基于受限非负张量分解的用户社会影响力分析
2016-10-13魏晶晶陈畅廖祥文陈国龙程学旗
魏晶晶,陈畅,廖祥文,陈国龙,程学旗
基于受限非负张量分解的用户社会影响力分析
魏晶晶1,2,陈畅3,4,廖祥文3,4,陈国龙3,4,程学旗5
(1. 福州大学物理与信息工程学院,福建福州350116;2. 福建江夏学院电子信息科学学院,福建福州 350108;3. 福州大学数学与计算机科学学院,福建福州350116;4. 福州大学福建省网络计算与智能信息处理重点实验室,福建福州350116;5. 中国科学院计算技术研究所,北京100086)
针对传统社会影响力分析方法未能充分考虑观点和话题信息等问题,提出了一种基于受限非负张量分解的用户社会影响力分析方法。首先把社交媒介用户相互评论关系自然地表示成三阶张量,然后通过拉普拉斯话题约束矩阵控制张量分解过程,最后根据分解得到的潜在因子度量用户观点社会影响力。该方法的优点是能有效地从受限张量分解结果中检索出给定话题下用户的社会影响力,同时保持其社会影响力的极性分布。实验结果表明,该方法的性能优于OOLAM和TwitterRank等基准算法。
社会影响力;话题;观点;张量分析
1 引言
社会影响力是指一个人的思想、情感或行为被他人所影响的现象[1,2],其作为一种影响网络结构和信息传播的重要因素,受到了许多研究者的关注。社会影响力分析往往通过分析人们的社会交互行为来研究人们的社会影响,并在多个研究领域中起到关键作用,如推荐系统[3]、社交网络信息传播[4,5]、突发事件检测[6]和广告投放[7]等。
在线社交网络出现和兴起之前,针对社会影响力的研究工作主要集中在理论层面,包括二级传播理论、弱连带优势理论、强连带优势理论和结构洞理论等[8]。随着微博、Facebook等社交媒体广泛使用,人们可以在社交媒介上随时随地发布信息,而不受时间和空间的限制。这些海量的用户自创造数据(user generated data)蕴含非常丰富的用户信息,如用户观点、用户间交互关系等,为社会影响力分析理论的验证与应用提供了理想的环境。从内容角度,社会影响力分析可分为3方面[9]:1) 社会影响力自身的识别,研究影响力和相关因素的联系;2) 社会影响力的度量,希望能够找到合适的度量社会影响力的方法;3) 社会影响力的动态传播,即刻画社会影响力的动态特性。社会影响力的度量方法主要有4个角度[9]:1)基于网络拓扑结构的度量,通过衡量网络图中节点与连接的重要性来体现社会影响力的大小;2)基于用户行为的度量,使用统计等方法分析用户在社交网络中留下的行为数据;3)基于用户交互信息的度量,主要包括基于交互信息内容的度量和基于话题的度量;4)基于时间因素、转移熵等其他度量。
从层次角度,社交影响力分析主要有以下3个层次。1)整体社交影响力分析,毛佳昕等[8]提出用户关注、微博转发这2种用户行为与时间维度有关,以及转发延迟的分布近似服从幂律分布2个假设,并通过假设检验验证,最后使用全局阅读期望的方法度量用户影响力。2)话题级社交影响力分析,Weng等[10]提出了一种结合网络结构与话题信息来计算话题级社会影响力的方法,验证了话题相似的用户间更容易互相产生影响。据此,在PageRank基础上加入话题相似度的因素,提出了一种TwitterRank方法并取得了不错的效果。3)信息条目级社交影响力分析:Cui等[1,2]提出了一种更细粒度的社交影响力度量思路,即信息条目级社会影响力度量。其使用受限非负矩阵分解的方法来预测用户在某一话题下的社会影响力大小,矩阵约束的部分考虑了用户朋友活跃度、用户与朋友关系强度以及话题信息,该方法的实验效果较好。
当前,细粒度的社会影响力分析更加引起了研究者的重视,用户观点已成为度量用户社会影响力不可忽视的因素。另一方面,用户社会影响力与话题密切相关。Cai等[11]曾提出利用带有倾向性连接的网络度量用户的社会影响力,并提出了一种可并行化的PageRank改进方法来求解所提出的OOLAM模型,得到2个独立的用户正负面影响力评分,从而更加细致地刻画了社会影响力。然而,该方法不能很好地融入用户的话题信息,难以分析领域专家的社会影响力。Weng等[10]提出的TwitterRank方法将话题信息融入到用户社会影响力分析中,能够有效地检索出给定话题下比较重要的用户,但是却不能反映出用户社会影响力的正负面倾向。导致这一局限性的根本原因在于基于图的方法主要是刻画二维数据,难以同时将不同的信息加入到分析过程中。张量[12]是一种特别适合表达多维数据、融合不同信息的数据表达方式,广泛应用于多模态特征融合相关研究。
因此,本文提出一种基于受限非负张量分解的用户观点社会影响力分析方法,度量特定话题下用户的社会影响力及其影响力的极性分布。该方法首先使用张量表示用户相互评论关系,然后通过Laplacian矩阵将话题信息融入到张量分解中,最后基于分解得到的潜在因子度量在特定话题下用户观点的社会影响力。通过实验表明,本文方法不仅在效果上比OOLAM、TwitterRank等方法有一定的提升,而且能够更加细致地刻画用户观点的社会影响力。
2 用户观点社会影响力估计模型
2.1 问题描述
2.2 张量代数介绍
遵循Kolda和Bader的符号描述,简要介绍与本文工作相关的张量代数基本知识[12]。

