藏汉神经网络机器翻译研究
2017-03-12李亚超熊德意殷建民
李亚超,熊德意,张 民,江 静,马 宁,殷建民
(1. 甘肃省民族语言智能处理重点实验室(西北民族大学),甘肃 兰州 730030;2. 苏州大学 计算机科学与技术学院,江苏 苏州 215000;3. 潍坊北大青鸟华光照排有限公司,山东 潍坊 261000)
0 引言
机器翻译研究如何利用计算机自动实现不同语言之间的相互转换,是自然语言处理的重要研究领域。机器翻译方法可以分为基于规则的机器翻译、基于实例的机器翻译、统计机器翻译,以及当前的神经网络机器翻译等。互联网与移动互联网的兴起,为机器翻译研究提供了巨大的应用空间。产业界如谷歌、微软、百度等公司都对机器翻译投入巨大资源进行研究,同时也对外提供了相关的翻译服务,如谷歌翻译、百度翻译等。国内外的科研机构同样把该领域作为重点研究方向。机器翻译成为当前自然语言处理研究的热点之一,不仅具有研究价值,同样具有实用价值。
神经网络起源于20世纪40年代,发展于50~70年代,由于种种限制80~90年代为神经网络研究的低潮期[1]。2006年,Hinton等人[2]解决了神经网络的训练难题。此后,随着计算能力的提高,以及训练数据量的增加,神经网络成功应用在多个领域。近年来,神经网络在图像识别、语音识别等领域取得巨大成功,同时学者们也将该技术应用在自然语言处理任务上,如语言模型、词语表示、序列标注等任务,并取得了令人鼓舞的成绩[3-5]。
在机器翻译研究上,用神经网络机器翻译实现源语言到目标语言的直接翻译,极大地提高了翻译效果,是目前机器翻译研究的前沿热点。基于神经网络的机器翻译方法源于20世纪90年代[6],由于资源限制并没有成为主流方法。在深度学习兴起之后,神经网络通常用于统计机器翻译的词对齐、翻译规则抽取等[7]。从2014年起,Sutskever、Cho、Jean等人[8-11]提出单纯采用神经网络实现机器翻译的新方法,称为神经网络机器翻译。该方法实现了源语言到目标语言的直接翻译,并在多个语言对上超过了传统的统计机器翻译方法[12],逐渐成为当前主流的机器翻译方法。
