国外Folksonomy与Ontology融合研究的热点与趋势
2016-09-03张云中李佳佳上海大学图书情报档案系
张云中,李佳佳(上海大学图书情报档案系)
国外Folksonomy与Ontology融合研究的热点与趋势
张云中,李佳佳(上海大学图书情报档案系)
以2005~2015年期间Web of science(SSCI)数据库中有关本体与大众分类法融合研究的相关文献为数据来源,采用共词分析法,以SPSS软件为工具,对提取出的高频关键词进行聚类分析和多维尺度分析,研究各高频关键词之间的内在关系,发现并探讨国外本体与大众分类法融合研究的四个热点与趋势,以期为国内学界相关研究提供启示。
本体;大众分类法;标签;融合;共词分析
Folksonomy源于web2.0下网络资源组织理论与实践的发展,其由词根folks和onomy组合而成,folks指人、大众,onomy指一种系统、专门的学科知识,二者结合简言之就是“由大众所产生的一种分类知识”。更精确地解释是“一群人自发性定义的平面非层级式标签分类方法”,[1]国内一般译为大众分类法。Ontology(本体)是共享概念模型的明确形式化规范说明,旨在通过捕获领域知识,用高度形式化的模型给出领域共享词汇间关系的明确定义。作为知识表示与组织的新兴工具,二者的优劣形成了鲜明的互补特色。本体具有高度形式化、准确性、规范性、可复用性等优点,但是创建成本高、灵活性低、不易变化等,而大众分类法具有低成本、高灵活性、易变动等优点,但存在非形式化、语义模糊和语义稀疏等缺点。[2]在此背景下,本体与大众分类法的融合研究逐渐兴起,如何利用本体与大众分类法的融合优化web2.0下的资源组织成为国内外学者们关注的热点。国外学者自2005年起就关注二者的融合研究,相比而言,国内则起步较晚。本文旨在提取Web of science(SSCI)数据库中2005~2015年期间发表的有关二者融合的文献,分析梳理该主题的研究热点及发展趋势,希望对国内该领域的研究者提供一些启示。
1 数据的获取及分析
1.1数据的获取与处理
本文主要以Web of science(SSCI)全文数据库作为数据来源,分别以 SU=“tag and ontology”和SU=“folskonomy and ontology”为检索式进行检索,限定研究方向为information science library science和computer science,共检索出文献469篇,经过去重、无关文献去除和无关键词文献去除后,得到文献281篇,关键词共678个,总词频为1410。为提高共词分析的精准度,本文对获取的关键词做了如下处理和筛选:① 不同关键词但含义相同或相近的,进行合并处理,如关键词 tag、tags、social tag、social book-mark统一合并为tag;② 关键词的大小写和单复数不同的,统一成单数、小写,如Digital library和digital libraries统一合并为digital library;③ 关键词与研究主题关系不紧密的,进行删除;④ 关键词书写错误的,进行改正。整理后的结果见表1。
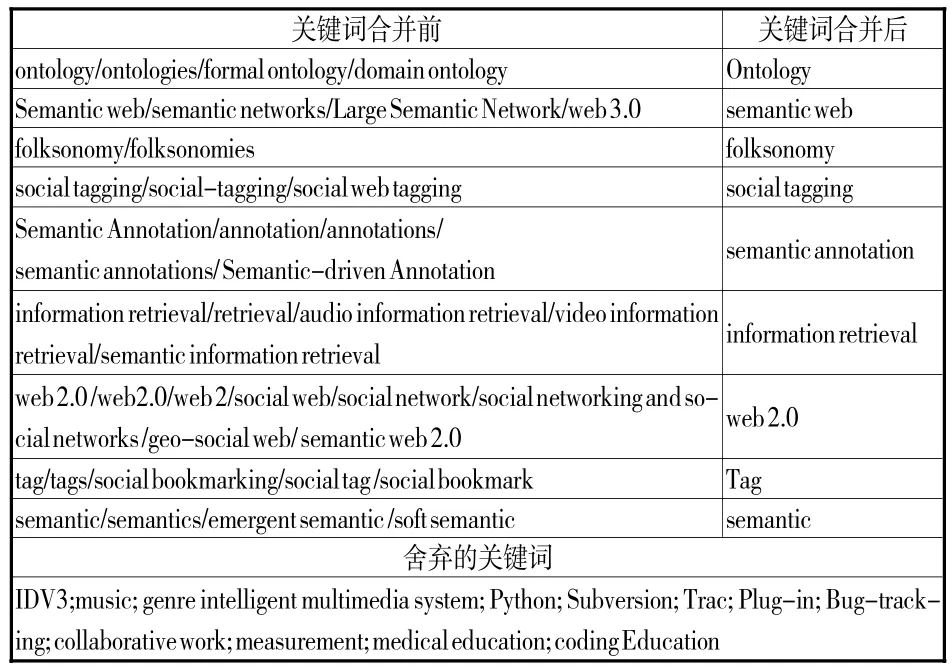
表1 关键词筛选表(部分)