(2)

2.3 基于受限非负张量分解的用户观点社会影响力分析方法
在应用的驱动下,越来越多研究工作关注话题级或条目级等更加细致的用户社会影响力分析。本文所关注的问题是分析特定话题下用户观点的社会影响力和极性分布。通过观察,本文发现:1)与话题相关度高的用户往往越容易获得其他用户的评论,其收到的评论总量一般会高出与话题无关的用户;2)话题相关的用户所发布的文档往往采用分布类似的词来描述话题。基于用户话题相似性特征,本文提出了一种基于受限非负张量的方法。该方法首先利用张量自然地对用户之间的评论关系建模,然后通过加入用户话题相似矩阵控制张量分解过程,最后基于张量分解得到的潜在因子度量用户观点的社会影响力和观点极性分布。
2.3.1 基于用户评论关系的张量构建
用户与用户之间带有观点评论的三元关系,可以用一个三阶张量刻画用户间的评论行为。其中,张量的1模式表示被评论用户,2模式表示发表评论的用户,3模式表示评论的观点倾向性,倾向性分为正面、中性、负面3种情况。这里的模式对应张量的每一个维度。每个张量元素值为

需要说明的是,判定用户u对用户u的评价观点,即观点倾向性的极性,是通过基于情感词典[13]的判定方法获得的。若评价内容中正面情感词数大于负面情感词数,则记为一次正面观点的评价,若评价内容中正面情感词数等于负面情感词数,则记为一次中性观点的评价,否则记为一次负面观点的评价。
2.3.2 用户话题相似性计算

(6)
2.3.3 改进的受限非负张量分解方法
针对评论关系张量,根据用户话题相似性假设,提出一种CP(CANDECOMP/PARAFAC)分解算法CP_ALS[14]的改进算法HF-CP-ALS,并通过该算法分解得到刻画用户观点社会影响力的潜在因子矩阵。
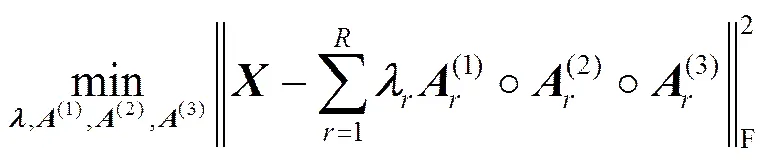
为求解目标函数式(7),先求解在CP_ALS算法中的1模式最优化目标函数为