藏语机器翻译相关研究主要集中在统计机器翻译,以及藏语机器翻译相关基础研究。例如,藏语统计机器翻译短语抽取[13]、基于短语的统计翻译等[14-15]、基于树到串的藏语机器翻译[16]、规则和统计相结合的汉语到藏语机器翻译[17]、面向藏语机器翻译的动词处理[18]、短语句法研究[19]、功能组块识别[20]、藏文数词识别与翻译[21]等。从整体上看,藏语机器翻译研究较为滞后,有关神经网络机器翻译在藏语上的应用及实际效果,并没有见到公开发表。
本文后续部分安排如下: 第一小节详细介绍神经网络机器翻译及迁移学习在藏汉神经网络机器翻译上的应用,第二小节进行实验与分析,第三小节为全文的总结和下一步工作安排。
1 神经网络机器翻译
机器翻译把翻译问题看作求解概率问题,即给定源语言s,求目标语言t在源语言s出现下的条件概率p(t|s),模型参数从双语平行语料中学习到。神经网络机器翻译在翻译建模上完全采用神经网络完成源语言到目标语言的直接翻译,不需要经过统计机器翻译的词对齐、翻译规则抽取、调序等步骤。本节简单介绍神经网络机器翻译及迁移学习方法在藏汉神经网络机器翻译上的应用。
1.1 基本神经网络机器翻译模型
神经网络机器翻译源于序列到序列学习[8-10],本文以蒙特利尔大学提出的翻译模型为例说明[9-10]。编码器解码器模型(encoder-decoder)是神经网络机器翻译模型之一,编码器读取源语言句子,编码为维数固定的向量,解码器读取该向量,依次生成目标语言词语序列,其模型如图1所示。神经网络机器翻译模型主要部分如下:x表示输入,h表示隐藏状态,y表示输出。
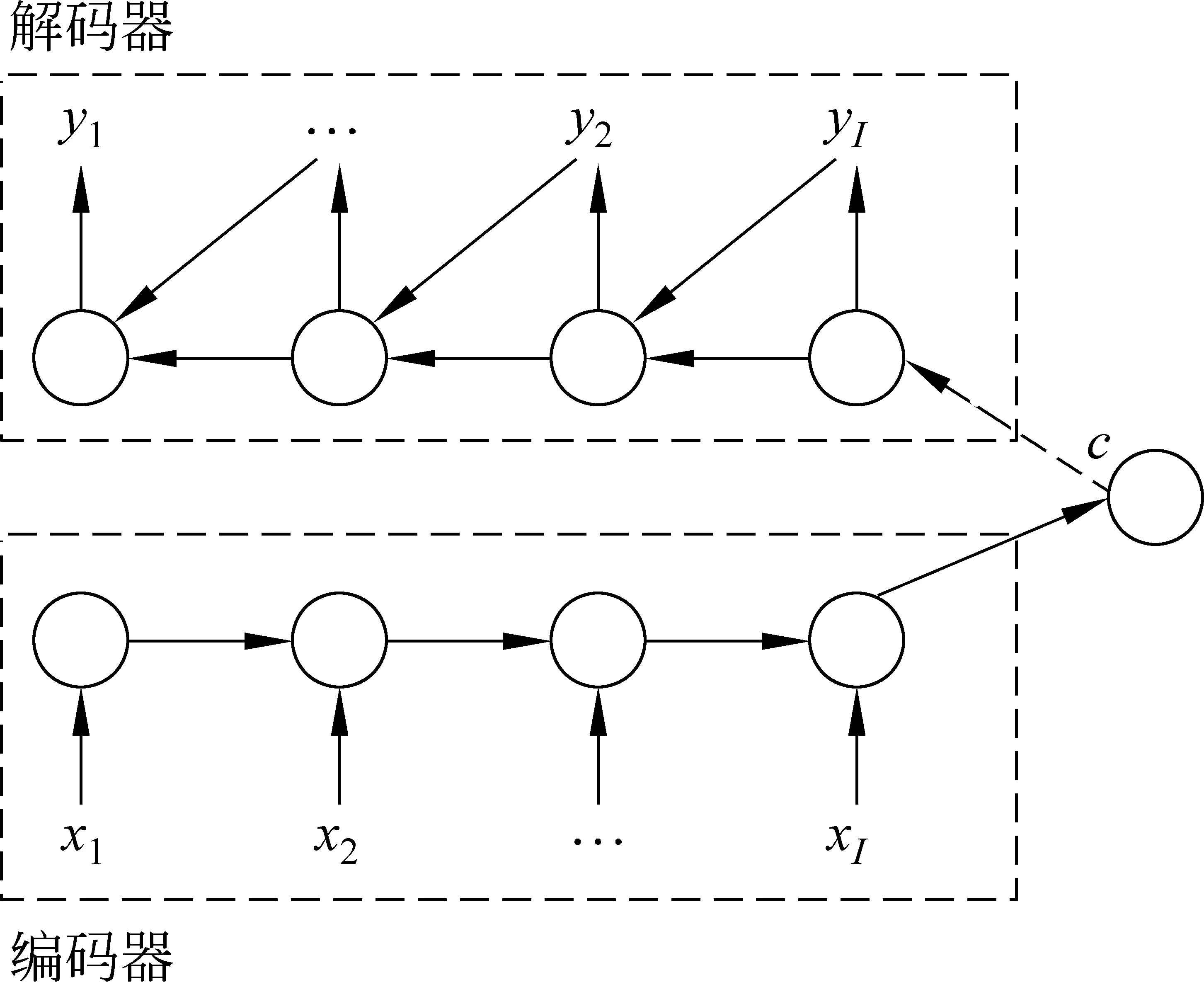
图1 编码器解码器模型
编码器: 编码器读取输入x= (x1,x2, …,xI),将其编码为隐藏状态h= (h1,h2,…,hI),编码器通常采用循环神经网络(recurrent neural network, RNN)实现,更新方式如式(1)~(2)所示。
c为源语言句子表示,f和q是非线性函数。
解码器: 在给定源语言表示c和前驱输出序列{y1, …,yt-1}条件下,解码器依次生成目标语词yt,如式(3)所示。
y= (y1,y2, … ,yT),解码器通常同样采用循环神经网络,形式如式(4)所示。