关键词处理和筛选后就可选取高频词,对此学界一般采用两种方式:①根据齐普夫第二定律公式,计算得出高频词界限值后选取;②由研究者根据领域情况自主选取。鉴于本文涉及的领域较新,文献数量不够庞大,故采用第二种方式,取频次为5以上的关键词作为高频词,共统计出高频词37条(见表2),涉及文献254篇,占总文献数的90.4%,因而在一定程度上能够代表国外最近10年有关本体与大众分类法融合研究热点。
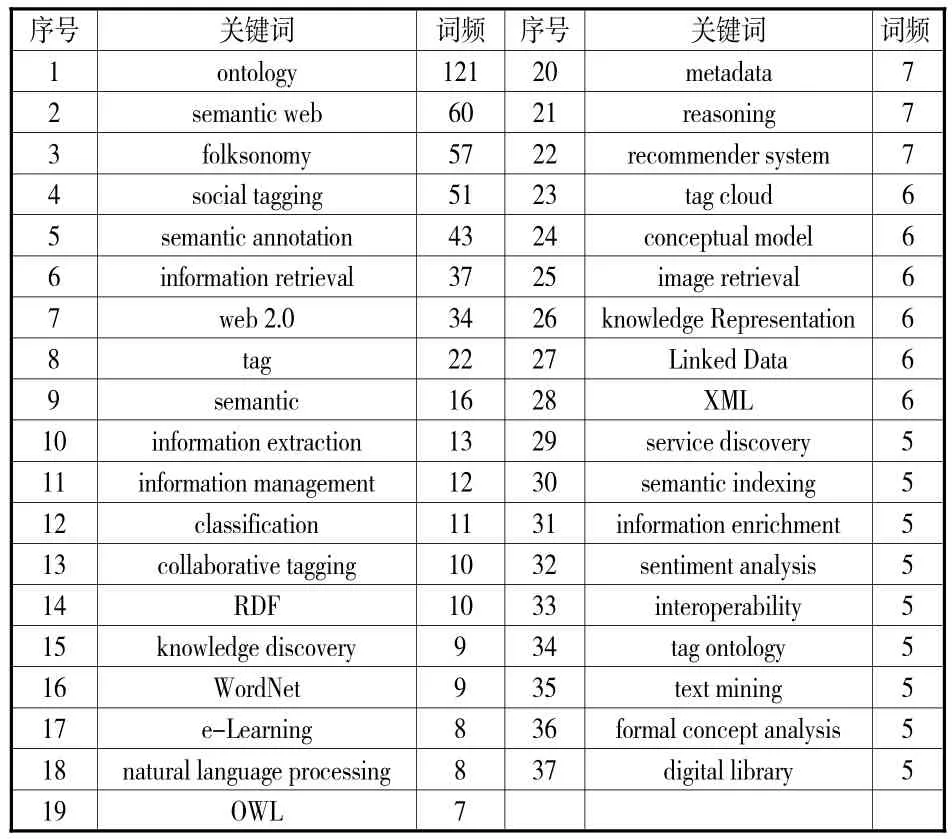
表2 高频关键词
1.2矩阵构建
虽然表2中关键词的词频排序在一定程度上代表了folksonomy与ontology融合的热点,但是这种线性排序未能反映出关键词之间的关联,因而需要进一步研究不同关键词在同一篇文献中的共现情况来发现研究热点间的关联,进而发现二者的融合热点与趋势。为此,本文构建了用于共词分析的 37*37的共词矩阵(见表3),并以此为基础进行多元统计分析。
本文采用聚类分析和多维尺度分析结合的方式来分析二者融合研究的热点和趋势,为满足这两种分析方法对矩阵的数据结构要求并保证数据的精确性,需将共词矩阵转化为相似矩阵和相异矩阵。共词矩阵转换成相关矩阵可用计算ochiia系数来实现,计算公式为:A,B两词Ochiia系数=A,B两词共同出现的次数/。相关矩阵中对角线上的数据都为1,表示某词自身的相关程度。一般情况下,相关矩阵中0值过多会导致较大的统计误差,因而需要用“1”减去相关矩阵中的全部数据,得到表示两词间相异程度的相异矩阵(见表4)。相异矩阵中,数值越小,则表示关键词之间的关系越近,反之亦然。

表3 共词矩阵(部分)
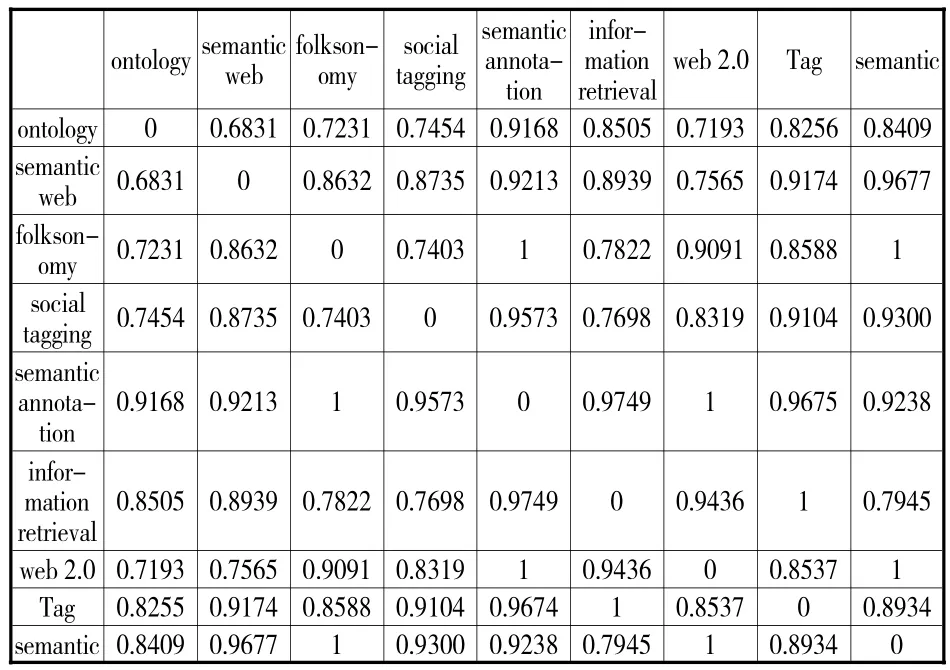
表4 相异矩阵(部分)
2 高频词的共词分析
2.1聚类分析
聚类分析又称集群分析,是统计学中研究物以类聚问题的多元统计分析方法,其目的在于将对象加以聚集、分类,使得在群体内的个体的同质性很高,群体之间的异质性也很高。本文使用聚类分析的目的是把关联程度较密切的关键词聚集到一个类团中,进而协助folksonomy与ontology融合研究方向的划分。具体做法是将表4中的相异矩阵导入SPSS软件中,运用其中的聚类分析功能对其进行层次聚类分析,得出所要研究的高频关键词的树状图(图1)。
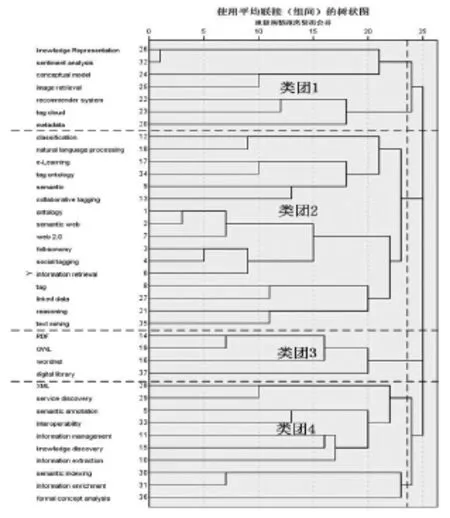
图1 聚类分析树状图
根据统计出来的聚类图,在阈值为24.1处把关键词分为4个类团,其中类团一包含的关键词主要有metadata、recommender system等,涉及文献38篇;类团二是图中较大的一块,包含的关键词主要有ontology、folksonomy、web2.0等,涉及文献247篇;类团三包含的关键词主要有OWL、RDF等,涉及文献25篇;类团四包含的关键词主要有service discovery、information management、information extraction等,涉及文献66篇。这四个类团共计包含文献376篇,因为有重复统计,所以总数要大于实际论文数,根据各个类团所占文献篇数可知,第二类团是目前国外关于大众分类法和本体融合研究的一个主要热点,也是本文第三部分所要重点阐述的内容。
2.2多维尺度分析
