汉语名词的隐喻知识表示及获取研究
2017-03-12汪梦翔王厚峰
汪梦翔,饶 琪,顾 澄,王厚峰
(1. 北京联合大学 师范学院,北京 100011;2. 北京大学 计算语言学研究所,北京 100871;3. 清华大学 五道口金融学院, 北京 100083)
0 引言
(1) 他是一只白眼儿狼。
(2) 他是一头猪。
这里两个句子都是“X是Y”型隐喻句。“白眼儿狼”这个惯用语,多比喻忘恩负义的人,我们一般理解为“他像白眼儿狼一样忘恩负义”,但是句(2)我们可以理解的意义很多,例如,“他像猪一样脏”“他像猪一样蠢”“他像猪一样肥”“他像猪一样丑”等。
文献[1]中指出隐喻其实就是一种两个概念的特征继承,传统的隐喻知识只是描述X和Y是否存在语义的映射关联,但是这种知识表示不能反映X和Y之间建立关联的特征项,而且Y上所有的特征也不一定都会被X所具备,因为X对Y特征的继承是可选择的,于是就会出现像句(2)那样的多种理解。基于此,本文提出一种新的隐喻知识表示方式,以便能够更深入地反映为什么X与Y能存在某种隐喻关联,以及它们在语义特征中的相似性问题。
另外,句(1)中惯用语的隐喻特点也引起了我们的思考。惯用语因由社会约定俗成而产生,所以具备语义的固定性和深层的隐喻性[2]。可见惯用语一般都伴随隐喻,而且所形成的隐喻含义比较固定,一般很难随着语境发生改变。比如,“中山狼”“二把刀”等名词性结构的惯用语比喻的对象都不超过两种,这比起一般名词“天气”“时间”“狗”等的隐喻义要单一得多。比如文献[3]中就指出“时间”所能映射对应的隐喻概念多达十余种,有动体、人、有价物、工具、容器、植物等,而且“时间”放入不同的语境中,就会有不同的隐喻对象。而一般像“白眼儿狼”“铁公鸡”这种映射的隐喻概念就比较单一和固定,不受语境影响,比如“铁公鸡要请客”“他平时就是个铁公鸡”“铁公鸡走了”中的“铁公鸡”一般人的理解都是隐喻“吝啬的人”。鉴于此,本文在提取隐喻知识时,注重了静态的惯用语的释义数据导入,并且和动态的日常性语料结合来提取名词的隐喻知识,从而为隐喻知识计算提供更深层的语义信息和新的知识来源。
1 相关研究
在中文信息处理领域,目前在汉语隐喻方面的研究,主要集中于隐喻句的机器识别和分类上[4-5],对于隐喻知识的表示和获取方法的专门研究相对较少,不过隐喻识别和隐喻知识获取紧密相关。
总体来看,国内对隐喻知识的提取有两种思路,第一种思路是基于规则的,规则依托的是形式上的判断,一般是根据特定的特征词或语法结构,比如“像、是”等关键词或“如……般”等常用隐喻结构来识别和提取隐喻知识。李斌[6]、杨芸[7-9]就是用的这种思路。这种思路最为基础,但也存在一些问题: 第一是现实中符合这些框架的语料极少;第二,即使带有特征词,判断起来仍有难度,比如“张三是地主”“张三是神”虽然具有同样的形式,但并非都含有隐喻色彩。贾玉祥[10-11]针对这两个问题进行了改进,一方面从Web海量数据中根据规则提取高质量的隐喻知识,另一方面利用词语的上下义关系特征来改进“A是B”型的隐喻判断。比如,面对“X是Y”型的句子,如果X是Y的下位,则“X是Y”的搭配为正常搭配,否则为隐喻。比如,“香蕉是水果”是正常搭配,“世界是个舞台”是隐喻搭配,需要抽取出来。但是,有时候X、Y处于同一个语义类下也有可能是隐喻关系,比如“集中营中的医生就是屠夫”,这里的“医生”和“屠夫”都属于“职业”这个类别的下属分类,但是却带有隐喻性。