在CP_ALS算法1模式的最优化目标函数中加入用户话题相似性限制,从而获得限定话题下的用户观点社会影响力。在该约束下,话题相关而且影响力小的那些用户,其用户观点社会影响力将提升,对于那些话题无关而且影响力大的用户,其用户观点社会影响力将减小。此外,为了保证潜在因子的可解释性,引入的约束,得到

(9)
直接求解式(9)所描述的优化问题时间复杂度过高,为简化运算引入拉普拉斯矩阵[15]=−,。是一个对角矩阵,。由于近似为对角占优矩阵,因此用近似,可以得到

(10)
引入拉普拉斯矩阵后,待优化的目标函数可以写成如下形式

(11)
张量分解中解决该类型的优化问题常用交替最小二乘法(ALS)求解目标函数,即更新其中一个因子矩阵时固定另外2个因子矩阵。表示限制项的重要程度,因此先计算对的微分

(12)

(14)
至此已经得到了3个潜在因子矩阵的更新规则,加入非负性约束后可以得到算法HF-CP-ALS,其伪代码如图3所示。

Procedure HF-CP-ALS(X,D,R) 初始化 Repeat单位化的每一列,将中小于0的值置零,更新λ单位化的每一列,将中小于0的值置零,更新λ单位化的每一列,将中小于0的值置零,更新λUntil收敛或达到最大迭代次数return λ,A(1),A (2),A (3)end procedure
在算法HF-CP-ALS中,值得注意的是在每一次更新因子矩阵完毕后,需要对矩阵做一次列向量单位化。特别地,潜在因子矩阵具有非负性约束,因此,在更新完(1)、(2)或(3)时还需将其中小于零的元素置为0,从而保持潜在因子矩阵非负,即保证潜在因子矩阵的可解释性。最后同时更新向量。HF-CP-ALS算法最终可以求得各个模式的潜在因子矩阵和向量。
2.3.4 用户观点社会影响力度量
用户观点的社会影响力往往由一系列潜在因子决定,可通过分析潜在特征矩阵计算得到[16,17]。通过算法HF-CP-ALS容易得到话题约束下的用户观点潜在因子:、和。设表示向量的长度,那么分解结果可以看成个秩为一的张量之和,其计算式可以写成


(17)
不难看出,式(17)就是利用张量分解结果估计原始张量,类似张量补全的工作。不同的是,加入了用户话题相似性约束。在该约束下,对于那些社会影响力大且与话题无关的用户,其影响力的量化数值将分享给大量话题无关且社会影响力小的用户。反映在最终分解结果中的就是在给定话题下,话题无关但是社会影响力大的用户的社会影响力得分将变得相对较小。同理,话题相关的用户将受到那些话题无关用户的影响很小,在张量分解过程中能够很好地保持这些数值的大小。在分解结果中,比起那些话题无关的用户,其用户观点社会影响力得分将变得相对较大,在最终用户观点社会影响力计算中取得较高的分值。因此,在用户相似性的约束下,本文方法最终能够从估计的张量中较好地选出那些话题相关且社会影响力大的用户。
3 实验结果及分析
3.1 数据描述
如表1所示,实验数据来自新浪微博,包括篮球、经济、法律、健康4个话题,共66 754个用户、282 748条微博。为了更加详尽地描述数据构成,图4统计了所有话题中拥有相同数量级粉丝数的目标用户分布。不难看出,粉丝数量和目标用户数量近似符合幂律分布(在对数—对数坐标下近似为一条直线)。因此该数据中的目标用户具有一定的代表性。

