基于Kinect的人脸表情捕捉及动画模拟系统研究
2016-11-29何钦政王运巧
何钦政, 王运巧
(北京航空航天大学机械工程及自动化学院,北京 100083)
基于Kinect的人脸表情捕捉及动画模拟系统研究
何钦政, 王运巧
(北京航空航天大学机械工程及自动化学院,北京 100083)
三维人脸表情动画技术是一个具有巨大应用前景和研究意义的学科方向。在研究现有表情捕捉和动画合成技术的基础上,提出了一种基于Microsoft Kinect设备的人脸表情动画系统。该系统首先利用Kinect设备捕捉人脸并提取相关表情参数,同时利用Autodesk Maya动画软件建立对应的人脸三维模型,之后将模型导入到OGRE动画引擎并把提取的表情参数传递给OGRE,渲染生成实时人脸表情动画。实验结果表明该技术方案可行,实时表情动画效果达到实际应用水平,相比于现有其他表情动画技术,系统采用通用的Kinect设备,成本更大众化且更容易进行操作。
Kinect;表情捕捉;人脸动画;Maya;OGRE
自20世纪70年代以来,对于人脸表情动画模拟技术的研究发展非常迅速,从最初的简单动画片到现在的好莱坞科幻大片,人脸表情动画越来越丰富,模拟的精度与逼真度也越来越高。随着计算机图形学的发展和动画产业的进步,人脸表情动画模拟技术的研究也逐渐成为了计算机图形学研究领域的一大热门。
人脸表情动画是指通过在计算机中预先设定一些规则,让计算机生成的动画中人脸图像从一种表情状态变为另一种表情的过程,模拟现实中人的表情变化。人脸表情动画的目的是利用动画中人脸的姿态和面部运动来形象生动地表达某个角色的表情和情感,让人机交互更加自然与人性化。
到目前为止,人脸表情动画模拟技术主要可以分为 2大类:①基于几何模型处理方法的人脸表情动画模拟技术,这也是最常使用的一类技术。Parke[1]提出的利用形状插值模型进行动画模拟、Pandzic和Forchheimer[2]提出的基于MPEG-4的标准人脸动画参数模型来进行动画模拟以及 Ekman 和 Friesen[3]提出的利用基于肌肉模型的人脸动作编码系统(facial action coding system,FACS)进行动画模拟都是属于这种技术。这种技术基本上都是先把人脸表情分成若干个动作单元,然后对每个表情分解成这些动作单元的线性组合,最后利用动画中的关键帧技术,把一些关键的人脸表情用动作单元组合形成,其余的画面根据插值算法自动生成,从而形成动画。②基于图像处理方法的人脸表情动画模拟技术。Oka等[4]提出的纹理映射系统以及Seitz和Dyer[5]提出的视图变换都属于这种技术。这种技术目前使用的比较少,得到的动画效果也不如第一类技术。
人脸表情动画模拟技术在电影制作、动画视频制作、刑讯监控、计算机多媒体教学、医疗研究等众多方面都有着巨大的市场应用需求,目前人脸表情动画最主要的应用在于各种影视中虚拟人物表情效果的制作,比如电影《阿凡达》中主人公各种惟妙惟肖的表情。这些高端专业应用价格往往极为昂贵,远离大众娱乐需求,而随着计算机软硬件的发展,基于非专业普通设备及需求的人脸表情动画模拟技术进入研究人员的领域,本文提出的模拟技术及应用系统正是针对这方面的研究。
(1) Microsoft Kinect。本文中用到的数据采集设备Microsoft Kinect是微软公司推出的一款三维摄像机,Kinect可以获得原始彩色图像、深度图像、红外图像以及音频数据流,主要具有身份识别、动作追踪、彩图识别、声音辨识等功能,不仅能用于游戏,还能应用在医疗、教育、三维人体建模等领域[6]。Kinect在工作时的关键硬件包括:
① 3个镜头:彩色摄影头,主要用来收集彩色RGB图像;红外投影机,用来发射红外光谱;红外摄像头,用来接收并分析红外光谱,采集深度数据(场景中物体到摄像头的距离),创建可视范围内的深度图像。
②麦克风阵列:Kinect内部包括4个同时收集声音的阵列式麦克风,然后比对后消除杂音,并通过其采集声音可以进行语音识别和声源定位。
③仰角马达:可以通过编程来控制角度的马达,用来得到所需最佳场景视角。不过,这个马达只能水平转动,不能支持垂直方向的转动。
2014年7月,微软发布了第二代Kinect for Window s,在水平和垂直方向上具有了更宽阔的深度和彩色视野,可以获得1 080 p全高清彩色图像,在声音、彩色、深度和骨骼数据方面的也有提升,还增加了更多的手势。本文采用第二代Kinect for Windows设备,其采集的RGBD图像如图1所示。

图1 Kinect设备及采集的RGBD图像
