基于半监督K-Means的属性加权聚类算法
2017-04-14周晓英吴立锋王国辉
潘 巍 周晓英 吴立锋 王国辉
(首都师范大学信息工程学院 北京 100048)(首都师范大学北京市高可靠嵌入式系统工程研究中心 北京 100048)(首都师范大学北京市电子系统可靠性技术研究重点实验室 北京 100048)
基于半监督K-Means的属性加权聚类算法
潘 巍 周晓英 吴立锋 王国辉
(首都师范大学信息工程学院 北京 100048)(首都师范大学北京市高可靠嵌入式系统工程研究中心 北京 100048)(首都师范大学北京市电子系统可靠性技术研究重点实验室 北京 100048)
K-Means是经典的非监督聚类算法,因其速度快,稳定性高广泛应用在各个领域。但传统的K-Means没有考虑无关属性以及噪声属性的影响,并且不能自动寻找聚类数目K。而目前K-Means的改进算法中,也鲜有关于高维以及噪声方面的改进。因此,结合PCA提出基于半监督的K-Means加权属性聚类方法。首先,用PCA得到更少更有效的特征,并计算它们的分类贡献率(即每个特征对聚类的影响因子)。其次,由半监督自适应算法得到K。最后将加权数据集以及K应用到聚类中。实验表明,该算法具有更好的识别率和普适性。
均值 聚类 半监督 主成分分析 属性加权
0 引 言
随着信息技术的快速发展,信息的重要性日益提升,同时信息的冗余也不可避免的大量存在。因此,数据挖掘技术顺势成为了最受欢迎的信息处理学科[1]。
聚类分析是一种应用广泛的无监督方法,在数据挖掘领域中占有非常重要的位置。聚类分析是1975年出现的,Hartigan[2]在他的“聚类算法”一书中详细的介绍了这个算法。随后,基于各种不同思想的聚类算法相继被提出来,包括基于分区、密度、网格以及模式等各种思想。
传统的无监督聚类分析不依赖原始数据集的类别信息,需要由聚类学习算法自动确定,因而聚类结果的精确性并不是很高。其中,K-Means算法以其速度快,稳定性高的优点广泛应用在各个领域,包括工程、经济、电子、地理、统计以及心理等[3]。K-Means算法思想中,聚类数目是需要用户根据先验知识来获得的[4]。这种做法不仅给用户带来了负担,而且由于用户给定聚类数目的随机性,聚类结果的准确性也会在一定程度上降低。此外,无关属性以及噪声属性同样会降低聚类结果的准确性。
在实际问题中,通常可以很容易地获得有限的样本先验信息,这些知识可以调整聚类过程,从而改善无监督聚类算法的性能。
近年来,大量的K-Means改进算法被相继提出。2015年,胡海峰[5]提出了一种基于特征间隙的检测簇数的谱聚类算法,根据数据之间的相似度确定簇数。同年,Jothi R[6],提出了一种使用约束递归的方法得到更精确的聚类中心。2015年,魏建东[7]提出了一种层次初始的聚类个数自适应的聚类算法研究。2014年,Drias H[8]提出了一种结合K-Means和K-Medoids的算法提高了聚类精度。以上算法均未有效地减少特征数量,当特征数量比较大时,聚类结果及速度会受到影响。如果能够在聚类前进行特征降维,将会提高聚类速度。
在特征降维算法中,PCA算法可以说是其中的经典。 PCA 是根据计算原始数据集的协方差矩阵以及协方差矩阵的特征值以及特征向量,选择累积贡献率(CR)比较大的特征向量得到新的向量基,最终将原始数据集投影到新的向量基中。
基于以上研究,如何将K-Means算法融入到半监督理论中选取最佳的K值,以及如何结合PCA提高聚类识别的准确率是亟待解决的问题。本文将PCA引入算法,并且利用半监督自适应的思想去解决自动的选择聚类数目K的问题。改进算法有效地克服了噪声和无关属性对聚类结果的影响以及不可以自动选取聚类数目K的不足,计算效率大大的提高。
1 本文提出的算法
本文提出的基于PCA以及属性加权的半监督聚类算法仅仅依据原始样本训练数据就可以自适应得到聚类数目K,在聚类效果上有着良好的表现。算法可以分为3个阶段。
1.1 第一阶段算法描述
(1) 首先对训练数据集进行PCA降维,得到有效的主特征;
(2) 其次,对主特征计算累积贡献率,并根据累积贡献率对原始数据集进行加权;
(3) 最后得到加权后的数据集。
PCA将会把那些对分类贡献率特别低的一些无关属性以及噪声属性全部剔除掉,根据CR将原始数据集进行属性加权得到二次处理的数据集。首先,进行归一化(xj-min)/(max-min)处理,其中min和max分别代表整个数据集的最小样本和最大样本,经过归一化处理之后,整个数据集所有样本的值都会处于0~1之间。下一步协方差矩阵以及协方差矩阵的特征值和特征向量可根据式(1)、式(2)计算得出,之后降序排列特征值,并且选出CR值大的主成分进行数据集的降维。
协方差矩阵的计算公式如下所示:
(1)

(2)