第二种思路是基于机器学习的方法,以统计为手段,为特定名词选择一定的语料,标记隐喻和非隐喻用法,用标记语料训练分类器,从新的名词性短语中识别出隐喻,进而就可以提取隐喻关联。王治敏[12-13]就是采用这种方法进行隐喻识别和提取。这种思路虽然识别准确,提取的质量也高,但是首先要为选取的每个名词人工标注一定数量的语料,才能进行相应的机器学习,因此非常耗费人力。
不过,上述思路都只是找到简单的词语隐喻映射关联,无法找到它们之间建立关联起核心作用的特征,而想要进一步地挖掘带有特征和属性的隐喻知识,还需要对本体和喻体以外的信息进行梳理。另外,虽然很多人通过语料或者借助语义知识库来提取隐喻,但是都没有借助惯用语这种隐喻固定且特征明显的语义资源,而我们把它纳入我们的抽取范围当中。本文针对惯用语和一般性的名词进行了相关的隐喻知识抽取工作,不过两者特点不一样,所以我们进行了分别对待。
2 名词隐喻知识的知识表示
以往隐喻知识的表示基本都是依托概念隐喻理论,只涉及源域和目标域两个概念[14],但分属于两个不同概念域的X和Y,要建立某种语义上的映射关联而达到一种语义隐喻的效果,一般需要它们语义蕴含的某种特征有着某种相似或交集[15]。为此,我们在描述词语的隐喻知识时,除了要明确哪些词语能够彼此建立这种语义映射关联,更应该提取其中蕴含的共同特征。而这些特征又是附着在某些属性上的,比如“猪”有“丑”的特征,也有“肥”的特征,这些特征其实都可以理解为“猪”这个概念中的“外形”属性的不同取值。所以我们说“他像猪一样丑”,其实是概念“他”和概念“猪”在“外形”属性上有着共同的特征值“丑”,具体如图1所示。
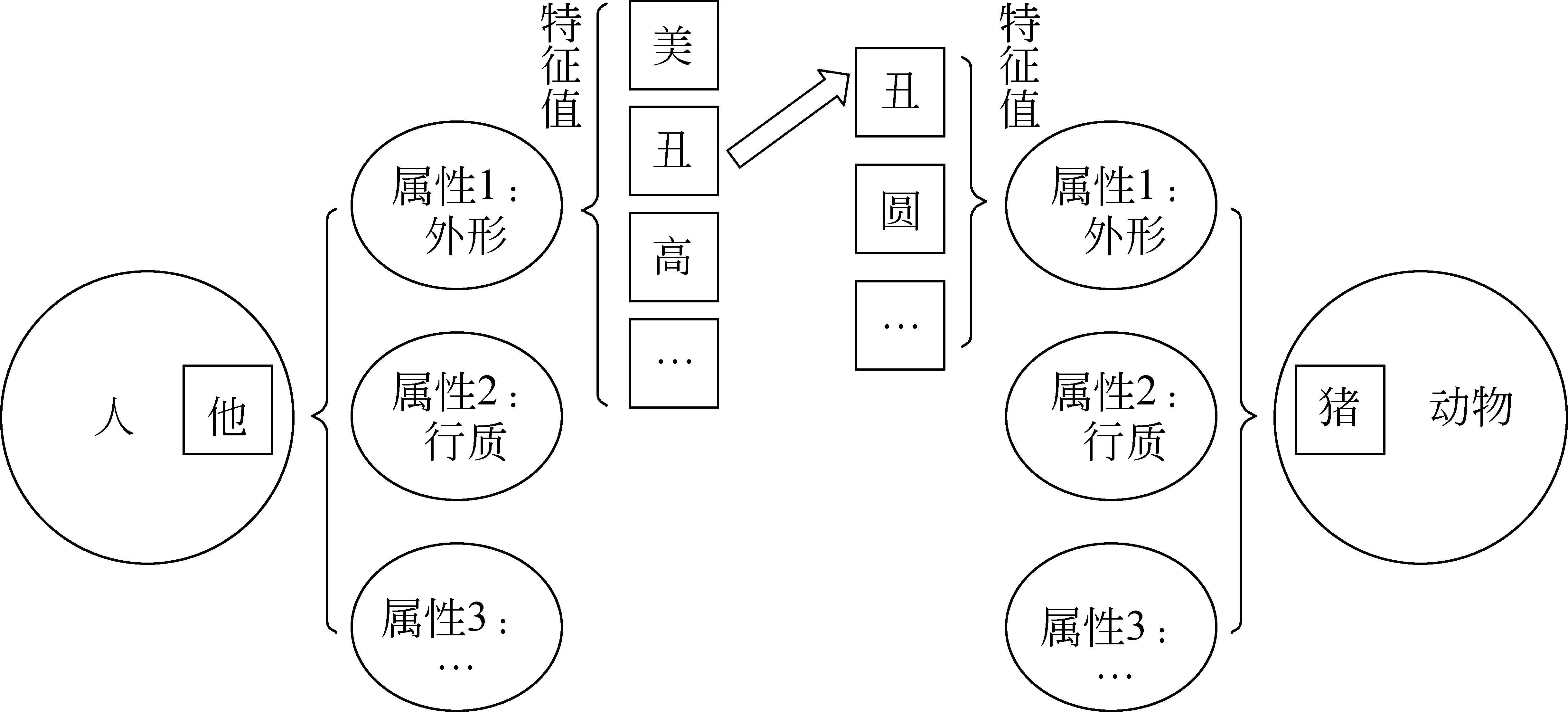
图1 “他像猪一样丑”的隐喻映射分析
基于上述思路,本文隐喻知识的描述不是表面意义的语义关联映射(如“他像猪一样”,不是简单的描述为“他”可以映射“动物”),而是要展示概念内部更深层次的语义关联, 包括概念隐喻中具有相同属性以及相关特征值的关系。本文所指名词所蕴含的隐喻知识,主要是指获取它的隐喻特征以及属性。比如“他像一只狼一样凶狠”,这里虽然是“他”和“狼”构成隐喻映射,但是这种隐喻知识包含的是相关特征以及内部属性的关联性,这里“凶狠”就是把“他”和“狼”建立起映射的特征之一,其属性值可以描述为“特质”。再比如“他像狼一样反应迅速”中的“迅速”作为“狼”的又一个隐喻特征,只不过属性由“特质”变成了“速度”。一般情况下,不同的映射关联特征对应不同的映射属性。例如,对于一个词语“花朵”,它的隐喻特征可以有“鲜艳”“美丽”“芬芳”,而对应的隐喻属性分别为“色彩”“形状”“气味”。
