基于相似用户索引和ALS矩阵分解的推荐算法研究
2016-12-28王保云
盛 伟, 余 英, 王保云
(云南师范大学 信息学院, 云南 昆明 650500)
基于相似用户索引和ALS矩阵分解的推荐算法研究
盛 伟, 余 英, 王保云
(云南师范大学 信息学院, 云南 昆明 650500)
针对交替最小二乘法(ALS)在处理大数据集时所面临的处理速度和计算资源问题,提出了基于相似用户索引的分布式矩阵分解推荐算法。首先算法基于用户的评分行为找到用户之间的最近邻,然后使用Spark平台运行提出的算法,并产生推荐。在GroupLens网站上提供的MovieLens数据集上进行仿真实验,实验结果表明,提出的算法能够有效解决ALS对于大数据集运行效率低及在云环境中可扩展性较差的问题。
交替最小二乘法; 最近邻; 推荐算法; Spark
个性化推荐系统如同一个信息过滤器,只把有用的信息提供给用户,有效解决了信息过载的问题。协同过滤算法[1]是最成功的个性化推荐技术之一,被广泛应用于很多领域。然而,在现实生活中用户和物品的数量庞大,而消费者通常只对一小部分物品进行评分,造成了评分矩阵严重稀疏,这导致传统协同过滤算法可以利用的数据非常有限,推荐精度较差。在用户和物品不断增加的同时,评分矩阵的维度也变得极高,这使得传统协同过滤算法的计算复杂度急剧增加,由此产生了可扩展性较差的问题。针对数据稀疏性问题,李红梅等[2]提出利用LSH快速获取目标用户的近邻用户集合,然后采用加权方法来预测用户评分并产生推荐;LIKA B等[3]提出了分类算法与相似度技术相结合的模型。针对可扩展性较差的问题,孙天昊等[4]在分布式平台下,提出改进聚类协同过滤推荐算法。近年来,隐语义模型(Latent Factor Model,LFM)[5]受到越来越多的关注,矩阵分解技术是其中最常用的一种方法,这是一类有效解决数据稀疏性问题的推荐算法,基于它的推荐模型获得了Netflix Prize推荐比赛冠军。此后,该方法被应用于更多的推荐系统研究中[6-7]。在众多基于矩阵分解的方法中,交替最小二乘(Alternating Least Squares,ALS)算法最为流行,它非常容易实现并行化计算。可是,随着用户数量的增加,ALS需要计算更多用户的评分集信息,计算量会迅速增大,ALS在大数据集下的可扩展性更加不理想。
大数据计算平台的更新及数据的增长进一步促进了推荐系统的快速发展。Spark是一个高效的分布式计算平台,不同于需要过多的文件读取操作的MapReduce,可以将任务中间输出结果保存在内存中,因此Spark能更好地适用于数据挖掘、矩阵分解等需要迭代的算法。
本文提出一种基于相似用户索引的分布式矩阵分解推荐算法,结合分布式计算特点,利用位置敏感哈希(Locality Sensitive Hashing,LSH)处理高维数据的良好特性来快速寻找用户之间的近邻集合,并将其植入到ALS矩阵分解推荐技术中,降低了计算复杂度,改善了算法可扩展性较差的问题并且在一定程度上提高了推荐精度。
1 基于相似用户索引和ALS矩阵分解的推荐算法
首先将己知用户-物品评分数据集分为训练集T1和测试集T2,训练集用来学习矩阵特征并构建LSH模型,测试集用来评价推荐结果。本文提出的算法分为两个阶段进行,分别是LSH的相似用户索引构建和基于ALS的矩阵分解推荐。以上阶段均在Spark集群下进行分布式计算,算法流程如图1所示。
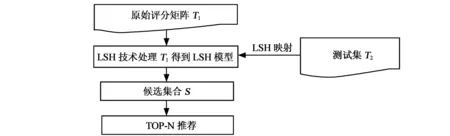
