基于词汇聚类方法的现代汉语分期与分期体系构建
2017-03-12饶高琦李宇明
饶高琦,李宇明
(1. 北京语言大学 对外汉语研究中心,北京 100083;2. 北京语言大学 语言政策与标准研究所,北京 100083)
0 引言
进行有关现代汉语历史变迁的研究无法不涉及分期问题。以往对现代汉语史的研究多直接借用政治史的分期方式将现代汉语分为新文化运动到1949年、1950—1966年、1967—1976年和1977—至今四个时期,并在这一基础上开展了许多研究[1-4]。虽然语言生活,尤其是本文使用的报刊历史语料,在内容上与政治生活有密切联系,但语言系统有其自身的演变规律。从语言数据出发对语言进行分期是更加合适的选择。传统的分期方法缺乏定量分析,往往根据相对孤立的语法现象和语法点进行分析,无法根据广泛的语言使用情况来获得较合理的分期依据。
本文将语言的分期落实在语料的分期中。语料的分期则可以视作不同时间文本的自然分组任务,即聚类问题。本文基于历史的词汇分层工作的结果[5-6],使用机器学习方法对历史语料库中的文本进行自动聚类。以期从词语使用的角度,进行定量的历史语料时期划分。
1 基础工作
1.1 历史语料库
本文使用的语料为BCC历史检索系统*http://bcc.blcu.edu.cn/hc.[7-8]中1946年到2015年的《人民日报》语料*由于种种原因,本文实验过程中没有获得2003年到2008年的《人民日报》语料,该部分由实验室积累的相应年份的《贵州日报》替补。,时间跨度70年,规模12亿字。使用GPWS通用分词系统*宋柔,罗智勇. 现代汉语通用分词系统(GPWS v3.5)http://democlip.blcu.edu.cn:8081/gpws/.[9]并辅之以小规模人工修正对历史语料库进行分词,词种数约220万。
1.2 时间敏感词