多维尺度分析是分析研究对象的相似性或差异性的一种多元统计分析方法,其目的是将研究个体之间的距离尽可能用二维或者三维的空间距离加以反映,这样可以客观地反映研究个体之间的相似性关系。本文利用多维尺度分析,目的是将ontology与folksonomy融合研究的高频关键词投射在一张知识图谱呈点状分布,并计算各个关键词之间的Euciliden距离来实现关键词的聚集,进而辅助folksonomy与ontology融合研究方向的划分。具体做法是将相异矩阵(见表4)导入SPSS中,通过度量功能,对导入的相异矩阵进行多维尺度PROXSCAL分析,得出一个具有二维空间效果的可视化图表,即多维尺度分析图(见图2)。根据多维尺度分析图,二者融合的领域可大致划分为三个区域:区域一涉及的关键词包括Ontology、folksonomy、semantic等 14个;区域二涉及的关键词包括web2.0、owl、RDF、metedata、reasoning等15个;区域三涉及的关键词包括information management、informationenrichment等8个。

图2 多维尺度分析图
3 研究热点与趋势分析
根据2005~2015年folksonomy与ontology融合领域相关文献高频关键词表及依托该表展开的聚类分析图和多维尺度分析图,本文展开如下分析。
聚类分析图中的类团2和多维尺度分析图中的区域1关键词具有很高的重合率,且关键词之间的内在关联都反映出folksonomy与ontology之间的相互优化,本文由此得出两个研究热点:热点一是利用ontology优化folksonomy语义,热点二是利用folksonomy实现本体开发及演进。
聚类分析图中的类团1及类团3和多维尺度分析图中的区域2关键词具有很高的重合率,且关键词之间的内在关联都反映出利用其它工具强化ontology与folksonomy融合的研究,此为热点三。
聚类分析图中的类团4和多维尺度分析图中的区域3关键词具有很高的重合率,且关键词之间的内在关联都反映出利用ontology和folksonomy融合的优势解决信息资源管理领域的问题,此为热点四。
3.1热点一:利用ontology优化folksonomy语义
热点一涉及的关键词共14个,总词频为437,词频较高的有ontology、folksonomy、social tagging、tag、semantic web、information retrieval、collaborative tagging,占总词频的82.2%。从高频关键词表2可以看出,这些关键词都是排在前几位的,说明是近几年国外学者对有关本体与大众分类法融合研究的核心主题。该热点聚焦于如何利用ontology提高folksonomy检索语义,具体的实现途径又可以分为四个分支。
(1)建立标签与本体之间的语义映射。涉及的主要关键词有tag、ontology、semantic、semanticweb、information retrieval等。国外学者普遍认为,folksonomy扁平化的资源组织和表示结构决定了其仅能揭示稀疏、模糊语义,要提高检索的精度,就需要通过语义映射借助其他形式化的语义工具来辅助folksonomy标签语义关系的建立。