实体驱动的双向LSTM篇章连贯性建模
2017-03-12杜舒静王明文
杜舒静,徐 凡,王明文
(江西师范大学 计算机信息工程学院,江西 南昌 330022)
0 引言
篇章连贯性是衡量篇章中句子间语义是否通顺和形式是否衔接的一个重要因素。因此,篇章连贯性建模对于统计机器翻译、自然语言问答、自然语言生成等研究具有重要的作用。根据系统功能语言学家Halliday所述,连贯性是一种具有逻辑意义的内在语义关联,连贯的篇章由一些逻辑上或语义上存在某种相似元素的段落或句子组成,这是篇章的一个基本特征[1]。此外,衔接性是篇章的另外一个基本特征,它是连句成章的词汇和语法方面的手段,指的是语篇中表层结构上的黏着性,是语篇的有形网络;相比较而言,连贯是采用这些手段所产生的结果,指的是语篇中底层语义上的关联性,是语篇的无形网络[2]。下面例子分别为连贯和不连贯的篇章。
例1连贯的篇章实例:
① 张三吃了很多食物,②由于所吃的食物大部分是高脂肪的,③所以张三体重超标了。
例2不连贯的篇章实例:
① 张三吃了很多食物,②由于他昨天买了很多衣服,③所以张三体重超标了。
其中,例1的分句①和分句②阐述了事件的主人公及发生的事件,分句③说明了事件的结果,三个分句都存在相似的成分“张三”;然而例2中的分句② 和其余的分句在内容上是不相关的,其中分句①和分句③是在阐述事件的主人公以及事件的结果,而分句②却在阐述一个与当前篇章无关的事件。从篇章的衔接性(实体重复)角度看,例1是连贯的篇章,而例2则是不连贯的篇章,因此,衔接性(实体重复)有助于篇章连贯性建模。
篇章连贯性建模是自然语言处理中的一个基础问题,它在多语言即时机器翻译[3]、文本自动摘要[4-6]、作文自动评分[7-9]等方面均有广泛的应用前景。传统的基于实体网格的篇章连贯性模型需要花费大量的时间进行特征提取,且太过依赖实体特征,如果篇章中含有的实体较多,可能会对实体网格模型产生一些噪声,导致实体网格模型的准确率下降。而现有的基于深度学习的模型仅通过学习文本本身的信息来对文本进行篇章连贯性建模,没有考虑篇章中句子间的实体链接对于篇章连贯性建模的重要作用,只是初步学习了篇章连贯性来对其进行建模,并未能进一步挖掘和利用篇章的连贯性。基于此,本文模拟人阅读篇章时利用篇章连贯性的名词重复阅读的习惯,进一步探究篇章连贯性。首先抽取篇章中相邻句子的实体信息,将其进行分布式表示来模拟人利用名词重复阅读的习惯,然后将此信息通过向量操作融合至句子级的双向LSTM深度学习模型之中。在汉语和英语篇章语料上的句子排序和机器翻译连贯性检测两种任务上的实验表明: 本文提出的模型性较现有模型有显著提升。
本文的后续内容安排如下: 第一节介绍篇章连贯性建模的相关工作;第二节着重阐述本文提出的实体驱动的双向LSTM篇章连贯性模型;第三节给出了实验设置及详细的实验结果分析;第四节是结论及后续工作部分。
1 相关工作
本节主要从基于特征抽取的篇章连贯性模型和基于深度学习的连贯性篇章模型两个方面概述相关工作。
1.1 基于特征抽取的模型
