组距式分组下关于众数计算问题的若干思考
2017-03-04曹洁马玲玲焦荣荣
曹洁+马玲玲+焦荣荣
摘要:在教学过程中,经过对众数的分析研究认为,在现行的统计学教材中就众数的计算方法有值得商榷之处。
关键词:众数;组距式分组;连续式;间断式
中图分类号:G642.41 文献标志码:A 文章编号:1674-9324(2017)08-0201-02
统计中一旦收集了数据,第一步就是整理数据,也就是实用简单的指标去描述数据。完成这一步最容易的方法就是计算几种不同形式的集中趋势(measures of central tendency),它能够最好的代表一组数据的数值,一般具有三种形式:均值、中位数和众数。
一、众数的概念
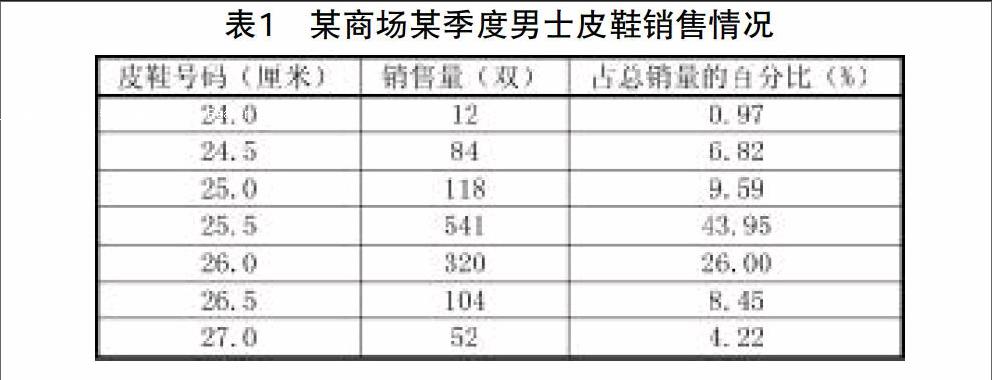
某制鞋厂要了解消费者最需要哪种型号的男士皮鞋,调查了某百货商场某季度男士皮鞋的销售情况,得到资料如表1。
从表1的资料可以看出,25.5厘米的鞋号销售量最多。统计学中,把在一组数据当中出现次数最多的标志值就称为众数(mode),一般用M表示。众数是位置平均数,它不受极端变量的影响,这是众数区别于均值的一个重要标志。
众数容易被人们“忽视”,因为人们仿佛总是更喜欢去记忆那些需要“计算”的事情,认为众数只要被“数”出来就可以。众数,的确是最笼统、最不精确的集中趋势,但它却在理解特定的数据分布中扮演着重要的角色。
二、众数的重要性
毫无疑问,对于定性数据,类似种族群体、眼睛颜色、收入档次等变量的集中趋势只可以使用众数来进行描述。例如,你不可能用中位数来描述哪个鞋码在销售中占有优势,也不能使用均值——平均鞋码为25.65厘米显然是没有实际意义的。而1231个人中几乎一半(541)人的鞋码是25.5厘米似乎是描述这个变量一般水平的最好的方式。再如,为了掌握市面上某种商品的价格水平,完全不必全面登记该商品的全部價格去计算其均值,因为均值很容易受到极端值的影响,只是需要用该商品成交量中最多的那个价格即价格的众数作为代表值,就可以反映该商品价格的一般水平。
三、关于众数的计算
就众数的计算方法来看,现行的统计学教材中的处理值得商榷。
一般情况下,在给出所有数据或在对数据进行了单项式分组的情况下,直接找到频数最大的变量值就是这组数据的众数,但是在组距式分组的情况下,对于众数的推算有以下的计算公式:
上限公式:M=U-d
下限公式:M=L+d
其中,U表示众数所在组上限;L表示众数所在组下限;Δ表示众数所在组频数与其下限的邻组频数的差;Δ表示众数所在组频数与其上限的邻组频数的差;d表示众数所在组的组距。
由于一般的数据分布中众数只有一个,所以上限公式和下限公式计算得到的众数应当是一样的,这一点非常重要。
例如:计算某班50名同学某一门课程成绩的众数,资料如表2所示。
其中,众数所在的组为“66—69”这一组,U=69,L=66,Δ=20-10=10,Δ=20-13=7、d=3根据公式可得:
上限公式:M=69-×3≈67.76
下限公式:M=66+×3≈67.76
四、几种特殊情况下众数计算的探讨
1.偏态分布。一组数据有如下分布(见表3),利用公式计算众数。