图1 基于相似用户索引和ALS矩阵分解的推荐算法流程图
Spark是UC Berkeley AMP Lab开源的通用并行计算框架。Spark立足于内存计算,提供了批处理、实时数据处理、机器学习以及图算法等一站式服务,非常适合于各种迭代算法和交互式数据挖掘。Spark中使用了弹性分布式数据集(Resilient Distributed Datasets,RDD)[8]抽象分布式计算,即使用RDD以及对应的相关操作来执行分布式计算;并且基于RDD之间的依赖关系组成Lineage以及CheckPoint等机制来保证整个分布式计算的容错性。
Spark运行架构如图2所示,用户将任务提交给Driver,Driver将任务分发到所有的Worker节点。Worker节点根据Driver提交过来的任务,算出位于本地的那部分数据,将数据以RDD的形式保存到内存中,然后对RDD进行接下来的计算。用户提交的任务一般在Cluster Manager中运行,目前Spark支持Standalone、Mesos和YARN等不同的Cluster Manager,本文选择的是Standalone模式。
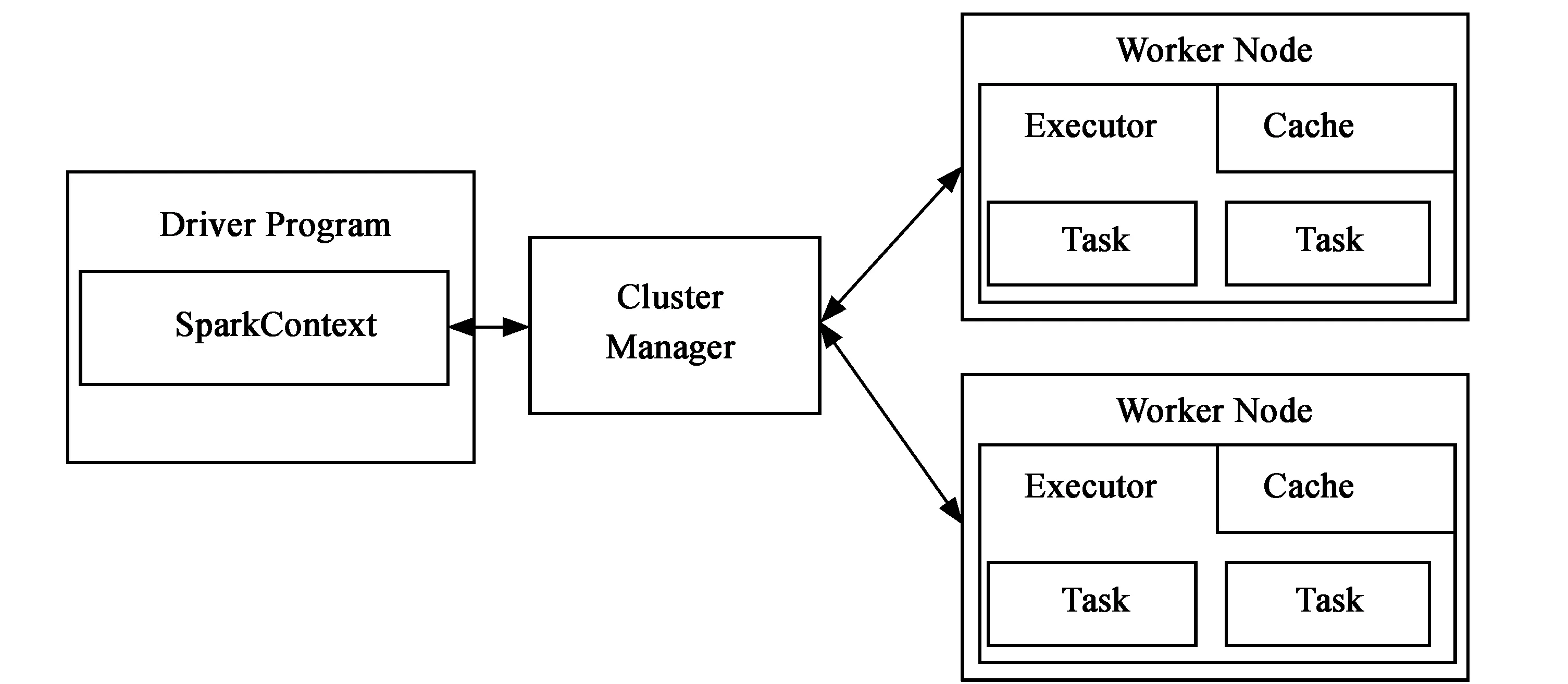
图2 Spark运行架构图
1.1 基于LSH的相似用户索引构建
建立相似用户索引,不仅可以过滤掉与目标用户不相关的评分信息,还降低了推荐算法需要计算的评分矩阵维度。因此,基于相似用户索引的推荐算法能够快速为用户产生推荐。
针对上述问题,本文引入LSH[9-10]对相似用户建立索引。LSH是当前最流行的近似最近邻快速查找技术之一,它使用哈希的方法把数据从原空间哈希到一个新的空间中,如果数据在原空间中相似,那么哈希到新的空间中的数据也保持一定的相似性。LSH通过原始评分矩阵,能够将评分行为相似的用户以一定的概率散列到同一个桶中。
定义(位置敏感哈希) 存在函数族H={h:S→U},对于任意的数据点p,q∈S,都有:
若p∈B(q,r1),则Pr[hi(p)=hi(q)]>p1;
若p∈B(q,r2),则Pr[hi(p)=hi(q)]>p2;
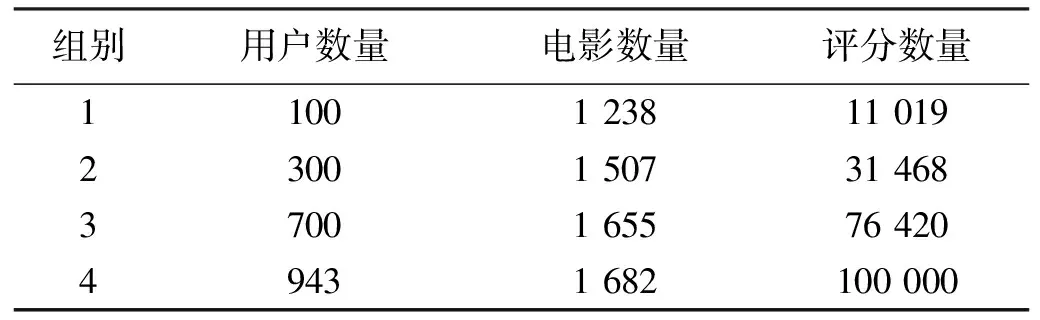
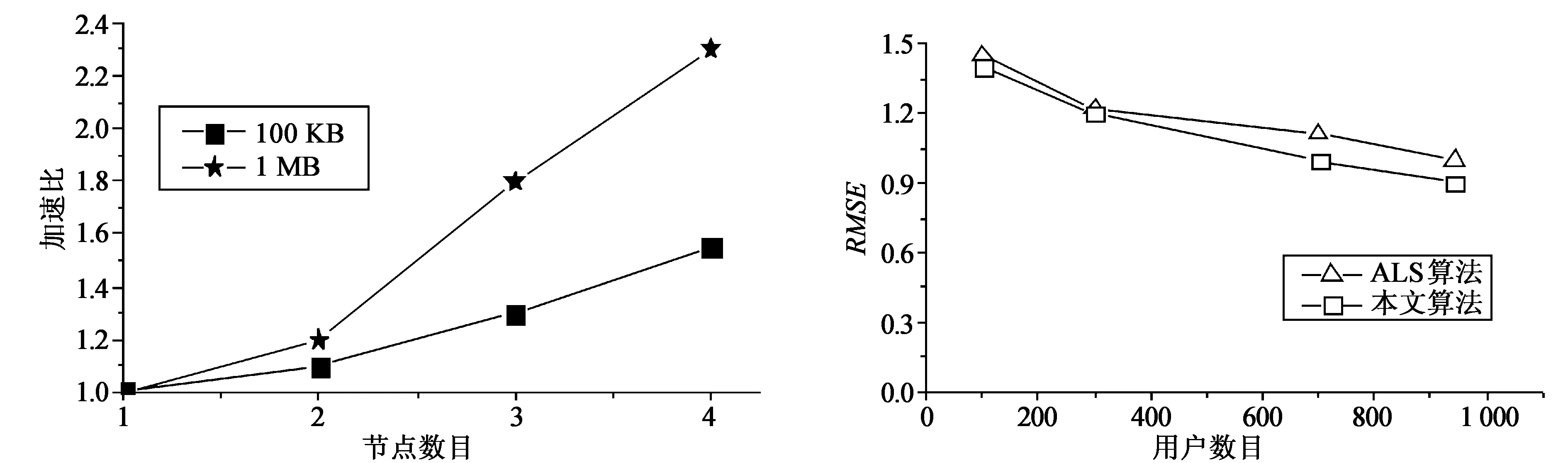
如果满足条件p1>p2和r1 对评分数据处理之前,首先需要将评分数据向量化。通常评分数据向量化是对用户评分行为的提取,通过相关计算将评分数据转化成对应的高维向量。常用的向量度量方式有:欧式距离、杰卡德距离以及余弦距离等。在这些度量方式中余弦距离在实际应用中有较好的效果。 在余弦距离的度量下,Chairkar M S[11]于2002年提出了超平面的思想,通过随机的超平面将原始数据空间进行划分,其中每一个空间构成一个散列桶,而位于每个桶内的数据被认为具有很大的相似性。因此我们选用超平面的思想方法对评分数据进行哈希。Chairkar M S设计了一族哈希函数,使得落入平面一侧的向量被哈希为1,另一侧被哈希成为0,哈希函数如公式(1)所示: (1) 其中v是待哈希的向量,u是随机生成的向量。 当数据量变得很大时,用户评分行为向量的维度也变得很高,单机模式的LSH构建会因为内存的限制而变得很慢,甚至无法继续运行。本文利用Spark平台将LSH构建过程分布化和并行化,以适应海量高维数据的计算需求。