云存储环境下分组校验纠删码冗余算法研究*
2017-01-09曾赛峰屈喜龙
曾赛峰,屈喜龙,2
(1.湖南工程学院 计算机与通信学院,湘潭 411104;2.湖南工程学院 风力发电机组及控制 湖南省重点实验室,湘潭 411104)
云存储环境下分组校验纠删码冗余算法研究*
曾赛峰1,屈喜龙1,2
(1.湖南工程学院 计算机与通信学院,湘潭 411104;2.湖南工程学院 风力发电机组及控制 湖南省重点实验室,湘潭 411104)
在海量云存储系统中,提高存储利用率,降低冗余方案的计算复杂度是热点研究问题.分组校验纠删码冗余算法能够减少在数据重构时所需的纠删码片段,从而减少对存储网络带宽以及系统I/O的需求,降低存储系统的负载.介绍了分组校验纠删码的编码规则,参数设置,通过实验分析算法具有良好的容错能力与空间利用率,能够满足云存储系统需要的编解码性能. 关键词:关键词:云存储;纠删码;冗余算法;分组校验
0 引言
在分布式存储系统中,特别是云计算、云存储系统中数据冗余是保证系统可靠性,提高数据可用性和持久性最基本的方法[1].通过存储同一数据文件的多个实例到不同节点,即使部分数据不可用,剩余节点也能足够重构原有数据,广泛使用的冗余策略为副本[2]和纠删码[3]两种.
副本冗余实现简单,响应速度快,但极大地浪费存储资源,在规模庞大的云存储中心势必会增加系统的投入成本;纠删码能够提高存储利用率,但是对数据分片及解码算法的引入将增加系统设计的复杂度.其次,纠删码分片冗余机制要求用户必须从网络的多个节点中获得所有分片才可以恢复原始数据,由于地理位置等因素,用户到多个节点的时延存在差异,这样获取数据的最终时延总是取决于到各节点中的最大者,导致数据下载效率降低.本文基于传统的纠删码技术设计并实现了分组校验纠删码(Group Parity Erasure Code, GPEC)算法,该算法在保证存储利用率的同时,能够降低系统负载,其容错能力和编解码效率能满足云存储系统对系统可靠性和可用性的要求.
1 分组校验纠删码冗余算法
为能够减少针对单个数据块重构的数据块请求个数,同时提供高磁盘利用率和数据持久性,以里德所罗门编码[4]为基础设计了分组校验纠删码冗余算法.分组校验纠删码冗余算法主要目标是减少分块重构代价,即恢复一个不可用数据块所需要的最少数据块的个数.如里德所罗门编码RS(6,3),表示将文件分为6块,然后通过这6块计算出3个校验块,总共9个数据块.其中任何一个数据块的丢失都需要6个其他数据块来进行重构,不管是原文件分块还是校验块,其分块重构代价则为6.
如图1所示,GPEC(k,m,g)编码,将一个文件划分为k个文件块(File Parity),以此计算出m个文件校验块(Group Parity),然后将k个分块分为g个组,每组计算出一个组校验块,即每k/g个文件块计算出一个组校验块.按照传统纠删码的参数,n等于k+m+g,即经过GPEC编码后总共有k+m+g个数据块,码率即磁盘利用率为k/n,额外磁盘开销为(m+g)/k. GPEC(6,2,2)的额外磁盘开销为0.67,RS(6,3)的额外磁盘开销为0.5,而三副本冗余方式的额外磁盘开销为2,通过对比GPEC拥有可接受的磁盘开销.