传统的篇章连贯性建模主要通过抽取出反映篇章连贯性方面的特征(如文本的潜在语义、实体的语法成份或篇章修辞关系等)进行工作。其中,1998年FoltzPW等人[10]提出基于潜在语义(latentsemanticanalysis,LSA)的篇章连贯性模型,该模型通过学习文本的潜在语义对文本的篇章连贯性建模,获取文本的潜在语义。但是,该模型在降维的时候可能会丢失一些包含篇章连贯的信息,导致无法捕获较为全面的篇章连贯信息。2004年Barzilay等人[4]提出了基于隐马尔科夫(hiddenmarkovmodel,HMM)的篇章连贯性模型,该模型通过对文本的主题以及这些主题出现的顺序进行分析,对特定领域内的文本内容结构进行篇章连贯性建模。该模型的局限是受领域的影响很大,不适用于开放的领域。此外,基于实体的网格模型[4,11-12]是目前较为流行的传统模型,该模型通过将篇章中实体作为网格的格点,将不同句子间实体的语义角色(如主语、谓语和其他)的转换作为格点间的连线,以网格的形式描绘对篇章的连贯性加以建模。此后的很多工作都是基于该模型开展的改进工作[14-16]。综上所述,传统的篇章连贯性建模均需要进行特征提取工作,代价总体而言比较高。
1.2 基于神经网络的模型
当前,深度学习在图像处理[17]、计算机视觉[18]和语音识别[19]等方面均取得了非常显著的成绩。同样,其在自然语言处理的统计机器翻译[20]、问答系统[21]、自然语言生成[22]等方面也取得了不错的成果。针对篇章连贯性建模方面,2014年李纪为等人提出基于分布式句子向量表示的神经网络模型[23],该模型分别利用两种RNN(recurrentneuralnetWork和recursiveneuralnetWork)表示篇章中的句子分布式向量,然后利用构建团的方式对篇章连贯性加以建模。此外,2016年李纪为等人提出了开放领域的生成式模型和判别式模型[24],该模型通过学习不连贯的文本及训练大量的开放领域语料来获取篇章连贯性。
总之,基于神经网络的模型可以免去传统方法中繁琐的特征工程步骤,自动提取出篇章中表示连贯性的各种词汇和句法特征,具有一定优势。
2 实体驱动的深度学习模型
递归神经网络(recursiveneuralnetworks,RNNs)能够有效地对时间关系进行建模,通过输入序列到隐藏层的映射能够学习到复杂的时间动态关系,已被成功应用于语音识别、机器翻译和行为识别等领域,尤其是时间递归神经网络(long-shorttermmemory,LSTM),能够应用于处理和预测时间序列中间隔和延迟非常长的重要事件。基于此,本文将利用双向LSTM构建篇章中句子的分布式向量表示形式。
由于现有的基于深度学习的篇章连贯性模型没有充分考虑篇章中句子间的实体链接对于篇章连贯性建模的重要作用。本文首先抽取篇章中相邻句子间的实体(名词)信息,并将其进行分布式表示,以此模拟句子间实体的链接,然后将此信息通过向量操作融合至句子级的双向LSTM深度学习模型之中。图1所示是本文提出模型的框架,主要由句子的双向LSTM表示、句子的实体驱动向量、基于团的篇章连贯性表示三个模块构成。
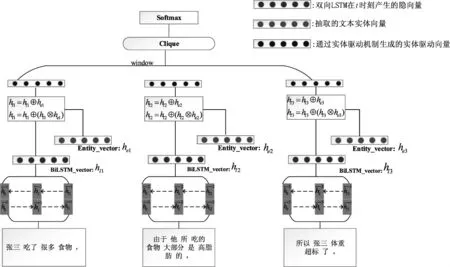
图1 实体驱动的双向LSTM模型
从图1中可以看出,本文的模型首先借助分词工具对语料进行分词,之后用词向量工具训练语料生成词向量,将得到的词向量输入LSTM中得到句子的表示BiLSTM_vector,同时将分词后的语料进行词性标注,并且将语料中名词对应的向量Entity_vector提取出来,并将BiLSTM_vector和Entity_vector进行图1中的公式的运算操作,得到本文提出的实体驱动向量,之后将实体驱动向量融入相邻一定大小句子组成的团,就句子排序任务而言,每次随机替换原文中的句子生成负例,原始文本为正例;如果置换文本的连贯性得分大于原始文本的得分,则将其看成连贯的文本,否则就是不连贯的文本;就机器翻译连贯性任务评估而言,每次学习人工译文为正例,机器生成译文为负例,计算和判别过程类似。本文将在接下来的两节中自底向上地描述图 1的组成。
