基于集成学习和元胞自动机的城市地理模拟
2016-07-13张锐豪赵耀龙吴智刚罗文斐
张锐豪, 赵耀龙, 吴智刚, 罗文斐
(1.华南师范大学地理科学学院,广州 510631;2.华南师范大学智慧国土与资源环境研究中心,广州 510631;3.华南师范大学城市与区域发展研究中心,广州 510631)
基于集成学习和元胞自动机的城市地理模拟
张锐豪1,2, 赵耀龙1,2*, 吴智刚3, 罗文斐1,2
(1.华南师范大学地理科学学院,广州 510631;2.华南师范大学智慧国土与资源环境研究中心,广州 510631;3.华南师范大学城市与区域发展研究中心,广州 510631)
摘要:针对常用城市地理模拟系统中元胞自动机转换规则获取算法的局限性,提出基于集成学习的元胞自动机,并将其应用于城市建设用地的动态模拟.以决策树作为弱分类器,应用集成学习和元胞自动机,模拟了东莞市2001—2005年的建设用地时空格局.精度评估的结果表明,经集成学习后的决策树比单个决策树对城市建设用地动态的模拟精度更高,算法泛化能力更好.
关键词:集成学习; 元胞自动机; 城市地理模拟; 决策树
城市是一个典型的动态空间复杂系统, 具有自组织性、自相似性、时空动态性和非线性等耗散结构特征[1].元胞自动机在复杂动态系统模拟上具有较强的优势[2],广泛应用于城市地理模拟[3-7],使用元胞自动机所面临的核心问题是元胞转换规则的获取[8-9].国内学者运用决策树[10]、神经网络[11]、支持向量机[12]等单分类算法来确定元胞的转换规则,但这种单分类算法在实际地理模拟中存在一定的局限性,主要表现在:(1)当所选取的训练集中原始样本数据存在噪声且样本容量较小时,通过这些数据所训练出来的元胞类型分类器无疑是有缺陷的,会降低分类的精度[13].(2)单分类算法本身也具有一定的局限性.如神经网络算法,通常采用梯度下降法实现错误率的最小化,由于训练方法的原因,算法容易陷入局部最优,同时算法的收敛速度较慢,需花费大量的时间[14];支持向量机算法则受参数设置的影响很大[12]845.
利用数据挖掘技术(如决策树)来完成元胞转换规则的获取是一种比较有效的方法.决策树是常用的数据挖掘算法,也是重要的机器学习算法,常用ID3、C4.5和CART等算法生成.决策树较于传统的启发式算法或智能算法,省去了繁琐的数学模型拟合与计算,大大提高了建模效率[10]872,但也存在局限性:(1)当参与决策的结点或变量增多时,决策树的错误率将会随之上升[15]10.(2)当用以训练的数据带有噪声或缺乏代表性时,会导致决策树过拟合,增加决策树误判率[15]10以及“树”本身过于庞大,失去了规则明确、易于理解的优点.此时要对决策树进行剪枝的操作,但若对剪枝率控制不好则易增加误判率.
针对元胞转换规则获取算法中存在的上述局限性,本文尝试以决策树算法作为弱分类器,引入集成学习(Ensemble Learning)的方法,突破决策树获取元胞转换规则挖掘的局限性,提高城市地理模拟结果的精度.
1集成学习与弱分类器
集成学习是机器学习领域中一个重要的热门研究方向,其核心思想是利用多个相同的学习器或弱分类器针对同一个问题进行学习,例如所有的学习器或弱分类器都是决策树或神经网络等.因为集成学习采用多个弱分类器的组合,因此可以获得比仅使用单一学习器更强的泛化能力[16].
根据对样本数据集处理方式的不同,常用的集成学习算法有Bagging、Boostig和随机森林等3种(图1)[16].本文以这3种算法及其相应的弱分类器决策树为基础,对应用集成学习算法和单个弱分类器进行城市地理模拟的结果精度进行对比分析.

