基于词典与规则的新闻文本情感倾向性分析
2017-03-09李晨朱世伟魏墨济于俊凤李新天
李晨 ,朱世伟 ,魏墨济 ,于俊凤,李新天
(1.山东省科学院情报研究所,山东 济南 250014;2.山东省科学院生物研究所,山东 济南 250014)
基于词典与规则的新闻文本情感倾向性分析
李晨1,朱世伟1,魏墨济1,于俊凤1,李新天2
(1.山东省科学院情报研究所,山东 济南 250014;2.山东省科学院生物研究所,山东 济南 250014)
通过对新闻类文体的结构分析,将新闻文体按段落划分,采用一种基于情感词典和语义规则相结合的情感关键句抽取方法,对段落内的句子进行情感分析。综合考虑情感、转折、否定、程度和归总等词语信息构建情感词典,根据规则切割新闻文本,将新闻划分为意群、句子、段落以及篇章,通过制定的规则计算情感关键句倾向值,最终获得段落以及整个篇章的情感倾向值,从而得出新闻的情感倾向。与情感词典和SVM情感分类方法的实验结果对比表明,本文方法在对新闻文本进行倾向判别时效果较好,方法具可行性。
情感分析;规则;情感词典;网络新闻
文本情感倾向性分析又称情感分析、意见挖掘,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程,旨在研究人们对人物、事件及其属性的主观意见和评价[1-3]。文本情感分析已经成为自然语言处理领域的热点研究话题,涉及自然语言处理、信息检索、数据挖掘等研究领域。
目前,国内外使用最多的文本情感分析方式有两种,一是基于机器学习的情感分析[4-5];二是基于语义的情感分析[6-7]。基于机器学习的情感分析多采用传统的文本分类技术,该方式将情感词汇作为分类的特征关键词,然后再联合其他特征训练分类器来完成文本情感分类,常用的方法有朴素贝叶斯、最大信息熵和支持向量机。Pang等[8]分别使用上述方法进行情感倾向性分析研究,对英文电影评论进行分类,并研究不同特征选择方式对分类效果的影响。Tan等[9]分别使用NB(NaiveBayesian)、KNN(K-NearestNeighbor)、SVM(SupportVectorMachine)、CentroidClassifier和WindowClassifier5种分类方法并结合多种特征选择方法对文章情感倾向性进行分类。樊小超[10]通过对评论性文本的分析,结合词典和规则将文本划分成情感句集合、细节句集合和关键句集合,再对全部文本情感句集合和关键句集合进行训练得到不同的分类器,最后使用投票策略将分类器进行融合,得到最终情感分类结果。采用机器学习的方法进行文本倾向性分类需要大规模标注的训练集,想要获得较高的分类结果时,对训练集的质量要求很高,而且在进行文本向量化的时候往往会忽略情感词汇的上下文信息。基于语义规则的文本倾向性研究中,研究者一般考虑词语、句子、段落和篇章等多个角度自底向上进行层次分析。首先,抽取文中具有明显主观色彩的情感词汇;然后,找出对该词汇进行修饰的否定和程度词汇等,通过规则计算情感词汇情感值;最后,根据情感词汇的情感值,计算得到句子、段落以及篇章的整体情感值,从而获得最终的情感倾向信息。朱嫣岚等[11]利用HowNet提供的语义相似度和语义相关场的定义,通过计算待评估词与褒贬基准词的相似性和相关性,从而得到待评估词的倾向度。Turney等[12]使用点互信息PMI(PointwiseMutualInformation)对基准情感词表进行扩充,并且采用了基于HNC(HierarchicalNetworkofConcepts)的语义相关度方法计算词语的原始极性。冯亮祖[13]利用语句情感倾向性、文本关键词、语句位置以及语句与标题的相似度4种特征抽取情感关键句,通过对情感关键句进行计算得出新闻文本的情感倾向。张成功等[14]构建了一个包括基础词典、领域词典、网络词典以及修饰词典的高效极性词典,将极性词和修饰词组合形成极性短语作为情感分析的基础单元。
