基于禁忌搜索算法的特征选择方法研究
2016-12-16胡天寒叶明全卢小杰
胡天寒,叶明全,张 浩,卢小杰
基于禁忌搜索算法的特征选择方法研究
胡天寒,叶明全,张 浩,卢小杰
为了提高特征选择对分类结果的准确率,本文提出了一种基于禁忌搜索算法的特征选择方法。该方法利用禁忌搜索算法获得包含特征权值和特征选择向量的相对最优解,然后用得到的最优解向量对测试样本做出预测。实验结果表明,与现有的特征选择方法相比,该方法的分类准确率有了进一步的提高,并且缩短了特征选择的时间。
特征选择;禁忌搜索;特征加权;距离度量
近十年,组合分类器已经成为研究的热点问题。一些学者将组合分类器应用于许多实际领域,如手写字符识别、人脸识别等[1,2]。一般来讲,组合分类器的效果与基分类器的准确率和多样性有很大关系[3]。为了获得KNN组合分类器的多样性,Bao等人[4]提出组合基于不同距离函数的NN分类器来改善NN分类器的分类性能。虽然他们的组合方法采用了不同的距离度量,但他采用的特征子集却是相同的。因此可能会出现一些样本含有与分类无关的特征,并且这些特征的值比较大,从而引起基分类器犯相同的错误。Bay[5]提出了一种不同的组合方法。他采用了单一的距离度量方法,用随机产生的不同特征子集来训练各基分类器,最后采用简单投票规则来组合各个NN分类器,使得分类效果得到了提升。
Zhang和Sun将禁忌搜索(Tabu Search,简称TS)算法运用到特征选择[6]。在他们的方法中,禁忌搜索以Mahalanobis距离作为目标函数,这个目标函数用来评估采用禁忌搜索获得的特征子集的分类器的分类性能。TS中的特征选择向量用0/1位串表示,0表示解向量没有包含某个特征,1表示解向量包含了某个特征。他们的实验结果表明,禁忌搜索算法很容易获得最优解或次优解,并且同其它次优算法或遗传算法相比,降低了计算代价。从此以后,禁忌搜索算法被广泛应用于特征选择问题[7,8]。
Muhammad Atif Tahir和 James Smith对前面bao和Bay提出的问题进行了综合[9]。他们提出只要达到以下两点要求,总体的分类性能就会得到提高:(1)采用禁忌搜索方法而不是随机取样方法来获得各个特征子集;(2)采用不同的距离函数而不是单一的距离度量。并且应该把两者有机地融合到一起,而不是单独的解决问题。为了达到以上目的,他们提出利用基于禁忌搜索方法进行特征选择,用最终得到的特征子集来训练五种不同距离度量的NN分类器,最后对各个NN分类器进行组合,利用简单投票原则做出分类预测。他们的实验获得了很好的效果。然而他们仅仅利用禁忌搜索算法进行了特征选择,将与分类不相关的特征都去掉了,但在剩下的特征中还存在与特征强相关和弱相关的。显然,将这些特征的权重全部等同起来,对分类的效果会产生不利的影响。陈振洲[10]等人指出, KNN算法中样本的距离是由样本的所有特征计算而来,而这些特征中有的特征与分类是强相关的,有的特征与分类是弱相关的,还有的特征与分类不相关。当近邻间的距离由大量的不相关特征所支配时, 就会出现“维度灾难”的问题, 最近邻方法对这个问题尤为敏感。
针对以上问题,Muhammad Atif Tahir等人提出一种基于禁忌搜索的KNN分类器[11]。它同时采用了特征选择和特征加权两种技术。他们的方法中用的特征权值向量是权值的真实值,而特征二进制向量由0/1位串构成。KNN分类器被用来评估禁忌搜索的每一个权值向量。除了特征权值和二进制向量以外,K值也被包含到解向量中。采用squared Euclidean distance进行距离度量。在加权的KNN分类器中,训练样本和测试样本的特征值在分类之前被乘以相应的权值。于是那些具有较高权值的的特征空间被扩大了,而具有较少权值的特征空间被压缩了,从而使得KNN分类器能够利用具有较高权值的特征更加精确地进行分类。
本文在总结前面文献思想的基础上,提出一种基于禁忌搜索算法的特征选择方法。我们利用禁忌搜索的寻优能力,对样本同时进行了特征选择和特征加权,在去除不相关特征的同时,对强相关和弱相关的特征分别赋予不同的权重,进而对各个特征对分类的影响做了全面的考虑。同时由于K值对分类效果也有影响,所以我们将K也包含到解向量当中,随着禁忌循环的执行,不断地搜索最适合的K值,从而获得最佳的分类效果。实验结果表明,该方法一定程度上提高了分类的准确率和缩短了分类的时间。