2.1 句子的双向LSTM表示
首先,本文采用glove*http://code.google.com/p/word2vec/和word2vector*http://nlp.stanford.edu/projects/glove/训练篇章语料生成词向量表示形式,可以为句子中的每个词w训练生成一个k维向量表示xw∈De。语料中的每个句子都可以看成一系列词向量,用xi表示句子S中的第i个词向量,则含有L个词的句子可以被表示为SL=[x1,x2,...,xL],最终通过双向LSTM训练得到k维句子向量SL。图1中LSTM模型的相关参数计算公式如下:
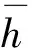
2.2 句子的实体驱动向量
借助双向LSTM获得文本中句子的分布式表示后,本文希望模拟人阅读文章时利用名词重复阅读的习惯进行篇章连贯性建模。即通读文章时,人们往往会先记住文章中相邻句子中的一些实体(名词),然后根据这些实体间的重复关系来推测整篇文章的大义。鉴于此,本文设计了实体驱动的方法来强化篇章中句子间的名词的重要作用。
首先将文本中句子间的实体(名词)抽取出来,然后得到它们的分布式向量表示形式,最后将这些实体向量(见式(7),其中符号⊕代表向量点加操作)与句子的双向LSTM分布式表示进行拼接,得到句子级别的最终向量表示(见式(8)和式(9),其中符号⊕代表向量点加操作,符号⊗代表向量点乘操作):
对于原始句子的表示,本模型首先将语料借助词向量工具训练得到的词向量输入双向LSTM,得到隐向量ht(其初始值是将训练好的词向量输入双向LSTM后得到的句子向量),同时用一个额外的存储容器存储文本中的实体向量。最初本文对实体向量仅仅进行了点加操作和点乘操作,来得到实体向量的多种表示方式,之后对数据集和实验结果进行分析,发现有一些句子可能不存在实体向量,仅对向量进行点乘的操作可能太粗糙了,因此本文对点乘操作进行了类平滑操作,得到了乘法操作。本文采用的加法和乘法操作如下:
2.3 基于团的篇章连贯性表示
本模型首先将含有L个相邻句子的滑动窗口视为团C,利用团C中所有的句子向量拼接表示团向量,其大小为(L+1)*k维,如式(10)所示。
然后,为每个团C定义一个相应的标签yc,如果团C是连贯的,则标签yc的值为1,否则标签yc的值是0。同时,将团C向量输入sigmod函数,如式(11)所示。
最后,整个篇章的连贯性得分为每个团的连贯性得分的乘积,如式(12)所示。
连贯性得分越大的文本越连贯,即假设两篇文本d1和d2的连贯性得分分别为Sd1和Sd2,如果Sd1大于Sd2,则文本d1比文本d2更连贯。
2.4 模型训练和优化
对于句子排序任务。本文首先用训练集来训练本文提出的模型,即将人工生成的文本作为正例,随机置换原始文本的句子生成的文档作为负例,本文的模型要学到测试集中的正例和负例的连贯性得分之间存在的关系;之后再对测试集进行打分,得到句子排序的连贯性分数,对于机器翻译连贯性评估。本文用人工译文作为训练集的正例,机器翻译得到的译文作为负例,首先用本文的模型学到测试集中的正例和负例的连贯性得分之间存在的关系,之后再对测试集进行打分,得到机器翻译连贯性评估分数。