基于Spark的LSH索引模型构造算法描述如下: 输入:评分数据T1,哈希函数数目K,哈希表数L; 输出:LSH索引模型, ① var sc=new sparkContext( ), ② val data=sc.textFile("...",numPartion), ③ 数据经过map生成sparseVectorData:RDD[user_id,SparseVector],SparseVector是序列 ④ Hasher(K*L,seed)随机生成K*L个哈希函数Hash(u:SparseVector)利用随机生成的哈希函数和公式(1)对每个向量生成hash signature (e.g.11110010), ⑤ 保存哈希过的向量hashTables:RDD[((hashTableId,hashValue),user_id)], ⑥ 输出LSH模型。 代码中:第①—②行初始化SparkContext,从HDFS中读入数据;第③行根据原始评分数据生成每个用户对所有已评分项目的评分记录向量;第④—⑤行利用随机超平面的思想对原始数据进行划分。 1.2 基于ALS的矩阵分解推荐算法 在协同过滤推荐系统中,输入数据可以用一个m行n列的评分矩阵T来表示,本文称之为User-Item矩阵,其中m表示用户数目,n表示物品数目。真实生活中消费者产生的评分数据非常少,造成User-Item矩阵极为稀疏。矩阵分解的核心思想是把稀疏的User-Item评分矩阵分解为两个低维度的矩阵P和Q,用一个重构的低秩预测矩阵X=PQT来逼近原来的评分矩阵,逼近的目标是使预测矩阵和原始矩阵之间误差的平方最小,其中P为m×d(d表示特征个数,也即为低维度矩阵的维度)的用户特征向量矩阵,Q为n×d的物品特征向量矩阵。预测方法如公式(2)所示: (2) 其中pu和qi分别为用户u和物品i的特征向量,rui为用户u对物品i的预测评分。当矩阵中含有大量空值时,此模型容易导致过拟合问题。许多研究者建议采用一个正则化[12]模型来避免过拟合问题。其需要优化的函数如式(3): (‖pu‖2+‖qi‖2), 治疗前,体表光学检测(OSMS)误差X方向平移和Y方向旋转与治疗前CBCT验证误差比较,差异无统计学意义,t=1.48,P=0.14;t=0.72,P=0.47。治疗前,体表光学检测误差Y方向平移、Z方向平移、X方向旋转和Z方向旋转与治疗前CBCT验证误差比较差异有统计学意义,t值分别为4.97、2.13、7.05和2.29,P值分别为0、0.03、0和0.02。 (3) 其中λ是正则化系数,K代表已有评分记录,rui为用户u对项目i的真实评分。ALS算法是求解上述模型最常用的方法。 ALS算法基本求解思想是固定P求解Q,然后固定Q求解P,重复交替上述两步直到算法收敛。ALS算法易于实现并行化,然而随着评分数据的增加,它需要更多的计算时间,大数据集下推荐效率不高。因此本文采用LSH和ALS相结合的算法。对于评分矩阵T,可以利用LSH算法对具有相似评分记录的用户进行粗略划分,得到相应的相似用户评分数据。然后为了产生项目推荐结果,可以利用相似用户的评分数据进行ALS推荐。这样不仅减少了ALS算法的计算量,改善了算法可扩展性较差的问题,也提高了推荐精度。