在此主导思想下,ontology成为国外学者的首选,建立标签与本体之间的映射成为一种比较常用且有效的方法,利用本体强化folksonomy语义,使标签与标签之间的结构、关系更为规范、精确和丰富,进而提高检索的精准度。该类研究中具有代表性的研究是Lezcano L等提出的利用标签向本体映射建立混合导航环境来提高大众分类法的检索效率。[3]建立标签与本体之间语义映射的难点在于如何利用统计、聚类等方式高效、简洁、准确地建立映射进而清晰化标签之间的上下位属种关系,因而不断探索建立二者映射的新理论、新方法就成为该类研究的必然趋势。
(2)利用本体规范标注活动的研究。涉及的主要关键词有 socialtagging、tagontology、collaborative tagging、ontology等。这类研究的主要思想是利用本体的语义控制功能在语义层次上构建标签语义网络,进而实现对用户的标注行为进行标识和控制。国外学者根据不同的设计理念设计了相应的标签本体模型,其中代表性的是三元组模型Tag ontology(user,tagging,tag)[4]和四元组模型 MOAT(user,resource,tag,meaning)。[5]在此基础上更深入一步,分析每个标签本体模型的异同点,整合不同的标签本体模型将成为该思路下近年来研究的趋势。另外,在本体辅助的基础上实现对资源的自动标注也是国外近年来探索的新方向之一,该类研究中代表性的是Rattanapanich R等利用本体和潜在语义分析技术实现自动标注,并通过比较自动标注和手动标注,发现自动标注方法返回的结果更加精确。[6]
(3)利用本体表示用户兴趣模型实现个性化推荐。涉及关键词有recommender system、ontology、tag、information retrieval等。除明晰标签语义和规范标注活动外,为用户推荐符合其兴趣偏好的资源也是提高folksonomy检索语义的重要途径,国外学者由此思想衍生出了利用本体构建用户兴趣模型实现folksonomy资源的个性化推荐的研究方向。用户兴趣可在社会化标注系统中用户对偏好资源的配置文件的基础上获得,代表性的研究是Movahedian H等在用户配置文件基础上改善和提出新的个性化推荐系统,[7]也可通过收集用户标签和分析用户的标注活动等方法获得,代表性的研究是Han X等通过收集用户标签构建出用户兴趣模型实现标签推荐。[8]用户兴趣模型的结果一般用本体表示,以实现对用户兴趣模型的精确化、形式化表达。从研究趋势看,依托数据挖掘方法从“用户集、资源集、标签集”获取用户兴趣较之从用户配置文件获取用户偏好更具发展前景,更能提高个性化推荐的准确性、多样化、新颖性和动态性。另外,当前的个性化推荐大多针对单用户,针对用户群体的偏好资源推荐也将成为研究趋势之一。
(4)利用本体实现跨平台的语义关联。涉及的主要关键词有folksonomy、ontology、linked data等。从单平台的资源检索发展成为跨平台的资源检索是国外folksonomy语义检索领域近年来研究的一步试探。实现跨平台资源检索的前提是必须选择具有语义重叠的同类社会化标注系统,其难点在于建立不同平台间的语义关联,核心在于选择实现语义关联的工具。近年来,由于本体的平台无关性、共享性、可复用性、形式化等优点,国外学者普遍将本体作为实现跨平台语义检索工具的不二选择,代表性的研究是Kim HL等利用跨平台的标签本体整合实现对网站间标注数据的共享和链接,通过对标注数据的整合来提高信息检索效率。[9]另外,随着关联数据研究的不断深入,利用本体和关联数据结合实现跨平台的语义关联也成为不错的选择,代表性的研究是Passant A等提出MOAT本体和关联数据整合方案。[10]就发展趋势而言,关联数据的应用为实现跨平台语义关联注入了新活力,关联数据与本体结合将成为未来解决该类问题的主流方法。
