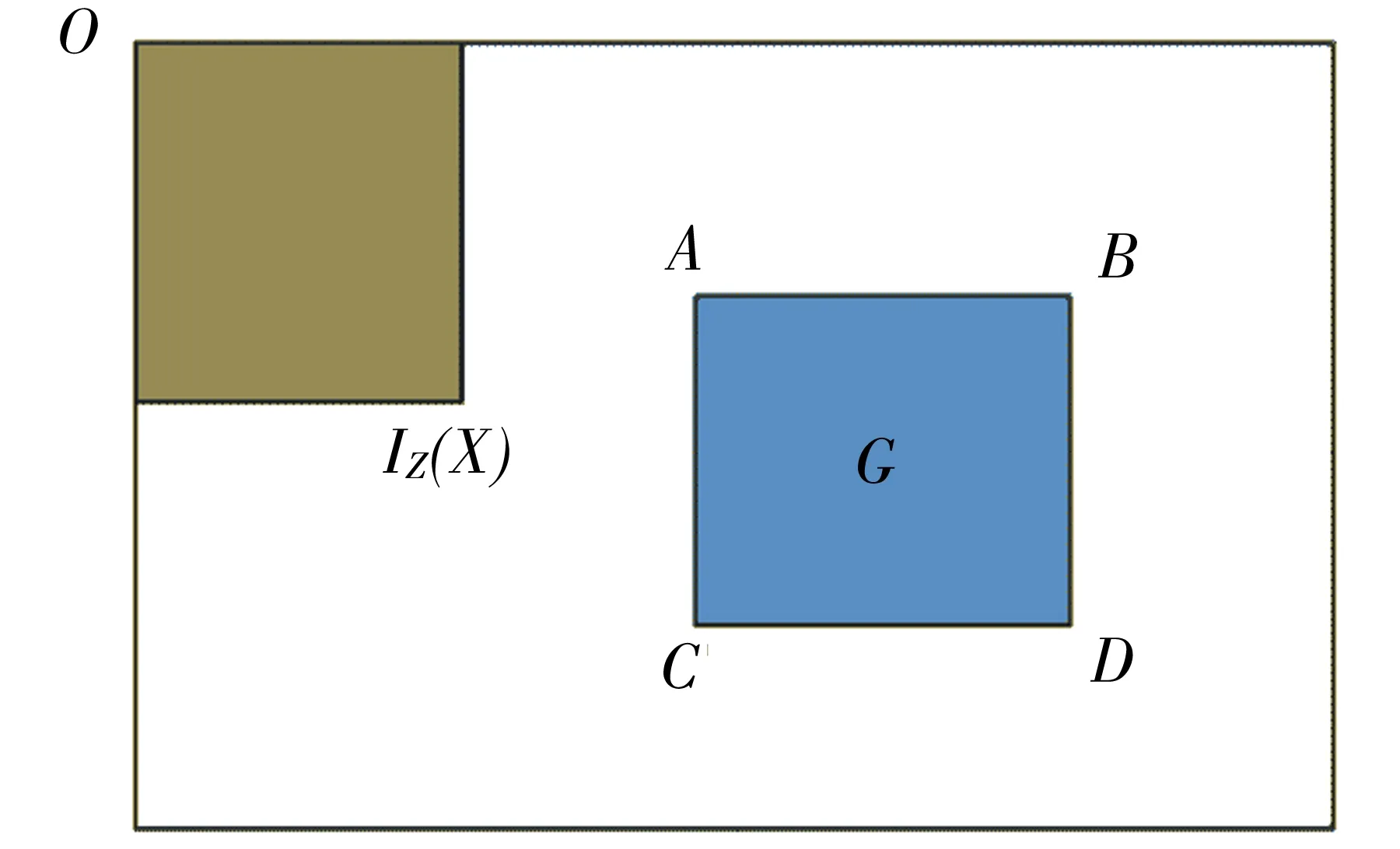
图1 积分图像Fig.1 Integral image

图2 y方向的箱式滤波器(灰色部分等于0)Fig.2 y direction box-type filter(the pessimistic part is equal to 0)
用它来代替σ=1.2的高斯二阶导数,这是SURF的最小尺度和最高的空间分辨率.用Dxx,Dyy,Dxy近似表示图像和高斯二阶导数的卷积Lxx,Lyy,Lxy.在计算H矩阵的行列式值时,为了提高计算效率选择了一个权值
(4)
|X|F表示F范数.于是得到了H矩阵的行列式值的近似表达
(5)
为了确定图像关键点的具体位置,在一个3×3×3大小的近邻区域采取非最大值抑制的原则,选择Hessian矩阵行列式的最大值所在的图像和尺度空间的位置作为特征点的位置.在寻找特征点的位置时,为了增加关键点的抗噪声能力,需要舍弃对比度较低的极值点或者边缘不稳定的相应点,然后就能得到相对稳定的特征点位置.