算法描述如下: 输入:原始评分矩阵T1,评分测试集T2,LSH索引模型LSHModel; 输出:推荐列表, ① var sc=new sparkContext( ), ② val data=sc.textFile("...",numPartion), ③ 读入T2生成TestRatings:RDD[Rating],Rating是序列 ④ LSHModel.getCandidates(TestRatings:RDD[(Int,Int,Double)])生成相似用户集合U, ⑤ 读入T1根据U生成候选集Hratings:RDD[Rating], ⑥ ALS.train(Hratings,rank,numIter,lambda)对评分数据Hratings进行numIter次训练,rank是用户因子矩阵和项目因子矩阵的维度,lambda是正则化因子, ⑦ recommendProducts(r,i)为用户r产生i个初始推荐, ⑧ 输出推荐列表。 代码中:第①—②行初始化SparkContext,从HDFS中读入数据;第③行读取并生成评分测试集;第④—⑤行评分测试数据集通过算法1的LSH模型的LSH映射获得相似用户集合,最后生成评分数据候选集合。第⑥—⑦行ALS算法训练候选集合生成ALS推荐模型,完成测试数据集的用户TOP-N推荐。 根据上述研究,利用4台计算机搭建Spark分布式集群,其中一台计算机作为Master节点,另外3台作为Slave节点负责运算。每个节点内存为2 GB,2核,安装CentOS 6.7操作系统和Spark 1.4.1。程序采用IntelliJ IDEA集成开发环境完成。从GroupLens网站(http://www.gouplens.org)下载MovieLens 100 KB和1 MB两个不同大小的数据集作为本文的数据源,其中100 KB数据集包含了943个用户对1 682部电影的评分,共100 000条评分记录;1 MB数据集包含6 040个用户对3 900部电影的评分,共1 000 209条评分记录。 实验采用加速比S=L1/Ln衡量同一数据集下增加节点时本文算法的运行效率,其中L1为单个节点完成任务所需的时间,Ln为n个节点完成任务所需的时间。实验过程中,从1个节点增加到4个节点,分别测试100 KB和1 MB数据集在单机模式下的运行时间以及在不同规模Spark集群下的运行时间,获取其完成运算所需时间L1—L4,绘制加速比曲线图如图3所示。 从图3可以看出,随着Spark集群节点数目的增加,两组数据集的加速比值都在增大,因此增加节点数目可以提高算法执行效率。100 KB数据集的加速比值较小,加速比曲线增长缓慢,1 MB数据集的加速比值较大。针对同一节点,数据量很小的情况下加速比不明显,随着数据量增加,加速比曲线提升明显,可以预期处理更大规模数据集时,本文算法执行效率会进一步提升。 实验采用均平方根差RMSE[13]作为本文算法推荐质量的评价指标。RMSE的值越小,表明算法的推荐准确率越高,其公式为 (4) 其中N为物品数量,ri为真实的评分,pi为预测的分数。从100 KB数据集中分别选取用户数量为100、300、700和943作为4组实验数据(表1)。本文实现的算法与传统矩阵分解算法的比较如图4所示。 表1 4组实验数据量 图3 加速比曲线图 图4 RMSE值 从图4可看出,随着用户数据逐渐增大,ALS推荐算法的推荐精度也在逐渐提高,所以ALS算法在处理大规模数据集时在推荐精度上有显著优势。然而,由于数据量巨大,ALS算法需要计算很多不相关信息,推荐精度还有进一步提升的空间。本文算法利用LSH技术找到用户最近邻,过滤掉不相似用户的评分信息,在此数据集的基础上再进行推荐,在改善ALS算法复杂度的同时,推荐结果也更加精确。 本文针对ALS矩阵分解算法存在的计算开销大及可扩展性较差的问题,结合Spark分布式计算和LSH快速处理高维数据的特点,提出了基于相似用户索引的分布式矩阵分解推荐算法。