3.2热点二:利用folksonomy实现本体开发及演进
热点二涉及的关键词有folksonomy、ontology、ontology learning、ontology development和ontology enrichment等,其中后三个的词频依次为4、4和3,所以没有出现在高频关键词表里,但是它们又是与该热点紧密相连的,所以把它们也放在讨论中。较之热点一,热点二的相关研究成果尚不丰硕,但却正处于逐年上升的发展趋势。该热点主要聚焦于如何用folksonomy去实现本体开发、本体学习和本体丰富的研究,下面从两个方面进行阐述。
(1)本体开发与构建的研究。涉及的关键词主要有folksonomy、ontology、ontology development。该方向的主导思想是充分发挥二者的互补性,借助folksonomy标签的群体性来确保本体概念的共享性,借助folksonomy大众参与的低廉成本来缩减本体构建的高昂成本,借助folksonomy更新快速来确保本体演进的时效性,基于folksonomy实现本体构建的术语收集、概念关系确立、属性实例填充、规则建立等环节,正如Chen W等指出,folksonomy是生成本体的潜在知识源,可以用folksonomy的基本层次概念来生成本体。[11]就本体构建的结果而言,国外学者大多倾向于构建具有折衷和融合意味的tag ontology、folksonomized ontology等,并将其应用到社会化标注系统中作为导航之用,该方面的代表性研究是Alves H等利用两者的融合构建folksonomized ontology,并利用3E技术提取、丰富和评估本体。[12]该方向的研究趋势是形成一种依托于folksonomy环境的本体开发理论和方法,作为对传统依托专家知识构建本体的补充和拓展。
(2)本体学习或本体丰富的研究。涉及的主要关键词有folksonomy、ontology、ontology learning、ontology enrichment和e-learning。国外学者开展本体学习或本体丰富的思路是自动或半自动地从folksonomy数据源中提取概念和关系,进而形成本体或对已有本体的概念、概念关系、属性、实例或规则进行丰富和完善,该类研究开展仍然是建立在folksonomy与ontology融合基础上,且本体学习和本体丰富往往一脉相承,前者作为后者的主要方法和途径。该研究方向上具有代表性的研究是 Freddo A R等通过本体学习和本体评估技术结合的方法利用本体校正方法进行本体丰富。[13]另外,利用基于标签的本体丰富来支持电子学习是国外学者近年来研究的一个创举,Monachesi P等通过用户评价对比了本体丰富和标签集群在支持学习任务方面的影响,[14]认为前者更具优势。就研究趋势而言,本方向仍将着眼于自动或半自动地从folksonomy标签集中抽取概念和概念关系,因而对本体学习方法的改进,对本体学习工具的完善,对本体学习结果的评价都将是学者们关注的焦点。