其中,g是非线性函数用来计算yt的概率,st是解码器的隐藏状态。
模型训练: 编码器和解码器可以进行联合训练,如式(5)所示。
其中,θ是模型的参数,通常采用梯度下降法进行计算,(xn,yn)表示双语训练语料。
1.2 基于注意力的神经网络机器翻译
普通神经网络机器翻译模型将源语言句子表示成一个固定向量,该方法存在不足之处,比如大小固定的向量并不能充分表达出源语言句子语义信息。基于注意力机制的神经网络机器翻译将源语言句子编码为向量序列,在生成目标语言词语时,通过注意力机制动态寻找与生成该词相关的源语言词语信息[14],因而大大增强了神经网络机器翻译的表达能力,在实验中显著提高了翻译效果,如图2所示。
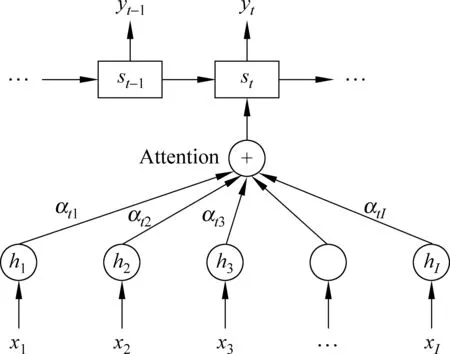
图2 注意力机制图示
当采用注意力机制时,式(3)重新定义为式(6)。
st是t时刻循环神经网络的隐藏状态,由式(7)得出:
g、f是非线性函数,上下文向量(contextvector)ct依赖于源语言编码序列(h1,h2,…,hI),hi包含第i个输入词上下文信息。ct计算方法如式(8)所示。
αtj是hj的权重,计算方法如式(9)所示。
etj=a(st-1,hj)是对齐模型,计算出t时刻生成词与第j个源语言词的匹配程度。
基于注意力的神经网络机器翻译在解码时只关注源语言句子中一部分区域,能够增强长句子表示能力。相比普通的神经网络机器翻译,该方法在解码时融合了更多的源语言端信息,可以显著提升机器翻译效果,是目前神经网络机器翻译的主流方法。
1.3 资源稀缺条件下的藏汉神经网络机器翻译
在训练语料较少情况下,神经网络机器翻译效果显著低于统计机器翻译方法,这在多个语言对上得到验证[22-23]。迁移学习[24]能够将学习到的知识应用到相近任务上,以减少应用任务的训练数据量。在神经网络机器翻译中,迁移学习主要用在资源稀缺语言翻译上,可以将资源丰富语言对的翻译模型参数,如英汉、英法等语言,迁移到资源稀缺语言上,如藏语到汉语的翻译等,这在一些实验中得到了实际验证。