利用LSH找到用户之间的最近邻集合,ALS通过这些用户的评分数据重新排列用户的喜好列表,形成最后的推荐,降低了时间复杂度。同时,算法在大数据环境下具有良好的可扩展性。后续研究将结合其他用户信息或者项目信息进行更准确地推荐。 [1] LIU Zhao-bin,QU Wen-yu,LI Hai-tao,et al.A hybrid collaborative filtering recommendation mechanism for P2P networks[J].Future generation computer systems,2010,26(8):1409-1417. [2] 李红梅,郝文宁,陈刚.基于改进LSH的协同过滤推荐算法[J].计算机科学,2015,42(10):256-261. [3] LIKA B,KOLOMVATSOS K,HADJIEFTHYMIADES S.Facing the cold start problem in recommender systems[J].Expert Systems with Applications,2014,41(4):2065-2073. [4] 孙天昊,黎安能,李明,等.基于Hadoop分布式改进聚类协同过滤推荐算法研究[J].计算机工程与应用,2015,51(15):124-128. [5] KOREN Y,BELL R,VOLINSKY C.Matrix factorization techniques for recommender systems[J].Computer,2009,42(8):30-37. [6] JAMALI M,ESTER M.A matrix factorization technique with trust propagation for recommendation in social networks[C]// Proceedings of the fourth ACM conference on Recommender systems.ACM,2010:135-142. [8] ZAHARIA M,CHOWDHURY M,DAS T,et al.Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[C]//Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation. USENIX Association,2012:2. [9] ANDONI A,INDYK P.Near-optimal hashing algorithms for near neighbor problem in high dimensions[C]//Proceedings of the Symposium on the Foundations of Computer Science,2006:459-468. [10] SLANEY M,CASEY M.Locality-sensitive hashing for finding nearest neighbors [lecture notes][J].IEEE Signal Processing Magazine,2008,25(2):128-131. [11] CHARIKAR M S.Similarity estimation techniques from rounding algorithms[C]//Proceedings of the thiry-fourth