3.3热点三:利用其它工具强化ontology与folksonomy融合的研究
热点三涉及的主要关键词较多,有 metadata、knowledge representation、conceptual model、formal conceptanalysis、RDF、linkeddata、owl、wordnet等,但各词的词频均不高,说明该类研究呈现多样化、多方案的趋势。该研究方向主要聚焦于利用其它工具最大限度地弥补和消除两者融合的负面效应,国外学者着重关注的研究方向如下。
(1)ontology、folksonomy的异同优劣对比。涉及的关键词主要是metadata、knowledge representation等。国外学者认为,ontology和folksonomy都可视为特殊的元数据,二者在知识表示的视角下各具优劣。开展这类研究的时期都较早,结论也很成熟,为二者融合奠定了坚实基础,代表性的研究是Christiaens S等较早指出ontology与folksonomy作为不同元数据机制具有一定的区别与联系,通过两者的互补结合,借助方法论,可以解决二者的缺陷。[15]
(2)利用其它工具实现对folksonomy的辅助或优化。涉及的关键词主要有 conceptual model、formal concept analysis等。该研究方向的基本思路是利用相关理论、方法和技术消除二者融合中的标签歧义、标签模糊等问题,通过赋予标签清晰的语义化概念,使标签变成具有语义丰富的层次化结构,从而在社会化标注系统中能被更好地使用,其中代表性的研究有:Kim H L利用概念语义模型描述标签的核心概念和相关特性,推导出标签之间的关系;[16]Jschke R等利用形式概念分析发现标签集中隐含的共享的概念及概念层次,并进行形式化的定义,实现folksonomy概念层次发现[17]等。 就研究趋势而言,此类研究仍将呈现多元化,除去上面提到的概念模型和FCA之外,分类法、叙词表、主题词等受控词表的引入,统计方法、聚类方法的使用,数据挖掘技术、可视化建模技术应用都会从不同角度、不同侧面弥补二者融合中folksonomy自身的缺陷。
(3)利用其它工具实现对本体的辅助或优化。涉及的关键词有 RDF、owl、wordnet、reasoning等。该研究方向的主导思想是利用相关理论、方法和技术辅助解决二者融合过程中本体的形式化表示、本体概念语义关系结构的解析、本体推理等问题。RDF三元组和owl语言在目前本体形式化描述语言中仍占主流,在描述本体概念的关系、属性与属性之间的关系等方面仍然不可或缺。Wordnet通常被国外学者作为通用本体或语义库用以确立同义词集或上下位语义关系,辅助标签语义确立或本体构建,代表性的研究是Chen R C利用wordnet识别语义,协助完成自动化的领域本体构建。[18]另外,为提高二者融合环境下资源检索的智能性,国外学者从语义推理入手,尝试通过丰富和完善本体推理规则解决该问题。该方向的研究仍将延续过去几年的思路,不断探索新的更合理的本体形式化表示方式,不断完善类似WordNet的语义结构体系,不断提升智能推理的水平。