本模型采用目前广泛使用的交叉熵函数作为目标函数,如式(13)所示。
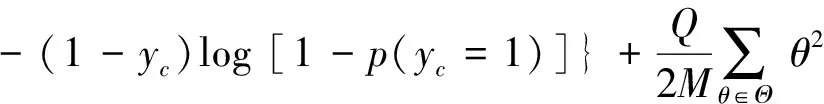
( 13)
本文采用了自适应梯度下降法AdaGrad[28]来优化此损失函数,它能够对每个参数自适应不同的学习速率,对稀疏特征得到大的学习更新,对非稀疏特征,得到较小的学习更新,是目前广泛使用的优化算法。
3 实验
为了验证提出的实体驱动双向LSTM篇章连贯性模型的性能,本文在标准语料库上进行了汉语和英语环境下的句子排序和机器翻译连贯性评估两组实验。其中,句子排序任务是给定原文本和随机置换句子顺序的置换文本,假定原文本比置换文本更连贯;机器翻译连贯性评估则是自动识别出比机器自动生成译文更连贯的人工参考译文。同时,本文进行了五倍交叉实验对模型加以验证。
3.1 数据集及评价指标
(1)英文句子排序数据集: 采用了文献[12]使用的两种不同文体的国际基准语料: 地震(earthquake)语料和飞机失事(airplane)语料。其中,训练集分别由99篇地震语料和100篇飞机失事语料组成,测试集分别由100篇地震语料和100篇飞机失事语料以及随机置换原始文本中句子顺序生成的置换语料组成,同时规定每篇原始文本最多生成20个置换文本。
(2)中文句子排序数据集: 分别采用了两种汉语篇章数据集作为语料。其一是汉语树库CTB(Chinese TreeBank)6.0对应的原始文件,其二是本文学校某学院标注的130篇汉语作文。其中,对于CTB语料,选择从chtb_2946到chtb_3045在的100个文档作为训练数据,从chtb_3046到chtb_3145的99个文档及其置换文本作为测试数据集。对于汉语作文语料(汉语作文),本文选取其中的前65篇作为训练集,其余的文档以及随机置换文档作为测试集,同时规定每篇原始文本最多生成20个置换文本。
(3)机器翻译连贯性评估数据集: 从语言数据联盟(linguistic data consortium,LDC)中提取NIST Open Machine Translation 2008评估中的汉英翻译作为语料(Smt_translation),其索引号为LDC2010T01和ISBN1-58563-533-2,该数据集中含有128组成对的文件(128篇人工参考译文和128篇机器自动翻译得到的译文)。
(4)语料预处理: 本实验的词向量利用词向量工具word2vector[29]以及glove[30]训练得到;同时采用斯坦福的词性标记工具*http://nlp.stanford.edu/software/提取出篇章中句子的实体,同时利用ICTCLAS*http://ictclas.nlpir.org/downloads进行中文分词。
(5)评价指标: 本实验采用的评价指标是准确率,即数据集中有m篇文本,预测数据集中连贯的文本数为n,准确率等于n除以m得到的数值。
此外,本文参考文献[18]的参数设置,将AdaGrad的初始学习率设置为0.1,词向量的维数设置为300,防止过拟合的Droprate设置为0.2,滑动窗口的大小设置为5。
3.2 实验结果
本节分别给出汉语和英语环境下的句子排序任务,以及机器翻译连贯性评估任务下的实验结果,并进行详细的实验结果分析。
3.2.1 中英文句子排序实验结果