(2) 三维人脸造型技术。利用计算机构造出一个具有真实感的人脸模型是制作人脸表情动画的前提,人脸本身的复杂性以及表情动画过程中人脸模型的变形可决定建模工作的难度。在进行特定的人脸建模过程中,应该根据不同的需要采用不同的建模方法,才能取得更好的效果。
首先需要考虑的是人脸三维模型的表示方法,目前常用的表示方法包括2种[7]:①单曲面模型,这种方法常用三角网格面来表示,也有用NURBS或四边形网格表示的。②层次模型,这种模型以根据人脸生理组织而建立的物理肌肉模型为主。这 2种表示方法对于不同的需求,有其自己的优缺点。单曲面模型表示法比较简单、易于渲染但模型的真实感及表情控制效果都不如层次模型好。
其次须考虑的是人脸建模过程。常用的有 2种方法:①利用普通人脸模型修改得到特定人脸造型。这种方法是利用预先建立的一个可以称之为大众脸的普通人脸模型,定义一系列的特征点,根据采集到的特定人脸图像以及定义的一种算法规则来交互式的修改这些特征点,从而建立特定人物的人脸模型。②根据拍摄的图像序列或视频序列直接进行特定人脸的建模。这种方法是通过一系列从不同角度拍摄的特定人脸的图像或者是视频,利用三维重建的思想在一个二维的人脸网格上计算出各点的深度信息,然后直接利用一些建模软件得到特定人物的人脸模型。
(3) 基于 Kinect的人脸表情捕捉及动画模拟流程。基于 Kinect的人脸表情捕捉及动画模拟系统的基本过程设想如下:利用 Kinect设备捕捉表演者的脸部,采集并优化脸部数据,提取相关表情参数;利用Autodesk Maya动画软件建立对应的人脸三维模型,将建立好的模型以及提取的表情参数拟合并导入到OGRE动画引擎,在OGRE中渲染生成实时人脸表情模拟动画,如图2所示。
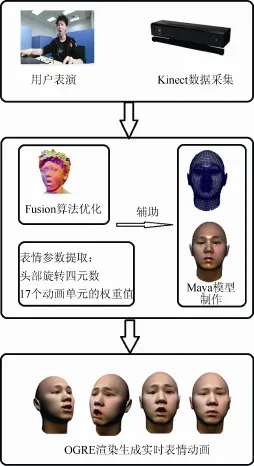
图2 系统流程图
1 面部表情捕捉与表情参数提取
1.1 Kinect数据采集
使用第二代的Kinect for Windows作为表情捕捉设备,可以得到的原始数据包括 1920×1080的高清RGB图像以及对应可视范围内的深度图像。数据以每秒30帧的速率刷新,得到不同时刻的人脸表情变化图像序列,进行实时面部表情捕捉。开发人员可以通过 Microsoft Kinect for Windows SDK 2.0中提供的接口获取需要的数据以供其他应用程序使用。
Kinect作为一种新型的数据采集设备,使用Kinect的优势包括:Kinect设备本身价格低廉,尺寸也比较小,方便使用,对于环境的要求低;Kinect提供额外的三维深度图像,使得人脸数据采集和表情参数提取更加方便与准确。另外,相比于传统需要穿戴特定物理设备或使用脸部标记点的表情捕捉方法,使用 Kinect可以非侵入式的进行数据采集。不过,由于第二代Kinect for Windows本身设备的限制,对开发电脑的配置要求相对较高。
实验过程中,表演者需站在或坐在设置调整好参数的 Kinect摄像头的前面,表演不同的表情状态,即可实现表情数据的自动捕捉。
1.2 Kinect Fusion算法进行数据优化
正常情况下,Kinect采集得到的深度数据只是单一角度的二维视图,而且捕捉到的数据会带有很多的噪点,这对后续的数据处理带来不便。所以为了减少噪点,本文采用 Kinect Fusion算法[8]将从对象的不同角度得到的深度数据聚合生成一个全局的表面模型,经过Fusion算法处理得到某一特定帧的光滑、精细的深度图像,如图3所示。另外,在 Kinect前面的表演者通过轻微的转动头部,加上Kinect Fusion算法的计算就可以得到表演者头部的三维信息,这些数据可以用于Maya三维模型的制作过程。

图3 采集的RGBD图像和Fusion处理后的面部图像
1.3 表情参数提取
Kinect拍摄得到了1 080 p高清RGB图像和深度图像之后,通过对 Kinect深度图像数据的处理和分析,可以实现对人脸的识别、跟踪和表情参数的提取。
在第二代的Kinect For Windows中,也具有对人脸进行跟踪和分析的算法,这种算法的核心是先用基于 Adaboost的人脸检测算法进行人脸检测,再利用AAM算法进行人脸识别与跟踪[9]。
通过对人脸进行跟踪与分析,利用参数计算载体模型来计算需要的表情参数,即:

其中,F为所有的顶点向量构成的整个模型的矩阵,F0为标准模型矩阵,S为形状单元,A为动画单元。R、t分别为人脸的旋转变换参数和位移变换参数,β、α分别为人脸的静态和动态控制参数。
将 Kinect得到的三维深度数据点与载体模型中的点进行配准,在配准过程中利用对能量项的不断迭代最小化就可以计算出所需要的 R、t、β 和α。最终通过转化可以获得头部旋转四元数以及17个动画单元的权重值,其中的这17个动画单元具有很强的表情代表性,组合起来可以实现几乎所有的人类表情,而这些权重值在–1到1范围之内,表征此时人脸表情中各个动画单元的比例,组合每一个动画单元及其对应的权重值,可以形成某一个特定的表情。