annual ACM symposium on Theory of computing.ACM,2002:380-388. [12] PATEREK A.Improving regularized singular value decomposition for collaborative filtering[C]//Proceedings of KDD cup and workshop,2007:5-8. [13] RICCI F,ROKACH L,SHAPIRA B,et al.Recommender systems Handbook[M].Berlin:Springer-Verlag,2011:109. [责任编辑:魏 强] ALS-based matrix factorization recommendation algorithm with similar user index SHENG Wei, YU Ying, WANG Bao-yun (School of Information Science and Technology, Yunnan Normal University, Kunming 650500, China) In order to solve the bottleneck problems of processing speed and resource allocation of Alternating Least Squares (ALS), a distributed parallel matrix factorization recommendation approach with similar user index was proposed. First, the approach found nearest neighbors among the users based on their ratings; Then, Spark was employed to implement the proposed approach, and the recommendation to the user is produced. Simulate experiments in MovieLens datasets provided by GroupLens website show that the proposed algorithm can resolve the issue of low execution efficiency of ALS for large-scale datasets and the worse scalability in clouds. alternating least squares; nearest neighbors; recommendation algorith; Spark 1673-2944(2016)06-0047-06 2016-05-06 2016-06-13 云南省教育厅科学研究基金资助项目(2014Y145) 盛伟(1988—),男,江苏省丰县人,云南师范大学硕士研究生,主要研究方向为推荐系统;[通信作者]余英(1965—),女,云南省昆明市人,云南师范大学副教授,硕士生导师,硕士,主要研究方向为网络通信;王保云(1977—),男,云南省玉溪市人,云南师范大学讲师,博士,主要研究方向为机器学习。 TP391.3 A2 实验及结果分析
3 结 语