综合分析现有的研究成果,在中文网络新闻情感分析领域,对篇章级情感分析的研究方法中仍然存在没有充分考虑文体特征和情感分布,以及对复杂句式缺乏有效的分析方法等问题。本文在上述研究基础之上,综合分析网络新闻的结构特点,对篇章级的新闻情感分析进行细化,把新闻自顶向下分割成篇章、句子以及意群,以HowNet情感词典为基础,利用哈工大同义词词林和台湾大学的中文情感极性词典进行扩展获得基准情感词典,再结合各类语义规则获得网络新闻的情感倾向。
1 情感倾向性计算方法
1.1 网络新闻文体研究
新闻的主观性是指在现实生活中真实发生的事件过程中,叙述者在新闻事件中表现出来的立场、态度和情感[15]。新闻文体一般主题描述简单突出,情感表达方式简单明了,所以可以较好地提取新闻的情感信息。通过对新闻文体的分析研究发现,对新闻情感分析起到关键作用的文本位置为:
(1)标题:标题是新闻作者主观意志的直接表达,是文章主旨的高度浓缩,能够直接陈述新闻的概要。当标题含有明显的情感倾向时,它应该被赋予较高的权重,同时可以将其他语句与标题进行相似度计算,进而得到句子与新闻主旨的的相似性。与主旨越相似则就越接近文章作者的情感。
(2)段首与段尾:段首与段尾是新闻作者的开篇与总结。通过观察研究,段首与段尾是表达作者情感的主观句最常出现的位置,而且新闻文本的结构是一种“倒金字塔”式[16]的结构。
(3)其他位置:对于其他位置的句子,如果与标题不相关,则按照普通方式进行情感倾向计算,不再附加额外权重。
对于篇章级的文本情感分析来说,通常都是对文本进行降维,压缩文本特征空间来优化情感分类问题。Yessenalina等[17]使用SVM模型在进行篇章级情感分类的同时抽取部分语句作为分类的特征空间,取得了较好的效果。李本阳等[18]使用ME模型处理小句级情感分类,以小句级的情感输出作为篇章级的输入,并结合句型特征和句子位置等信息作为特征,采用SVM模型对文本进行篇章级情感分类。本文在对网络新闻文本进行情感分析时,首先切割新闻文本,找出情感句,以情感句作为分析基础,最终通过融合各类规则计算出文本的情感倾向。
1.2 情感词典构建
新闻由句子组成,句子由词汇组成,因此词汇是进行情感倾向性分析的基础。通过构建情感词典可以将句子中具有情感的词汇识别出来,从而进行分析。情感词典在情感分析中起到了重要作用,一些研究者对情感词典的构建工作展开了深入的研究[19]。自然语言当中一般会把词汇分为褒义词、贬义词和中性词3类,其中褒贬义词明确地表达了作者对某一主题的情感倾向。
本文以HowNet为主体,合并中文负面情感词语和中文负面评价词语去重后构建负面基础情感词典,合并中文正面情感词语和中文正面评价词语去重后构建正面基础情感词典,以中文程度级别词语作为描述情感词的程度词语词典,考虑否定词、转折词和新闻中的各类归总词语,分别构建否定词典、转折归总词典。HowNet所包含的情感词汇有限,本文采用哈工大同义词词林和台湾大学NTUSD简体中文版本进行去重、剔除歧义词汇之后,分别加入正/负面基础情感词典。文中采用四元组对情感词典进行描述,定义如下:
sentimentword(name,polarity,pos,weight) ,
(1)
其中,name表示该词汇的名称,polarity表示极性,pos表示词性,weight代表该词的权重。name和pos通过文本分词工具FudanNLP获取,polarity和weight则通过定义好的情感词典获取。
1.2.1 程度词典构建
在各类语言描述当中,修饰词对情感词汇的情感表达有着非常重要的作用,不同级别的词语会产生不同级别的情感倾向。例如:这个人极其讨厌和这个人很讨厌,同样是对“讨厌”进行修饰,但是“极其”所表达的情感倾向比“很”更加强烈。针对这些能够对情感倾向产生巨大作用的词汇,本文借助HowNet提供的中文程度级别词语,构建了程度词语词典。HowNet对程度词语进行了级别分类,具体分为6个等级:最(most)、很(very)、较(more)、稍(-ish)、欠(insufficiently)和超(over)。本文按照修饰程度的不同为这6个级别的程度词分别赋予不同的权重值,程度词典表如表1所示。

表1 程度词典表
1.2.2 否定词典与转折归总词典构建
否定词在文本分析中起到置反情感倾向的作用,所以在分析文本情感倾向时也应该将否定词作为重要的分析对象,因此本文构造了一部否定词词典。根据张谊生[20]的文献,本文使用了28个否定副词,这些词包括:不、没、无、非、莫、弗、勿、毋、未、否、别、無、休、不要、没有、未必、难以、未曾、不能等。由于否定词在进行情感判断时具有置反作用,所以将其权值设置为-1。
文本中会存在很多转折句型,在转折句型中往往会发生情感反转,将前一部分表达的情感弱化,从而突出转折之后的情感。同样,文本中可能也会包含对作者观点进行总结的归总类词汇,包含这类词汇的分句更能够表达作者的情感倾向,所以需要赋予更高的权重比例。通过查阅金允经等[21]的文献,本文选择但、但是、却、然而、不过、只是、就是、总之、总而言之、总体来看、认为、觉得、总结、综上所述等作为转折归总词汇。
本文情感词典的构建过程如图1所示:
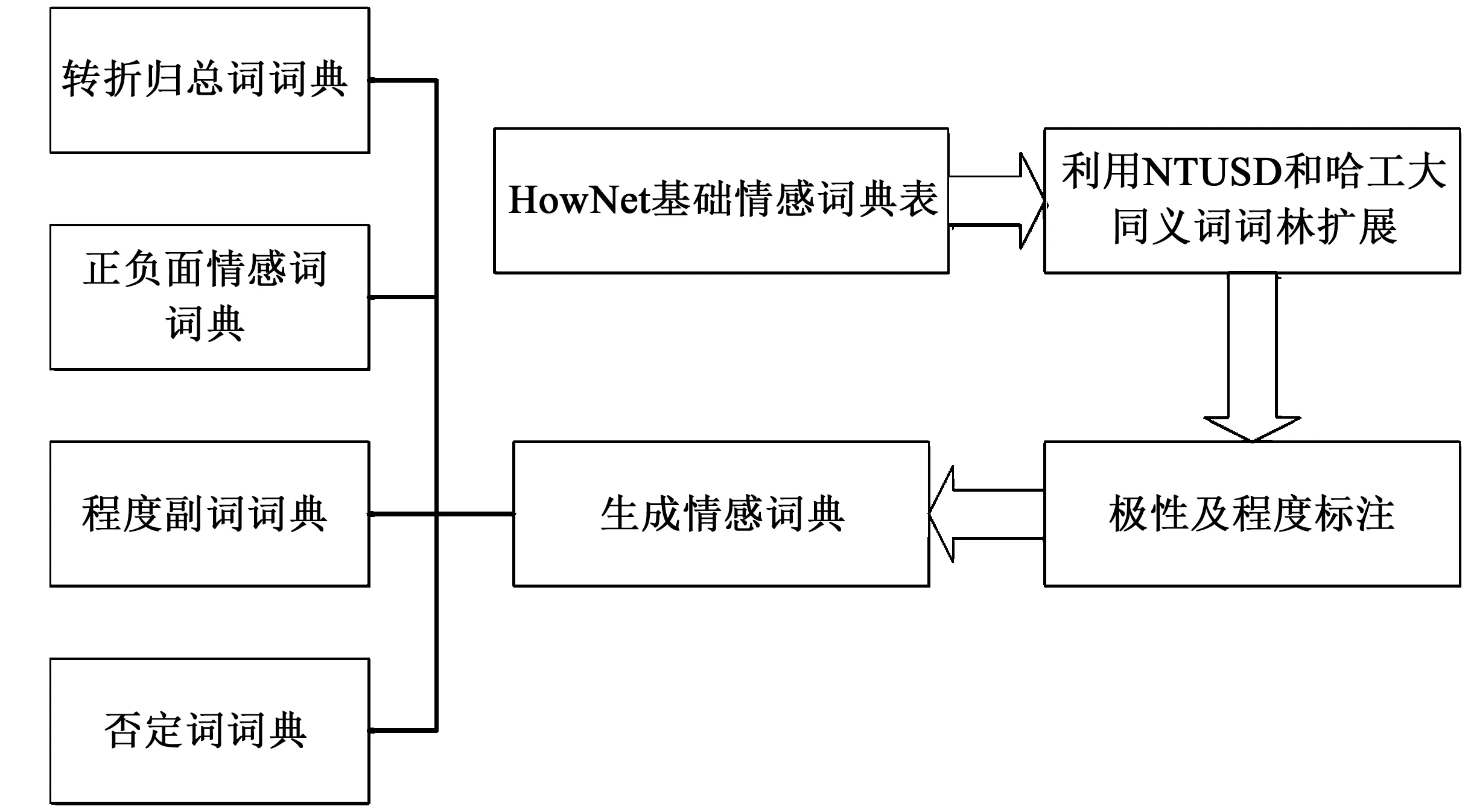
图1 情感词典构建流程Fig.1 Construction process of sentiment lexicons
1.3 规则定义
情感词典的构建可以把情感词语从句子中孤立出来,但是如果孤立地看待这些词语,并不能正确地反映新闻的情感倾向。为了提高分析的准确度,必须将上下文的联系考虑进来。因此,在词语情感计算的基础上,应该考虑上下文中能够改变词语情感倾向或者情感强度的语义规则信息。
本文结合新闻文体的特点,综合情感词典、情感句位置、标题等元素定义了多种语义规则用于情感句的倾向性计算。
1.3.1 情感表达组合
对新闻进行切割,分为段落、句子以及意群,以意群为最小情感单元进行分词获取情感词汇。以情感词汇为中心,与情感表达有关的规则有如下几种:
规则1:只包含情感词汇而不包含其他修饰词汇的意群,例如:今天心情不错。例子当中只包含“不错”一个情感词,该类别的意群权值计算如公式2所示,其中w为该意群的情感值,p为该情感词汇的情感值,N为情感词汇数量。

(2)