饶高琦[5]基于70年跨度的历史报刊语料库,使用了包括TF-IDF、互信息、联合熵、变异系数、词项随机采样、修正频率、累积频率等九种统计方法计算了词汇在历史中的使用稳定性,并通过对稳定性、覆盖度和时间区分性能的考察,确定了以月为划分文本的时间颗粒度、以TF-IDF为主的计量方法,并获得了规模为3 013词的历时稳态词候选词集。其中词语的时间敏感性极差,包括功能词和基本名词等,构成语言生活的底层,即基干层。
饶高琦[6]发现,基干层之外的词汇中,以月颗粒度计算TF-IDF值按降序排列,第10 000到50 000位之间的词汇对时间变化较为敏感,且平均频次较大,例如,合作社、非典、拨乱反正等。它们与快速出现获得较高频次,但迅速退出使用的命名实体有很大不同。这部分词汇构成了时间敏感层。许多时间敏感的社会语言现象多由这一层中的词语构成。流行语和年度词亦多出自此层。
1.3 聚类算法
本文选择K均值算法和期望最大化算法对历史语料库中的文本进行聚类,并使用机器学习平台Weka*http://www.cs.waikato.ac.nz/ml/weka/.[10]实现。
K均值(K-means)算法是一种十分常用的聚类机器学习算法,也是一种基于距离的迭代聚类算法[11]。本文中的K均值算法采用欧氏空间距离。其优点是可以确保一个类中每个实例到中心的距离平方和最小。但聚类数量K需要人工指定,且只能获得局部距离平方和最小值。通常通过对不同K值进行多次实验来寻找较优的聚类数量,对特定K值进行多次实验则可以在一定程度上克服无法获得全局最优聚类的缺陷。根据经验K均值方法中的聚类数K≪N,N为样本数量,在本文中就是历史语料的年数。
期望最大算法(expectation-maximum algorithm)是一种基于统计的聚类方法,其基础是建立一个限混合(finite mixtures)统计模型[12]。期望最大算法在给定一个(随机)初始值后不断进行迭代,进行重新估计直到收敛。该算法的优势在于无需事先指定聚类数量(分布的数量),但同样不能保证收敛于全局极大值。为了有机会获得全局极大值,需要对同一组数据进行多次试验。
2 对历史语料进行聚类