假如使用B=[b0,b1,b2,··,b17]来表示这17个动画单元,那么任何一个捕捉到的用户表情都可以用下面的公式表示:

其中,b0为自然表情,ΔB=[b1−b0,b2−b0,…,b1−b0],x为对应的动作单元权重值。
头部旋转四元数可以转换为以欧拉角表示的Yaw、Pitch和Roll,3个数据可以被OGRE直接使用来模拟头部的运动情况。
由于Kinect以每秒30帧的速度采集数据,所以每次刷新 Kinect数据时,都可以获取到此刻的表情参数,把这些表情参数传递给OGRE中的相关方法,就可以实现表情动画的合成与渲染。
2 动画模拟
在 Kinect采集到表演者的面部数据,利用Fusion算法优化数据并提取出所需要的表情参数之后,还需要建立人脸三维模型,才能在 OGRE中实现实时的人脸表情动画模拟,这里采用Autodesk M aya建模软件建立三维模型。
2.1 Maya模型建立与Blendshape重构
为了建立在动画渲染过程中使用的三维人脸模型,采用了 Maya2013建模软件。Maya是Autodesk公司的一款三维动画制作软件,提供了优秀的 3D 建模、动画、特效和高效的渲染功能,经常被用于各种三维建模、游戏角色动画和电影特效渲染中。
首先是对自然表情的人脸模型进行建模,可以利用在Fusion算法中得到的表演者头部三维数据信息来辅助建立,以提高三维模型的质量,之后再附上贴图材质就可以得到真实感模型。
建立好了自然表情的三维模型之后,对应于17个动画单元也需要分别建立一个3D模型,如图4所示,然后利用Maya中的创建Blendshape动画功能将每一个动作单元对应的表情模型作为一个Blendshape,保存并导出为以.mesh为后缀格式的文件,就可以进行下一步动画制作。

图4 Maya建立的人头模型
2.2 OGRE引擎驱动动画
OGRE是一款面向对象的开源3D图形渲染引擎,其按照自己的规则对比较底层的图形系统库OpenGL和Direct3D进行了抽象和封装,为用户开发提供了方便;同时,也支持很多平台下的开发,当然也包括Windows平台。OGRE由许多功能模块组成,不仅能渲染各种静态场景,还能渲染粒子系统、骨骼动画和脸部表情动画,所以也经常被用于各种应用程序和游戏中。
Maya建立好的三维模型可以直接被OGRE所识别并使用。这样,利用OGRE中的类及接口,结合Windows平台下的VS2010开发环境,就可以编写相应的代码来渲染模型动画。如图5所示,将包含一个自然表情和17个基础动画单元的mesh文件导入到OGRE,这里显示了其中3个基础动画单元状态。

图5 Maya模型导入OGRE中
本文使用的是OGRE顶点动画中的姿势动画,主要调用OGRE SDK中的API函数来实现动画功能,具体流程如下:
(1) 调用OgreMeshManager类中的load方法加载Maya导出的.mesh格式3D模型;
(2) 调用createAnimation方法创建动画;
(3) 调用createVertexTrack方法创建顶点轨迹跟踪;
(4) 调用createVertexPoseKeyFrame方法创建顶点姿势关键帧;
(5) 调用 addPoseReference方法把这 17个Blendshape导入作为OGRE姿势动画的参考Pose;
(6) 调用 updatePoseReference方法更新关键帧的姿势;
(7) 调用 getParent()->_notifyDirty()方法来通知系统更新动画显示。
当每次 Kinect数据刷新时,会得到关于这每一个Blendshape的权重值,把权重值赋给OGRE中对应的Pose,组合这些Pose就能够得到该特定时刻的表情,从而实时模仿出表演者此时的表情状态,随着每一帧数据的到来,就形成了表情动画。
此外,把Kinect获取到此时的头部旋转四元数转化为 Yaw,Pitch 和 Roll,然后调用SetYaw PitchDist方法设置摄像机的位置,可以模仿头部运动的效果。
3 实验结果与分析
本次实验利用的设备环境包括:第二代Microsoft Kinect For Windows一台、笔记本电脑一台(CPU:Intel Core i7-4710HQ,显卡:NVIDIA GeForce GTX 850 M,8 G内存,Windows 8操作系统)。
在实验过程中,首先对整个系统能否实现所需功能,得到最终的表情动画进行了测试。然后为了验证该系统在表情捕捉方面的实际应用能力,在实验中还分析了系统对与光照环境条件、驱动距离等参数的需求影响,结果表明此次研究提出的利用Kinect来进行表情捕捉具有一定的可行性,开发的系统也具有较强的鲁棒性。