我们可以把“X→Y”的隐喻知识标记为:X→Y=X(属性+特征)∩Y(属性+特征)
在具体的描述中,我们可以将“X→Y”隐喻知识采取二维表格的形式(表1)。
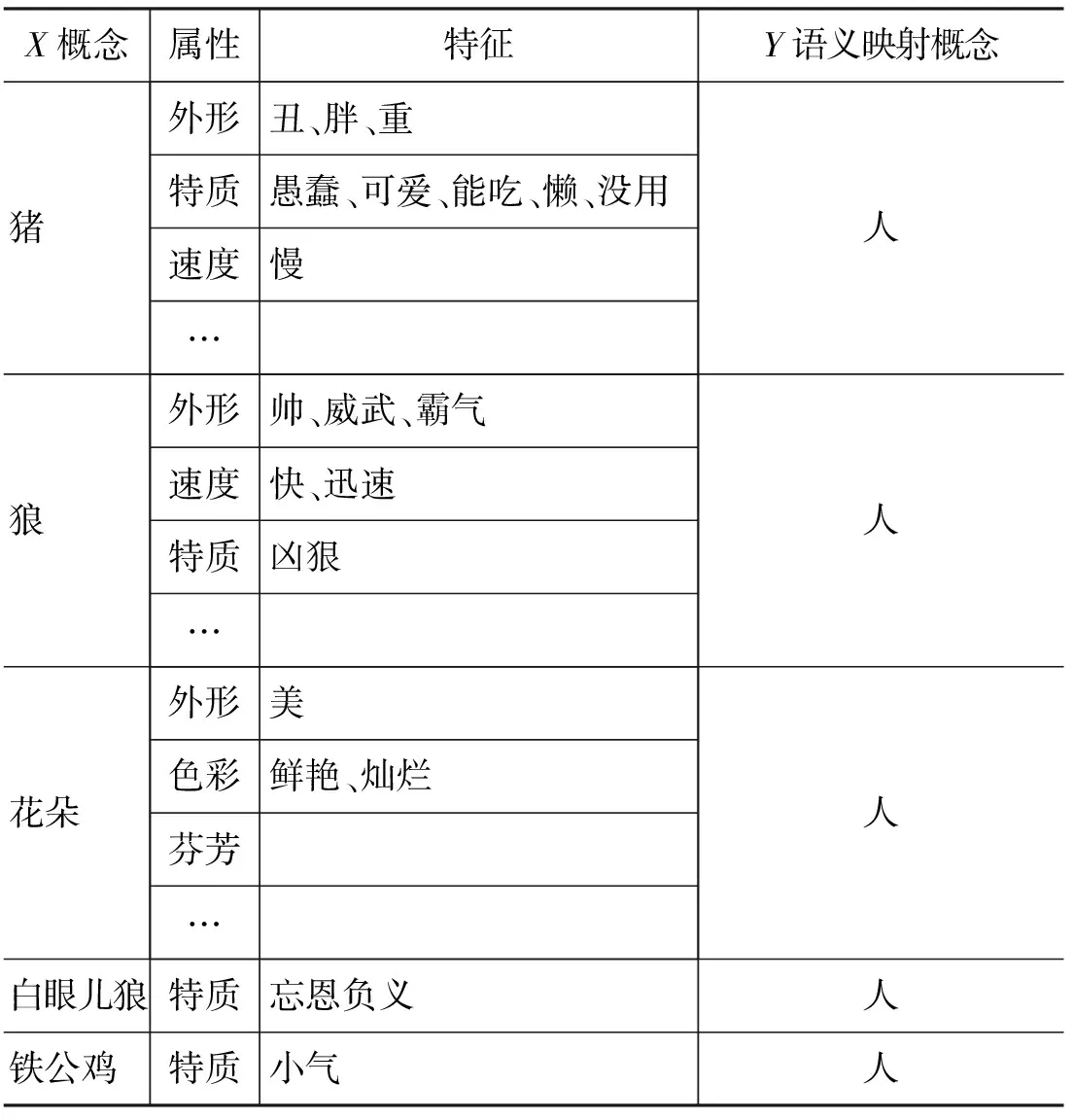
表1 概念隐喻的知识表现形式
表1我们可以看到,一个概念的隐喻知识,都是通过属性以及属性特征的取值来展现的。其中隐喻特征可定义为人们长期以来对某名词的认知特征中常用于隐喻修辞中描述本体和部分特性的认知特征,这种特征通常用谓词来表示,如花朵的隐喻特征包括“美丽”“娇弱”等。在这里,一般性名词的特征众多,而惯用语中的名词隐喻特征比较单一,这主要是由于惯用语的语义较为固定、不受语境制约引起的,所以惯用语的隐喻知识提取比较简单。这个表中的特征值,一般取的是X和Y所具备特征的交集,而非全部。
隐喻知识中的属性,本文定义为具体事物的宏观属性,即该事物所属群体的属性,而不是某一个体属性,由描述属性的名词构成。比如“小李就是一朵花”中“小李”的属性应该是一般人都具有的属性,所以其隐喻的语义映射应该是在“花”和“人”之间关联。属性一般由名词性成分表示,多半都是特征所描述的对象,比如“美”主要是描述“外形”的。另外,由于惯用语比喻的对象都比较固定,语义上可选的特征也比较固定,基本上对应的都是这个名词性词组的特点,所以在描述属性时,我们为了简单起见,都标为“特质”。比如,“铁公鸡”的特征一般固定为“吝啬”,其属性归属按照非自然属性的归类,原则上是要归入“心理态度”,但是这里我们都统一写为“特质”,“特质”接近于心理认知的特性。
一般情况下,只有特征值有相似性,才会发生隐喻关联。比如“人”和“花”都有相似特征“美”,那么它们两者可以发生隐喻关联。另外,两个发生隐喻关联的概念还不能是从属关系,这在文献[11]中已经论证。比如“白眼儿狼”从属于“狼”,即使和“狼”有共同的特征“凶狠”,也不能发生隐喻关联,比如“这头白眼儿狼像一头狼”就说不通。
3 名词隐喻知识的获取
本文将名词的隐喻知识获取途径分为两种,一种是面向惯用语中的名词性词组,另一种是面向动态文本中的普通名词。同时,隐喻知识的提取包括隐喻特征的获取和隐喻属性的提取两个方面。
3.1 基于惯用语导入的隐喻知识获取
目前惯用语词典一般都会将比喻意义列出,所以从词典的释义中,我们就可以进行提取,并且建立语义映射关联。
因为惯用语长短不一,有时甚至是一句话,如“吃不了兜着走”,所以我们对惯用语进行了筛选,主要从《现代汉语惯用语规范词典》[16]和《新华惯用语词典》[17]提取了1 650个名词性惯用语词组,提取的多以三字词居多,也有四字词和二字词。通过分析释义,我们发现有些惯用语所隐含的隐喻对象不只一个,比如“馋嘴猫”解释为“贪吃嘴馋的人或好色的男人”,虽然都是指人,但是隐喻的特征却不一样,另一个是“贪吃嘴馋”,一个是“好色”。在这些惯用语中,表示一个隐喻特征的有1 240个,表示两个隐喻特征的有360,表示两个以上隐喻两个以上的50个,具体统计结果如表2所示。