本文在历史语料库中提取各年度的词表,使用基干层词汇和时间敏感层(简称词敏层)词汇两个时间敏感性几乎相反的词集进行处理,以获得进行聚类实验的特征集,处理方法如下。
处理A在第i年词表Lexi中保留出现的时敏层词汇Ssens,即FAi=Lexi∪Ssens。FAi为第i年的特征集。

将两种方法处理后获得的特征集FAi和FBi中的词当作聚类特征,把其在当年的频率当作特征值,分别使用K均值和期望最大化两种方法进行聚类。语料的时间颗粒度为年。
由前文已知K均值和期望最大化算法的缺陷,每种实验设定均对相同数据进行五次实验以获得稳定的聚类结果。表1是K均值选取不同聚类数时的聚类结果。

表1 K均值在不同聚类数时的实验结果
表2是期望最大化算法自动获得聚类数时的聚类结果。
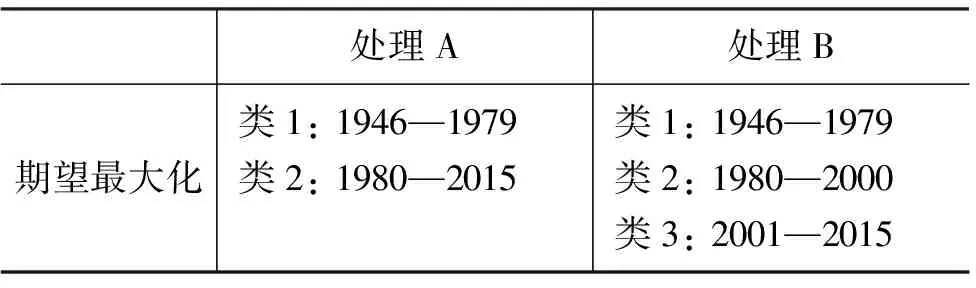
表2 期望最大化算法实验
语言的演变是连续而渐进的,依据语言特征的时间演变进行聚类,其结果在时间轴上也应当是连续的,即一个聚类应由年份连续的语料组成。
通过对表1的观察,发现处理A仅在聚类数量增加到7的时候开始出现类和类之间互相穿插的现象,如类1和类2将彼此切割成了3段和2段。处理B在许多实验的聚类数量下容易出现类和类之间互相穿插的现象。如K=2和3时类1被类2截为两段;K=6时类1和类2则互相穿插多次,而且K>2的聚类中始终都存在一个孤立点。这与语言演变具有渐变性的认知有较大的冲突。因而处理B在使用K均值算法进行的聚类中并不是一种好的选择。处理A在聚类数量增加到7时,聚类质量也开始变差。下一节将选择聚类数从2到7的实验进行分析。
我们尝试对处理B的较差效果进行解释。处理B是将每年词表去除出现在当年的基干层词后的结果。每年语料的特征数量过于庞大,词汇繁杂。其中既有时间敏感性略差的介于基干层与时间敏感层之间的词汇,也有大量超低频的出现时间极短的词汇(大多是命名实体)。这些特征对聚类过程形成了一定干扰。
