Structure and context adaptive entropy codersfor ultra-compression efficiency
2016-12-22MURSHEDManzur
MURSHED Manzur
(Faculty of Science and Technology, Federation University Australia, Churchill Vic 3842, Australia)
Structure and context adaptive entropy codersfor ultra-compression efficiency
MURSHED Manzur
(Faculty of Science and Technology, Federation University Australia, Churchill Vic 3842, Australia)
Our appetite for rich visual contents and interactivity has led to a huge jump in raw data volume of future generation video technologies. Contents for the Full Ultra High Definition TV (FUHDTV) at 120 fps, to be commercially released overseas late this year, has to pack 128 times more raw pixels per second compared to HDTVi, the current best transmission format of Australian free-to-air TVs. A similar growth in data volume is expected for a multiview broadcasting in HDTVi format with 120 viewpoints. While the latest High Efficiency Video Coding (HEVC) standard is flexible enough to support encoding data streams for both FUHDTV and multiview broadcasting with as many as 120 viewpoints, the ultra-compression efficiency needed to transmit such streams via traditional broadcasting networks cannot be met with the current state-of-the-art context-adaptive entropy coders. A generalized coding paradigm capable of exploiting structural-similarity will be presented here to significantly improve compression efficiency of the existing context-adaptive coders.
ultra-compression efficiency, context-adaptive coder, structural-similarity, compression framework
CLC Nubmer: TN919.81 Document Code: A Article ID: 2095-6533(2016)06-0001-06
Perhaps the beauty in brevity and simplicity is nowhere expressed so elegantly in a scientific field than data compression. Not only does this field relate immediately to its ancient philosophical counterpart, the Occam’s Razor principle[1], which suggests not to introduce any additional concept unless necessary, but it has also never lost touch with the contemporary science, as it blends so eloquently in today’s motto towards sustainable future. Data compression is the art of expressing information using a description as short as possible. It is an art because what constitutes information is not an exact science as information is often relative/subjective, to what we already know. A message may carry meaningful information to someone while remain clueless to others. Nevertheless, today’s data compression research is founded on one of the earliest branches of applied mathematics, information theory, which helps defining what constitutes information and how their intrinsic correlations can be exploited to achieve brevity in expression. Note that data compression is subject to a space-time trade-off, i.e., the compressed data must be decompressed before use, which results in extra time.

Video data compression technology has so far been able to meet the compression efficiency needed to transmit larger display capacity through the radio spectrum apportioned to the broadcasting industry. While the latest High Efficiency Video Coding (HEVC) standard[3]has doubled the compression efficiency of its predecessor H.264 and its video file format can accommodate up to 300 views, it is unable to cope with the ultra-compression efficiency needed to transmit FUHDTV through the normal broadcasting channels. This paper presents a novel video coding paradigm to address this challenge. Unlike HEVC, which primarily exploits contextual correlations to achieve data compression, the new coding paradigm also exploits structural correlations such as data clustering tendency. Experimental results have shown that structure-context adaptive coding technique can improve coding efficiency of HEVC’s context adaptive coding by more than 50%.
The rest of the paper is organised as follows. Section 1 outlines the traditional context adaptive coding. The structure-context adaptive coding paradigm is introduced in Section 2 along with a novel 5D multiview video coding framework in Section 3. Section 4 concludes the paper.
1 Context adaptive coding
Data compression framework, in general, has two significant stages: modelling and coding. In the modelling stage, various prediction, transformation, and context models are applied on the raw input data stream to split it into a number of mutually-exclusive subsets such that each may be deemed as if drawn from an independent and identically distributed (iid) source. The coding stage then separately encodes each of these subsets using an optimal entropy coding technique. For lossy coding, entropy coding is preceded by a quantization step.

Optimal entropy coding is a solved problem. It has been established that a simple arithmetic coding[5]implementation can achieve Shannon entropy by generating a single code for the entire sequence xnof n symbols with code length matching nH bits. The encoder iteratively reduces the initial interval
|b0,l0〉=[b0,b0+l0)=[0,1)
by a factor of the probability of the current symbol xi, concomitantly factoring into its order in the alphabet, as
|bi,li〉=|bi-1+li-1F(xi-1),li-1f(xi)〉,
where F is the extended cumulative distribution function (cdf) corresponding to the discrete probability density function (pdf) f, defined over the alphabet, with an extra entry F(0)=0. At the end of the iteration, a carefully selected value from the final interval |bn,ln〉 is returned in binary. Successful decoding is guaranteed so long the source distribution is also known to the decoder.
Optimal modelling, on the contrary, remains allusive. Modelling is highly subjective as it is closely related to message semantics. Finding an optimal model for a coding problem is also computationally prohibitive. Developing efficient generic modelling heuristics is still an open research problem. Prediction and context-adaptation are two of the prevailing generic modelling tools.
Often prediction is used as a generic pre-processing to aid modelling and reduce resultant entropy. Consider the simplest linear prediction model, which estimates the current symbol xiusing a linear combination of the m recently-encoded symbols