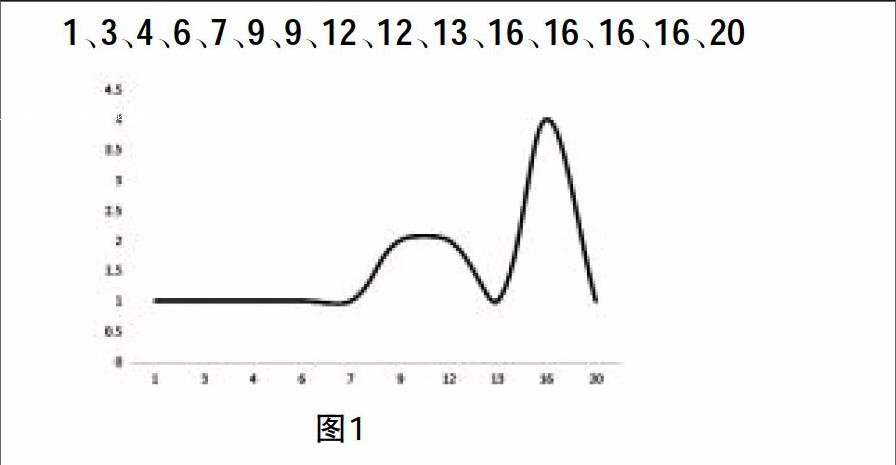
由分布情况可知,众数所在的组为“9—13”这一组,按照公式进行计算,得到M=12.2。但是如果是这样一组数据,具体如图1所示。
1、3、4、6、7、9、9、12、12、13、16、16、16、16、20
显然,这组数据符合表3中的数据分布情况,对于组距式分组,我们无法判断它的众数是什么,只能用众数的计算公式对它的众数进行一个估计和推断。
2.间断式组距式分组。虽然我们很不喜欢间断式的组距式分组,但不可否认,它依然是存在的。比如刚才说的某班50名同学的成绩,我们假设每一个学生的成绩都没有小数,于是,我可以对成绩进行间断式的组距式分组。
你能猜到出现了什么情况吗?
上限公式:M=68-×3≈66.76
下限公式:M=66+×3≈67.76
是的,使用上限公式和下限公式所计算的结果出现了异常。对比后发现,除了众数所在组的上限从69变到了68以外,公式里的其他条件都没有发生变化。这又是为什么呢?首先能想到的原因就在于我们的间断式分组上。我们都知道,如果分组是表2中的连续式分组,有一个原则叫做“上限不在内”,也就是说,在“66—69”中,上限69是没有包含在这一组中的,而是变成了下一组的下限,那么反过来考虑,能不能认为在间断式分组计算众数公式时,M=U-d中的U其实就是下一组的下限呢?当然可以,并且我们已经得到了验证。根据这种情况,我们给出在间断式组距式分组下众数的计算公式:
上限公式:M=L-d
下限公式:M=L+d
其中,L表示与众数所在组后一组下限;L表示众数所在组下限;Δ表示众数所在组频数与其下限的邻组频数的差;Δ表示众数所在组频数与其上限的邻组频数的差;d表示众数所在组的组距。
当然,此时的组距应当是本组上限—前组上限。就是我们所说的间断式分组的组距的计算方法。
还有其他的解释吗?让我们把焦点放在公式中所涉及到的对象上面。之前提到,公式中“d”是众数所在组的组距,也就是说,不管是连续式分组还是间断式分组,众数的计算只和众数所在的那一组有关系,所以这时候,d就应该是68-66=2,此时,
上限公式:M=68-×2≈67.18
下限公式:M=66+×2≈67.18
不要再去纠结为什么两种方式得到的众数值不一样,就像前边解释过的,我们通过公式计算出来的众数只是实际众数的一个近似值。
注释:
(1)集中趋势:是指一组数据向其中心值靠拢的倾向。
(2)均值:即算术平均数,是观察值的总和除以观察值总个数的商。
(3)中位数:将数据按照一定的顺序排列,处于中间位置的数就是中位数。
(4)标志值:数量标志在各单位的具体表现数值。
(5)位置平均数:总体中处于特殊位置的个别单位的标志值。一般有众数和中位数。
(6)定性数据:表示事物的品质特征,不能用数值表示,结果表现为类别。
(7)单项式分组:一个变量值为一组。
(8)组距式分组:将变量值一次划分为几个区间,每个区间为一组,每个变量值按其大小确定所属的区间。
参考文献:
[1]夏鹭平.统计学基础[M].哈尔滨工程大学出版社,2014.
[2][美]萨尔金德.爱上统计学第二版[M].史玲玲,译.重庆大学出版社,2011.