藏汉机器翻译同样存在训练语料不足问题,为此本文根据Zoph等人[22]思想,首先,采用大规模英汉平行语料训练得到英语到汉语神经网络机器翻译模型。然后,在训练藏语到汉语神经网络机器翻译模型时,采用英汉翻译模型参数初始化藏汉翻译模型参数。最后,对由英汉翻译模型参数初始化后的模型,采用藏汉平行语料进行训练。
与Zoph等人[22]方法不同的是,本文方法对藏汉翻译模型的所有参数均采用英汉模型参数初始化,且在初始化时不要求两种翻译模型的汉语词向量(word embedding)一致。这种迁移学习方法简单,对翻译模型本身不做任何改变,并具有语言无关优点,因而更加适合训练语料极度缺少的特殊情况。
2 实验与分析
2.1 实验设置
本实验采用的平行语料为2011年机器翻译研讨会(CWMT 2011)藏汉机器翻译评测语料,训练语料10万句,测试语料650句。迁移学习采用英汉平行语料,共125万句,从LDC语料中抽取得到。为了相对公平地对比,统计机器翻译语言模型训练采用大小100MB的汉语文本语料,神经网络机器翻译不采用额外单语语料。
对训练语料句子长度限制为50词以下,双语词向量维数为620,隐藏层大小为1 000,解码时Beamsize大小为10,系统选择Adadelta方法[25]优化参数,训练中mini-batch大小为80句,Dropout[26]设置为0.5。为了减少未登录词问题,藏语、汉语词典大小设置为3万,约覆盖99%的词语。语料训练轮数最多为60轮。
本文采用的基线系统为东北大学开发的Niutrans短语统计机器翻译系统[24],用“Niutrans”表示。神经网络机器翻译系统为本课题组基于Bahdanau[22]工作所开发的基于注意力的神经网络机器翻译系统,循环单元采用门限循环单元(gated recurrent units, GRU)[9],用“NMT”表示。本文提出的采用迁移学习实现的藏汉神经网络机器翻译系统用“NMT+Trans”表示。
由于测试语料限制,在统计机器翻译中,测试语料同样作为训练短语翻译模型的开发集,即统计机器翻译结果是开发集上的结果。在神经网络机器翻译中测试语料同样作为开发集,但是不影响翻译模型,仅用于选择最优的翻译模型。以BLEU-4作为评测标准,采用基于词的评测方法。
2.2 主要实验结果