与K均值不同,在期望最大化算法的结果中,两种处理方式都有较好的表现。期望最大化算法在处理B时的聚类结果和K均值算法中聚类数量K=3时的结果一致。期望最大化算法中使用处理A时的聚类结果和K均值算法中聚类数量K=2时的结果一致。这也在一定程度上使我们可以更确信地在后文中使用K=2和3时的K均值的聚类结果。
3 聚类结果分析
语言变化的速率是不均匀的。当变化较快,在一个特定时间单位(如年)内无法刻画变化过程的时候,该时间单位就形成一个边界。而较为缓慢的变化可以在几个时间单位内被观察到,这就形成了若干时间单位构成的一个过渡(地带),更加缓慢的变化以至于在很长一段时间内保持稳定,那么就形成了前文中所描述的一个聚类,其现实意义就是一个时期。本节通过这三种方式对聚类结果进行分析,从而获得语言使用的时期信息。
K均值在不同聚类数量下的聚类结果给我们提供了一扇观察历史语料分期,尤其是历史词汇使用分期的窗口。K均值在处理A的特征集FAi的实验中存在一些较为稳定的聚类边界。如1979—1980年的边界在聚类数为2、3和4时均无变化,在聚类数为5、6时变化为1977—1978年边界和1978—1979年边界。聚类边界的移动或变化是算法受聚类数量影响的结果。但其移动幅度小说明类的聚类比较稳定。聚类的小幅度移动也符合对语言使用演变是渐变的假设,刚性的边界在语言使用的变化中可能不多见。因此本节将聚类的边界模糊处理,即将较少的若干个样本(即若干年的语料)视作两个聚类的过渡,如1979—1980年边界可以扩大为1977—1980年过渡。
聚类数为3时的2000—2001年边界在聚类数量为4—6时可以扩大为1997—2002年过渡。聚类数为5时的1988—1989年边界在聚类数量为6时可以扩大为1988—1990年过渡。聚类结果中也存在不变化或移动的边界,如2007—2008年边界在聚类数量为4时出现,在后来的实验中保持稳定,并未变化。而1964—1965边界出现的很晚(K=6时才出现),也未移动或变化。