规则2:包含否定修饰词意群,例如:今天我不高兴!例子中存在否定词“不”来修饰情感词“高兴”,那么句子的倾向性发生了反转,由正面变成了负面。该类别的意群情感值计算如公式3所示,其中m为修饰该情感词的否定词的个数,m的选取采用了滑动窗口方式。通过对情感语料的分析,本文将m设置为5,即选择情感词汇之前5个词汇中的否定词个数。
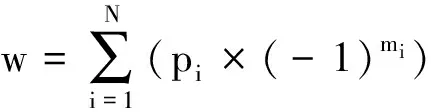
(3)
规则3:包含程度修饰词的意群,例如:今天我很高兴!例子中存在“很”这样一个程度词来修饰“高兴”,那么本来的意群情感倾向在经过修饰后得到了明显的加强。该类别的意群情感值计算如公式4所示,其中d表示修饰该情感词汇的程度词的情感权重,程度修饰词的选择依然采用滑动窗口的方式,根据对情感语料的分析,本文设置窗口大小为情感词汇前后各3个。
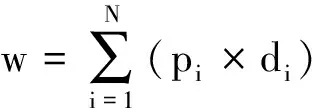
(4)
规则4:包含否定词、程度词和情感词汇的意群,其中否定词位于程度词之前,例如:今天我不是很高兴。这种句型当中,否定词将程度词的情感程度有所弱化,意群情感计算方式如公式5所示,其中α为否定词和程度词的位置信息权重,这里取0.8。
(5)
规则5:包含程度词、否定词和情感词汇的意群,其中否定词位于程度词之后,例如:今天我很不高兴。这种句型当中,否定词将程度词的情感倾向明显加强,意群情感计算方式如公式5所示,其中w的取值为1.2。
规则6:当上述规则中含有转折、归总词汇或者位于段首与段尾时,其情感值计算的权重要增强。计算方式如公式6所示,其中wori为未引入规则6时计算出的情感值:
w=1.2×wori。
(6)
根据上述规则可以计算出每个句子的意群情感倾向值,由此可以计算句子、段落以及篇章的最终情感值,从而得到新闻的情感倾向。其中,s为该句子的情感值;P为段落的情感值;K为该句意群总数;M为该段落句子总数;n为最终情感值;Q为该篇章段落总数。
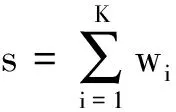
(7)
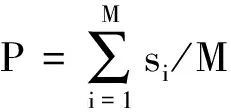
(8)

(9)
1.3.2 分析流程
本文使用的基于规则的网络新闻文本情感分析具体流程如下:
(1)文本切割。将文本Doc按照换行符“/r”或者“/n”切割成段落Para,再按照[“。”,“?”,“!”]将Para分为Sen,最后按照[“,”]将Sen切割为多个意群SenGroup。
(2)文本预处理与情感定位。对每个意群使用FudanNLP进行分词,结合情感词典获取情感关键词并按照sentimentword四元组进行标注。
(3)融合规则计算意群情感值。通过文中定义的6个规则,对得到的意群进行情感值计算。
(4)计算句子情感倾向值。通过规则对意群加权得到句子的情感值之后需要再次计算该句子与标题的文本相似度。文本采用SimHash算法进行相似度计算,生成标题和要对比句子的Hash值,再通过计算两个Hash值的海明距离判断相似度。此时句子的情感倾向值计算方式如公式10所示,其中α的值根据相似度进行调整,相似度越高α越大。sori为未进行相似度计算时的句子情感值:
s=α×sori。
(10)
(5)计算段落以及篇章的情感倾向值,最终得到文本的情感倾向。算法流程如图2所示。

图2 算法流程分析Fig.2 Algorithm flow analysis
2 实验结果与分析
2.1 数据来源及任务指标
