基于机器学习方法的强对流天气识别研究
2016-09-08修媛媛冯海磊
修媛媛,韩 雷,冯海磊
(中国海洋大学 信息科学与工程学院,山东 青岛 266100)
基于机器学习方法的强对流天气识别研究
修媛媛,韩 雷,冯海磊
(中国海洋大学 信息科学与工程学院,山东 青岛266100)
用机器学习中有监督学习模型支持向量机SVM来进行强对流天气的识别和预报。强对流天气的发生可以看作是小概率事件,因此强对流天气的预警问题可以作为不平衡数据分类问题来处理。在SVM的应用上结合判别准则来对不平衡数据进行处理,更好的对强对流天气进行预警。本文从数据的获取、训练算法的选择、算法的应用、实验结果的评估几个方面进行了详细的描述。通过采用丹佛地区的数据进行大量试验,排除了不平衡数据对分类的干扰,提高了强对流天气识别的准确度。
强对流天气预警;SVM;不平衡数据分类;机器学习
强对流天气[1]是常见的一种气象灾害,具有生命史短暂、发展移动速度快的特点,往往会给人民的工作生活带来不便,对农业生产、国家财产等造成威胁。多普勒雷达资料以其较高的时空分辨率在临近预报及天气预警方面具有独特的优势,气象业务上强对流天气预警主要依赖于雷达的实时监测[2]。NCAR(National Center for Atmospheric Research国家大气研究中心)研究出的多普勒雷达四维变分分析系统[3](The four-dimensional Variational Doppler Radar Analysis System,VDRAS)能够给出反映低层大气热动力特征的实时分析场,是强对流行天气临近预报的有力工具。
目前的气象临近预报方法[4]主要有概念模型预报[5]、数值模式预报[6]、外推法预报[7]等。概念模型预报技术主要是通过综合分析多种观测资料,包括常规探测资料和遥感资料等在此基础上建立雷暴发生、发展、消亡的概念模型,再结合数值模式预报和其他外推方法的结果,最终建立对流性天气的临近预报专家系统,如NCAR的ANC(Auto Nowcaster)预报系统[8]。精细化的数值天气预报技术是未来强对流天气短时临近预报的重要发展方向[9]。利用多普勒雷达资料和其他常规观测资料进行数值模式初始化进而预报中尺度对流系统的发生、发展和消亡已经取得了重要进展。
文中使用VDRAS模式实时反演的低层大气分析场数据,结合机器学习中的基于统计学习理论的支持向量机方法[10],针对强对流天气进行临近预报。首先用VDRAS系统反演得到对流天气的数值模式数据和雷达组合反射率,然后用SVM对不平衡数据[11]进行预报,最后通过评分准则来解决不平衡数据造成的预测结果不均衡。
1 算法设计与实现
文中使用美国国家大气研究中心(NCAR)的VDRAS模式输出的高时空分辨率的实时分析场数据,构建基于box的特征,以美国NEXRAD[12]多普勒雷达数据作为验证的真值,然后利用SVM算法进行训练和预测。
1.1数据的选择
VDRAS系统反演得到的物理量有46个,根据其物理意义和多次实验选出能有效强对流预警的特征(预报因子)。文中所用的预报因子有6个,分别为:rh(relative humidity相对湿度),w(wind垂直风速度),div(divergence辐合抬升),byc (bouyance距平温度),sh(shear风切变),gsh(gshear梯度风切变)。
本论文中所用的VDRAS系统、数据资料均来自NCAR,研究区域为美国丹佛地区。由于风暴是运动的,所以没有采用点对点的预报,而是采取划分子块的方式,以6km*6km大小的方块为单位(1个box,即一个box中的所有特征为一个样本),选取方块中的最大值作为该子块的值写入数据。采取这种方式的原因有两个,一是如果采取点对点的方式进行数据读取,会造成数据资料过多,会产生许多冗余信息,最终会导致计算量过大,速度过慢;二是因为考虑到实际的强对流天气并不会仅仅只是发生在某一个点上。因此,采用划分子块的方式选是可行的。
1.2数据的预处理
将上述6个预报因子作为样本的属性特征,并利用30 min后的雷达组合反射率(radar composite)作为样本的标签。设定标签(label)的基本思想为:将雷达组合反射率的值大于等于35 dbz的样本记为正类(label值为+1),小于35 dbz的样本记为负类(label值为-1)。
样本数据的预处理(不包括radar composite)主要分为两步:差分和归一化[13]。
差分:在天气的变化过程中,相邻时刻的数据在物理意义上是有关联的。随着时间的推移,数据的变化反映了天气的变化。而相邻时刻数据的差值能反映出天气的变化趋势,知道变化趋势能更好的对CI预报,因此本文用向后差分来记录下时间增量信息。具体差分公式如下:

归一化:由于本实验样本数较多,且数据分布较为发散。通过归一化让权重变为统一,且归一化后可以加快梯度下降求最优解的速度,也有可能提高精度。目前,主流的归一化方法有两种。通过实验,发现线性函数归一化能使预报更加准确。因此本文使用的是线性函数归一化。具体公式如下:

1.3算法的设计
1.3.1算法的设计
不平衡数据问题,即在分类问题中正负样本的比例相差很大。在强对流天气预警问题中,强对流天气是属于个别天气,是少数类。因此,可以作为不平衡数据分类问题来处理。目前不平衡数据分类的相关解决方法主要从数据层面(改变数据的分类)、算法层面(设计新的分类方法)和判别准则(设计新的分类器性能评价准则)3个不同层面进行研究。
分类问题中,基于统计学习理论的支持向量机(Support Vector Machine,SVM)方法逐渐成为机器学习的重要研究方向。与传统的基于经验风险最小化原则的学习方法不同,支持向量机基于结构风险最小化,能在训练误差和分类器容量之间达到一个较好的平衡,它具有全局最优、适应性强、推广能力强等优点。文中选用机器学习中常用的SVM算法作为分类器。
强对流天气的发生可以看作是小概率事件,因此强对流天气预警问题可以作为不平衡分类问题来处理。而现在机器学习大部分的学习算法是基于一个平衡的训练集而设计的(包括SVM)。为了解决此类问题,文中将SVM和不平衡数据分类方法中的判别准则结合,用来对强对流天气预警。
1.3.2评估方法
评价一个分类器的性能的好坏的一个关键因素是评分标准,评分标准将指导分类器模型的建立。在两分类问题中,混淆矩阵(见表1)中记录的是每一个类的正确和错误识别的结果。

表1 二分类问题下的混淆矩阵
由于在气象预报领域和机器学习领域中各自存在不同的评分标准,本论文通过结合两类评分标准以及不平衡数据分类的特点挑选出了合理的评分标准[14],做如下定义:
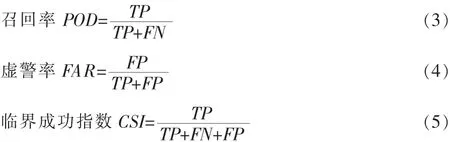
1.4算法的实现
文中通过用SVM分类器进行分类,然后对预测样本输出概率置信度,将其重新调整,从而获得最优的分类结果。具体步骤如下:
1)从VDRAS中获取实验所需的数据;
2)对数据进行预处理;
本文中的预处理包括对原始数据进行差分和归一化,并将所有的样本数据分为训练集和测试集两部分。
3)用SVM对训练集进行训练,得到模型;
4)用3)所得的模型,对测试集进行预测,获得每个样本的置信度;
置信度(confidence)是一个概率值,下面的步骤会根据置信度将样本预测为正类或者预测为负类。将此样本划分为正类的概率值称为正例置信度。
5)通过调整阈值解决本实验中所用的数据不均衡的问题。
文中的阈值亦为临界值。由于SVM主要是应用于平衡数据集的分类,其默认的概率阈值为0.5,即当预测概率结果中正例置信度大于等于0.5的时候,分类为正样本,小于0.5的时候分类为负样本。由于本实验的数据为非平衡数据,因此进行分类时,为获得最优的分类结果,对概率阈值进行了调整,分别采用不同的阈值进行分类,并计算相应的评价指标,最后选取最优的评价指标。
文中主要应用的评价指标为POD、FAR、CSI。不同的阈值下评价指标结果不同,考虑到CI预警具有的实际意义,POD达到0.6的时候才具有实际应用价值,所以在选取评价指标结果的时候按照以下标准进行:因CSI指标综合考虑召回率(POD)和虚警率(FAR),故首先观察该指标,即不同置信度下,若CSI的指达到最大且POD的值大于等于0.6,则选择该置信度下的评级指标结果;若CSI达到最大时POD的值小于0.6,则重新观察不同置信度下POD的值,选择POD达到0.6时,对应的置信度下的评价指标结果。
6)用feature selection分析预报因子的重要性
前面经过分析选取了6个预报因子,这6个预报因子连同其差分(12个特征)又进行了特征选择实验,主要用来获取最重要的特征。具体实验描述如下:依次去掉每个特征值和其对应的差分,用剩下的10个特征值进行训练和预测,然后观察每次的结果表现。实验结果如图1所示。
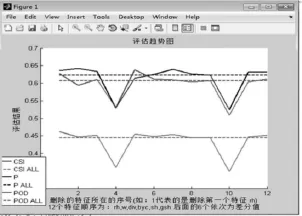
图1 feature-selection实验结果
图1表明,当去掉byc及其差分dbyc的时候,CSI、P(这里的P为精确度,值的大小为1-FAR)和POD值都下降很多,由此可得出结论byc在整个预报过程中起重要作用。则,预报因子的贡献率由高到低依次为:byc、w、gsh、div、sh、rh。
针对feature selection结果和在实际中特征值的物理意义,最终选取如下特征组合进行实验:1)byc+dbyc 2)w+dw+ byc+dbyc 3)所有12个特征值。
2 实验结果与分析
2.1实验结果
下面是所做各种组合的实验结果:(注:文中所用的POD 和CSI值是越大越好,而FAR越小越好 )
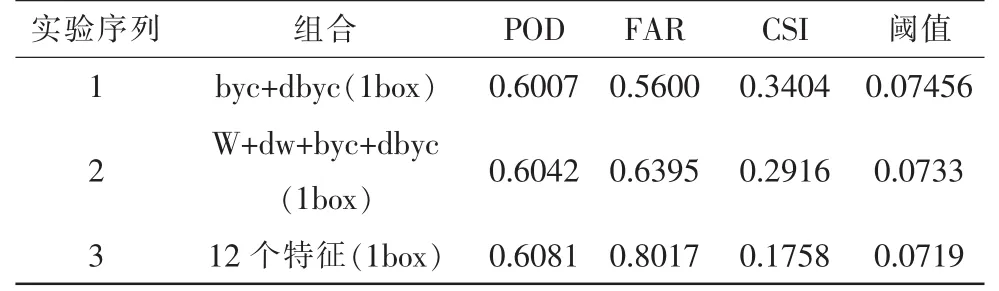
表2 SVM各种特征组合实验结果表