如果将上述边界和过渡都整理到一张树状图(图1)中,就可以较清晰地看到1946—2015年历史语料由词汇使用来划分的年代分期情况。
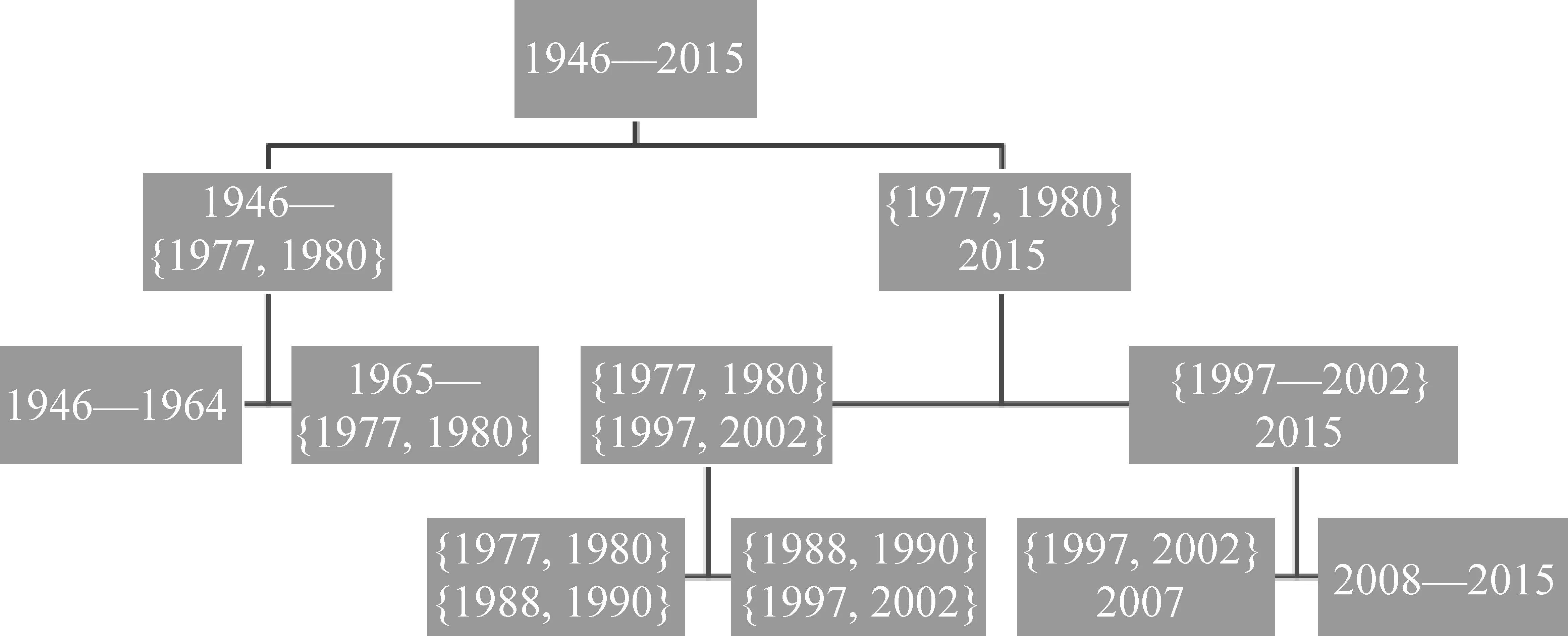
图1 基于K均值方法的历史语料词汇使用分期
图中,{m,n}表示年份m到年份n形成的过渡,如{1988,1990}为前文中描述的1988—1990年过渡。我们将边界、过渡和聚类的数量同时映射到一张树形图上,可以得到图2,以反映分期和聚类数量之间更直观的关系。
图3则将不同聚类数目中的分期结果绘制在时间轴上。深浅差异用来表示不同的聚类分裂的早晚和亲疏关系。
如前文所述,这些“边界”或“过渡”中,1977—1980年过渡和1997—2002年过渡也在期望最大化算法中出现,将语料分为两个或三个相对稳定聚类。而它们出现时的实验设定(K=2和3)也表明,如果只将历史语料划分为两段,那么应该选择1977—1980年进行切分。如果划分为三段,应该再将80年代至今划分为80年代到2000年和新世纪以来两个阶段。
这一划分结果和对过去70年语言生活变迁的直观感受基本相符。1977—1980年过渡是改革开放政策开始并逐渐起步的阶段,语言使用的情况随着国人思想的变化焕然一新。可以说改革开放的开始是过去70年词汇使用变迁最重要的分水岭。
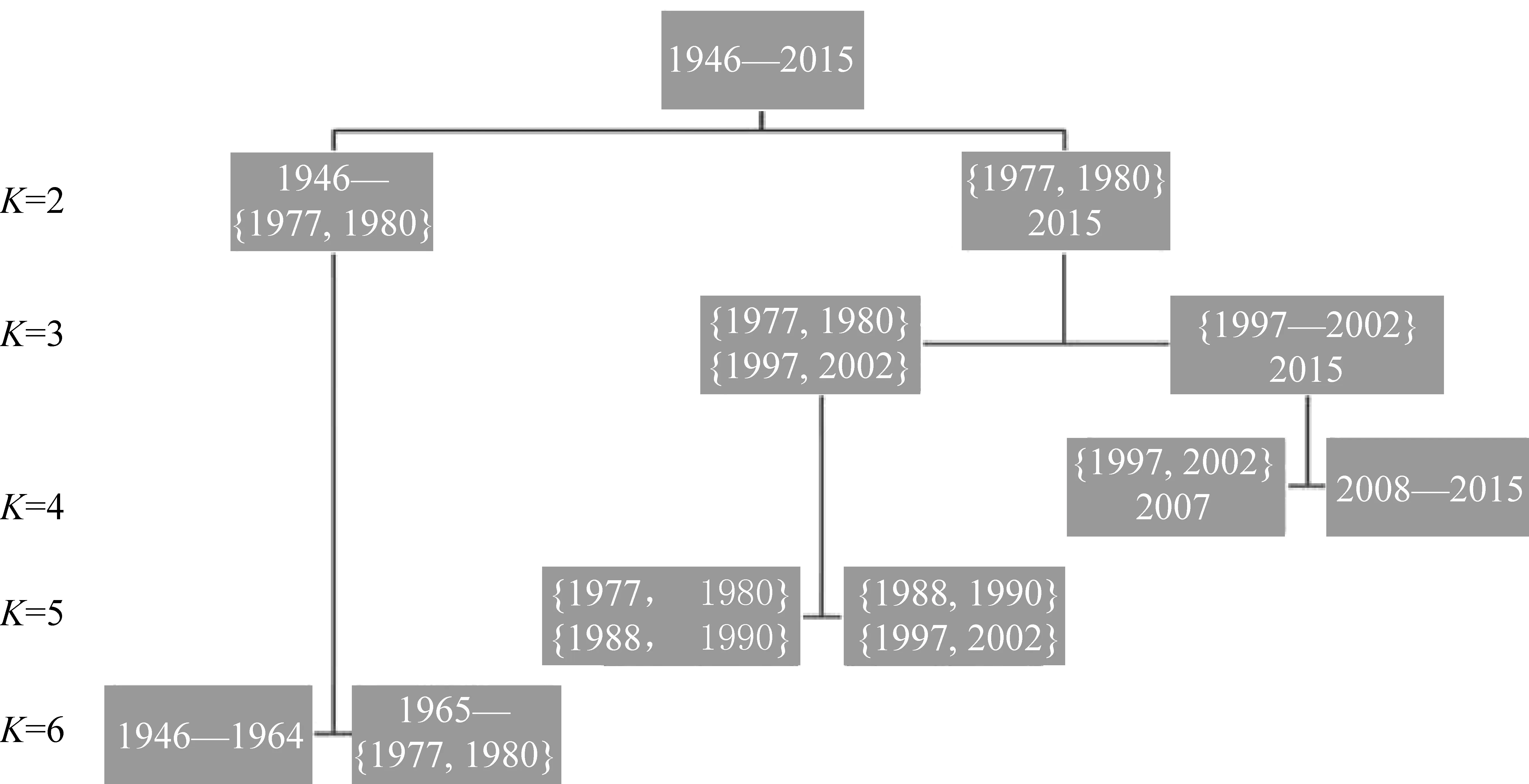
图2 基于K均值方法的历史语料词汇使用分期及其聚类数量
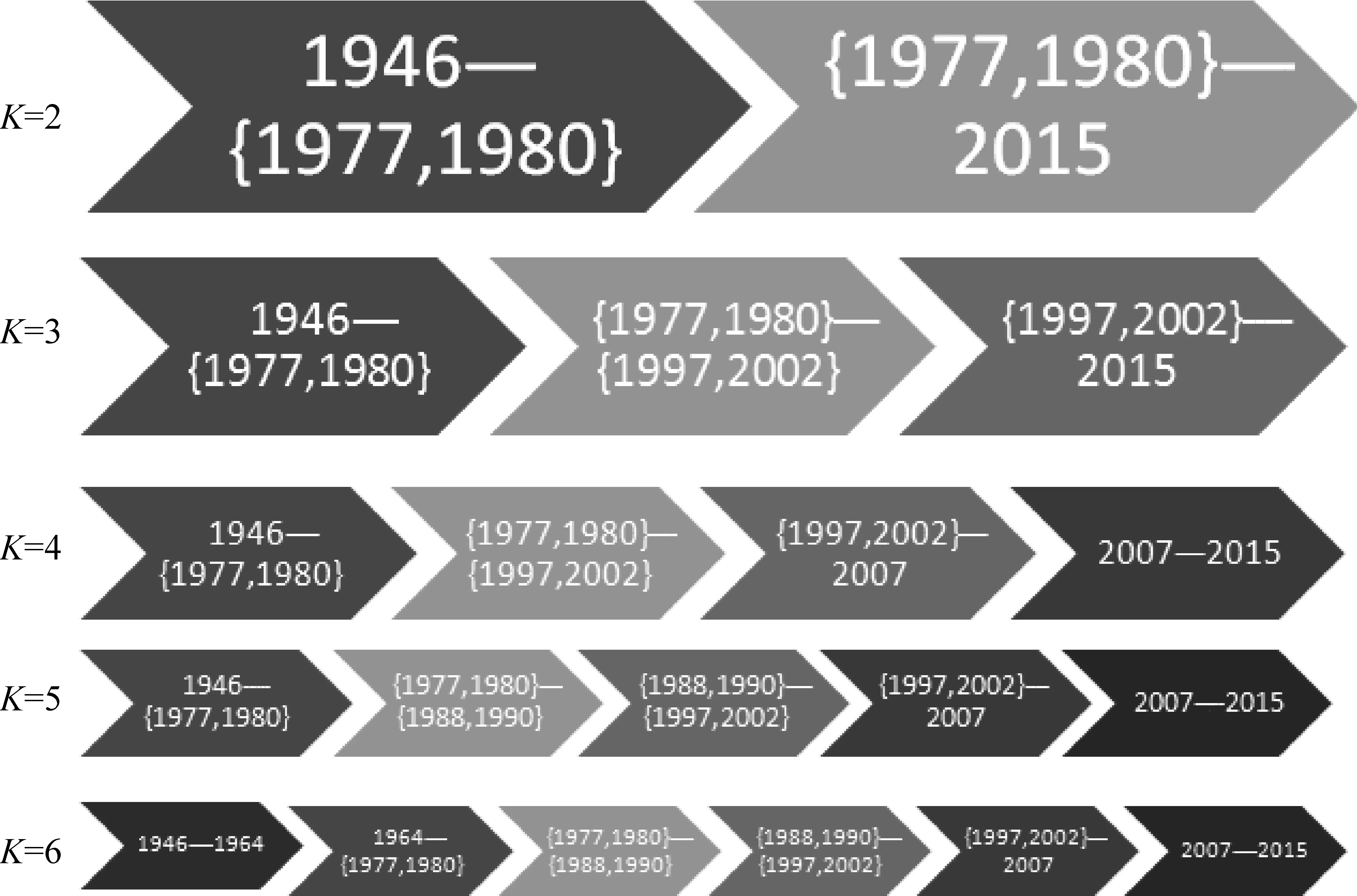
图3 历史语料词汇使用分期及其聚类数量
1997—2002年过渡则是在改革开放渐入佳境,我国综合国力高速上升的阶段。语言生活和媒体的发展步入新的阶段。但是这一过渡在已有的研究中很少被注意到。在刁晏斌[1-2]和Rao[3]的研究中, 都借用政治史将中华人民共和国成立后的现代汉语白话以文革运动为界分为三段。王建华[4]意识到“跨世纪稳定发展期”的存在,但是将1990年至今的时段划为此段。涉及新政权建立前的语料,则简单地以1949年为边界分为两段。并没有注意到在词汇使用的层面,新政权建立在语言上所产生的冲击不如改革开放,甚至不如进入新世纪的影响大。