图1 集成学习算法分类
1.1Bagging算法
Bagging 算法旨在通过对原数据进行多次Bootstrap抽样,通过抽样得到的多个训练集对弱分类器进行训练.然后,再将未知样本代入已训练好的弱分类器,得到相应的分类结果,取分类结果中频数最高的类别作为执行算法所得到的分类类别.与Boosting算法比较,由于Bagging算法的训练集之间不存在强的依赖关系,所以其所集成的弱分类器也不具有相关关系,使Bagging算法并行生成,而Boosting算法需串行生成[17].本文的实验采用经典的Bagging算法进行城市地理模拟.
1.2Boosting算法
Boosting算法跟Bagging算法的差异主要体现在训练集的获取上.Bagging算法主要通过对原数据集进行反复的bootstrap抽样,各训练集之间不相关,而Boosting算法抽样则依赖于前一次训练所带来的样本权重的调整,要求增加分类错误样本的权重,以便再次执行迭代这些分类错误的样本被再次训练,提高对其判别的正确率.因为原始Boosting算法要求在集成学习知道弱分类器的泛化下界,这就造成了原始的Boosting算法难以用于解决实际问题.AdaBoosting算法在Boosting算法家族中最具代表性,相较于原始的Boosting算法,其无需获取所集成的弱分类器的先验信息,因而可更好地应用于解决实际问题.近期,LI[18]将基于迁移学习的AdaBoosting算法与Logistic-CA模型结合用于土地利用模拟,取得了比传统模拟方法更好的模拟效果.因此,本文将采用AdaBoosting算法来完成相关的训练与模拟.
1.3随机森林算法
随机森林算法是一种新的机器学习算法,由Bagging集成学习理论与随机子空间方法相结合[19].随机森林算法与Bagging算法、Boosting算法的不同之处在于:使用训练集完成子决策树的创建时,需要先随机在训练集所包含的M个属性中选出m个属性,按照结点的不纯洁度最小原则选出一个最佳属性进行分裂,并以CART算法完成整棵树的生长,一般不用进行剪枝过程.其中对于m值的选取,一般有2种方法[20]:
(1)直接取m=1;
(2)取m=int[((lnM)/(ln 2))+1].
这2种方法的取值绝对误差不会大于1%.为了取值方便,在保证精度的前提下,本文取m=1.
影响随机森林分类性能的主要因素有森林中各棵决策树精度与森林中各棵决策树的相关性.随机森林中单棵决策树的分类精度越高,则随机森林的分类精度也就越高.而随机森林中各棵决策树之间的相关性越弱,随机森林的分类效果越好.随机森林对包含噪声的数据有较好的鲁棒性,也能较好地克服过拟合问题.同时,对于参与分类且包含很多变量或属性的数据也具有良好的可拓展性与并行性[21].
2基于集成学习的元胞自动机
2.1技术路线
应用地理模拟系统对城市动态进行模拟时,通常将研究区域内下一阶段元胞的变换状态分为2类:转变为建设用地或保持原地类(不转换).本集成模型将这2种变换状态作为分类器的分类结果,各影响因子作为输入参数.输入各影响因子的图层到相应的分类器,以此获得下一阶段元胞转换后的状态图,再进行元胞运算即可得到模拟结果(图2).

图2 技术路线图
本文使用CART算法(也称分类回归树算法)来生成决策树,根据Gini指数对树中的非叶子结点进行二叉分割,相比于ID3与C4.5有更好的抗噪声性能[22].
基础数据处理与采集以及模拟结果的可视化主要在ARCGIS软件中完成,而集成学习与决策树的训练以及元胞自动机的模拟及其精度评估由MATLAB完成.各算法模拟结果的精度评估混淆矩阵以及泛化性能评价采用 Holdout 验证方法来完成.Holdout 验证方法的主要思路是将原始数据集划分为两部分,一部分作为分类器的训练数据集,另一部分作为分类器的评估数据集.
2.2数据及数据处理
以广东省东莞市作为地理模拟实验区域,实验数据见表1.