1.2 SURF特征点描述和计算
SURF算法在提取了特征点后,结合特征点周围的一个圆形区域内的信息,给特征点添加一个方向,然后根据该方向创建一个方形区域,在该区域提取SURF描述符.
为了保证SURF算法的旋转不变性,首先以特征点为中心,在半径为6s(s是特征点所在的尺度空间的尺度值)的圆形区域内计算各点在x、y方向的Haar小波响应.在计算时,同样使用积分图像来加快计算的速度.小波变换计算出来后,用σ=2.5s的高斯函数进行加权,使得离特征点近的响应贡献大.最终小波响应被表示成一个向量,该向量包括小波响应的水平信息和垂直信息.主方向通过计算一个角度为π/3的滑动窗口内的小波响应的和得到.这时同样需要分别计算水平和垂直方向的响应,这就产生一个新向量,最长向量的方向即为特征点的主方向.对每个特征点逐个进行计算,就能得到所有特征点的主方向.
为了得到SURF描述符,首先在提取的特征点附近建立一个20s的方形区域,将前一步计算的主方向作为其方向.建立的方形区域被划分为4×4的子区域,对于每一个子区域,计算5t×5t(采样步长取t)范围内的小波响应.为了简化描述,将Harr在水平方向的响应记为dx,在垂直方向的响应称为dy,这里“水平”、“垂直”都是相对于特征点的方向来说的.为了提高描述符对于几何变换的鲁棒性,首先赋予dx和dy以权值系数,然后将每一个子区域内的dx、dy相加,形成子区域特征向量的前2个组成部分.为了使特征描述符具有强度变化的极性信息,将dx和dy的绝对值也加入了特征描述符.因此,每一个子区域的底部,形成了一个四维分量的矢量v,v=(∑dx,∑dy,∑|dx|,∑|dy|).因此,所有的4×4个子区域的描述符,合起来形成4×(4×4)=64维的描述向量,因此,最终的SURF描述符是一个64维的向量.
1.3 SURF提取的人脸特征描述符计算
首先,将人脸图像经过归一化处理后,将图像变成同样的尺寸.然后利用SURF算法提取人脸的关键特征点,计算该点的64维特征描述符.
图3是一幅人脸图像经过预处理后得到的SURF局部特征描述符.

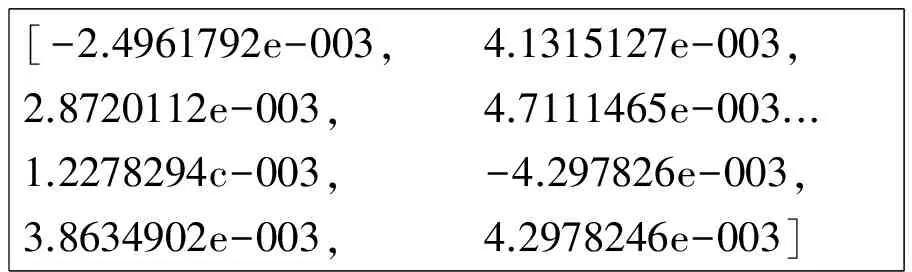
图3 人脸的局部特征描述符
Fig.3 SURF partial characteristic description symbol
2 Bag-of-word(BOW)算法的局部特征计算
本文应用经典的Bag-of-word(BOW)算法[14]将SURF算法提取的关键点和描述符重新编码作为局部特征.得到所有特征点的特征向量后,需要对特征点进行分类.纵观最佳的分类方法,K-means[15]算法在众多研究领域得到广泛应用.该算法不仅拥有更好的分类效果,而且计算速度非常快.因此本文采用的分类方法是K-means聚类算法.K-means算法可以有效处理大型数据集,是硬聚类算法,终止于局部最优.K-means算法是一种基于点对称的非数字距离测量方法,优化目标函数是数据点到原点的距离.它将观察值划分成K类,拥有相似特征的观察值属于同一类.在本文中,采用欧氏距离来表示相似度,也就是说,聚类准则函数的表达采用误差平方和.