图1 GPEC校验图

1.1 分组校验纠删码编码规则
编码规则是纠删码算法的核心内容,描述了纠删码算法的编码过程,其对应的逆过程即为算法的解码过程.以GPEC(6,2,2)为例,将文件分为6块,每三个文件块一组分为两组.假设6个文件块分别为X0、X1、X2、Y0、Y1、Y2.其中X组包含X0、X1、X2,Y组包含Y0、Y1、Y2.假设组X和组Y的编码系数分别为α、β,在伽罗瓦有限域GF(28)中定义乘法和加法两种运算,则可建立如下等式:
α00x0+α01x1+α02x2=r1
α10x0+α11x1+α12x2=r2
α20x0+α21x1+α22x2=r3
β00y0+β01y1+β02y2=r4
β10y0+β11y1+β12y2=r5
β20y0+β21y1+β22y2=r6
以此为基础,定义校验块数据分别为:GP1=r1,GP2=r4,FP1 =r2+r5,FP2 =r3+r6.为了便于简化系数矩阵的寻找过程,假设α、β矩阵都为范德蒙矩阵,如下所示:
综上,分组校验纠删码的校验块生成等式,即GPEC的编码规则为:
X0+X1+X2=GP1
Y0+Y1+Y2=GP2
α0X0+α1X1+α2X2+β0Y0+
β1Y1+β2Y2=FP1
由该编码规则可知,GPEC是GF(2w)上的线性码.根据Singleton界定理,有汉明距离最小值d≤n-k+1,实验测试GPEC(6,2,2)中d最大不超过4,表明分组校验纠删码不是极大距离可分码.根据上述四个线性方程组构成的编码等式中的系数矩阵,可以确定分组校验纠删码的一致校验矩阵中不满足任意4列线性无关,根据最小距离定理,证明GPEC不满足MDS[4]性质.
1.2 编码系数设置
依据上述编码等式,我们得到一个初步的编码系数矩阵即分组校验纠删码的生成矩阵.为了使等式可逆,即数据块丢失时可恢复,需要找到合适的α和β.GPEC(k,m,g)使用了m+g个校验块,根据编码后的数据丢失情况构成解码方程组,而α和β必须使线性方程组可解.这样要求线性方程组的系数矩阵必须可逆,考虑下面这三种数据块丢失情况:
第一种,两个组校验块(GP1,GP2)和两个文件块丢失.假设两个文件块各自在X和Y组中,用Xi,Yj表示,则其方程组为:
αiXi+βjYj=R
αi2Xi+βj2Yj=T
从而其解码系数矩阵和对应的行列式分别为:
由于X组或Y组中任意数据块都有丢失的可能,故下标i、j都分别为0,1,2中的任何一个.从参数向量中的元素α0,α1,α2,β0,β1,β2都必须满足基于该系数矩阵的要求,下面的矩阵或等式中同理.
第二种,一个组校验块和三个文件块的丢失,三个文件块分别在X和Y组中.假设三个文件块中一个在X组中,两个在Y组中,丢失的组校验块为GP2,则可以得到如下线性方程组:
Ys+Yt=S
αiXi+βsYs+βtYt=R
αi2Xi+βs2Ys+βt2Yt=T
故其解码系数矩阵为:
=αi(βs-βt)(βs+βt-αi)
第三种,四个文件块的丢失,且X组和Y组各有两块.同前面两种情况一样,我们可以得到线性方程组的系数矩阵为:
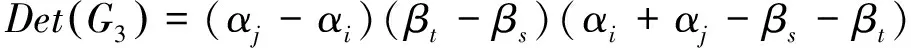
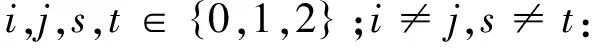
αi,αj,βs,βt≠0
αi≠βs
αi≠αj,βs≠βt
αi≠βs+βt,αi+αj≠βs
αi+αj≠βs+βt
为了找到符合该条件的α、β,我们可以查找伽罗瓦有限域GF(28)中的数值,即αi,βs都是用8位二进制表示的无符号整数.通过计算α和β分别有7个数值可以选取.例如(0x01,0x02,0x03,0x10,0x20,0x30)即是一组“合法”的(α0,α1,α2,β0,β1,β2).
由于不等式的建立过程中,因式分解丢失了对β2的考察.由于范德蒙矩阵在有限域中满秩的特性,在参数设置的初期我们选择了范德蒙矩阵作为系数矩阵.可以看到在GF(28)中,上面有效的β值(二进制低4位和最高位0为0的值)的平方模256皆为0.显然,这样的系数矩阵不属于范德蒙矩阵,导致在编码过程中会丢失对应的值.为了解决这个问题,需要使用β的低四位,比如将最低的位置1即可保证其平方值在GF(28)下不为零.因为β中高四位的特性,上述不等式仍然可以满足.最后找到满足上述所有条件的α和β值,如(0x01,0x02,0x03,0x15,0x25,0x45)即是一组符合条件且保证生成矩阵为非奇异阵的参数.