表1 原始数据及来源
引用如下变量作为模型输入参数:
(1)因变量:输出特征变量作为训练时分类器所输出的类别.以东莞市2005年的建设用地图与2001建设用地图做栅格运算.当栅格值为1时,代表该栅格在模拟中转化为建设用地;而当栅格值为0时,代表该栅格没有发生转化.
(2)区域空间变量[10]868,包括:与市中心的距离;与镇中心的距离;与公路的距离;与高速公路的距离;与铁路的距离.
(3)邻域变量:各元胞Moore邻域内已城市化的元胞数量[10]868.
因为原始土地利用现状图的数据量较大,为了加快模拟速度,本文在处理输入变量数据和因变量的数据时,都先用Matlab进行随机抽样选出一部分数据进行算法训练.
应用ARCGIS中Raster Calculator工具对东莞市2001、2005年的建成区与非建成区的二值图层进行计算,获得建设用地的转化图层,以此作为真实分类结果.通过矢量化操作完成东莞市道路、铁路、高速公路、城镇中心、市行政中心要素图层的数字化,借助ARCGIS中的空间分析工具(如Straight Line与Neighborhood Statistics)完成相关距离要素图层的获取与邻域信息要素图层的获取.在Matlab完成训练与模拟过程,而Matlab不支持直接对栅格图层直接操作,所以将各要素图层转成浮点数的FLT文件,再在Matlab里转化为相应的数值向量.
3结果及精度评价
随机森林算法是集成学习的一个研究热点,在实际中运用较多,因此本文将先以随机森林算法代表集成学习与决策树算法的模拟精度进行比较,对集成学习算法与决策树算法的模拟精度作初步的判断,再深入分析3种集成学习算法的模拟结果.实际应用中,对于分类器训练样本量的选取有一定要求.若训练样本过小,受所包含的噪声数据影响,不利于比较算法模拟精度.若训练样本过大,由于决策树有过拟合倾向,导致其对于训练的样本拟合精度很高,而被用来训练的样本在求总体模拟精度会再次被拟合,导致在求总体模拟精度时会出现决策树模拟的总体精度虚高的现象.因此,在模拟时注意训练样本容量选择,同时,为了检验各分类算法的泛化能力,在求模拟结果的精度评估混淆矩阵时对参与训练的样本予以剔除.在模拟东莞2005年的建设用地现状图时,将算法训练样本容量定为50 000,约为参加模拟所用元胞总数的20%[10]868.
对于弱分类器CART决策树的训练和模拟,为了防止过拟合所带来的误差,采用25%的剪枝率[10]868来简化决策树.集成学习算法的迭代次数取为100.分别应用CART算法和集成学习算法得到2005年建设用地模拟结果与实际情况对比(图3). 2类算法模拟结果的精度评价见表2和表3(参考文献[7]162和文献[11]24,对表格中“实际”标注的位置进行了修改). 结合2个算法的城市建设用地模拟结果图与现状图的可视化对比以及模拟的精度评价结果可以看出,随机森林算法的模拟结果精度要优于决策树CART算法的模拟结果,表明集成学习后的模型优于传统决策树模型.
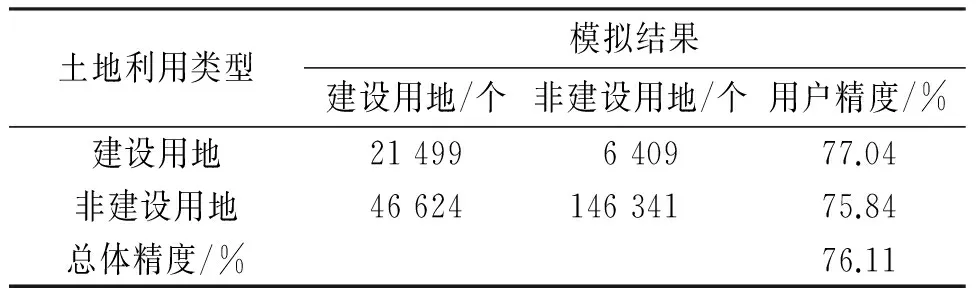
土地利用类型模拟结果建设用地/个非建设用地/个用户精度/%建设用地21499640977.04非建设用地4662414634175.84总体精度/%76.11