最后计算CRi和CR,以此作为计算属性重要度的根据。这样根据阶段1就可以得到一个经过属性加权之后的数据集。贡献率CRi和累计贡献率CR可以由以下的公式进行计算得到:
(3)
(4)

1.2 第二阶段算法描述
(1) 首先计算训练数据集的聚类半径R并且选择初始聚类中心C1、C2;
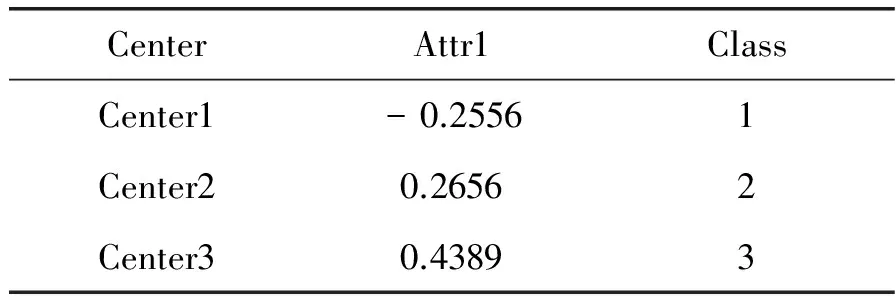
(2) 其次,计算DBI指数,当NDBI (3) 最后,直到当判断结果为否时,得到聚类数目K。 第一步,根据式(5)计算得到训练数据集的聚类半径,式(5)如下所示: (5) 其中,n代表训练数据集的总体样本数,本文定义的新的欧几里得距离的计算式表示为: (6) 为了考虑每一个样本贡献度对聚类结果的影响,在计算欧氏距离的时候,需要将分类贡献率Ri和Rj加入到计算公式中作为一个影响因子,也就是我们在阶段一所说的属性重要度。传统的欧氏距离没有考虑到每个样本属性的不同,从而计算出的距离对于聚类不能起到很好的作用。dij表示样本xik和xjk之间的距离,接下来就是根据距离dij选择下一个聚类中心,下一个聚类中心的选择由下式来决定: d=max{min(d(c1,j),d(c2,j))} (7) 其中,C1和C2分别表示最初的两个聚类中心,d表示第j个样本与聚类中心C1或者C2之间的距离。最后,DBI指数由式(8)-式(10)计算获得。方差(所有的样本和聚类中心之间的距离)计算式表示为: (8) 其中,Ti、xj和Ai分别代表的是第i个聚类里面的所有的样本数目,第i个聚类里面的第j个样本,还有就是第i个聚类的所有样本的平均值。第i个聚类簇与第j个聚类簇的距离矩阵Mij由下式计算得到: (9) (10) 其中,Si、Sj和Mij可以由式(8)、式(9)计算得到。每个样本的最大相似度(DBI)由下式计算得到: (11) 1.3 第三阶段算法描述 (1) 将K和加权数据集作为参数传给K-Means算法; (2) 选择初始聚类中心,聚类成K簇,计算平均值;并更新聚类中心; 2) 计算CEI。确定可能的化学品泄漏事故,确定ERPG-2,确定各种可能场景下的大气泄漏量(AQ),选择AQ最大的场景,计算CEI,计算安全距离(HD),汇总报告。 (3) 当不符合平方差准则函数时返回,重新选择聚类中心; (4) 当符合平方差准则函数时,输出K个类簇。 属性加权后的数据集和自适应得到的聚类数目K应用到K-Means聚类算法中,得到最终的聚类结果。 本文提出的基于PCA以及属性加权的改进的半监督K-Means聚类算法能很好地去除掉噪声以及无关属性的影响,并且通过半监督算法自适应地得到聚类数目K。下面以IRIS数据集为例进行分析。 IRIS数据集共有样本150个,特征数为5,其中属性特征4个,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度,决策特征1个,共分3类。 2.1 属性重要度的介绍 从图4中可以看到属性重要度在对分类结果的影响中发挥着极其重要的作用,不同特征属性的分类贡献率(CR)截然不同。通过图4(a)效果图展示,我们可以看到,花萼长度和花萼宽度这两个特征属性的分类结果非常不明显。如果我们应用这两个属性来作为聚类的主要属性,那么会出现很大的错误。图4(b)和(c)中,通过花萼长度和花瓣长度以及花萼宽度和花瓣宽度的组合来进行聚类,界限模糊的现象大大的改善了,图4(d)是通过花瓣长度以及花瓣宽度来进行聚类,可以看到展示的分类效果最好,两类数据很好地区别开来,聚类簇之间的界限比较明显,并且聚类簇内部非常紧凑。因此应该给予花瓣长度和花瓣比其他特征属性更高的属性重要度。 图4 IRIS不同属性分类结果 如图5所示,IRIS数据集中每个特征的属性重要度都是不同的,其中,花瓣长度的属性重要性最高。 图5 IRIS分类贡献率 从表1中可以看到,IRIS数据集的主特征花瓣长度属性的累积分类贡献率已经达到97%,远远超过其他特征属性的累积分类贡献率。也就是说,花瓣长度这个特征属性可以很好地还原原始数据集IRIS,因此选择这个属性作为主属性。 表1 IRIS分类累积贡献率 如表2所示,Center代表初始得到的聚类中心,Attr代表初始聚类中心的每一个特征属性。 表2 IRIS数据集中初始的三个聚类中心 表2中,由于开始进行了主特征属性的筛选,因此只留下花瓣长度一个主特征,根据累积贡献率选取的初始三个聚类中心分别来自三个不同类,这样聚类出的结果相对来说会更加准确。 图6表示的是IRIS数据集在两个特征属性在传统的K-Means的分类效果图在处理前后的对比图,(a)是原始的分类效果图,其中位于右下角的两类有大面积的混合;(b)中,三类很好地分了开来,并且达到了类间距离很大、类内距离很小的标准聚类准则。 图6 IRIS分类对比 2.2 本文改进算法有效性验证 本文采用半监督的方式加强K值的准确性。下面用IRIS数据集以及Wine数据集与其他改进K-Means算法进行比较。