2 性能对比测试与结果
本文以目前流行的开源云计算项目Openstack中的分布式对象存储系统Swift为原型搭建了云存储系统.系统部署在三个机架上的12台HP服务器上,其中两台服务器作为代理节点,其他10台作为存储节点.每个节点均采用同样的配置:CPU四核2.0 GHz,千兆网卡、500 G硬盘、操作系统CentOS 6.3.
2.1 编码效率分析
编码时间与文件的大小和读写速度有很大的关系,故测试了几种不同大小的文件, 分别比较分组校验算法和RS编码、柯西编码三种算法的编码速度.参数分别为GPEC(k=6,m=2,g=2)、RS(k=6,m=3)、CRS(k=6,m=3).

图2 编码速度测试
图2中结果显示,Cauchy RS编码具有较好的编码优势,平均编码速度达到40 MB/s,而标准RS编码为35 MB/s,分组校验纠删码算法平均速度为32 MB/s,达到了基准速度47.5 MB/s的67.4%,也就是实际编码计算只占用了其中32.6%的时间.分组校验纠删码算法在文件小于200 MB时,和RS编码算法效率比较接近,整体上和RS编码以及Cauchy编码还有一定的距离和优化空间.
2.2 解码效率分析
当出现节点故障等问题导致数据丢失或损坏时,需要对数据进行修复,即解码.解码速度主要由数据块读取速度、网络带宽、译码速度等决定.为了更好的体现算法的译码速度,所有解码的数据块均保存到一台服务器上.同编码测试一样,本节继续以不同大小的文件作为测试的变量,比较分组校验纠删码算法、里德所罗门RS编码和柯西RS编码.比较结果如图3所示.

图3 单个数据块丢失文件解码速度
RS编码在单个数据块丢失时的平均解码速度与文件的平均编码速度较相似,大约在31.5 MB/s左右.Cauchy编码相对RS编码,有一定的优化,达到38 MB/s.相比RS编码和Cauchy编码,分组校验纠删码算法在数据块解码上花费时间最少,100 M文件不到2 s,平均解码速度达到50 MB/s.
3 结论
本文以里德所罗门编码为基础设计了分组校验纠删码冗余算法,详细说明了分组校验纠删码的编码规则和参数设置,并通过具体实验验证该编码规则的性能,相比传统纠删码技术,分组校验能够获得较好的解码效率,从而使各项评价指标达到平衡.
[1] 罗 亮,吴文峻,张 飞.面向云计算数据中心的能耗建模方法[J].软件学报,2014,25(7):1371-1387.
[2] 张 松,杜庆伟.基于预测的云计算热点数据副本因子决策算法[J].计算机与现代化,2015(2):62-67.
[3] 张 乐.云计算环境下的分布存储关键技术研究[J].电子技术与工程,2015(23):185-189.
[4] L.Xu.and J.Bruck.X-code.MDS Array Codes with Optimal Encoding[J]. IEEE Trans.on Information Theory. Jan,1999,45(1):272-276.
Redundancy Algorithm of Group Parity Erasure Code Under Cloud Storage Environment
ZENG Sai-feng,QU Xi-long
(School of Computer and Communication, Hunan Institute of Engineering, Xiangtan 411104, China;2. Hunan Provincial Key Laboratory of Wind Generator and Its Control, Hunan Institute of Engineering, Xiangtan 411104, China)
In the massive cloud storage system,the hot research problem is to improve storage utilization and reduce the computation complexity of redundancy scheme. Redundancy algorithm of group parity erasure code can reduce the erasure code fragments required for data reconstruction, thereby decreasing the demand for storage network bandwidth and system I/O, and reducing the load of the storage system. Coding rules and parameter settings of group parity erasure code are described in this paper. Good fault tolerance and space utilization are verified through experimental analysis algorithm, meeting the codec performance required for cloud storage system.
cloud storage; erasure code; redundancy algorithm; group parity
2016-05-06
湖南省自然科学基金资助项目(2016JJ2040);湖南工程学院博士启动基金项目(15044).
曾赛峰(1983-),男,博士,讲师,研究方向:网络存储、大规模分布式存储、云存储.
U462.3TM615
A
1671-119X(2016)04-0042-04