主要实验结果见表1。
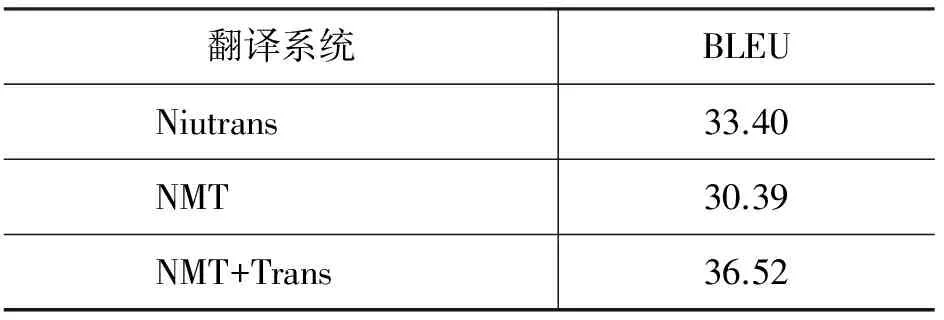
表1 实验结果
从实验结果来看,基线神经网络机器翻译系统的BLEU值低于短语统计机器翻译系统。因为训练数据量较少,神经网络机器翻译模型并不能获得高质量的词汇语义映射关系。在数据量较少情况下,神经网络机器翻译效果低于短语统计机器翻译,这种情况同样出现在英汉、英法等其他语言翻译中[22-23]。
本文通过迁移学习将语料资源规模较大的英汉神经网络机器翻译模型参数迁移到藏汉神经网络机器翻译中。相比基线神经网络机器翻译,本文方法提高了六个BLEU值,同时也显著超过了短语统计机器翻译系统结果。
根据Liu[23]的实验,在30万句的汉英语料上,神经网络机器翻译比短语统计机器翻译低了10个BLEU值。本文的平行语料更少,但是神经网络机器翻译与统计机器翻译效果仅相差了三个BLEU值。我们认为是该训练语料题材很集中, 且测试集与训练集题材也很一致所致。因此,两种翻译方法并没有出现巨大差距。
2.3 模型训练轮数对翻译结果影响
在神经网络机器翻译中,要对训练语料整体训练多次,平行语料完整训练一遍称为一轮(epoch),通常经过20轮左右的训练,即可得到稳定的模型。因为藏汉平行语料较少,在常规训练轮数下,并不能得到稳定的结果。因此,本文对语料训练轮数对最终翻译结果的影响进行实验,结果如图3所示,实验采用基线神经网络机器翻译系统。
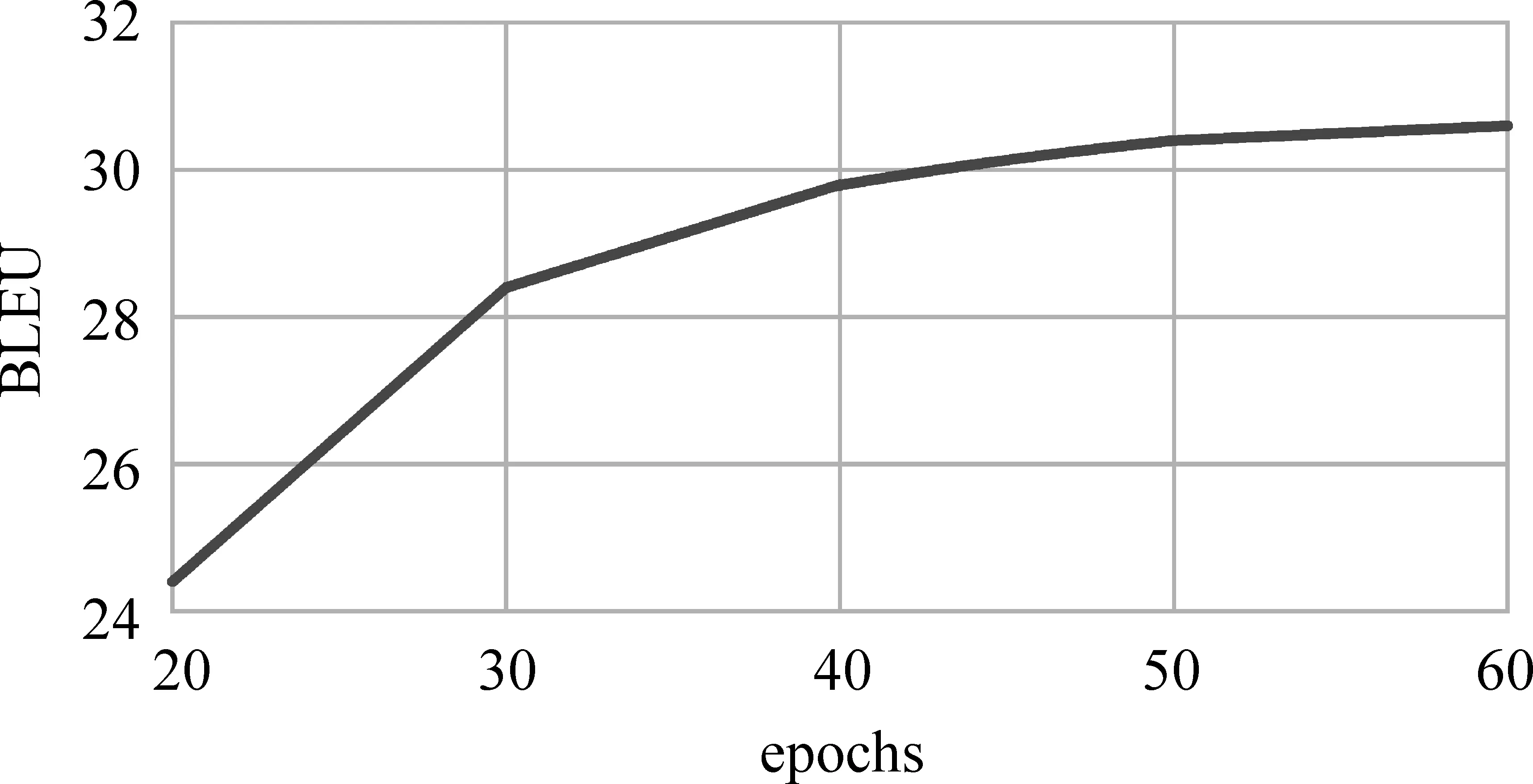
图3 模型训练轮数与BLEU值关系
可以看出,模型迭代到30轮时,取得了28.37的BLEU值,从30轮开始BLEU值缓慢增长,直到迭代到60轮时取得最好翻译效果。为了防止过拟合,本文实验迭代轮数不超过60。
2.4 翻译结果示例
本节对统计机器翻译和神经网络机器翻译的译文进行简单对比,主要从翻译忠实度、翻译流利程度、翻译不充分(部分词或短语没有被完整翻译)、过度翻译(部分词或短语被多次翻译)[27]等标准进行对比。对比结果如表2所示,“SMT”表示基线统计机器翻译系统译文,“NMT+Trans”表示本文用迁移学习实现的藏汉神经网络机器翻译系统的译文,“UNK”符号表示未登录。空格表示藏语、汉语词语之间的切分标志。