表1 实验数据描述
以篮球话题为例,数据内容包含2个部分:1) 用户间交互关系;2) 用户信息。其中,用户间交互关系可以使用三元组表示,其中,表示被评论用户,表示发表评论的用户,用户对用户进行了评论并且评论内容是,、和分别表示正面、负面和中性的评论内容。根据预先设定的话题“篮球”,通过新浪微博提供的搜索相关用户功能获取目标用户集合,剩余所需的数据则通过爬取新浪微博页面得到。目标用户将均与篮球相关,即曾发表过与篮球有关的微博,用户间的交互关系是从每个被评论用户各自发表的40条微博中获取的。由于评论量可能非常庞大,只选取每条微博的前30条评论关系。用户信息则包括用户发表过的微博内容,包括每个被评论用户最多200条的微博。
实验的关键是如何确定给定话题下用户观点的社会影响力排序。实验中确定该影响力排序列表的方法将结合用户与话题的相关性,由5位均参加过COAE2013-COAE2015、SIGHAN2015标注工作的标注者进行标注。提供给这5位标注者的数据包括:1)用户列表;2)用户主页地址,可以进入目标用户主页查看该用户的详细情况,包括粉丝数、评论量、职业、发表过的微博等。每位标注者根据这些数据,判断用户在给定话题下的社会影响力大小,然后选出、和的用户。如表2所示,5位标注者的指标在0.62以上,因此对用户观点社会影响力标注在一定程度上是可接受的。

表2 数据标注的Kappa指标
3.2 实验设计
实验环境为Matlab 2010,Intel(R) Pentium(R) CPU G645 2.90 GHz,8 GB内存。将基准方法与本文的方法应用在相同的数据集上,计算得到各个用户在给定话题下的社会影响力得分,即排序结果。最后,基于人工标注的社会影响力用户列表,比较各个方法在不同评价指标的性能优劣。参与实验的基准方法包括以下几方面。
1) CP:未添加本文约束的CP分解方法[14],从分解结果计算用户影响力的方法与本文相同。
2) CP+BM 25:将话题相关性BM 25结合CP分解方法,计算方法是在CP分解的结果上乘以BM 25话题相关性得分。
3) OOLAM[11]:OOLAM模型的计算结果是用户正面影响力和负面影响力2个得分,本文对比实验中取正负面影响力的均值作为用户社会影响力得分。
4) OOLAM+BM 25:由于OOLAM未考虑话题信息,本文对比实验中将用户话题相关性BM 25得分乘以OOLAM方法的结果作为用户社会影响力得分。
5) TwitterRank[10]:TwitterRank的计算结果是用户在特定话题下的重要程度得分,本文实验直接使用该得分作为用户社会影响力得分。
6) TR+RA:由于TwitterRank未考虑用户间评论的交互关系。因此在对比实验中,将用户受到评论的数量乘以TwitterRank的结果作为用户影响力得分。
3.2.1 评价指标
本文所采用的评价指标有以下3个指标。
1) 排序精度指标

2) 张量分解精度指标

3) 相关性评价指标
使用Pearson相关系数来评价本文方法计算的用户社会影响力极性分布与用户真实的社会影响力极性分布的相关强度。计算式如下

其中,和表示需要度量相关性的2个向量,表示这2个向量的长度,和表示均值。实验中,取每个被评价用户收到的正面、中性、负面评价数量作为用户真实的社会影响力极性分布,对这3个方面的评价数量做归一化得到的取值。而的取值就是本文方法对用户社会影响力极性分布的估计值。最后取所有用户的,计算均值作为评价本文方法反映用户社会影响力极性分布性能的指标。
3.2.2 实验结果分析
1) 参数确定
2) 用户社会影响力排序精度比较