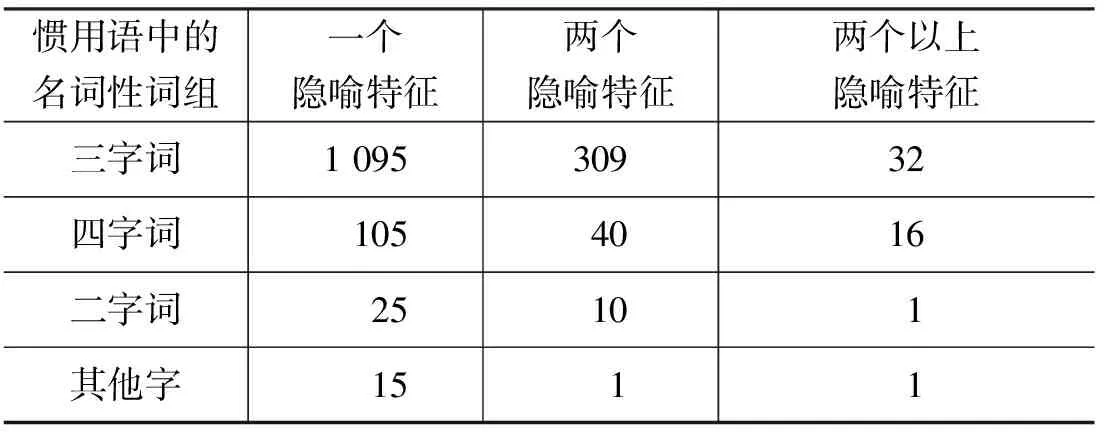
表2 惯用语中的名词性词组的隐喻特征分布
可见,大部分汉语惯用语只有一个隐喻特征,如“白眼儿狼”的隐喻特征只有“忘恩负义”,而作为狼的“凶残”“敏捷”等特征不会被使用于隐喻中,如“他跑得飞快,像一只白眼儿狼”这样的句子是不会出现的。也就是说,惯用语中的隐喻知识只出现在特性隐喻中,通过喻体事物(惯用语)最显著的特征体现出来,而且具有一定的排他性,因此对于惯用语中隐喻特征的提取,我们只需要根据惯用语的释义就可以确定具体名词的隐喻特征了。对于惯用语的释义格式,我们做了相关考察,名词性惯用语以偏正和联合结构居多,一般在释义中多以“喻、比喻、形容、指、意谓”引出映射性概念Y,而且Y多存在于“的”字结构之中,而隐喻特征多为Y的修饰性成分,我们找了五种名词性结构进行对比,如表3所示。

表3 五种名词性结构惯用语释义列举
我们从释义中可以看出,只要惯用语的结构是名词性的,那么其解释多半是“A的B”模式,这样通过抽取“的”字结构并进行适当过滤就可以得到我们想要的知识了。识别算法如下:
Step1预处理: 将惯用语词典进行词性标注等预处理。
Step2确定隐喻文段: 利用关键词“喻、比喻、形容、指、意谓”等进行判断,提取这些关键词后面的文档。
Step3提取隐喻特征: 利用关键词和(“或”)特定语法结构(主要是“的”字结构)从惯用语词典中获取惯用语释义作为其隐喻特征。一般情况下,“或”确定特征数量(有“或”字的多为两个隐喻特征),“的”确定隐喻特征值以及所映射对象(一般“的”前的修饰性成分为隐喻特征值,“的”后为隐喻对象)
至于惯用语的隐喻属性提取,由于大部分都是一个隐喻特征,较为单一,为了处理上的方便,我们统一标为“特质”。另外,名词的属性定义在具有特定含义的具体名词惯用语身上往往并不成立,因为属性定义为该事物所属群体的属性,而惯用语由于对其内涵进行了限定,失去了大部分其所属群体的属性。例如,“白眼儿狼”作为惯用语,失去了其所属群体“狼”的部分属性(如动作、外貌),只保持了狼的特征属性。所以惯用语“白眼儿狼”的属性唯一且固定为“特质”。
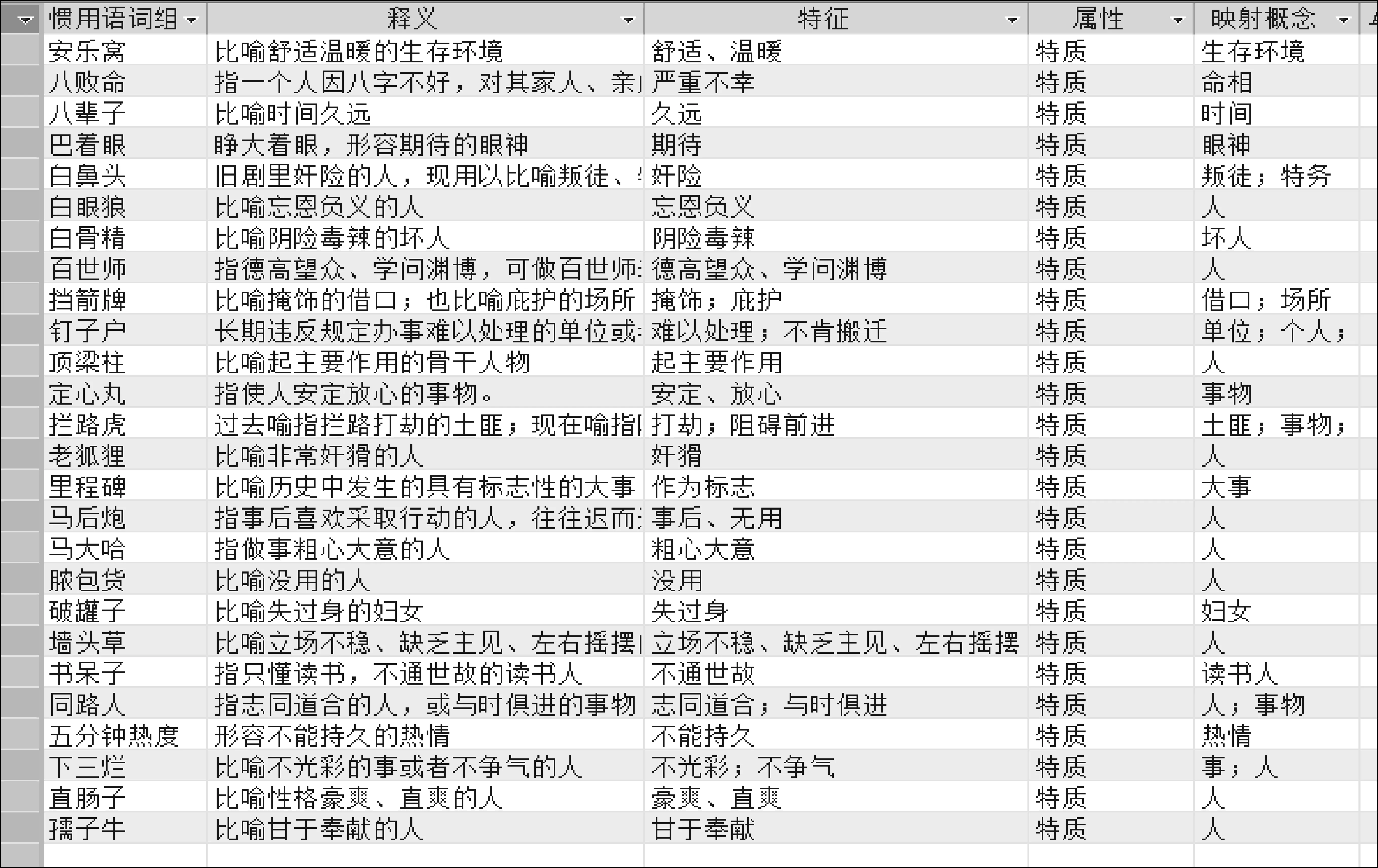
按照上述方法,我们把上面五个惯用语释义信息的隐喻知识进行相关的提取和分类,结果如表4所示。
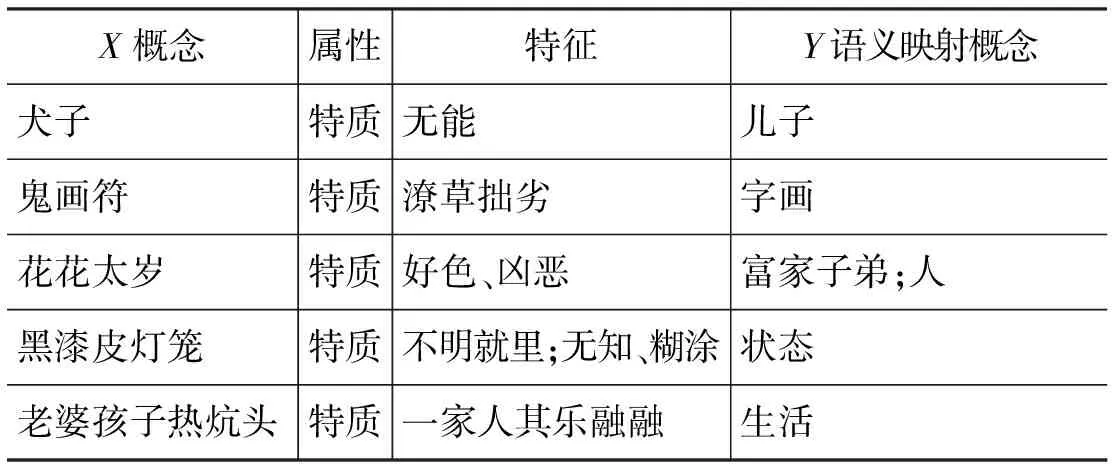
表4 五种名词性结构的惯用语隐喻知识提取结果
3.2 基于句法模式识别的隐喻知识获取
从大规模的语料来看,惯用语的使用范围有限,对于一般名词我们以采用句法模式的提取方法作为补充,靠一些常见的表示比喻的动词“像”“如”等,或者依托一些语法结构特征来提取。由于一般性名词不同于惯用语,它一般有多种隐喻意义,所以需要对隐喻特征和隐喻属性进行分别讨论。
3.2.1 隐喻特征提取
基于句法模式识别的隐喻特征提取主要是依靠出现在隐喻句中的特征词来获取喻体的隐喻特征,在提取方法上参考了李斌[6]的思路。通过考察,我们确定了五种隐喻句的语法模式,如表5所示。