图 6为实验过程中表演者几个不同的表情和系统在OGRE人脸动画中驱动得到的对应动画模拟结果截图。实验结果表明,按照本文给出的整个系统流程,可以得到所需要的功能,实现对表演者的表情捕捉和实时的动画模拟,系统最终能够输出展示效果不错的虚拟角色表情动画。

图6 用户实时表情动画模拟结果
如图7所示,通过对表演者与Kinect不同距离下的人脸表情捕捉精度实验结果分析,人与Kinect设备之间最佳距离在 1 m 左右。而经过Fusion优化之后得到的人脸表情效果相比于直接利用深度图的表情效果也有很大的提升,所以利用Fusion算法进行优化是必要的。

图7 人与Kinect的距离对表情捕捉精度的影响,以及是否对深度图像进行Fusion处理对结果的影响
如图 8所示,为了验证系统对于光照环境变化的适应能力,在不同光照环境下做了实验分析,结果表明系统在不同光照环境下对于人脸的捕捉和提取的表情参数没有明显的差距,因此系统对于光照环境没有特殊的要求,具有广泛的适应能力。
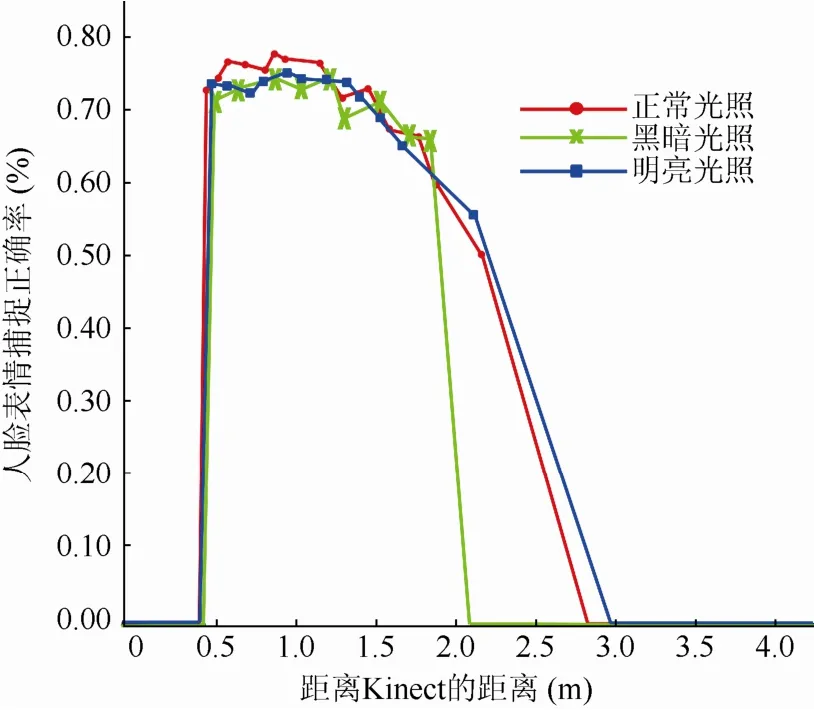
图8 光照条件对表情捕捉精度的影响
综合所有实验结果可以发现,得到的虚拟角色表情与真实表演者的表情基本一致,达到了表情动画的实际应用水平,同时具有一定的实用性,可以用在大部分的虚拟现实场景中。但是系统本身的限制导致了一定误差的存在,其误差主要来源于Kinect本身,到目前为止,Kinect主要还是被用于人肢体和骨骼运动的捕捉,对于人的脸部在 Kinect图像数据中只占有很小像素的一部分,所以对于面部表情的捕捉在精度上还不够优秀。同时,系统中人脸表情捕捉的速度为每秒24帧,在OGRE中显示的虚拟人物表情相比于表演者会有大概0.1 s的延迟,虽然实时性不是特别完美,但这还是在可以接受的范围之内,这一问题也可以在进一步的研究中寻找优化解决方法。
4 总结与下一步研究
本文对基于 Kinect的人脸表情捕捉与动画模拟方法进行了研究,给出了此次研究的思路与流程,首先利用 Kinect进行表情捕捉,优化采集的面部数据并提取所需要的表情参数,然后利用Maya进行三维模型制作并在OGRE驱动引擎中实现表情模拟动画的渲染,最后对总体方案进行了实验验证。实验结果表明本文提出的方法可以取得不错的效果,达到了动画的基本要求,同时本文提出的利用 Kinect来捕捉人脸表情,不需要前期的训练学习与校准,这种简单高效的捕捉方法以及廉价的捕捉设备,也使得本文提出的方法易于用在各种娱乐游戏或虚拟现实的应用中,具有一定的实用性。下一步的研究将从动画的实时性和精度着手,优化算法来得到更好的效果。
[1] Parke F I. Computer generated animation of faces [C]// ACM National Conference. ACM’72 Proceedings of the ACM Annual Conference-Volume 1. New York: ACM Press, 1972: 451-457.
[2] Pandzic I S, Forchheimer R. MPEG-4 facial animation: the standard, implementations and applications [M]. New York: John Wiley & Sons, 2003: 1-328.
[3] Ekman P, Friesen W V. Facial action coding system: a technique for the measurement of facial movement [M]. Palo A lto: Consulting Psychologists, 1978: 38-43.
[4] Oka M, Tsutsui K, Ohba A, et al. Real-time manipulation of texture-mapped surface [C]//ACM SIGGRAPH Computer Graphics. SIGGRAPH’87 Proceedings of the 14th Annual Conference on Computer Graphics and Interactive Techniques. New York: ACM Press, 1987: 181-188.