K-Means算法表示的是原始算法,PCA-K-Means指的是经过本文算法进行改进后的算法,SC-ICNE表示的是文献[5]中基于特征间隙改进的谱聚类算法,IV-AFS表示的是文献[6]中融合免疫接种机制的改进鱼群聚类算法,DHIKM表示的是文献[7]中基于层次的聚类个数自适应改进聚类算法,FO-CA指的是文献[8]中基于距离差异度组合权重的多属性数据分类方法,如表3所示。 表3 算法比较 从表3中可以看到,本文方法在IRIS数据集中表现最好,在Wine数据集中表现也不错,仅略次于FO-CA算法,本文算法总体识别率最高。 2.3 本文改进算法的普适性验证 本文为了更加准确清晰地描述该改进算法的有效性,分别选取了离散数据集以及连续数据集各8个数据集来进行效果的验证。 表4介绍的是离散数据集的具体信息,Samples表示每一个数据集的样本总数,Attr表示的每一个数据集的特征总数,Class表示的是每一个数据集的类别总数,Percent表示的每一个数据集的每一个类别在整个数据集中的所占百分比。 表4 离散数据集介绍 表5主要介绍了每一个连续数据集的情况。 表5 连续数据集的介绍 本文所选择的数据集,不论是离散数据集还是连续数据集,都力求做到多样性,在样本个数、特征个数以及类别数上都各不相同,以此来验证本文改进算法的普适性。 2.4 自适应得到K值 验证半监督自适应得到K值的有效性,选取的数据集同时包括离散数据集以及连续数据集,并且在样本数、特征数目以及类别数上有一定差别的数据集来说明改进算法的有效性。 从表6中可以看到,当训练数据集占得百分比逐渐增多的时候,自适应得到的聚类数目K也越来越准确。如表7和表8所示,不论是在连续数据集还是离散数据集的聚类识别率上,本文提出的SP-Kmeans算法都有较好的表现。 表6 聚类数目 注:数据集后面的括号中代表的是数据集本身的类别数,百分比指的是训练数据集占原数据集的比例 表7 离散数据集识别率的比较 续表7 注:括号中数字代表同样一个离散数据集各个算法的分类识别率,本文的PCA-K-Means改进算法的排名总体最高,均为前2名,即使第2名也远远高于其他算法的性能 表8 连续数据集识别率的比较 注:括号中数字代表同样一个离散数据集各个算法的分类识别率,本文提出的PCA-K-Means改进算法在8个连续数据集中,有7个排名第一,1个第二,但也均远远高于其他算法的识别率 图7为表7的图形化表示,X轴表示8个离散数据集,Y轴表示每一种方法在此数据集上的分类识别率。可以直观看到,本文改进算法在选择的离散数据集中表现良好,聚类识别率高于其他聚类算法。 图7 离散数据集的实验结果的折线图 图8为表8的图形化表示,X轴表示8个连续数据集,Y轴同样表示每一种方法在此数据集上的分类识别率。从图中可以看到,其他五种聚类算法识别率非常不稳定,且识别率准确性不是很好。随着数据集类别数目的变化,分类识别率有大幅度升降,而本文提出的改进算法不论数据集类别数目如何变化,分类识别率始终保持在一定范围之内,稳定性比较高。 对比图7和图8,可以看到本文方法对于连续型数据集有着较好的分类识别率,而对于离散型数据集则没有达到连续型数据集那样好的效果,但还是高于其他的聚类算法。 图8 连续数据集的实验结果的折线图 本文提出了一种基于半监督的PCA属性加权的K-means聚类算法,通过提出的属性重要度以及特征属性的聚类贡献率等影响因子的概念,不仅有效地去除了无关属性以及噪声属性对聚类结果精确度的影响,并且通过自适应算法自动得到聚类数目K,减轻了用户的负担。通过在UCI公开数据集上对比文献中提到的改进算法的对比实验,验证了本文改进算法的有效性和精确性。 [1]HamrouniT,SlimaniS,CharradaFB.Adataminingcorrelatedpatterns-basedperiodicdecentralizedreplicationstrategyfordatagrids[J].JournalofSystemsandSoftware,2015,110:10-27. [2] 周世兵,徐振源,唐旭清.基于近邻传播算法的最佳聚类数确定方法比较研究[J].计算机科学,2011,38(2):225-228. [3]LiC,ZhangY,JiaoM,etal.Mux-Kmeans:multiplexkmeansforclusteringlarge-scaledataset[C]//Proceedingsofthe5thACMworkshoponScientificcloudcomputing.ACM,2014:25-32. [4] 樊宁.K均值聚类算法在银行客户细分中的研究[J].计算机仿真,2011,28(3):369-372. [5] 胡海峰,刘萍萍.一种基于特征间隙的检测簇数的谱聚类算法[J].