建立BOW模型主要分为2个步骤:第1步,将提取的所有训练图片的SURF描述符和相应的关键点,利用K-means方法聚类.用汉明距离作为度量标准估计2个SURF描述符之间的距离.在K-means方法中,计算每一个聚类中心和描述符之间的距离.在BOW模型中,每一个聚类中心都代表一个bin,称这些bin为视觉词汇.因此,第1步的目的就是构建视觉词汇.得到的一系列视觉词汇,用W={w1,w2,w3…}作为目标表示.BOW模型就由这些视觉词汇构建而成.
由K-means聚类得到的这些视觉词汇,在第2步中,输入的SURF描述符可以由相应的视觉词汇描绘出来.在所有的视觉词汇中有一个最小汉明距离,如式(6).
(6)
公式(6)中的t表示SURF算法提取到的特征,通过将所有计算得到的SURF描述符绘制成相应的视觉词汇,最终可以得到不同的视觉词汇直方图.

(7)
其中,Di是视觉词汇的频率.由于图像之间提取的SURF特征点的数量不同,所以由公式(7)得到的视觉词汇直方图标准化为
(8)
BOW词典构建的M个视觉词汇用L=[b1b2…bM]来表示.因为BOW模型基于提取的SURF局部特征,所以在本文中被称为人脸局部特征.在K-means算法中,质心初始值的选取十分关键.质心初始值如果改变,聚类准确率也会随之改变.在本次研究中,初始值的位置通过多次实验来获得.如果在实验中能得到很好的聚类效果,就记录下这个初始值的位置.那么在下次实验时,就可以直接使用这个初始值.利用K-means算法分类所有的特征点,然后用直方图来表示图像的词包模型.每一类都会存在质心,则词包模型每一类的特征就用这个质心的特征向量来表示,那么这些特征向量就构成了需要的词包模型的字典.结果,一个单位直方图代表一幅人脸图像,
如图4所示,即为得到的2组不同类型的测试人脸的BOW表示.
图4 2组不同类型的测试人脸的BOW表示Fig.4 Two different person face type of BOW indicated
3 人脸分类识别算法K-NN
在识别人脸时,使用K-NN算法.K-NN如图5所示.图5描述了在SURF局部空间使用K-NN判断一幅图片(圆形)为正方形或者三角形的过程:1)圆形在SURF局部空间采用K-NN计算K(K=2,2个三角形)个最近邻;2)这K个最近邻形成的判决空间中,全部为三角形,因此判定圆形所属类型为三角形.在选择K的具体值时,需要反复测试选择出最佳值,使得最终判决的准确率最高.
在人脸识别时,提取输入人脸图像的SURF局部特征,使用K-NN从SURF局部空间计算K个最近邻,在形成的判决空间中,使用K-NN根据距离的远近判断输入人脸图像的类别.
本文算法的整体流程图如图6所示.

图5 K-NN识别Fig.5 K-NN recognition
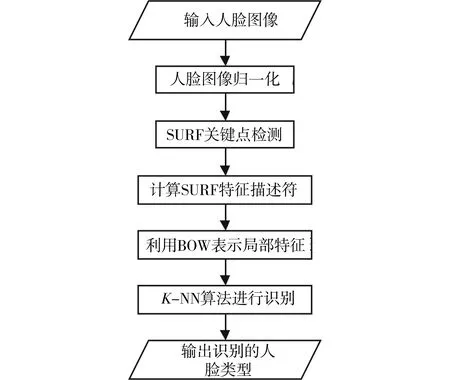
图6 人脸识别流程Fig.6 Face recognition flowchart
4 实验结果及分析
在CMU PIE标准人脸数据库及本研究室的真实身份证人脸图像上进行实验,并与经典的SIFT、传统的SURF进行比较.实验首先对输入的每一幅人脸图像,用SURF和BOW算法提取局部特征,并用K-NN算法进行识别.
4.1 人脸图像库描述
CMU PIE库:该人脸库内含68位志愿者的人脸图像,总共41 368张,来自不同姿态、光照和表情.所有人脸图像的面部关键特征都比较规范,为标准的人脸库.从CMU-PIE人脸数据库中选择了50个人(共1 500幅图像),这些人脸图像的光照、姿态、表情各不相同.在选择的1 500幅图像中1 000幅用于训练,500幅用于测试.图7为CMU PIE人脸图像库部分样本.