数据集1来源于网易和新浪新闻板块,通过网络爬虫共采集1 000篇新闻语料,采用人工标注的方式进行情感标注,其中正面新闻320篇,负面新闻219篇,其余为中性新闻。数据集2采用网络爬虫爬取的新闻、博客、论坛各300篇作为测试数据集。文本采用准确率(precision)、召回率(recall)和F1值对实验结果进行评估。计算方式如下,其中a为判断正确的文本数目;b为实际正确的文本数目,c为所有的文本数目,Pre为准确率;Rec为召回率:
Pre=(a/b)×100% ,
(11)
Rec=(a/c)×100% ,
(12)

(13)
2.2 结果与分析
本文实验1以只考虑情感词典而未加入任何规则条件的测试结果作为baseline,将融入规则的测试与之进行对比。结果如表2所示,其中RPos为正面新闻召回率、PPos为正面新闻准确率、F1Pos为正面新闻F1值;RNeg、PNeg和F1Neg分别代表负面新闻召回率、准确率和F1值。通过结果可知,只采用情感词汇权重加权方式的情感倾向性计算方式比本文采用的基于情感词典和规则的计算方式各项指标明显偏低,在复杂的语言环境下,相同的词汇在不同的上下文中所代表的语义有所不同,单纯只考虑词汇本身的含义不能准确表达情感信息。随着各类规则的加入,综合考虑上下文语义关系,本文得到的实验结果准确率和召回率都在0.75以上,从而验证了本文方法是有效可行的。

表2 实验1结果
实验2对数据集2中的数据进行分析,与目前比较主流的分析方法SVM进行对比。SVM采用的是台湾大学林智仁教授开发的LibSVM。实验结果如表3所示。其中Rec为召回率、Pre为准确率。从实验结果来看,通过对各类规则的总结,本文提供的方法要优于SVM算法,说明本文提供的方法是有效的。

表3 实验2结果
3 结语
本文在对网络新闻文体结构分析的基础上,先后构建了正负面情感词典、否定词词典、程度副词词典、转折归总词典,结合多种规则,提出了一种基于词典和规则的网络新闻文本情感分析方法,并通过实验对本方法的有效性和可行性进行了验证。虽然此次研究取得了一定的成果,但是尚有许多工作需要完成,如含有歧义的词语的处理;篇章级的情感值是通过段落加权平均得到,而段落的情感值又是通过句子的加权平均获得,这种方式虽然能取得不错的效果,但是仍然比较简单。因此,如何消除词语歧义和更好地获取篇章级情感值是下一步的研究重点。
[1]赵妍妍,秦兵,刘挺.文本情感分析[J].软件学报,2010,21(8):1834-1848.
[2]LIUB,HUMQ,CHENGJS.Opinionobserver:AnalyzingandcomparingopiniosontheWeb[C]//Proceedingsofthe14thinternationalconferenceonWorldWideWeb.NewYork,NY,USA:ACM,2005:342-351.
[3]PANGB,LEEL.Opinionminingandsentimentanalysis[J].Foundationsandtrendsininformationretrieval,2008,2(1/2):1-135.
[4]王成. 基于半监督机器学习的文本情感分析技术[D]. 南京;南京理工大学,2015.
[5]孙建旺,吕学强,张雷瀚. 基于词典与机器学习的中文微博情感分析研究[J]. 计算机应用与软件,2014, 31(7):177-181.
[6]杨佳能,阳爱民,周咏梅. 基于语义分析的中文微博情感分类方法[J]. 山东大学学报(理学版),2014,49(11):14-21.