计算机技术与发展,2015,25(9):37-42. [6]JothiR,MohantySK,OjhaA.OnCarefulSelectionofInitialCentersforK-meansAlgorithm[C]//Proceedingsof3rdInternationalConferenceonAdvancedComputing,NetworkingandInformatics.SpringerIndia,2016. [7] 魏建东,陆建峰,彭甫镕.一种层次初始的聚类个数自适应的聚类方法研究[J].电子设计工程,2015(6):5-8. [8]DriasH,CherifNF,KechidA.k-MM:AHybridClusteringAlgorithmBasedonk-Meansandk-Medoids[M]//AdvancesinNatureandBiologicallyInspiredComputing.SpringerInternationalPublishing,2016. ATTRIBUTE-WEIGHTED CLUSTERING ALGORITHM BASED ONSEMI-SUPERVISED K-MEANS Pan Wei Zhou Xiaoying Wu Lifeng Wang Guohui (CollegeofInformationEngineering,CapitalNormalUniversity,Beijing100048,China)(BeijingEngineeringResearchCenterofHighReliableEmbeddedSystem,CapitalNormalUniversity,Beijing100048,China)(BeijingKeyLaboratoryofElectronicSystemReliableTechnology,CapitalNormalUniversity,Beijing100048,China) K-Means is a classic unsupervised clustering algorithm which is widely applied in various fields for its high speed and high stability. However, the traditional K-Means methods do not take unrelated attributes and the impact of noise into consideration. They also cannot automatically look for the number of clusters K.Atpresent,theimprovedK-Meansalgorithmsalsorarelyfocusonhigh-dimensionaldataandnoiseattributes.Therefore,thispaperproposesanattribute-weightedclusteringalgorithmbasedonsemi-supervisedK-MeansassociatedwithPCA.Firstly,thedimensionreductionisachievedbyintroducingPCA,andthecontributionrateofeachdimensionclassificationcharacteristics(theimpactfactorofclusteringprocessedbyeachfeatureattribute)iscalculated.Secondly,thenumberofclustersKisobtainedthroughanadaptivesemi-supervisedalgorithm.Finally,theweighteddatasetsandKareappliedtoclustering.Experimentalresultsshowthattheproposedmethodhasbetterrecognitionrateanduniversality. Means Clustering Semi-supervised Principal Component Analysis Attribute-weighted 2016-03-02。国家自然科学 61202027);北京市属高等学校创新团队建设与教师职业发展计划项目(IDHT20150507)。潘巍,副教授,主研领域:信息融合与模式识别。周晓英,硕士生。吴立锋,副教授。王国辉,讲师。 TP ADOI:10.3969/j.issn.1000-386x.2017.03.034
2 实验分析













3 结 语