3.4热点四:利用ontology和folksonomy融合的优势解决信息资源管理领域的问题
热点四涉及的关键词包括 information retrieval、image retrieval、service discovery、information management、 informationextraction、 informationenrichment等。该研究方向的主导思想是既不用本体去优化folksonomy,也不用folksonomy来丰富本体,而是将两者放在平等地位上,充分发挥各自优势来解决信息资源管理领域信息检索、图像检索、服务发现、信息管理、信息抽取和信息丰富等问题。folksonomy由大众构建,技术简易,成本低廉又具有柔性,在解决信息资源管理领域问题时方便易用,适合用于前段与用户互动;ontology语义准确且丰富,形式化程度高,在解决信息资源管理领域问题时精准可靠,适合用于后台作为保障。该方向具有代表性的研究有Peng X等利用众分类法和本体融合,使数字地名系统能够提供智能的数字地名信息服务,从而提高地理信息检索的能力。[19]Bindelli S等利用整合了大众分类法与本体的优势从而达到提高信息搜索与导航的目的。[20]Karimpour R等利用本体从语义上增强web服务和实现web服务发现。就研究趋势而言,随着web2.0实践的不断发展和深入,该热点在folksonomy与ontology融合领域所占的比重将越来越高,其原因在于二者融合的终极目标不是为了融合而融合,而是为解决现实问题而融合。
[1]王爽,徐行.基于用户分类标签建立结构性的大众分类法[J].图书馆学研究,2011(9):73-76.
[2]张云中.本体与自由分类法的融合机理研究[J].情报理论与实践,2012,35(2):35-40.
[3]Lezcano L,et al.Bridging informal tagging and formal semantics via hybrid navigation[J].Journal of InformationScience,2012,38(2):140-155.
[4]Richard N,et al.Tag ontology[EB/OL].[2015-04 -22].http://www.holygoat.co.uk/owl/redwood/0.1/tags/.
[5]Passant A,Laublet P.Meaning of a tag:A collaborative approach to bridge the gap between tagging and Linked Data[EB/OL].[2015-04-22].http://events. linkeddata.org/ldow2008/papers/22-passant-laubletmeaning-of-a-tag.pdf.
[6]Rattanapanich R,Sriharee G.Auto-tagging articles usinglatentsemantic indexing and ontology[M]//Intelligent Information and Database Systems.Springer InternationalPublishing,2014:153-162.