1 基于禁忌搜索算法的特征选择
1.1 禁忌搜索算法
Glover在1986年首次提出禁忌搜索算法,它是从全局上逐步搜索得到最优解的算法。TS算法通过建立一个存储结构和禁忌准则来避免过多的不必要搜索,并通过特赦准则将被禁忌的优良状态进行释放,从而实现全局优化。TS从确定一个初始解开始搜索,在当前解中确定若干候选解,再从这些候选解中选出最好的解作为最佳候选解。如果最佳候选解的目标值比“best so far”状态好,就忽视它的禁忌特性,用最佳候选解来代替当前解和“best so far”状态,并把相应的对象加入到禁忌表中,同时将禁忌表中各对象的禁忌长度进行修改;若不存在上述候选解,则选择候选解中非禁忌的最佳状态作为当前解,同时将相应的对象加入到禁忌表中,并修改禁忌表中各对象的禁忌长度;重复上面的迭代搜索的过程,直到满足给出的停止准则。
禁忌搜索算法流程如下:
(1)给出算法参数,给初始解x赋值,将禁忌表置为空。
(2)判断算法结果是否满足终止条件。若是,则结束算法并输出最优解;否则,继续以下步骤。
(3)由当前解的邻域函数产生若干邻解,并确定若干候选解。
(4)用藐视准则判断候选解是否满足。若成立,用满足藐视准则的最佳状态y代替x成为新的当前解,即x=y,并用与y对应的禁忌对象来替换最早进入到禁忌表的禁忌对象,同时用y替换“best so far”状态,然后转步骤6;否则,继续以下步骤。
(5)判断候选解对应的各对象的禁忌属性,将候选解中非禁忌对象对应的最佳状态作为当前解,并将它对应的禁忌对象用来代替最早进入禁忌表的禁忌对象。
(6)转步骤(2)。
1.2 基于禁忌搜索算法的特征选择
1.2.1 编码方法。本文提出的基于禁忌搜索算法的编码解的结构包含四个部分,如图1所示。第一部分,W1,W2,…,Wn对应的是n个特征的真实权值;第二部分,B1,B2,…,Bn对应的是n个特征选择向量,由0/1位串组成,0表示该特征不被选择,1表示该特征被选择;第三部分,K是KNN算法中近邻的个数;第四部分是目标函数值。

W1W2………WnB1B2………BnKCost
图1 编码解的结构
1.2.2 目标函数。本文中的目标函数值指采用基于简单投票方案的误分类数目,定义为:
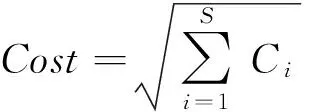
1.2.3 初始解。本文中,初始解的形式如图2所示:

1.01.0……1.011……11K=1Cost=10
图2 初始解
初始的情形是所有特征都被包含进解向量中,而且权值全都为1.0,近邻数也为1。
1.2.4 邻解。邻解是当前解在邻域中所产生的。在本文中,通过两种方式来产生邻解:
(1)对n个不同的特征赋予m个不同的权值,产生m*n个邻解。
(2)通过对特征向量添加或删除特征来产生邻解。
从产生的N个邻解中,选出最好的M个解作为候选解。从而,对Mn(n是距离度量的个数)种集成候选解用目标函数进行评估,选出目标函数值最小的一个解作为最优候选解,即下一轮循环的当前解。
1.2.5 禁忌移动。从某个状态转移到其邻域中的另一状态叫做一次移动。在本文中,如果在第i轮选中某个集成解,在接下来的T轮循环(T表示禁忌表的大小,也可称为禁忌长度)中,禁止再次选中该集成解。
1.2.6 特赦准则。也称为期望准则、藐视准则。特赦准则的机制是暂时停止禁忌移动,在我们的方法中,如果在第i轮选中一个集成解,当前的移动会产生循环以来最优的目标函数值,所以即便它已经在禁忌表中,仍然可以选中它作为下一轮的当前解。
1.2.7 终止规则。常用的终止规则包括:
(1)给定一个迭代步数。
(2)连续迭代T次结果基本保持不变。
(3)当前得到的最优解数目达到预定要求。
给定的迭代步数是本文的终止条件。
1.2.8 本文方法的具体流程。(1)分类器的训练阶段:
在每一轮的循环当中,由每一种距离度量对应的特征向量解产生N个邻解。从N个邻解中选出M个最好的候选解,接着将形成的Mn种集成候选解用简单投票方案进行评估,从而得到能够产生不相关错误的基于各种距离度量的特征子集及其权值。重复地进行这一过程,不断地改善集成分类性能,直至达到终止条件为止。最终我们会得到n种距离度量对应的n个最优特征子集。图3描述了分类器的训练阶段。

图3 训练阶段
(2)分类器的测试阶段:
采用n种距离度量和n种相应特征子集的KNN分类器被组合到一起,用来对测试样本做出分类预测。图4描述了分类器的测试阶段。

图4 测试阶段
2 算法实现与比较
实验中,我们采用的样本是江苏大学附属医院提供的医学数据。其中,样本1包含120个样本,含有9个特征,2个类别;样本2包含190个样本,含有18个特征,2个类别。实验程序采用Java语言编写。使用的机器配置为3.00GHz Pentium(R) D CPU、2.00GB内存、Windows XP操作系统。实验采用的各个参数值如下:

(2) M=2。M是选出的候选解的个数。
MuhammadAtifTahir等人提出一种基于禁忌特征选择的NN分类器(记为T-NN)。为了做出对比,我们利用他们提出的NN分类器在两个样本上进行了实验。同时我们认为KNN分类器的分类效果与K值也有很大关系,因此在他们思想的基础上,将K值也加入到解向量当中(记为K-T-NN),即K值在循环过程中也是在不断变化的。并与本文提出的基于禁忌搜索算法的特征选择方法进行对比分析。为了得到较好的解,我们进行了6次实验。
实验结果如表1所示,从表中数据可以看出,采用的数据为样本1时,利用禁忌搜索算法进行特征选择的K-T-NN组合分类器比T-NN分类器获得的效果要好,K-T-NN组合分类器在6次实验中的最高准确率为95%,而T-NN分类器的最高准确率为90%。这说明,K值对分类效果确实有影响。本文的方法获得的最高准确率可以达到100%,比上面获得的最高准确率分别高5%和10%,而且在禁忌循环次数相同(程序运行时间相同)的情况下,更容易获得最优解。当采用的数据为样本2时,利用禁忌搜索算法进行特征选择的K-T-NN组合分类器和T-NN分类器,获得的最高准确率相同,都为85.7%。我们认为这是由两方面原因造成的:(1)样本2含有18个特征,是样本1含有特征个数的2倍,因此样本2 较样本1更不容易获得最优解;(2)由于KNN适合于大样本分类,而本实验采用的样本量过于偏小,因此,两者的差别不明显。本文的方法获得的最高准确率可以达到94.3%,比上面获得的最高准确率要高出8.6%,并且可以看出随着循环次数的增加获得最优解的可能性也在不断增加。
最后我们还可以看出无论是样本1还是样本2,经过禁忌特征选择后获得的分类效果要比未经特征选择的单分类器和组合分类器要好很多。并且缩短了程序运行的时间。
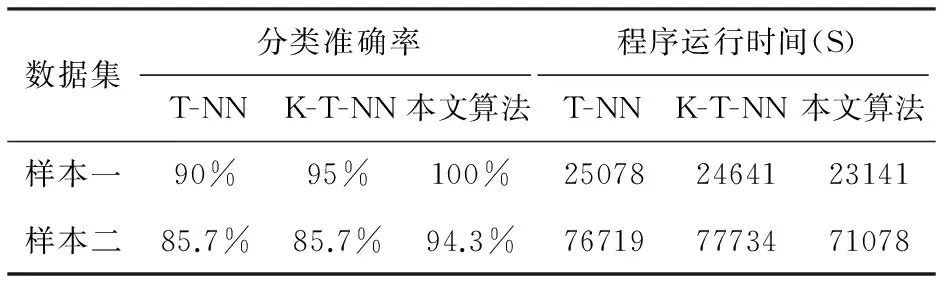
表1 本文算法同T-NN及K-T-NN算法在分类准确率和程序运行时间上的比较结果
在实验中我们将训练样本分为两部分,一部分作为训练阶段的训练样本,另一部分作为训练阶段的测试样本;测试阶段则采用原始的训练样本和测试样本。通过多次实验,我们发现:训练阶段的训练样本和测试样本的比例不同,得到的分类结果也会不同。实验过程中,我们把训练阶段的训练样本和测试样本的比例分别设为9/1、3/1、1/1、4/1,通过实验发现75/25的比例获得的效果最佳,因此上面我们采用了3/1的比例。
3 结束语
本文提出一种基于同步特征加权和特征选择的KNN分类器,并利用医学数据进行了实验验证。实验结果表明与现有的特征选择方法相比,该方法使得分类准确率得到了提高,并且缩短了程序运行的时间。当然,由于禁忌搜索本身的一些特点,本方法也存在一些不足,比如为了利用禁忌算法获得最优解,就需要设定充分的循环次数,不可避免地要耗费时间资源。另外,由于本文的方法会涉及到一些参数,例如K值的范围、权值的范围、禁忌循环的次数、目标函数值Cost的初始值、禁忌长度等,这些参数都需要人工来设定,这样就不可避免地会引起因参数设定不当而对分类效果带来的负面影响。由于本方法使用了不同的距离度量来组合KNN分类器,而距离度量的个数是有限的,因此对多路分类的效果不是太理想。基于以上不足,以后将对以下地方进行改进:(1)进一步改进禁忌算法,降低其带来的时间代价;(2)研究解决参数设定问题。