从翻译示例1可以看出,神经网络机器翻译相比统计机器翻译,可以很好地处理汉语语序问题,翻译结果很流畅。
从翻译示例2可以看出,相对参考译文“本法 有关 规定”,神经网络机器翻译系统翻译成“本 法律 有关 规定”,统计机器翻译系统的翻译结果为“本法 有关 规定”,能够看出神经网络机器翻译具有很强的词义联想能力。
从翻译示例3可以看出,虽然神经网络机器翻译的译文很流畅,但是存在与原文语义相差较大的问题,翻译忠实度较低,并且存在重复翻译现象。
翻译示例4句型结构比较复杂,神经网络机器翻译显然能够更好地理解原文意思,并且翻译结果更为流利。
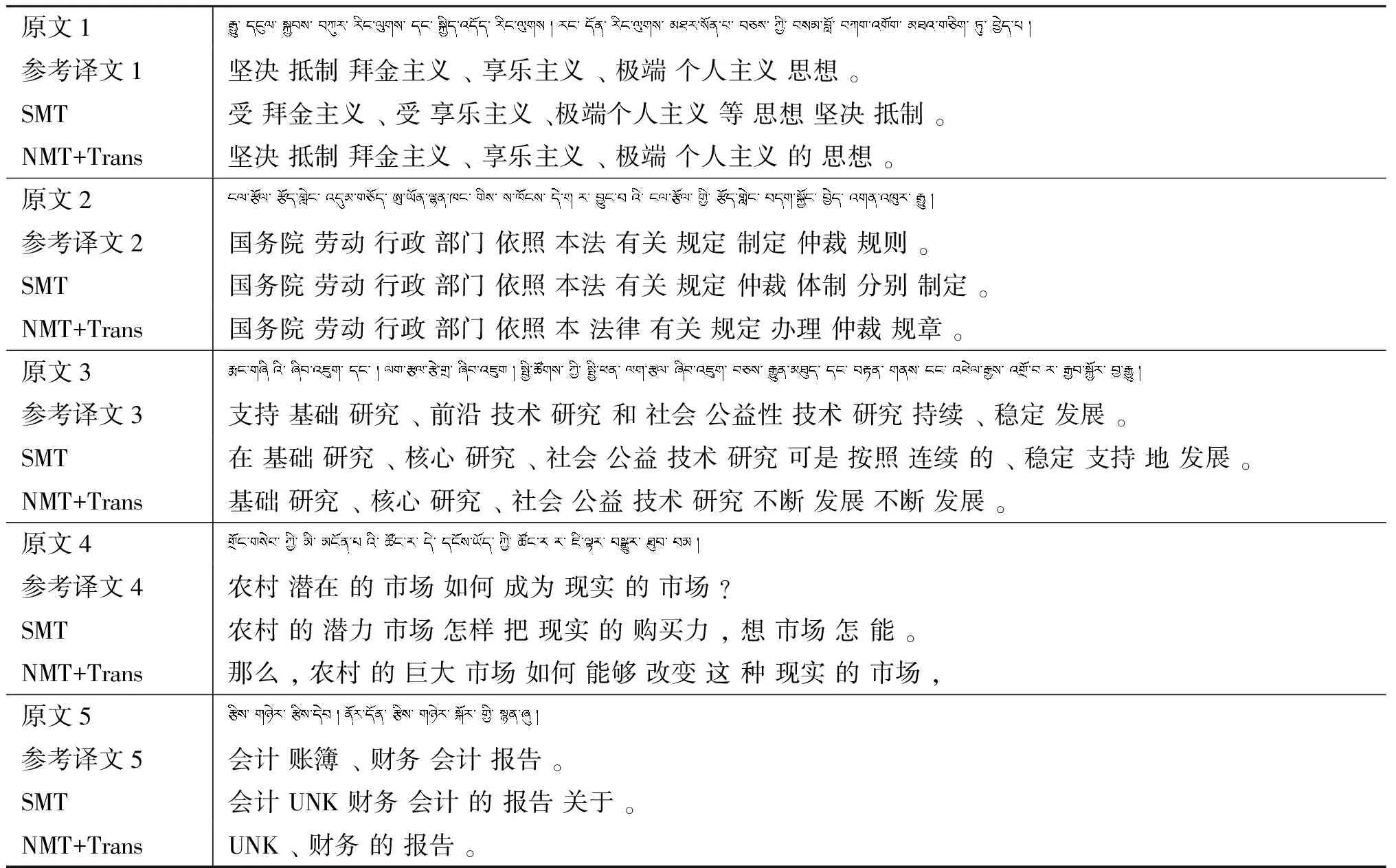
表2 翻译示例对比
翻译示例5中出现了未登录词,神经网络机器翻译和统计机器翻译均未能够准确翻译出“账簿”这个词,且神经网络机器翻译出现严重的翻译不充分现象,即原文多个词语并没有被完整翻译出来。
从以上翻译结果可以看出来,藏汉神经网络机器翻译虽然存在神经网络机器翻译的不足之处,如翻译不充分、过度翻译、对原文的翻译忠实度较低等缺点。但是从整体上看翻译结果较为流畅,翻译调序处理效果很好,且对原文语义理解能力更强,译文质量整体上优于统计机器翻译方法。这种实验结果符合神经网络机器翻译在其他语言上应用的效果。
3 结论与下一步工作
本文研究了神经网络机器翻译在藏汉翻译上的应用,并采用迁移学习方法将英汉神经网络机器翻译模型参数迁移到藏汉神经网络机器翻译模型中。该方法显著提高了基线神经网络机器翻译系统效果,并超过了短语统计机器翻译,取得了最好的翻译结果。
从实验结果可以得出,藏汉神经网络机器翻译同样具有神经网络机器翻译的共同优点和不足之处。由于语料资源较少,基本的神经网络机器翻译模型效果仍然低于统计机器翻译方法。本文提出的迁移学习方法简单有效,能够使藏汉神经网络机器翻译结果显著超过短语统计机器翻译效果。该方法对神经网络模型不做任何改变,并具有语言无关性,理论上可以应用到维吾尔语、蒙古语等其他资源稀缺语种的神经网络机器翻译中。