真实身份证人脸库:训练集为本实验室成员的真实身份证人脸图像,共15人,图像大小为150×200;测试集为无约束环境条件下采集的每人10幅相应的人脸图像.图8为真实身份证人脸库部分样本.

图7 CMU PIE人脸图像库部分样本Fig.7 Partial samples of CMU PIE human face image storehouse

图8 真实身份证人脸库部分样本Fig.8 Partial samples of real status witness face storehouse
4.2 实验及参数设置
在K-NN分类时,K值的大小需要仔细选择,由于没有严格的理论依据,通过重复实验的方式进行参数设置,见表1.

表1 标准测试集不同K值的识别结果
经不断实验,选定K=2,此时使用K-NN的准确率最高.最后共K=2个最近邻放入K-NN进行最后的分类,确定人脸的类型.由实验的结果判断,提出的方法每幅图片提取特征的平均时间为108 ms,识别的平均时间为17 ms,特征提取时间和分类所需的全部时间少于130 ms,实验结果表明本文提出的方法可以用于实时人脸的识别.
4.3 实验结果及分析
实验1: 在CMU PIE标准人脸库下的实验.
对SIFT、ORB、传统的SURF和本文算法分别进行测试,实验结果见表2所示.通过比较时间和识别率可知,本文算法明显由于其他算法.

表2 在标准人脸库上的性能
实验2:真实身份证人脸库下的实验.
选择身份证人脸图像作为训练样本,实际采集的人脸图像作为测试样本.将采集的人脸图像在经灰度化处理后,转化为200×150的图像,然后用SURF和BOW算法提取局部特征,并用K-NN算法进行识别.同样,经过测试,选定在SURF局部空间计算K=2个最近邻,最终这2个最近邻由K-NN做最后的判断,判断输入人脸属于哪一类.
实验结果见表3.

表3 真实人脸身份证库下的识别结果对比
从表3可以看出,本文算法相比其他算法,优势明显,识别率最高.
实验3:为了更好地判断算法的性能,在MATLAB上进行了仿真实验,分别对SIFT、ORB、传统的SURF与本文算法进行了性能测试,进一步验证了本文算法的优越性.仿真结果如图9-11所示.