[1] 张永宏, 曹健, 王丽华. 一种解决人脸识别误匹配灾难问题的方法[J]. 计算机应用与软件, 2014, 31(9): 177-180.
[2] 杨志华. 一种基于纹理识别的手写数字识别方法[J].计算机工程与应用, 2008, 44(13): 27-29.
[3] 郭华平,袁俊红,张帆等. 一种新的组合分类器学习方法[J].计算机科学, 2014, 41(7): 283-289.
[4] Y. Bao and N. Ishii and X. Du. Cobmining Multiple k-Nearest Neighbor Classifiers Using Different Distance Functions [C]. 5th International Conference on Intelligent Data Engineering and Automated Learning, 2004: 634-641.
[5] S.D.Bay. Combining Nearest Neighbor Classifiers Through Multiple Feature Subsets[C]. Proceedings of the Fifteenth International Conference on Machine Learning, 1998: 37-45.
[6] Zhang, H., Sun, G.. Feature selection using Tabu Search method [J]. Pattern Recognition, 2002, 35(3): 701-711.
[7] 冶晓隆, 兰巨龙, 郭通. 基于主成分分析禁忌搜索和决策树分类的异常流量检测方法[J].计算机应用,2013, 33(10): 2846-2850.
[8] 张昊, 陶然, 李志勇, 蔡镇河. 基于KNN算法及禁忌搜索算法的特征选择方法在入侵检测中的应用研究[J]. 电子学报, 2009, 37(7): 1628-1632.
[9] Muhammad Atif Tahir,James Smith. Improving Nearest Neighbor Classifier using Tabu Search and EnsembleDistance Metrics[C]. Proceedings of the Sixth International Conference on Data Mining (ICDM'06), 2006: 1086 - 1090.
[10] 陈振洲, 李磊, 姚正安. 基于SVM的特征加权KNN 算法[J].中山大学学报(自然科学版), 2005, 44(1):17-20.
[11] Muhammad Atif Tahir, Ahmed Bouridane, Fatih Kurugollu. Simultaneous feature selection and feature weighting using Hybrid Tabu Search/K-nearest neighbor classifier [J]. Pattern Recognition Letters, 2007, 28(4):438-446.
责任编辑:刘海涛
TP391
A
1673-1794(2016)05-0061-04
胡天寒,皖南医学院公共基础学院实验师,硕士;叶明全,皖南医学院公共基础学院教授;张浩,卢小杰,皖南医学院公共基础学院教师(安徽 芜湖 241002)。
国家自然科学基金面上项目(61672386);安徽省高校省级自然科学研究重点项目资助 (KJ2014A266);皖南医学院博士启动基金项目(WK2014RC01)
2016-01-06