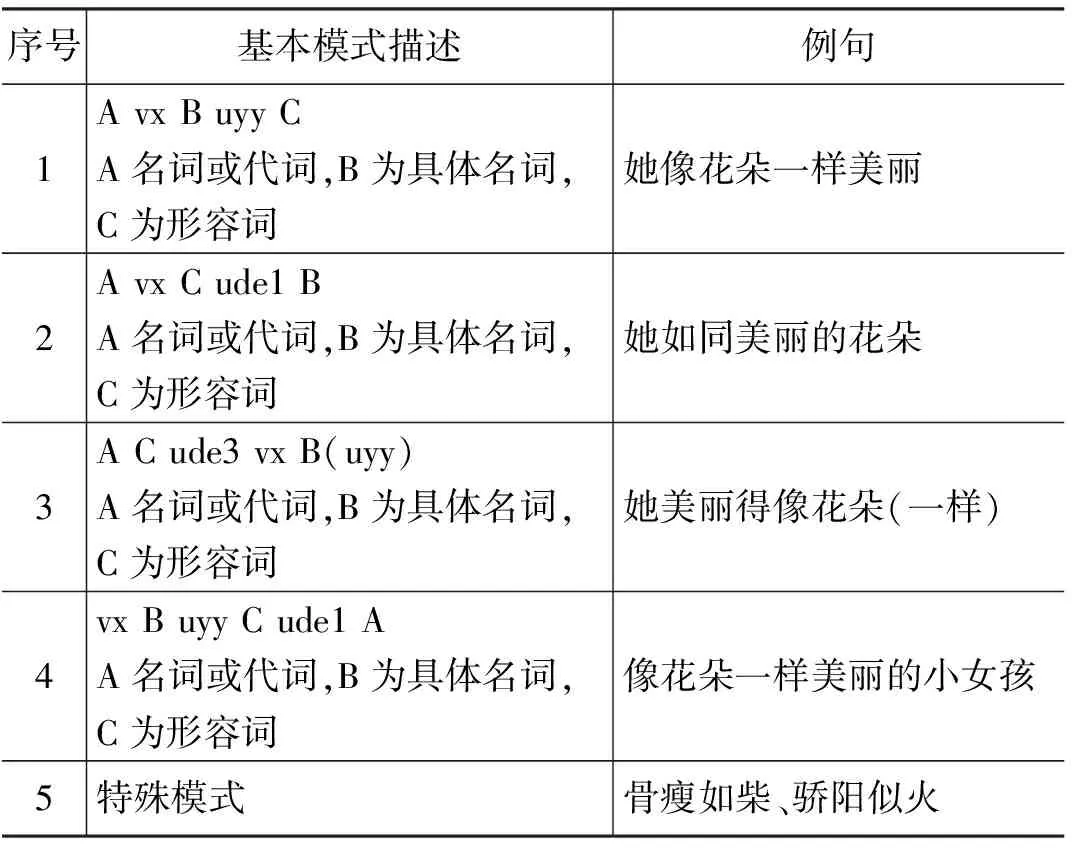
表5 隐喻句的语法模式
注: vx=“像、如同、似”等比喻动词,u=助词,yy=一样,de1=的,de3=得
基于句法模式获取汉语隐喻特征的算法如下:
Step1预处理: 获取隐喻句语料库,将语料库中语料以句子为单位进行分割,然后依次对各句进行切词和词性标注。
Step2句法模式识别: 根据各句中的词语位置和词性标注进行模式识别,剔除无法匹配的句子。
Step3提取隐喻特征: 根据不同隐喻模式,提取相应的喻源词语(具体名词)和其在句中的隐喻特征。
3.2.2 隐喻属性提取
在汉语一般名词的隐喻特征提取中,往往会提取出多个特征,为了提高隐喻意义获取的准确度,我们还需要为每个隐喻特征加上对应属性值,加以区分。
在获取属性值时,对无法归纳至群体的名词,可采用单个词语属性挖掘的方法获取隐喻属性;对于可归纳至某一群体的名词,通过群体属性挖掘方法,可提高获取隐喻属性的准确度。之后,通过搜索引擎搜索海量的语料库,提高不同候选属性和隐喻特征相关性计算的准确度。
(1) 单个词语属性挖掘方法
属性值的获取是通过基于语料库的、模板驱动的知识挖掘方法。基本思想是,具体名词的属性是指其宏观属性,由属性名词来描述。如“小姑娘”的属性包括“身高”“年龄”和“外貌”等,可以根据人们的用语习惯构建模板,直接从语料库中提取这些属性信息。模板主要有两种,如表6所示。

表6 属性值提取模板
在大规模语料库中,通过模板进行挖掘后,设定阈值,过滤出现频率低的词汇。之后根据特征值,再在语料库中进行文本挖掘,统计特征值和属性候选集中各候选项出现在同一句子中的次数。出现频率最高的候选项作为具体名词在该特征下的属性被记录。
单个词语汉语隐喻属性获取算法(见图2)如下:
Step1预处理: 获取隐语句语料库,将语料库中语料以句子为单位进行分割,然后依次对各句进行切词和词性标注。
Step2模式识别: 在具体名词出现的句子中,根据具体名词在句子中出现的位置和词性标注,进行模式识别,选取符合模板的候选属性词。
Step3过滤: 选取阈值,将出现频率低于阈值的候选词语删除,只保留出现频率高于阈值的词语,组成候选属性集。
Step4确定属性值: 再次对语料库中的句子进行文本挖掘,统计候选属性集中各项特征值出现在同一语句中的频率。出现频率最高的候选项被选取为属性值。
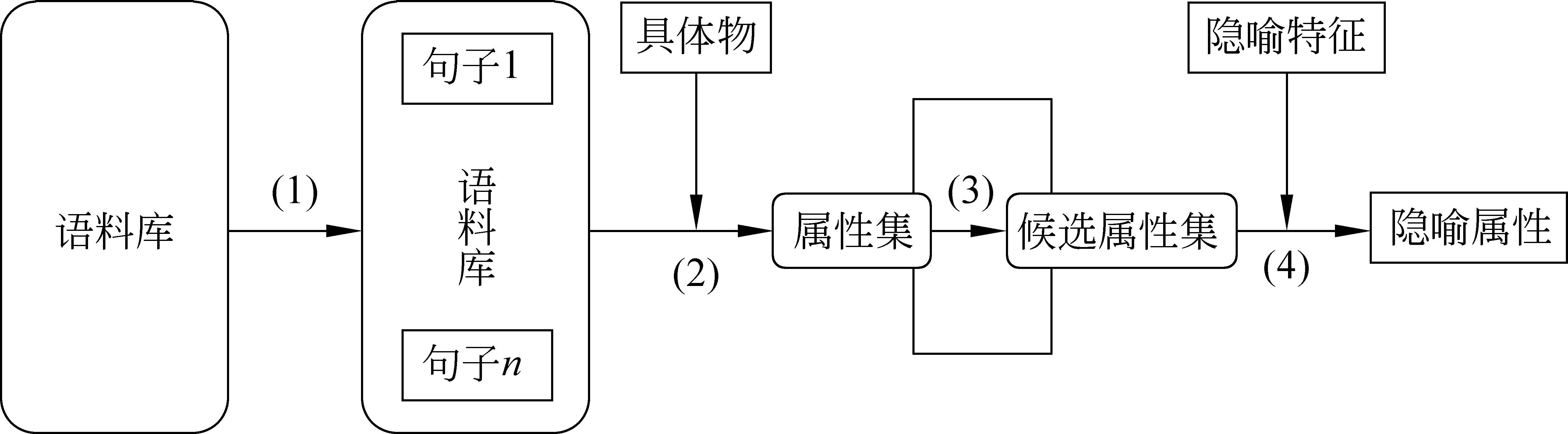
图2 基于单个词语的汉语隐喻属性获取算法
(2) 群体属性挖掘方法
通过对单个具体名词的属性进行挖掘,我们发现属于同一群体的名词在隐喻修辞中使用到的属性非常相似。
群体的属性挖掘,就是指从群体的个体实例的语言表述中,通过大规模语料的自动提取,获得其共同属性。相比于单个词语的属性获取,群体的属性挖掘可以过滤单个词语属性中并不常使用于隐喻中的“噪声”,提高属性提取的准确性。