为了体现英汉实验环境的公平性,本文先采用英文语料重现了英文语料下的神经网络实验,然后将其移植至中文环境。同时,本文分别验证了word2vec和glove两种词向量下的性能,word2vec的性能显著优于glove性能,为了找到最适合做篇章连贯性建模的语料设置,先采用word2vec和glove生成的不同维数的向量进行实验;同时为了找出较适合篇章连贯性的语料形态,在语料预处理时本文将语料生成为一句一行及一词一行的形式,以期望找到较适合篇章连贯性建模的语料形态。通过对该实验的结果进行分析,发现形态为一句一行的语料,借助word2vec生成的300维词向量最适合篇章连贯性建模,限于篇幅,本文以下均提供采用该种词嵌入的实验结果。下面介绍所采用的基准模型。
基准模型1实体网格模型(entitygraphbasedmodel[14]),一个具有代表性的基于特征工程的传统篇章连贯性模型,本文利用文献[14]中提供的开源代码*http://github.com/karins/CoherenceFramework.重现了该模型,同时将此模型移植至中文环境。
基准模型2神经网络模型,该模型仅利用双向LSTM对篇章连贯性进行建模,本文重现了此模型,同时将其移植至汉语环境。
表1显示了中英文句子排序任务的系统性能对比实验结果。实验采用的语料是3.1节中的中文句子排序数据集和英文句子排序数据集,实验结果表明本文提出的实体驱动模型明显优于基准模型,原因在于airplane语料中有约 29.32%的名词,earthquake语料中有约30.67%的名词,作文语料中有约22.01%的名词,ctb语料中有约25.76%的名词。对于名词含量比较大的数据集(类似于earthquake和CTB)而言,由于含有的名词数量较多,对实体网格模型可能存在一些噪声,因而它们在实体网格模型上的结果较低,同时由于一般的深度学习模型没有充分挖掘出这种名词间的依赖关系,导致模型的性能也存在一定的局限。
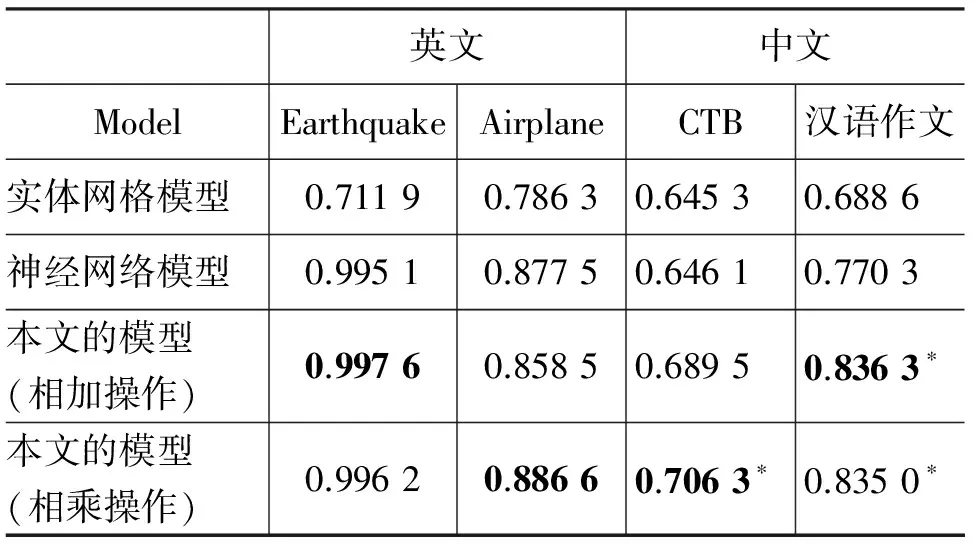
表1 中英文句子排序性能
根据进一步分析,本文的模型(相加操作)更适合学习名词较多的语料集,本文的模型(相乘操作)则更适合学习名词较少的语料集。其中,本文的模型(相加操作)主要是对抽取的实体向量与LSTM向量进行按位相加操作,而本文的模型(相乘操作)主要是对抽取的实体向量与LSTM向量进行按位相乘操作。总体上,本文的模型(相乘操作)比较稳定,显著优于现有的基于实体和基于神经网络的模型。结果表明,本文提出的实体向量对于篇章连贯性建模具有重要作用,而且可以多种有效的方式(相加或相乘)与现有神经网络模型加以融合。此外,经过显著性测试,本文模型在中文情况较现有模型有显著的提升(采用成对的t-检测对应的p<0.01),即便对于性能比较好的英文情况,本文模型的性能仍有小幅度的提升。
3.2.2 机器翻译连贯性评估实验结果
表2显示了机器翻译连贯性评估任务的性能对比实验结果。实验采用的数据集是3.1节中的机器翻译连贯性评估数据集。实验结果表明: 本文的模型(相加操作)更适用于机器翻译的连贯性评估,机器翻译语料中名词约有24.21%,参考译文中含有约25.51%的名词,机器翻译得到的译文中含有约22.75%的名词,虽然Smt_translation 语料中名词比例与句子排序的中文语料CTB和作文语料比例类似,但由于机器翻译连贯性检测任务比句子排序任务更具有挑战性,其原因在于前者需要区分比较相近的人工参考译文与机器生成译文,而句子排序任务中原文件和置换文件的可比较性不高,从而导致传统的实体网格方法和传统神经网络方法的识别性能均不高,但本文将两者融合后,性能得以显著提升,说明本文的模型将实体信息融入机器学习中能较好地评估机器翻译连贯性,充分说明了实体的分布式表示与现有深度学习模型之间具有一定的互补作用。