由表2的实验1、2、3结果可以看出在1个box试验中byc+dbyc组合的实验结果是最好的,它的CSI值为0.3404,而w+dw+byc+dbyc组合的CSI值为0.2916,12个特征的效果更差CSI为0.1758。
下面的结果显示就是将实验效果最好的组合 (实验1:1box byc+dbyc组合和实验2:9box w+dw+byc+dbyc组合)用CIDD[15]显示出来,可以进一步观察分类器的好坏。
2.2分析
论文主要是利用30 min后雷达组合反射率来标记标签,对30 min后的天气进行CI预报。本文实验所用的是2012年前的5个案例做训练集,2012年的2个案例做测试集,具体的预测结果可通过气象中的VDRAS系统中的CIDD以图像的方式显示出来。下面对所用的结果预报图和结果显示图进行分别说明:
1)结果预报图:即,所用的背景雷达图像是当前时刻的雷达图像,而所用的预报结果是30 min之后的。图中的白框表示当前时刻此处有强对流天气的现象;黑框表示当前时刻存在强对流天气,30 min后也存在强对流天气;灰框表示的是本算法所预测出30 min后会出现强对流天气,能很好的描述出强对流天气的运动趋势和发展方向。
2)结果显示图:即,所用的雷达图像是30 min之后的,预报结果也是30 min之后的。图像中的3种不同的框与结果预报图中的表示有所不同:白色表示漏报,黑色表示预报正确,灰色表示的是误报。此图用来说明预报的是否准确。
结果分析:本实验中用1个box byc+dbyc组合的样本来训练。在此实验中,选取最优的阈值为0.074 56,评分结果如下:
POD为0.600 7;FAR为0.560 0;CSI为0.340 4;
1)图2为2012年6月6日20时55分的预测结果的CIDD显示图(当前时刻为20时55分,预报为30分钟之后的),图(a)是结果预报图,图(b)是结果显示图。
由图(a)看灰色框可以看出该天气的运动趋势,向图所示的右上方发展。而在图(b)的整个显示区域中,黑框很好的展现出了预报结果,还是挺准确的。
2)图3为2012年6月6日22时10分的预测结果的CIDD显示图,图(a)是结果预报图,图(b)是结果显示图。
图(a)中可以看出,此强对流天气处于产生、发展、消亡中的发展阶段。从整个3-2来看,研究区域中给出的预报结果基本上都覆盖了出现强对流天气的地方,虽然会出现少量误报,但是整个区域的基本形状还原程度还是比较高的。给出的预报结果与实际情况非常吻合。
3)图4为2012年7月7日21时10分的预测结果的CIDD显示图,本图为结果显示图。
这个是预测失败的个例,由图可以看出,本次的预测结果有些偏离强对流天气发生的位置。图的右下角区域还是可以预报出整个强对流天气的大体位置,但周围会出现一些的漏报和误报;在图的左上角区域不是漏报就是误报,而左下角更是出现大片的误报。出现这种预报结果,说明本文提出的预警算法还是有待于进一步完善。

图2 2012年6月6日20时55分结果图

图3 2012年6月6日22时10分结果图

图4 2012年7月7日结果显示图3
3 结 论
文中主要用VDRAS的数值模式数据,结合机器学习中的SVM,针对强对流天气进行临近预报。首先用VDRAS系统反演得到实验所需的数据并将数据做预处理;然后用SVM对不平衡数据进行训练和预报;最后通过调整阈值(即修改评分准则)来解决不平衡数据造成的预测结果不均衡。为了直观的观察实验结果的好坏,本文通过CIDD将预报结果直观的展示出来。分析实验结果,发现本文提供的算法在一定程度上提高了识别的精度,降低了虚假警报发生的概率。表明,该方法能很好地实现强对流天气的临近预报,但是本算法还有些缺陷需要改进,这也将是我们下一步的工作目标。例如:只能人工选取预报因子,这就增加了实验的不确定性;划分子块上,文中用每个子块区域中6*6格子中的最大值作为该子块的值,虽然有效减少了计算量,但是也丢弃了一部分信息,因此应该由更加完善的做法在减少计算量的同时也保留信息。
[1]韩雷,俞小鼎,郑永光,等.京津及邻近地区暖季强对流风暴的气候分布特征[J].科学通报,2009,54(11):1585-1590.
[2]赵畅.多普勒雷达及多源资料在局地短临预报中的应用[D].南京:南京信息工程大学,2014.
[3]Sun J,Crook N A.Dynamical and microphysical retrieval from Doppler radar observations using a cloud model and its adjoint[J].Model development and simulated data experiments. J.Atmos.Sci.,1997(54):1642-1661.
[4]程丛兰,陈明轩,王建捷,等.基于雷达外推临近预报和中尺度数值预报融合技术的短时定量降水预报试验 [J].气象学报,2013,71(3):397-415.