[7]Movahedian H,Khayyambashi M R.Folksonomy-based user interest and disinterest profiling for improved recommendations:An ontological approach[J].Journal of Information Science,2014:40(5):594-610.
[8]Han X,et al.Folksonomy-based ontological user interest profile modeling and its application in personalized search[M]//ActiveMediaTechnology.SpringerBerlin Heidelberg,2010:34-46.
[9]KimHL,etal.Integratingtaggingintotheweb ofdata: Overview and combination of existing tag ontologies [J].Journal of InternetTechnology,2011,12(4): 561-572.
[10]Passant A,et al.Auri is worth a thousand tags:From tagging to linked data with moat[J].Semantic Services,Interoperability and Web Applications:E-merging Concepts:Emerging Concepts,2011:279.
[11]Chen W,et al.Generating ontologies with basic level concepts from folksonomies[J].Procedia Computer Science,2010,1(1):573-581.
[12]Alves H,Santanche A.Folksonomized ontology and the 3E steps technique to support ontology evolvement [J].Web Semantics:Science,Services and Agents ontheWorldWideWeb,2013,18(1):19-30.
[13]FreddoAR,TaclaCA.Integrat-ingSocial Webwith SemanticWeb-OntologyLearningandOntologyEvolutionfromFolksonomies [C]//Las Vegas:IKE'09 2009-The 2009 International Conference on Information and Knowledge EngineeringIKE'09,2009:247-253.
[14]Monachesi P,et al.Ontology enrichment with social tags for e-learning[M]//Learning in the Synergy of Multiple Disciplines.Berlin:Springer-Verlag,2009: 385-390.
[15]Christiaens S.Metadata mechanisms:From ontology to folksonomy...and back[C]//On the Move to Meaningful Internet Systems 2006:OTM 2006 Workshops. Berlin:Springer-Verlag,2006:199-207.
[16]KimHL,et al.Social semanticcloudof tags:semantic model for folksonomies[J].Knowledge Management Research&Practice,2010,8(3):193-202.
[17]Ja..schke R,et al.Discovering shared conceptualizations infolksonomies[J].WebSemantics:Science, ServicesandAgentsontheWorldWideWeb,2008,6 (1):38-53.
[18]Chen R C,Chuang C H.Automating construction of a domain ontology using a projective adaptive resonance theoryneuralnetworkandBayesiannetwork[J].Expertsystems,2008,25(4):414-430.
[19]Peng X,et al.A folksonomy ontology based digital gazetteer service[C]//Beijing InternationalConferenceon Geoinformatics.2010:1-6.
[20]Bindelli S,et al.Improving search and navigation by combiningontologiesandsocial tags[C]//On the Move to Meaningful Internet Systems:OTM 2008 Workshops.Berlin:Springer-Verlag,2008:76-85.
Abroad Research Hotspots and Trends of the Integration of Folksonomy and Ontology
Zhang Yun-zhong,Li Jia-jia
Taking the documents of the research on the integration of Folksonomy and Ontology in Web of Science(SSCI)in 2005~2015 as data source,this article applying co-term analysis method and SPSS to analyzes high frequency keywords so as to discover internal relationship among these keywords.Meanwhile,this article discovers 4 hotspots and trend of the integration of Folksonomy and Ontology in abroad which can serve as reference for domestic research field.
Ontology;Folksonomy;Marks;Integration;Co-term Analysis
G254.1
A
1005-8214(2016)07-0039-06
本文系上海市哲学社会科学规划课题青年项目“自由分类法、专家分类法和本体的融合集成研究”(项目编号:2014ETQ001),上海市教育委员会科研创新项目“web2.0下本体与大众分类法的互补与融合”(项目编号:14YS007)的研究成果和上海市青年教师培养资助计划成果之一。
张云中(1985-),男,博士,上海大学图书情报档案系讲师,硕士生导师,研究方向:知识组织;李佳佳(1990-),女,上海大学图书情报档案系硕士生,研究方向:知识组织。
2015-12-14[责任编辑]阎秋娟