[7]张志飞,苗夺谦,岳晓冬,等. 强语义模糊性词语的情感分析[J]. 中文信息学报,2015,29(2):68-78.
[8]PANGB,LEEL,VAITHYANATHANS.Thumbsup?Sentimentclassificationusingmachinelearningtechniques[EB/OL]. [2016-03-04].http://delivery.acm.org/10.1145/1120000/1118704/p79-pang.pdf?ip=222.173.55.212&id=1118704&acc=OPEN&key=4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E6D218144511F3437&CFID=849300259&CFTOKEN=78353276&__acm__=1475909422_f62191db62812a3a07db2d210c7dc31b.
[9]TANSB,ZHANGJ.AnempiricalstudyofsentimentanalysisforChinesedocuments[J].ExpertSystemswithApplications, 2008, 34(4):2622-2629.
[10]樊小超. 基于机器学习的中文文本主题分类及情感分类研究[D]. 南京:南京理工大学, 2014.
[11]朱嫣岚, 闵锦, 周雅倩,等. 基于HowNet的词汇语义倾向计算[J]. 中文信息学报, 2006, 20(1):14-20.
[12]TURNEYPD,LITTMANML.Measuringpraiseandcriticism:Inferenceofsemanticorientationfromassociation[J].AcmTransactionsonInformationSystems, 2003, 21(4):315-346.
[13]冯亮祖. 基于情感关键句的新闻文本情感分类研究[D]. 北京:北京邮电大学, 2015.
[14]张成功, 刘培玉, 朱振方,等. 一种基于极性词典的情感分析方法[J]. 山东大学学报(理学版), 2012, 47(3):47-50.
[15]李凌燕. 新闻叙事的主观性研究[M]. 上海:东方出版中心, 2013.
[16]谢晖. 新闻文本学[M]. 北京:中国传媒大学出版社, 2007.
[17]YESSENALINAA,YUEY,CARDIEC.Multi-levelstructuredmodelsfordocument-levelsentimentclassification[C]//ConferenceonEmpiricalmethodsinnaturallanguageprocessing.Massachusetts,USA:AssociationforComputationallinguistics,2010:1046-1105.
[18]李本阳. 句子和篇章文本倾向分析[D]. 哈尔滨: 哈尔滨工业大学, 2010.
[19]杜伟夫. 文本倾向性分析中的情感词典构建技术研究[D]. 哈尔滨:哈尔滨工业大学, 2010.
[20]张谊生.现代汉语副词研究[M].上海:学林出版社,2000.
[21]金允经,金昌吉. 现代汉语转折连词组的同异研究[J]. 汉语学习,2001(2):34-40.
DOI:10.3976/j.issn.1002-4026.2017.01.020
Lexiconandrulesbasednewstextsentimentanalysis
LIChen1,ZHUShi-wei1,WEIMo-ji1,YUJun-feng1,LIXin-tian2
(1.InformationInstitute,ShandongAcademyofSciences,Jinan250014,China;2.BiologyInstitute,ShandongAcademyofSciences,Jinan250014,China)
∶Accordingtothestructure,thenewsstylewasdividedintoseveralparagraphs.Basedonsentimentlexiconandsemanticrules,amethodofextractingsentimentalkeysentenceswasusedtoanalyzethesentimentofsentenceswithineachparagraph.Firstly,sentimentlexiconwasbuiltbyconsideringtheemotion,twist,negation,degreeandsumsupvocabularies;Secondly,accordingtorules,newstextwasdividedintosensegroups,sentences,paragraphsandchapters;Furthermore,orientationvalueofsentimentalkeysentenceswascomputedbytherulesestablished,andthenthesentimentalorientationvalueoftheparagraphsandthewholechapterswasobtainedbyweightedaverageofsentences,thusthesentimentalorientationofnewswasrevealed.ComparedwithlexiconbasedmethodandSVMsentimentclassification,experimentalresultsshowthatthemethodproposedhasgoodeffectsontheorientationidentificationofnewstext,showinggoodfeasibilityaswell.
∶sentimentanalysis;rules;sentimentlexicon;onlinenews
10.3976/j.issn.1002-4026.2017.01.019
2016-07-13
山东省科技发展计划(2014GGX101013);山东省重点研发计划(2015GGX101032,2015GGX101037,2016GGX101018)
李晨(1988—),男,硕士,研究方向为大数据和数据挖掘。
TP
A
1002-4026(2017)02-0115-07