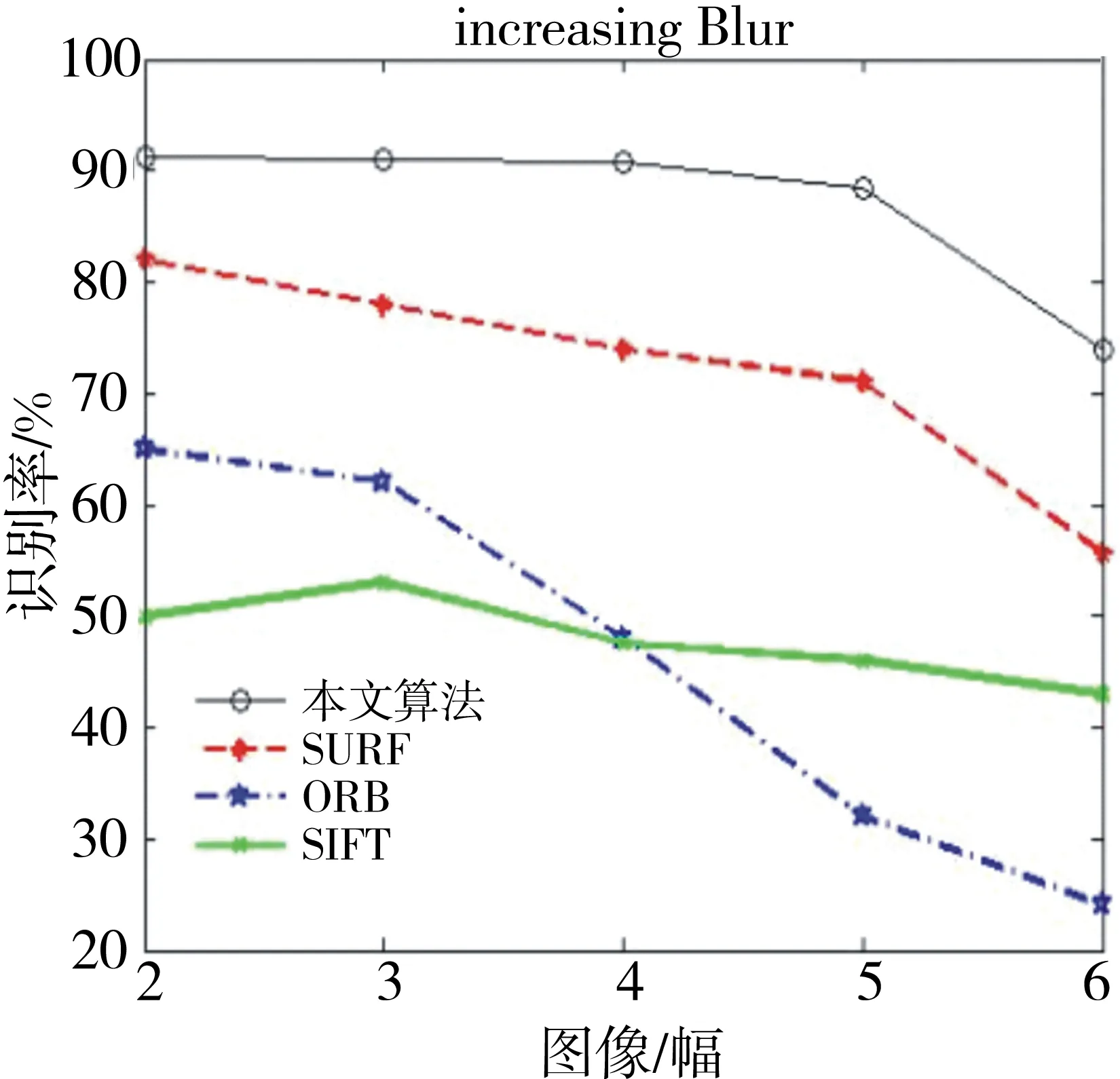
图9 高斯模糊性能比较Fig.9 Comparison of gauss fuzzy performance
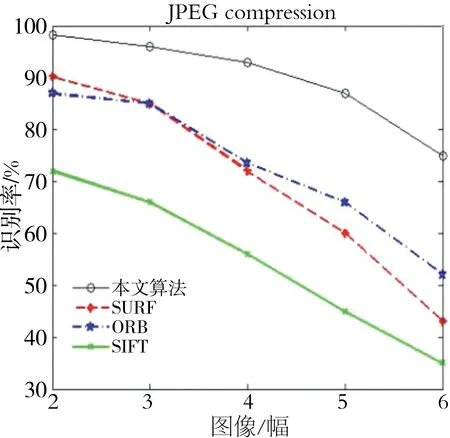
图10 压缩性能比较Fig.10 Comparison of compression performance
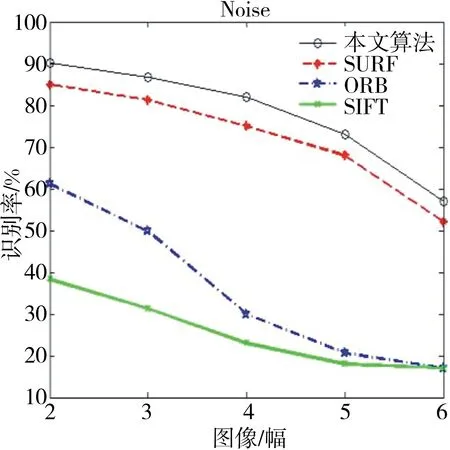
图11 抗噪性能比较Fig.11 Comparison of anti-chirp performance
该仿真实验是将6幅图片进行模糊处理、压缩处理、噪声处理后,再利用这4种算法分别进行分类识别,得到相应的识别率.由MATLAB仿真结果可知,本文算法在对图像的模糊性、压缩性和抗噪性能上,都具有很好的优越性.
5 结束语
本文提出了一种SURF算法和词包模型相结合的人脸识别方法.首先提取人脸的SURF和BOW局部特征,然后运用K-NN算法识别人脸类别.从实验结果可以看出,无论对于标准的人脸数据库还是自己采集的真实身份证人脸数据库,均能取得较好的测试效果.通过实验可以证明新的词包模型有较好的性能,图像分类准确率比原有模型要好.该方法不仅继承了SURF 算法的实时性和鲁棒性,而且还提高了SURF的效率,为今后在其他更加复杂的场景中利用BOW算法进行特定的人脸识别奠定了基础.
[1] SOLDERA J, CARLOS A R B, SCHARCANSKI J.Customized orthogonal locality preserving projections with soft Margin maximization for face recognition[J].IEEE Transactions on Instrumentation & Measurement, 2015, 64(9):2417-2426.DOI:10.1109/TIM.2015.2415012.