聚类的分裂率先从图2第二层的右侧(也就是图3的第一层的浅色部分)开始。当二分类时的类2已经分裂为四个类的时候,二分类时的类1才开始分裂。这从一个侧面展现了改革开放前后词汇使用更新速度的差异。改革开放以前词汇使用总的来说变化缓慢,该聚类较之改革开放后更为稳固,分裂得晚。
4 两层三段分期体系
综上所述,本文将1946—2015年共70年的历史语料的时期划分任务分为两个层次。第一层次分为两段,1946年到1977—1980年过渡为一段(E1),之后为一段(E2),并以1980年为实际操作时的边界。第二层次分为三段,即第一层次中的第二段进一步分为1980年到1997—2002年过渡为一段(E2.1),之后为一段(E2.2),并以2000年为实际操作时的边界。为行文简便,后文中也使用E1、E2、E2.1和E2.2指代该分期体系中的时期。该体系示意如图4所示。

图4 两层三段分期体系示意图
对应Rao[3]在传统分期方法下进行的词语使用统计,本文在新的分期体系下对用词情况进行了统计,如表3~5所示。
从表3容易发现: E2在词语使用的丰富程度上大大超越E1,这在总词种数和年均词种数上都得到体现。在表4中比较年均词种数可以发现E2.1处于最高峰。表5统计了各时期达到特定词语覆盖度(按词频降序获得的词汇累积频率)所需的词数。该组数据也刻画了诸时期的词语使用丰富程度,比例越高说明词汇使用越丰富。表5数据体现出E2高于E1,E2.2高于E2.1高于E1的趋势。这表明虽然高频段词种数在E2.1较多,但内部分布于E2.2更为平均,词汇分布在高频段更为多样。总体而言,改革开放后(E2)的词汇丰富程度有了明显提高,并且呈现出先增长(E2.1)后回调(E2.2)的态势,词汇使用的多样性持续增长。
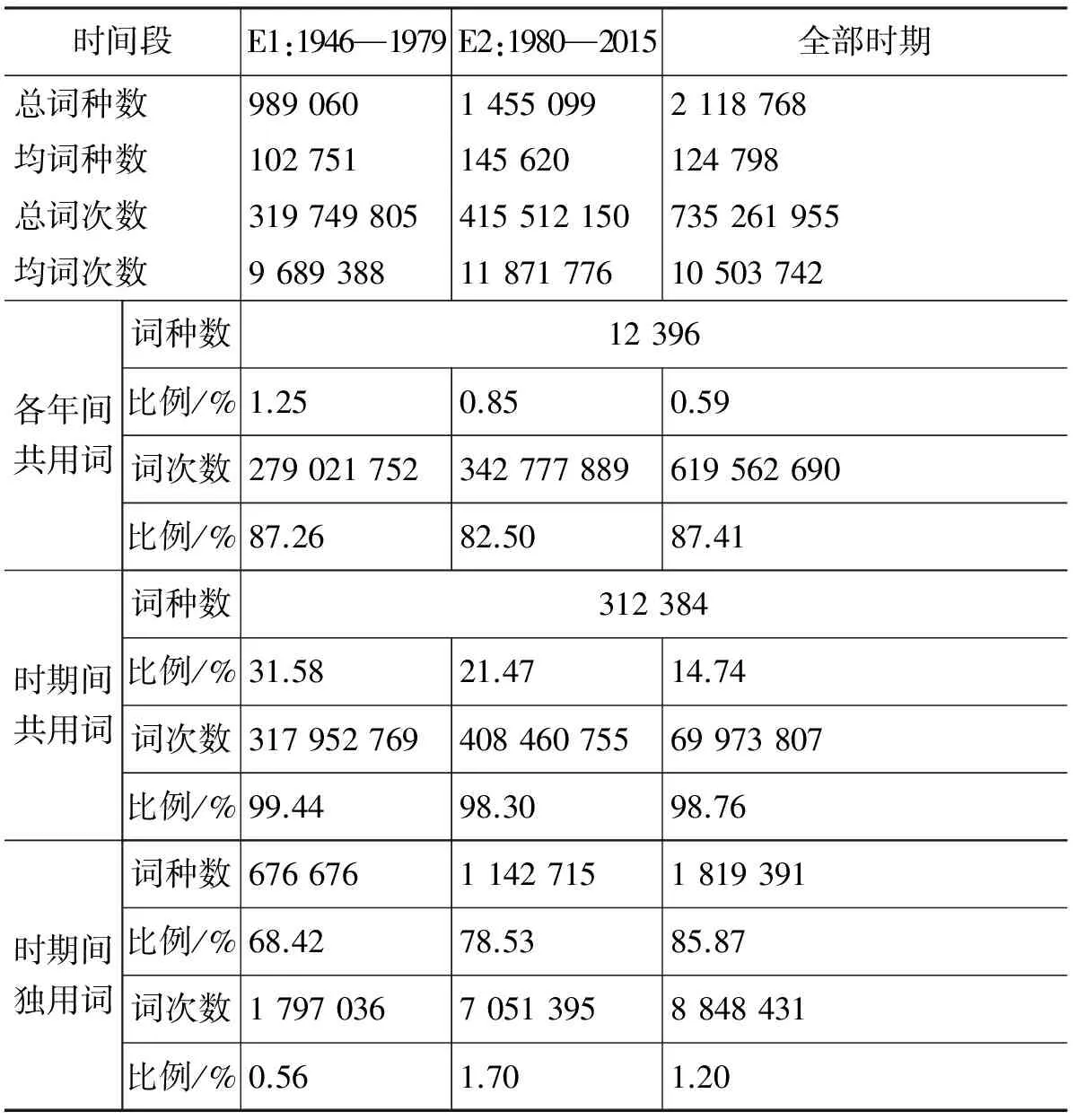