基于群体属性的汉语隐喻属性获取算法如下:
Step1归类: 将名词划分至所属群体。
Step2单个词语属性模式识别: 在具体名词出现的句子中,根据具体名词在句子中出现位置和词性标注,进行模式识别,选取符合模板的候选属性词。
Step3群体属性获取: 根据群体中每个实例的候选属性集,设定阈值,选取出现频率超过阈值的属性作为群体共同属性,产生群体属性集。
Step4确定属性值: 再次对语料库中的句子进行文本挖掘,统计群体属性集中各项和具体名词特征值出现在同一语句中的频率。出现频率最高的候选项被选取为属性值。
(3) 基于搜索引擎的属性挖掘方法
通过实验发现,实际群体属性集的规模不大,于是我们想借助搜索引擎,通过具体模式搜索在海量数据的情境下帮助在群体属性中获取某一隐喻特征的隐喻属性。这一思路贾玉祥[10]和李斌[19]都尝试过,只是针对的对象有所差别。
基于搜索引擎的属性挖掘算法如下:
Step 1~Step 3: 同方法2。
Step 4 确定属性值: 将具体名词、特征属性和群体属性集中的每个选项都输入到搜索引擎中进行搜索,过滤掉不符合条件的搜索条目后,记录搜索条目数量,选取搜索条目最多的候选项为属性值。
这种属性挖掘方法,虽然只修改方法(2)的第四步,但是效果改进还是较为巨大。专业的搜索引擎与我们的语料库相比,存储了海量的文本数据,并且具有更加优化的关键词搜索技术,因而在获取相关性上效果更好。
4 实验与分析
本次实验中的中文分词和词性标注相关工作,选用了NLPIR汉语分词系统。《新华惯用语词典》为惯用语主要释义来源,自建语料库选取《人民日报》的部分内容和文学作品集。
4.1 基于惯用语的隐喻知识提取
我们提取了1 650个惯用语,在基于惯用语的具体名词的隐喻特征直接导入时,直接将现有的惯用语的释义作为隐喻特征导入,隐喻属性标志为空。基于惯用语导入的隐喻特性的部分生成结果如表7所示。
我们对能从名词性惯用语的释义中成功提取隐喻知识的情况作了统计,其中准确率92.6%、召回率89.4%、F值为90.97。这个数值比目前单纯地在海量文本中提取隐喻知识要高得多,这主要是由惯用语的自身特点决定的。
表7惯用语隐喻知识抽取结果示例
4.2 基于句法模式识别的一般性名词的隐喻知识提取
4.2.1 隐喻特征提取
我们从语料中提取了3 111个符合隐喻模式的句子,根据句法模式识别方法把这些符合条件的句子中的隐喻特征提取了出来,部分生成结果如表8所示。
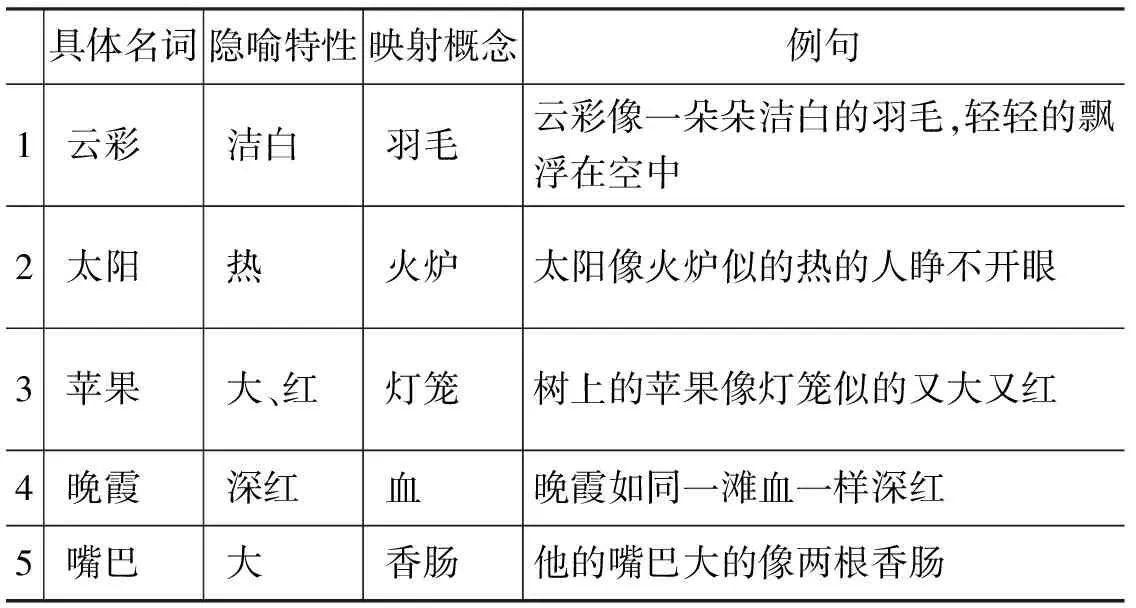
表8 基于模式识别的一般性名词的隐喻特征提取
在实验中,我们能够成功提取到隐喻特征的句子有3 028个,准确率高达97.3%,可以说基于模式识别的隐喻特征提取具有较高的准确度。
4.2.2 隐喻属性集的获取
(1) 单个词语的隐喻属性候选集生成
我们根据方法(1)从3 111个模式隐喻句中提取了2 480个单个词语的属性,通过人工校对,全部正确的只有1 382个,准确率只有55.7%,可以说准确率不是很高。但是前面三个属性的正确率却达到了82.4%,部分生成结果举例如表9所示。