由于藏汉平行语料较少,语料资源是藏汉机器翻译的最大障碍。在后续研究中,我们将采用其他方法提高资源稀缺条件下的藏汉神经网络机器翻译效果,以及研究本文方法在其他语言上的应用。
[1] 焦李成,杨淑媛,刘芳等.神经网络七十年: 回顾与展望[J]. 计算机学报, 2016,39(8):1697-1716.
[2] Geoffrey E H, Simon O, Yee-Whye T. A fast learning algorithm for deep belief nets [J]. Neural Computation, 2006(18): 1527-1554.
[3] Yoshua Bengio, Réjean Ducharme, Pascal Vincent, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research, 2003, 3(6):1137-1155.
[4] Tomas Mikolov, Ilya Sutskever, Kai Chen, et al. Distributed representations of words and phrases and their compositionality [J]. Advances in Neural Information Processing Systems, 2013(26): 3111-3119.
[5] Ronan Collobert, Jason Weston, Leon Bottou, et al. Natural language processing (almost) from scratch [J]. Journal of Machine Learning Research, 2011, 12(1):2493-2537.
[6] Ramnn P N, Mikel L. Forcada. Asynchronous translations with recurrent neural nets[C]//Proceedings of International Conference on Neural Networks, Houston, USA, 1997:2535-2540.