此外,显著性测试显示,本文模型在中文情况下较现有模型的性能有显著性提升(采用成对的t-检测对应的P<0.01)。
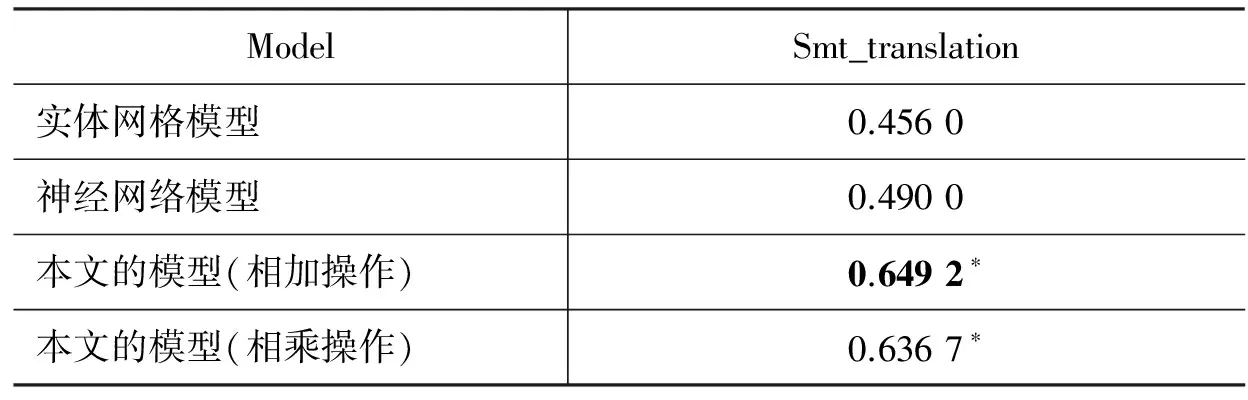
表2 机器翻译连贯性评估五倍交叉验证实验
4 总结与展望
本文提出了一个实体驱动的神经网络篇章连贯性模型。由实验结果可知: 本文的模型(相乘操作)更好,在句子排序和机器翻译连贯性评估任务上均有稳定的性能提升。本文的模型既避免了需要耗费大量时间的特征工程,又充分考虑了篇章中句子间的实体链接对于篇章连贯性建模的重要作用。因此,本文首先抽取出篇章中相邻句子的实体信息,将其进行分布式表示,然后将此信息通过多种简单且有效的向量操作融合至句子级的双向LSTM深度学习模型之中。在汉语和英语篇章语料上的句子排序和机器翻译连贯性检测两种任务上的实验结果表明本文提出的模型在性能上较现有模型具有显著提升。
[1] Halliday M A K.An introduction to functional grammar[M].New York: Oxford University Press Inc, 2004.
[2] 黄国文.语篇分析概要[M].长沙: 湖南教育出版社,1987.
[3] Heidi J F. Phrasal cohesion and statistical machine translation[C]//Proceedings of EMNLP, 2002: 304-311.
[4] Regina B, Lillian L. Catching the drift: probabilistic content models, with applications to generation and summarization[C]//Proceedings of NAACL-HLT, 2004: 113-120.
[5] Lin Zi Heng Lin, Hwee Tou Ng, KAN Minyen. Combining coherence models and machine translation evaluation metrics for summarization evaluation[C]//Proceedings of ACL, 2012: 1006-1014.
[6] Danushka Bollegala, Naoaki Okazaki, Mitsuru Ishizuka. A bottom-up approach to sentence ordering for multi-document summarization[C]//Proceedings of ICCL-ACL, 2012: 385-392.
[7] Helen Yannakoudakis, Ted Briscoe. Modeling coherence in ESOL learner texts[C]//Proceedings of ACL,2013: 33-43.