表3 本文的方法与基准方法对比实验结果
3) 用户社会影响力极性特征
为了评价本文方法刻画用户社会影响力极性分布的性能,以用户正面、负面和中性的评论分布作为用户真实的社会影响力极性分布,分别计算每个用户真实社会影响力极性分布与预测结果的Pearson相关性得到均值,结果如表4所示。篮球、经济、法律和健康这4个话题的Pearson 相关系数值均大于0.70,具有强相关性。因此本文的方法能够较好地反映用户社会影响力的极性分布。

表4 话题的Pearson相关系数值
根据实验结果,选出一位具有代表性的用户,将其倾向性分布绘图,结果如图6所示。该用户的正面社会影响力占主导,可以理解为其他用户对他的反映往往是积极的。不难发现,在本文提出的方法中,借助于用户社会影响力极性分布,可以更加全面的分析用户的社会影响,进而为推荐系统、社交网络信息传播、突发事件检测和广告投放等应用提供更为细致的参考数据。
4 结束语
本文提出了一种在给定查询话题下融合用户观点的用户社会影响力分析模型,提出了一种受限的CANDECOMP/PARAFAC(CP)分解方法并应用于社会影响力分析。首先,在CP分解中加入用户相似性约束,为保证张量分解结果中因子矩阵的可解释性又加入了潜在因子非负约束。其次,为解决受约束的CP分解,设计了一种CP_ALS的改进算法HF-CP-ALS求解本文的模型。最后,通过分析潜在因子评定用户的社会影响力得分,并可以根据张量评论倾向性维度的潜在因子得到用户社会影响力的极性分布,在用户社会影响力的分析上提供了更加详尽的刻画。在与基准方法的对比实验中,本文提出的方法表现出了较好的性能。
[1] CUI P, WANG F, YANG S, et al. Item-level social influence prediction with probabilistic hybrid factor matrix factorization[C]//AAAI. c2011: 331-336.
[2] CUI P, WANG F, LIU S, et al. Who should share what?: item-level social influence prediction for users and posts ranking[C]//The 34th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, c2011:185-194.
[3] RASHID A M, KARYPIS G, RIEDL J. Influence in ratings-based recommender systems: an algorithm- independent approach[C]//The SIAM International Conference on Data Mining. c2005:556-560.
[4] BAKSHY E, HOFMAN J M, MASON W A, et al. Everyone's an influencer: quantifying influence on Twitter[C]//The fourth ACM International Conference on Web Search and Data Mining. ACM, c2011: 65-74.
[5] YANG J, LESKOVEC J. Modeling information diffusion in implicit networks[C]//2010 IEEE 10th International Conference on Data Mining (ICDM). IEEE, c2010: 599-608.
[6] SAKAKI T, OKAZAKI M, MATSUO Y. Earthquake shakes Twitter users: real-time event detection by social sensors[C]//The 19th International Conference on World Wide Web. ACM, c2010: 851-860.
[7] BAKSHY E, ECKLES D, YAN R, et al. Social influence in social advertising: evidence from field experiments[C]//The 13th ACM Conference on Electronic Commerce. ACM, c2012: 146-161.
[8] 毛佳昕, 刘奕群, 张敏, 等. 基于用户行为的微博用户社会影响力分析[J]. 计算机学报, 2014, 37(4): 791-800.
MAO J X, LIU Y Q, ZHANF M, et al. Social influence analysis for micro-blog user based on user behavior[J]. Chinese Journal of Computers, 2014, 37(4): 791-800.
[9] 吴信东, 李毅, 李磊. 在线社交网络影响力分析[J]. 计算机学报, 2014, 37(4):735-752. WU X D, LI Y, LI L. Influence analysis of online social networks[J]. Chinese Journal of Computers, 2014, 37(4):735-752.
[10] WENG J, LIM E P, JIANG J, et al. Twitterrank: finding topic-sensitive influential twitterers[C]//The Third ACM International Conference on Web Search and Data Mining. ACM, c2010: 261-270.
[11] CAI K, BAO S, YANG Z, et al. OOLAM: an opinion oriented link analysis model for influence persona discovery[C]//The fourth ACM International Conference on Web Search and Data Mining. ACM, c2011: 645-654.
[12] KOLDA T G, BADER B W. Tensor decompositions and applications[J]. SIAM Review, 2009, 51(3): 455-500.
[13] DONG Z D, DONG Q.“ZhiHu”[EB/OL]. http://www.keenAge.com.