where wj(j=1,2,…,m) are constant weights such that
算法要求:在前期有较高的全局搜索能力以得到合适的位置,找到合适的位置后,a值能迅速减小进入局部搜索以加快收敛速度,在后期要求有较高的局部开发能力,以提高算法收敛精度。本文提出一种基于对数递减策略的非线性动态变化收敛因子更新公式:
It has been shown that often the residual
exhibits the traits of a white noise with zero mean with entropy lower than xi.
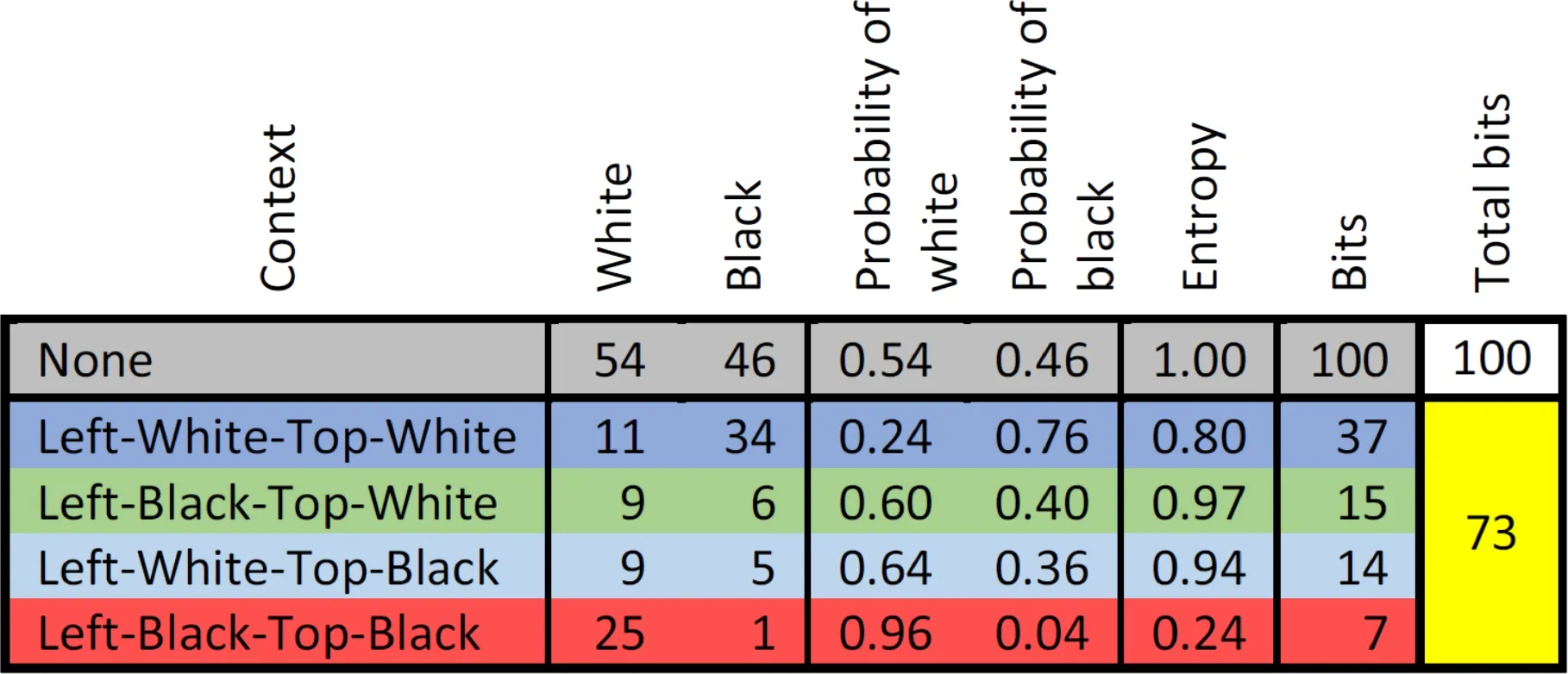
Context-adaptation, in general, refers to a process of splitting the input sequence into multiple sub-sequences using the neighbourhood of individual symbols. The idea is originated from the observation that symbols surrounded by similar neighbourhood exhibit more-or-less identical pdf, which effectively aids the coding stage in achieving higher compression. To restrict the modelling overhead, the neighbourhood is classified into a finite number of contexts. For example, a 2D 10×10 binary sequence is modelled with four contexts based on left-top neighbourhood in Fig. 1 and the corresponding 27% improvement in compression efficiency is presented in Table 1. For video coding applications, context-adaptive binary arithmetic coding (CABAC)[6]is found to be superior for providing much better compression than most other entropy encoding algorithms. While CABAC is supported only in the Main and higher profiles of H.264, HEVC uses CABAC in all its profiles extensively for encoding coding modes, motion vectors, and residuals.