表3 在第一层次分两段时各段的用词情况
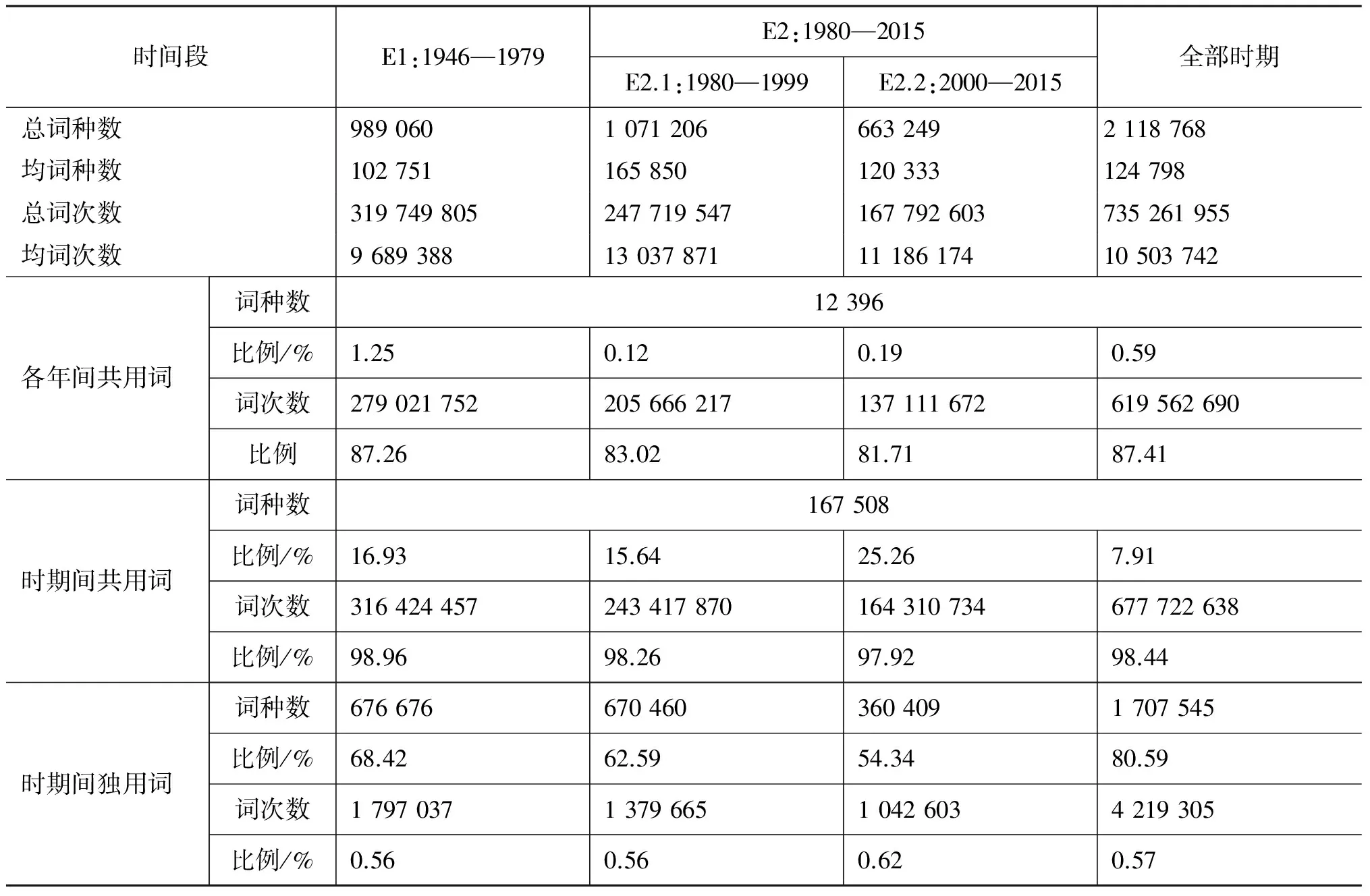
表4 在第二层次分三段时各段的用词情况
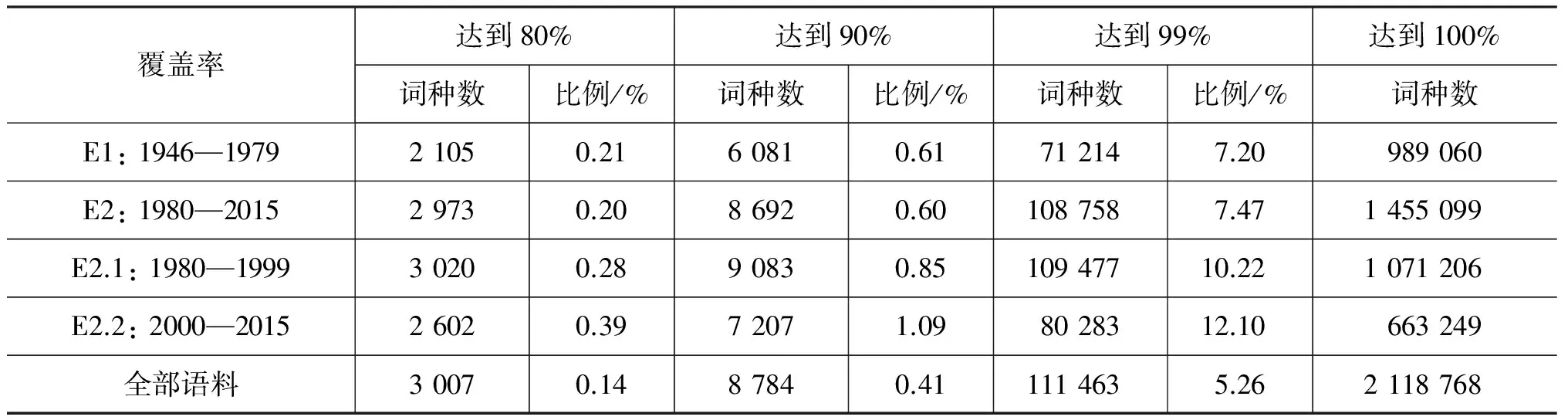
表5 各时期用词覆盖度
表3~5所示数据与传统分期中用词简况[3]所展现的数据趋势差异并不悬殊。首先是因为双层分期体系依据时敏层词的使用状况而非全体词汇的频率进行分期, 表3和表4中着重分析的共用词恰是基干层的重要部分;其次是因为时期的划分本身具有一定的模糊性,这也恰恰表明仅仅通过对词汇系统做整体的频次统计,难以获得时期划分的线索。
5 小结
不同于过去借用政治史对现代汉语白话文进行分期的方法,本文工作使用统计聚类方法,以具有时间敏感性的词汇的使用频率为特征对70年跨度的报刊语料进行了聚类,寻找到了较稳定的聚类,并在不同的聚类数下绘制了具有层次性的词汇使用分期树。本文以1980年和2000年为实际操作边界,构建了两层三段分期体系。从纯粹的语言学数据出发进行语言分期,打破了现代汉语白话文分期借鉴政治史分期的局面,揭示了把改革开放的开始作为过去70年间词汇使用变迁最重要分水岭的重要事实,世纪之交具有第二重要地位,并显示了语言使用相对于社会变革的短暂滞后效应。
[1] 刁晏斌. 现代汉语史概论[M]. 北京: 北京师范大学出版社,2006.
[2] 刁晏斌. 现代汉语史[M]. 北京: 人民出版社,2006.
[3] Gaoqi R, Endong X. Words and characters in official newspapers since the foundation of PRC: Guizhou Daily and People’s Daily as Examples[C]//Proceedings of International Journal of Knowledge and Language Processing (IJKLP), 2015, 6(2): 23-33.