表3 2005年随机森林算法模拟精度评估
4讨论
4.1不同集成学习算法的模拟效果
由于不同集成学习算法在构成原理上有差异,应用于实际模拟中的效果存在差异.将随机森林算法所用的训练样本用以训练Bagging 与Boosting算法,进行同样的模拟,获得这2种算法的2005年东莞市城市建成区模拟结果(图4).
由表4和表5可见,3种集成学习算法获得的模拟结果的总体精度均大于决策树模拟的总体精度,整体集成学习算法的模拟效果要优于单个弱分类器的模拟效果,其中随机森林算法的总体精度最高.在建设用地数量方面,根据各算法模拟的精度评价结果,Bagging算法远优于其他3种算法.Boosting

图4 Bagging和Boosting算法模拟结果可视化比较
算法的模拟效果则介于Bagging算法与随机森林算法之间.集成学习算法在模拟中各有优点,在实际应用中应该根据需要选择合适的集成学习算法.
4.2集成学习算法中迭代次数对模拟结果的影响
3种集成学习算法在训练中需要考虑迭代次数选择,也是弱分类器数量的选择.为了确定迭代次数问题,本文在不同的训练样本容量(设为N)下,以迭代次数为自变量、各集成学习算法的模拟精度为因变量,得到模拟精度与迭代次数的关系(图5).

表4 2005年Bagging算法模拟精度评估

表5 2005年Boosting模拟精度评价

图5 各集成学习算法模拟精度与迭代次数的关系
图5表明,当训练样本容量较小且迭代次数也较小时,集成学习算法的模拟精度也较低;保持训练样本容量不变,增大迭代次数,经过约100次的迭代,模拟精度开始趋于稳定,之后继续增加迭代次数,但模拟精度没有显著提高.在训练样本较大的情况下,模拟的总体精度趋于稳定,与迭代次数并无显著的相关关系.因此,当训练样本量足够大时,可以通过减少迭代次数实现减少算法执行时间开销.
迭代次数是影响集成学习算法效率一个很重要的因素.由集成学习构成的原理可知,其执行训练与模拟的过程需要多个弱分类器同时训练与模拟,则决定了集成学习算法的执行时间大大超出单个弱分类算法的时间.因此要优化集成学习算法的效率,可以通过减少不必要的迭代次数来实现.结合以上计算结果,考虑到要减少集成学习算法的时间开销,本文取迭代次数为100.
4.3训练样本容量对模拟结果的影响
为了明确训练样本容量对模拟结果的影响规律,将3种算法在不同训练样本容量下进行训练,各算法模拟的总体精度见图6.分析发现,当训练样本容量较小时,集成学习算法的模拟精度相较于决策树算法有显著的优势.随着训练样本容量的增大,Bagging算法的模拟精度也超过了随机森林算法,这是因为Bagging算法直接对弱分类器进行组合集成,不对训练样本的抽样与弱分类器的生成进行干预,所以其模拟的特性与决策树具有一定的相似性:对于原始的训练样本拟合效果较好.Boosting算法的模拟精度开始低于决策树,同时模拟的精度与训练所用的样本容量并没有显著的相关关系,这说明Boosting算法的一个优点是其对于算法训练样本容量的大小依赖性不强,可以通过采用减少样本训练容量来增强算法的执行效率.随着样本增加,Boosting算法的模拟精度低于决策树算法,原因可能出自决策树的过拟合倾向.因为在计算总体精度时,算法训练所用的样本也被再次运用于模拟,而决策树对于这部分的数据模拟较好导致了其模拟总体精度虚高;同时,Boosting算法着重于对模拟分类错误的对象进行反复训练,噪声样本数据的存在以及在训练中的累积也可能导致最终分类器的分类精度下降.随着训练样本量的增加,Bagging算法与随机森林算法相较于单棵决策树模拟精度始终保持显著的