Fig.1 Modelling of a 2D binary sequence (left) with four contexts based on left-top neighbourhood (right)
Table 1 Context modelling for improved compression efficiency
2 Structure-context adaptive coding
Often input sequences drawn from real-world applications exhibit clustering tendency that context-adaptive technique alone cannot exploit efficiently. Consider digital photography where an image capturing a natural scene may have distinct regions of separation as if it is a collage of homogeneous images of different sizes. The most natural modelling operation for such an image would be to partition the images into structurally similar regions before applying any context model. This is analogous to using variable-sized coding-blocks that are defined adaptively by the structure of the data. Such an idea also contrasts the conventional wisdom where an image is first divided into a mesh of fixed-size coding-blocks that are further partitioned to exploit intra-block structural similarity. For example, HEVC uses 32×32 pixels coding units that may be partitioned into smaller square and/or rectangular coding units.
A simple binary tree based decomposition technique, which iteratively splits a block of 2D data either horizontally or vertically such that the collective entropy of the partitions is smaller than that of the block, can be used as an effective partitioning tool for exploiting structural similarity. Consider the 2D 24×24 binary sequence in Fig. 2, which is partitioned into four 4×24, 8×24, 12×5, and 12×19 coding blocks using binary tree based decomposition. Table 2 presents the ultra 42.5% improvement in compression efficiency achieved by the combined structure-context adaptive coding, compared to 32% improvement with only context-adaptive coding. Structure-context adaptive coding has already been successfully applied for lossless image coding[7], near-lossless depth coding[8], and depth motion vector coding[9].

Fig.2 Structure-context adaptive coding of a 2D binary sequence (left) with a binary tree (right) based decomposition.Blue, green, and red tree nodes represent horizontal-split, vertical-split, and no-split, respectively,with the number inside denoting the split row/column
Table 2 Structure-context modelling for ultra-compression efficiency

3 5D video compression framework

Fig.3 Structure-context adaptive 5D-bitmap video coding for ultra-compression efficiency
We have validated the efficacy of this 5D framework on computer generated test bitmaps of low, medium, and high clustering tendency as shown in Fig.4. Each bitmap was generated with width: 320 pixels, height: 240 pixels, temporal: 4 frames, multiview: 4 views, and bit-planes: 8 bits per pixel. Compression efficiency results on these test bitmaps are presented in Table 3. The bit-savings against the state-of-the-art CABAC-2D framework on low, medium, and high clustering bitmaps is 1%~3%, 19%~22%, and 24%~35%, respectively, for fraction of 1’s varying from 0.01 to 0.3. Even for low clustering bitmaps, where structural similarity is homogenous across the bitmap, SCABAC-5D could still manage marginally improving compression efficiency. Obviously, the ultra-compression efficiency is achieved for high clustering bitmaps as these can be partitioned efficiently using binary tree based decomposition to exploit structural similarity.

Fig.4 Computer generated test bitmaps of various degree of clustering tendency
Table 3 Compression efficiency of 5D-bitmap video coding framework