[8] Jill Burstein, Joel Tetreault, Slava Andreyev. Using entity-based features to model coherence in student essays[C]//Proeedings of NAACL-HLT, 2010: 681-684.
[9] Derrick Higgins, Jill Burstin, Daniel Marcu, et al. Evaluating multiple aspects of coherence in student essays[C]//Proceedings of NAACL-HLT, 2004: 185-192.
[10] Foltz P W, Walter K, Thomas K L.The measurement of textual coherence with latent semantic analysis[J].Discourse Processes, 1998, 25(2&3): 285-307.
[11] Regina Barzilay, Mirella Lapata. Modeling local coherence: an entity-based approach[C]//Proceedings of ACL, 2005: 141-148.
[12] Regina Barzilay, Mirella Lapata. Modeling local coherence: an entity-based approach[J].Computational Linguistics, 2008, 34(1):1-34.
[13] Mirella Lapata, Regina Barzilay. Automatic evaluation of text coherence: Models and representations[C]//Proceedings of IJCAI, 2015: 1085-1090.
[14] Camille Guinaudeau, Michael Strube. Graph-based local coherence modeling[C]//Proceedings of ACL, 2013: 93-103.
[15] Feng V W, Hirst G.Extending the entity-based coherence model with multiple ranks[C]//Proceedings of EACL, 2012: 315-324.
[16] Ak John, Ld Caro, G Boella. Text segmentation with topic modeling and entity coherence[C]//Proceedings of International Conference on Hybrid Intelligent Systems, 2016:175-185.
[17] Wang Z, Lu J, Lin R, et al. Epithelium-stroma classification via convolutional neural networks and unsupervised domain adaptation in histopathological images[J]. IEEE Journal of Biomedical & Health Informatics, 2017(99): 1.
[18] Paul A, Dey A, Mukherjee D P, et al. Regenerative random forest with automatic feature selection to detect mitosis in histopathological breast cancer images[C]//Proceedings of MICCAI 2015,Part Ⅱ, 2015: 94-102.
[19] 杨明翰,许曜麒, 洪孝宗,等. 融合多任务学习类神经网路声学模型训练于会议语音辨识之研究[C]//Proceedings of the 28th Conference on Computational Linguistics and Speech Processing, 2016:016-1001.
[20] Mi Haitao, Wang Zhiguo, Abe Ittycheriah. Supervised attentions for neural machine translation[C]//Proceeding of the EMNLP,2016:2283-2288.
[21] Tan Ming, Cicero dos Santos, Xiang Bing, et al. Improved representation learning for question answer matching[C]//Proceedings of ACL, 2016: 464-473.
[22] Natsuda Laokulrat, Sang Phan, Noriki Nishida, et al. Generating video description using sequence-to-sequence model with temporal attention[C]//Proceedings of COLING, 2016: 44-52.
[23] Li Jiwei, Eduard Hovy. A model of coherence based on distributed sentence representation[C]//Proceedings of EMNLP, 2014: 2039-2048.
[24] Li J, Jurafsky D. Neural net models for open-domain discourse coherence[J]. arXiv preprint arXiv:1606.01545, 2016.
[25] Graves A. Long short term memory[J]. Springer Berlin Heidelberg, 2012, 9 (8):1735-1780.
[26] Sak H, Senior A, Beaufays F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling[J]. Computer Science, 2014:338-342.
[27] Tai K S, Socher R, Manning C D. Improved semantic representations from tree-structured long short-term memory networks[J].Computer Science, 2015, 5(1):26- 36.
[28] John Duchi, Elad Hazan, Yoram Singer, Adaptive subgradient methods for online learning and stochastic optimization[J], Journal of Machine Learning Research, 2011, 12 (7):2121-2159.
[29] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[C]//Proceedings of ICLR Workshop, 2013:3-1127.
[30] Jeffrey Pennington, Richard Socher, Christopher D. Glove: Global vectors for word representation[C]//Proceedings of EMNLP, 2014:1523-1543.