[14] CICHOCKI A, ZDUNEK R, PHAN A H, et al. Nonnegative matrix and tensor factorizations: applications to exploratory multi-way data analysis and blind source separation[M]. John Wiley & Sons, 2009:42-46.
[15] HU X, TANG L, TANG J, et al. Exploiting social relations for sentiment analysis in microblogging[C]//The Sixth ACM International Conference on Web Search and Data Mining. ACM, c2013: 537-546.
[16] DAVIDSON I, GILPIN S, WALKER P B. Behavioral event data and their analysis[J]. Data Mining and Knowledge Discovery, 2012, 25(3): 635-653.
[17] KOLDA T G, BADER B W, KENNY J P. Higher-order Web link analysis using multilinear algebra[C]//Fifth IEEE International Conference on Data Mining. IEEE, c2005: 242-249.
User social influence analysis based on constrained nonnegative tensor factorization
WEI Jing-jing1,2, CHEN Chang3,4, LIAO Xiang-wen3,4, CHEN Guo-long3,4, CHENG Xue-qi5
(1. College of Physics and Information Engineering, Fuzhou University, Fuzhou 350116, China; 2. College of Electronics and Information Science, Fujian Jiangxia University, Fuzhou 350108, China; 3. College of Mathematics and Computer Science, Fuzhou University, Fuzhou 350116, China; 4. Fujian Provincial Key Laboratory of Networking Computing and Intelligent Information Processing, Fuzhou University, Fuzhou 350116,China; 5. Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100086, China)
Existing models for measuring user social influence fail to integrate both opinion and topic information. Therefore, a new constrained nonnegative tensor factorization method combining user’s opinion and the topical relevance was proposed. The method represented user’s comment relations as 3-order tensor, factorized the comments tensor constrained by Laplacian topical matrix, and then measures user influence according to the latent factors resulting from the tensor factorization. Thus, the new method not only was capable to effectively calculate the strength of user social influence on given topic, but also kept the polarity allocation of social influence. The experimental result shows that the performance of the proposed method is better than that of the baseline methods such as OOLAM , TwitterRank, etc.
social influence, topic, opinion, tensor analysis
TP391
A
10.11959/j.issn.1000-436x.2016125
2015-05-22;
2016-01-30
廖祥文,liaoxw@fzu.edu.cn
国家自然科学基金资助项目(No.61300105);教育部博士点联合基金资助项目(No.2012351410010);福建省科技重大专项基金资助项目(No.2013H6012);福州市科技计划基金资助项目(No.2012-G-113, No.2013-PT-45)
The National Natural Science Foundation of China (No.61300105), The Research Fund for Doctoral Program of Higher Education of China (No.2012351410010), The Key Project of Science and Technology of Fujian (No.2013H6012), The Project of Science and Technology of Fuzhou (No.2012-G-113, No.2013-PT-45)
魏晶晶(1984-),女,福建平潭人,福州大学博士生,主要研究方向为网络文本观点挖掘。
陈畅(1991-),男,浙江江山人,福州大学硕士生,主要研究方向为社交网络、数据挖掘等。
廖祥文(1980-),男,福建泉州人,博士,福州大学副教授、硕士生导师,主要研究方向为Web信息检索与观点挖掘。
陈国龙(1965-),男,福建莆田人,博士,福州大学教授、博士生导师,主要研究方向为网络计算、智能信息处理等。
程学旗(1971-),男,安徽安庆人,博士,中国科学院计算技术研究所研究员、博士生导师,主要研究方向为网络科学与社会计算、互联网搜索与挖掘等。