[5]刘国忠,黄开刚,罗建英,等.基于概念模型及配料法的持续性暴雨短期预报技术探究[J].气象,2013,39(1):20~27.
[6]王启光,丑纪范,封国林.数值模式延伸期可预报分量提取及预报技术研究[J].中国科学,2014,44(2):343-354.
[7]陈雷,戴建华,徐强君.基于雷达回波外推技术的闪电临近预报方法研究[C]//第九届长三角气象科技论坛论文集,2012.
[8]Wilson JW,Crook N A,Muller C K,et al.Nowcasting thunderstorms:a status report[J].Bull Amer Meteor Soc,1998,79 (10):2079-2099.
[9]郑永光,张小玲,周庆亮,等.强对流天气短时临近预报业务技术进展与挑战[J].气象,2010,36(7):33-42.
[10]邓乃扬,田英杰.数据挖掘中的新方法-支持向量机[M].北京:科学出版社,2004.
[11]叶志飞,文益民,吕宝粮.不平衡分类问题研究综述[J].智能系统学报,2009,4(2):148-156.
[12]Bieringer P,P S Ray.A Compari son of tornado warning lead timeswithandwithoutNEXRADDopplerRadar[J]. WeaForecasting,1996(11):47-52.
[13]XIAO Han-guang,CAI Cong-zhong.Comparison study of normalization of feature vector[J].Computer Engineering and Applications,2009,45(22):117-119.
[14]石璐.基于数值模式和雷达数据的对流初生预警技术研究[D].青岛:中国海洋大学,2015.
[15]陈明轩,俞小鼎,谭晓光,等.对流天气临近预报技术的发展与研究进展[J].应用气象学报,2004,15(6):754-766.
The identification of strong convective weather based on machine learning methods
XIU Yuan-yuan,HAN Lei,FENG Hai-lei
(School of Information Science and Engineering,Ocean University of China,Qingdao 266100,China)
The present study was designed to use a supervised learning method-support vector machines SVM of machine learning to recognize and forecast the strong convective weather.The occurrence of strong convective weather can be seen as a small probability event,so this problems can be handled as imbalanced data classification.To make better forecast,on the application of SVM we proposed a new criterion for processing data on imbalances.This paper described the algorithm in several aspects:the data obtained,the training algorithm,the application of the algorithm,the assessment results.This paper used Denver area data,eliminated the interference of imbalanced data classification,and improved the accuracy of recognition of severe convective weather.
strong convective weather warning;SVM;unbalanced data classification;machine learning
TN957.52
A
1674-6236(2016)09-0004-04
2015-11-19稿件编号:201511181
国家自然科学基金(41005024)
修媛媛(1991—),女,山东聊城人,硕士研究生。研究方向:人工智能。