[4] 王建华,周明强,刘福根. 信息时代报刊语言跟踪研究[M]. 杭州: 浙江大学出版社,2006.
[5] 饶高琦,李宇明. 基于70年报刊语料的现代汉语历时稳态词抽取与考察[J]. 中文信息学报,2016,30(06):49-58.
[6] 饶高琦,李宇明. 基于词频逆文档频统计的词汇时间分布层次[C]//第十八届汉语词汇语义学研讨会,乐山,2017.
[7] 荀恩东,饶高琦,肖晓悦,等.大数据背景下BCC语料库的研制[J].语料库语言学,2016, 3(1):93-118.
[8] 荀恩东,饶高琦,谢佳莉,等. 现代汉语词汇历时检索系统与应用研究[J],中文信息学报,2015(3): 169-176.
[9] 罗智勇. 现代汉语通用分词系统的技术与实现[D]. 北京: 北京工业大学硕士学位论文, 2002.
[10] Ian H W, Eibe F, Mark A H. Data mining: Practical machine learning tools and techniques[M]. (3rd Edition). Morgan Kaufmann, 2011.
[11] Altman N S. An introduction to kernel and nearest-neighbor nonparametric regression[J]. The American Statistician,1992, 46 (3): 175-185.
[12] Dempster A P, Laird N M, Rubin D B. Maximum likelihood from incomplete data via the EM algorithm[J]. Journal of the Royal Statistical Society, Series B. 1977,39 (1): 1-38.