表9 部分名词属性候选集
从表9中可以看出,单个词语的属性集中的候选项,部分可以作为描述具体名词隐喻特征的隐喻属性。例如,具体名词“汽车”在隐喻特征为“飞驰”的时候,“速度”是其隐喻属性;具体名词“母亲”在隐喻特征为“慈祥”的时候,“形象”是其隐喻属性。
但是也应看到,候选属性集内有一些不会成为真正的隐喻特征的属性,例如“白发”虽然常与“母亲”搭配出现,但不会成为其隐喻属性。
(2) 群体的隐喻属性候选集生成
上述数据显示,对单个词语生成隐喻属性候选集时,容易产生跟词汇内在含义相关的“噪声”,如在文学作品中,“母亲”常与名词“白发”搭配出现,然而“白发”并不是“母亲”的宏观属性,所以也不会成为其隐喻属性。但是若将具体名词先划分为一些群体,再通过选取个体实例中共同出现的属性作为群体的属性集,就可以过滤这类情况,提高准确度。
本次实验将一般具体名词划分为人、动物、景物、物品(歌曲等无形物也算作物品)四个群体,每个群体包含的部分实例如表10所示。

表10 群体与部分实例
每个群体根据实例属性集产生的群体属性集如表11所示。

表 11 群体属性集部分属性
具体名词按照群体属性集获取的隐喻属性准确度有了较大的提高,人工核查发现,隐喻属性包含在群体属性集前三名的比例超过50%。也就是说属性集的前三名基本上涵盖了具体名词一半的属性。
(3) 基于搜索引擎的隐喻属性候选集生成
隐喻属性是从隐喻属性集中选取和隐喻特征共同出现的频率最高的候选项中产生的。对于无法归类至群体的候选项,选取其单个词语候选项,否则选取其群体候选项,或基于搜索引擎进行属性挖掘。我们根据方法(3),使用必应搜索引擎,结果如表12所示。
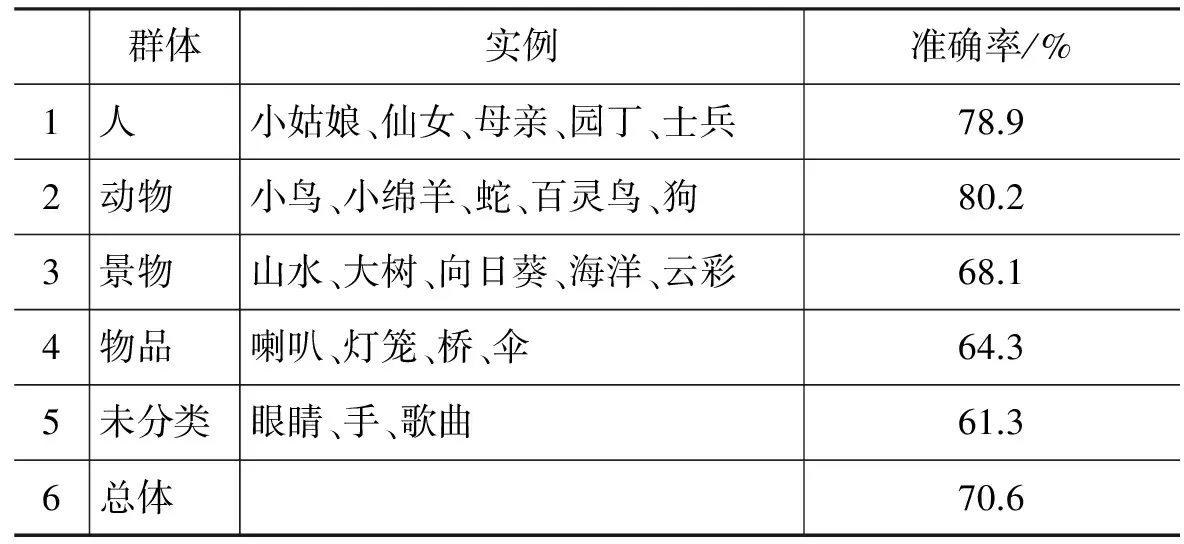
表 12 搜索引擎提取属性举例
根据表12可以看出,对群体分类的方式加上搜索引擎的搜索方式有效地提高了隐喻属性获取的准确率,总体准确率达到70.6%。这一结果表明,虽然三种方法结合可以有效提高属性值获取的准确率,但是要想找到具体名词隐喻知识中的全部属性还是有一定难度的。不过总的来说,惯用语的隐喻知识难度还是比一般名词要简单,而且准确率要远高于一般名词。
5 结论
隐喻从某种程度上讲是一种语义映射关联,但是其中起关联作用的是语义特征的相似性。本文主要是将汉语具体名词间所映射的隐喻知识以隐喻特征和相关属性的形式加以表现,通过惯用语导入和特定句法模式导入两种方法引入隐喻知识,并从中提取隐喻特征和对应属性。针对惯用语,本文主要是基于语义词典的释义来提取特征。由于惯用语的隐喻特征具有唯一性,其对应的属性也相对唯一,所以可以说惯用语的隐喻知识是静态的。而一般名词由于语境不同,在不同的句子中可能隐喻的对象往往也不同,因此一般名词的隐喻知识是动态的。针对一般句子中名词的动态隐喻知识,我们是通过一些规则性的隐喻构式来提取具体名词的隐喻特征,在获取属性值时,根据具体情况采用单个词语属性挖掘法、群体属性挖掘法和搜索引擎挖掘法来获取相关属性值。实验表明,在特征识别上取得较好效果,但在具体对应的属性值挖掘上准确率不高,这说明获得具体名词对应的隐喻属性难度要远大于隐喻特征的获取。