Let A be the number of raw pixels per second of a video sequence and b be the number of bit planes in use. Let B be the number of bits used by the final coding stage of encoding to represent the above volume of pixels in compressed form with a compression factor f=Ab/B.
Let B′
s=(B-B′)/B
having a new compression factor
f′=Ab/B′=Ab/[B(1-s)]=f(1-s)-1.
For the state-of-the-art multiview lossy video coder, 3D-HEVC[3], typically f=100 times compression factor is achieved. If we replace 3D-HEVC’s CABAC-2D coder with SCABAC-5D, we can expect an overall
f′=100(1-0.35)-1=154
times compression factor.
4 Conclusions
Efficient modelling tries to deviate from uniform distribution as much as possible by exploiting domain knowledge and structural redundancies such as spatiotemporal correlations. Context adaptive coding is a powerful modelling tool used to amplify structural redundancies and structure-context adaptive coding is even more powerful tool, which can exploit structural clustering tendency. Structure-context adaptive entropy coder can assist in meeting the ultra-compression demand of next-generation video technology.
Reference
[1] HANSEN M H, YU B.Model selection and the principle of minimum description length[J/OL].Journal of the American Statistical Association,2001,96(454):746-774[2016-05-06].http://dx.doi.org/10.1198/016214501753168398.
[2] World’s first ‘8K TV satellite’ broadcasting live in japan with free viewing for Rio Olympic fans[EB/OL].[2016-08-08].http://www.universityherald.com.
[3] SULLIVAN G, BOYCE J M, CHEN Y, et al. Standardized extensions of High Efficiency Video Coding (HEVC)[J/OL]. IEEE Journal of Selected Topics in Signal Processing, 2013,7(6):1001-1016[2016-06-06].http://dx.doi.org/10.1109/JSTSP.2013.2283657.
[4] SHANNON C E. A mathematical theory of communication[J/OL]. Bell System Technical Journal, 1948,27(4):623-656[2016-06-08].http://dx.doi.org/10.1002/j.1538-7305.1948.tb00917.x.
[5] SAID A. Arithmetic coding[M/OL]//SAYOOD K. Lossless Compression Handbook.New York: Academic Press,2003:101-152[2016-06-10].http://samples.sainsburysebooks.co.uk/9780080510491_sample_795943.pdf.
[6] MARPE D, SCHWARZ H, WIEGAND T. Context-based adaptive binary arithmetic coding in the H.264/AVC video compression standard[J/OL]. IEEE Transactions on Circuits and Systems for Video Technology, 2003,13(7):620-636[2016-06-15].http://dx.doi.org/10.1109/TCSVT.2003.815173.
[7] ALI M, MURSHED M, SHAHRIYAR S, et al. Lossless image coding using hierarchical decomposition and recursive partitioning[J/OL].APSIPA Transactions on Signal and Information Processing,2016[2016-08-01].http://csusap.csu.edu.au/~rpaul/paper/APSIPA 2016.pdf.
[8] SHAHRIYAR S, MURSHED M, ALI M, et al. Lossless depth map coding using binary tree based decomposition and context-based arithmetic coding[C/OL]//2016 IEEE International Conference on Multimedia and Expo (ICME). Seattle, WA, USA: IEEE, 2016:1-6[2016-08-02].http://doi.ieeecomputersociety.org/10.1109/ICME.2016.7552984.
[9] SHAHRIYAR S, MURSHED M, ALI M, et al. Cuboid coding of depth motion vectors using binary tree based decomposition[C/OL]//Proceedings of IEEE Data Compression Conference (DCC). [S.l.]:IEEE,2015:469[2016-06-20].http://dx.doi.org/10.1109/DCC.2015.43.
[Edited by: Chen Wenxue]
可提高超压缩效率的上下文自适应熵编码器
穆尔希德
(澳大利亚联合大学 计算机科学与技术学院, 澳大利亚 丘吉尔维克 3842)
对丰富视觉内容和交互性的研究,极大提高了下一代视频技术所能传输的原始数据量。2016年即将商业发布120 fps全超高清电视(FUHDTV),其每秒内所能传输的原始像素,是澳大利亚免费电视目前所用最佳传输格式HDTVi的128倍。人们对于120-多视点广播HDTVi格式的数据量有着类似增长预期。最新的高效视频编码(HEVC)标准相当灵活,足以为FUHDTV和120-多视点广播提供编码数据流支持,但通过传统广播网络传输这种数据流所需的超压缩效率,与当前最高水平的上下文自适应熵编码器还不匹配。一种能采用结构相似性的一般编码范式将被给出,来大幅提升现有上下文自适应编码器的压缩效率。
超压缩效率;上下文自适应编码;结构相似性;压缩构架
10.13682/j.issn.2095-6533.2016.06.001
Received on:2016-08-10
Supported by:Australian Research Council Discovery Project (DP130103670)
Contributed by:Manzur Murshed(1970-), male, PhD, Robert HT Smith Professor and Personal Chair, engaged in video technology, information theory, wireless communications, Cloud computing, information forensics, and security & privacy. E-mail:manzur.murshed@federation.edu.au