[7] Zhang Jiajun, Zong Chengqing. Deep neural networks in machine translation: an overview [J]. Intelligent Systems IEEE, 2015, 30(5):16-25.
[8] Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Sequence to sequence learning with neural networks[C]//Proceedings of the Neural Information Processing Systems (NIPS 2014), Montreal, Canada, 2014:3104-3112.
[9] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, et al. Learning phrase representations using rnn encoder-decoder for statistical machine translation[J]. arXiv preprint/1406.1078v2, 2014.
[10] Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bahdanau, et al. On the properties of neural machine translation: encoder-decoder approaches[C]//Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation. Doha, Qatar, 2014: 103-111.
[11] Sebastien Jean, Kyunghyun Cho, Yoshua Bengio. On using very large target vocabulary for neural machine translation[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (ACL 2015), Beijing, China, 2015:1-10.
[12] Marcin Junczys-Dowmunt, Tomasz Dwojak, Hieu Hoang. Is neural machine translation ready for deployment? A Case Study on 30 Translation Directions[J]. arXiv:1610.01108v2, 2016.
[13] 董晓芳. 藏汉统计机器翻译短语抽取技术研究[D]. 兰州: 西北民族大学硕士学位论文, 2013.
[14] 位素东. 基于短语的藏汉在线翻译系统研究[D]. 兰州: 西北民族大学硕士学位论文, 2015.
[15] Yan Xiaodong, Zhao Xiaobing. Research on Sino-Tibetan machine translation based on the reusing of domain ontology[J]. International Journal of Online Engineering, 2013, 9(4):105.
[16] 华却才让. 基于树到串藏语机器翻译若干关键技术研究[D]. 西安: 陕西师范大学博士学位论文, 2014.
[17] Liu Huidan, Zhao Weina, YU Xin, et al. A Chinese to Tibetan machine translation system with multiple translating strategies[J]. Himalayan Linguistics, 2016, 15(1):148-166.
[18] 华果才让. 汉藏机器翻译中的藏语动词研究[D]. 西宁:青海师范大学硕士学位论文, 2014.
[19] 万福成, 于洪志, 吴玺宏,等. 面向机器翻译的藏语短语句法研究[J]. 计算机工程与应用, 2015, 51(13):211-215.
[20] 王天航. 面向机器翻译的藏语功能组块识别研究[D]. 北京: 北京理工大学硕士学位论文, 2016.
[21] 孙萌, 华却才让, 刘凯,等. 藏文数词识别与翻译[J]. 北京大学学报(自然科学版), 2013, 49(1):75-80.
[22] Barret Zoph, Deniz Yuret, Jonathan May, et al. Transfer learning for low-resource neural machine translation[C]//Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP 2016). Austin, USA, 2016:1568-1575.
[23] Lemao Liu, Masao Utiyama, Andrew Finch, et al. Neural machine translation with supervised attention[C]//Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics. Osaka, Japan, 2016:3093-3102.
[24] Karl W, Taghi M K, Wang Dingding. A survey of transfer learning[J]. Journal of Big Data, 2016, 3(1):9.
[25] Matthew D.Zeiler. ADADELTA: An adaptive learning rate method [J]. Computer Science, 2012.
[26] Srivastava N, Hinton G, Krizhevsky A, et al. Dropout: A simple way to prevent neural networks from overfitting[J]. Journal of machine learning research, 2014(15):1929-1958.
[27] Tu Zhaopeng, Lu Zhengdong, Yang Liu, et al. Modeling coverage for neural machine translation[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016), Berlin, Germany, 2016:76-85.
[28] Xiao Tong, Zhu Jingbo, Zhang Hao, et al. NiuTrans: An open source toolkit for phrase-based and syntax-based machine translation[C]//Proceedings of the ACL 2012 System Demonstrations. 2012:19-24.
[29] Dzmitry Bahdanau, KyungHyun Cho, Yoshua Bengio. Neural machine translation by jointly learning to align and translate[J]. Arxiv: 1409.0473v6, 2014.