[1] 郭振伟.我国隐喻语料库研究现状与展望[J].浙江师范大学学报(社会科学版),2013,3(38): 38-43.
[2] 李行健.惯用语的研究和规范问题[J], 语言文字应用,2002(1): 55-60.
[3] 裴霜霜, 周榕. 借助Sketch Engine 和WordNet 进行隐喻的概念模型和语义映射分析:以目标域TIME为例[J].外语教学,2012,33(2):13-17.
[4] 田嘉, 苏畅, 陈怡疆. 隐喻计算研究进展[J].软件学报,2015,26(1): 40-51.
[5] 王治敏. 隐喻的计算研究与进展[J]. 中文信息学报,2006,20(4): 16-24.
[6] 李斌, 于丽丽, 石民,等.“像”的明喻计算[J]. 中文信息学报,2008,22(6): 27-32.
[7] 杨芸. 汉语隐喻识别与解释计算模型研究[D]. 厦门: 厦门大学博士学位论文,2008.
[8] 杨芸, 周昌乐, 王雪梅, 等. 基于机器理解的汉语隐喻分类研究初步[J].中文信息学报, 2004,18(4): 31-36.
[9] 杨芸, 周昌乐, 李剑锋. 基于隐喻角色依存模式的汉语隐喻计算分类体系[J].语言文字应用,2008(3):125-133.
[10] 贾玉祥,俞士汶. 基于实例的隐喻理解与生成[J]. 计算机科学,2009,36(3):138-141.
[11] 贾玉祥,俞士汶. 基于词典的名词性隐喻识别[J]. 中文信息学报,2011,25(2):99-104.
[12] 王治敏.名词隐喻相似度及推理识别研究[J]. 中文信息学报,2008,22(3): 37-43.
[13] 王治敏.汉语名词隐喻的语义映射分析[J].语言教学与研究.2009(3): 89-96.
[14] 王金锦, 杨芸, 周昌乐. 隐喻字面语义表示与生成[J].中文信息学报,2009,23(3): 95-102.
[15] 张威, 周昌乐. 汉语隐喻理解的逻辑描述初探[J].中文信息学报,2004,18(5): 23-28.
[16] 李行健. 现代汉语惯用语规范词典[M]. 长春:长春出版社,2002.
[17] 温端政. 新华惯用语词典[M], 北京:商务印书馆,2007.
[18] 戴帅湘, 周昌乐, 黄孝喜,等. 隐喻计算模型及其在隐喻分类上的应用[J].计算机科学,2005,32(5): 159-166.
[19] 李斌, 陈家骏, 陈小荷.基于互联网的汉语认知属性获取及分析[J]. 语言文字应用,2012,(3): 134-143.
[20] 李斌, 宋丽, 曲维光,等.基于认知属性库的原型范畴研究[J]. 中文信息学报,2016,30(6): 90-99.
[21] 苏畅. 汉语名词性隐喻的计算方法研究[D]. 厦门: 厦门大学博士学位论文.2008.