[5] Seitz S M, Dyer C R. View morphing [C]//ACM SIGGRAPH Computer Graphics. SIGGRAPH’96 Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques. New York: ACM Press, 1996: 21-30.
[6] 石曼银. Kinect技术与工作原理的研究[J]. 哈尔滨师范大学自然科学学报, 2013, 29(3): 83-86.
[7] 邹北骥. 人脸造型与面部表情动画技术研究[D]. 长沙: 湖南大学, 2001.
[8] Izadi S, Kim D, Hilliges O, et al. Kinect fusion: real-time 3D reconstruction and interaction using a moving depth camera [C]//UIST’11 Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology. New York: ACM Press, 2011: 559-568.
[9] Cao Z M, Yin Q, Tang X O, et al. Face recognition with learning-based descriptor [C]//Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2010: 2707-2714.
Research on System of Facial Expression Capture and Animation Simulation Based on Kinect
He Qinzheng, Wang Yunqiao
(School of Mechanical Engineering and Automation, Beihang University, Beijing 100083, China)
The technical of 3D human facial expression animation is a subject which has potential application and fatal research significance. This paper proposes a facial expression animation solution based on Microsoft Kinect device after the research of existing facial expression capture technology and animation synthesis technology. First, Kinect device is used to capture the face data and relevant expression parameters are extracted, at the same time, a three-dimensional model of face is reconstructed with Autodesk Maya animation software. Then the model is imported to OGRE animation engine and the expression parameters transferred to OGRE in which real time facial expression animation is rendered at last. Experiment results show that the method can provide an acceptable and reliable real-time facial expression animation. Compared to other existing facial expression animation technologies, the system is easier to operate with rather inexpensive device.
Kinect; expression capture; facial animation; Maya; OGRE
TP 391
10.11996/JG.j.2095-302X.2016030290
A
2095-302X(2016)03-0290-06
2015-07-08;定稿日期:2015-10-14
何钦政(1993–),男,江西乐平人,硕士研究生。主要研究方向为计算机图形学。E-mail:574332581@qq.com