[2] ZHANG W Y, HUA L L, DU H R, et al. SIFT: predicting amino acid changes that affect protein function[Z]. International Symposium on Computer Network and Multimedia Technology, Wuhan, 2009.
[3] LOWE D G.Object recognition from local scale-invariant features [J].Computer Vision, 1999, 2(9):1150-1157.DOI:10.1109/ICCV.1999.790410.
[4] LIU C, YUEN J, TORRALBA A.SIFT flow: Dense correspondence across scenes and its applications[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(5):978-994.DOI:10.1109/TPAMI.2010.147.
[5] GENG C, JIANG X D.Face recognition based on the multi-scale local image structures[J].Pattern Recognition, 2011, 44(10):2565-2575.DOI:10.1016/j.patcog.2011.03.011.
[6] 李伟红, 陈龙, 龚卫国.单样本快速人脸不变特征提取方法[J].光电子·激光, 2014(3):558-564. LI W H, CHEN L, GONG W G.Fast facial descriptor extraction for single image based face recognition[J].Journal of Optoelectronics·Laser,2014(3):558-564.
[7] DU G, SU F, CAI A.Face recognition using SURF features[J].Pattern Recognition,2009,7496(28):131-137.DOI:10.1117/12.832636.
[8] BAY H, ESS A, TUYTELAARS T, et al.Speeded-up robust features (SURF)[J].Computer Vision and Image Understanding, 2008, 110(3):346-359.DOI:10.1016/j.cviu.2007.09.014.
[9] DING N N, LIU Y Y, ZHANG Y, et al.Fast image registration based on SURF-DAISY algorithm and randomized kd trees[J].Journal of Optoelectronics Laser, 2012, 23(7):1395-1402.
[10] KANG M, CHOO W, MOON S. Improved face recognition algorithm employing SURF descrpitors[Z]. Society of Instrument and Control Engineers Annual Conference, Japan,2010.
[11] LEWIS D D.Naive (Bayes) at forty: The independence assumption in information retrieval[J].European Heart Journal, 1998, 21(15):1204-6.
[12] LI F F, PERONA P. A Bayesian hierarchical model for learning natural scene categories[Z]. Computer Society Conference on Computer Vision & Pattern Recognition, America, 2005.
[13] YANG J, JIANG Y G, HAUPTMANN A G, et al. Evaluating bag-of-isua-words representations in scene classification[Z].International Workshop on Workshop on Multimedia Information Retrieval, ACM, 2007. DOI:10.1145/1290082.1290111
[14] CHU W T, HUANG C C, CHENG W F. News story clustering from both what and how aspects: using bag of word model and affinity propagation[Z]. The 2011 ACM International Workshop on Automated Media Analysis and Production for Novel TV Services, ACM, 2011.
[15] FENG J, JIAO L C, ZHANG X, et al.Bag-of-Visual-Words based on clonal selection algorithm for SAR image cassification[J].Geoscience & Remote Sensing Letters IEEE, 2011, 8(4):691-695.DOI:10.1109/LGRS.2010.2100363.
(责任编辑:孟素兰)
Face recognition based on BOW and SURF local features
LIU Cuixiang, LI Min, ZHANG Fenglin
(School of Electronics Information Engineering,Hebei University of Technology,Tianjin 300401,China)
To overcome the limitations of traditional face recognition methods for real-time, a face recognition method which based on speed up robust features and bag-of-word model was proposed.Image after preprocessing, we used SURF to extract key points of images and corresponding feature descriptors automatically.Further, bag-of word model was used to code the descriptors into visual words as local features of the face.Finally,K-Nearest Neighbor algorithm was adopted to recognize the human faces.The proposed method is validated with both CMU-PIE dataset and dataset collected in the laboratory.It can achieve 97.5% and 99.3% recognition rates on these two datasets, respectively.In average, it took less than 0.108 s for feature extraction and less than 0.017 s for matching.The results indicate that the proposed method not only precise moreover fast, and had better stability and effectiveness.
face recognition; bag-of-word model; SURF; local features;K-NN
10.3969/j.issn.1000-1565.2017.04.013
2016-09-29
国家自然科学基金资助项目(61203245)
刘翠响(1973—),女,河北辛集人,河北工业大学副教授,博士,主要从事信号处理与模式识别研究. E-mail:liucuix@126.com
李敏(1990—),女,山东德州人,河北工业大学硕士研究生.主要从事图像处理与模式识别研究. E-mail:1607708753@qq.com
TP391
A
1000-1565(2017)04-0411-08