图6 不同训练样本容量的模拟精度比较
Figure 6Accuracy of simulation in terms of different training sample size
优势,但集成学习的原理决定了执行Bagging算法与随机森林算法的执行时间开销也会相当大,远大于单棵决策树.但考虑到Bagging算法与随机森林算法的算法结构可以并行化处理,所以算法执行效率可以得到优化,有助于算法应用的推广.
5结论
本文以决策树作为集成学习的弱分类器,将随机森林、Bagging、Boosting (AdaBoosting)算法等3个常用的集成学习算法与元胞自动机相结合,以东莞市为例,模拟其2005年建设用地现状.经对模拟结果精度及其泛化能力进行评估、比较,结果表明,决策树算法经过集成学习后,模拟结果的总体精度有较显著的改善,稳定性和泛化能力也有了明显的提升.其中,随机森林算法的模拟总体精度最高,而Bagging 算法则在建设用地数量上的模拟效果最好.Boosting 算法对于训练样本容量的依赖性不强,故而有利于增强算法的执行效率;同时也有不错的泛化能力.在实际的应用中,应根据需要选择合适的集成学习算法.
集成学习也面临着算法执行的时间开销要远大于单个弱分类器,以及如何提高集成学习的效果与如何提高集成学习解决问题的规模等问题.但随着并行计算技术的引入以及相关技术的发展,相信集成学习算法在城市地理模拟领域将会更广泛地应用.另外,本文仅应用混淆矩阵方法对模拟结果进行评估,后续工作中应进一步考虑对建设用地模拟结果的形态进行评价.
参考文献:
[1]刘小平,黎夏,张啸虎,等.人工免疫系统与嵌入规划目标的城市模拟及应用[J].地理学报,2008,63(8): 882-894.
LIU X P, LI X, ZHANG X H, et al. Embedding urban planning objective by integrated artificial immune system and cellular automata[J]. Acta Geographica Sinica, 2008, 63(8): 882-894.
[2]COUCLELIS H.Cellular worlds:a framework for modeling micro-macro dynamics[J].Environment and Planning B, 1985, 17: 585-596.
[3]WHITE R, ENGELEN G. Cellular automata and fractal urban form: a cellular modelling approach to the evolution of urban land-use patters[J]. Environment and Planning A, 1993, 25: 1175-1199.
[4]CLARKE K C, HOPPEN S, GAYDOS L. A self-modifying cellular automaton model of historical urbanization in the San Francisco Bay area[J]. Environment and Planning B, 1997, 24: 247-261.
[5]APOSTOLOS L. Urban sprawl simulation linking macro-scale processes to micro-dynamics through cellular automata, an application in Thessaloniki, Greece[J]. Applied Geography, 2012, 34: 146-160.
[6]龙瀛, 沈振江, 毛其智, 等.基于约束性CA方法的北京城市形态情景分析[J]. 地理学报,2010,65(6): 643-655.
LONG Y, SHEN Z J, MAO Q Z, et al. Form scenario analysis using constrained cellular automata[J]. Acta Geographica Sinica, 2010, 65(6): 643-655.
[7]黎夏, 叶嘉安. 基于神经网络的单元自动机CA及真实和优化的城市模拟[J]. 地理学报,2002,57(2): 159-166.
LIE X,YEH A G-O. Neural-network-based cellular automata for realistic and idealized urban simulation[J]. Acta Geographica Sinica, 2002,57(2): 159-166.
[8]ZHAO Y, MURAYAMA Y. A new method to model neighborhood interaction in cellular automata-based urban geosimulation[J]. Lecture Notes in Computer Science, 2007, 4488: 550-557.
[9]LI X, YEH A G-O. Data mining of cellular automata’s transition rules[J]. International Journal of Geographical Information Science, 2004, 18(8): 723-744.
[10]黎夏, 叶嘉安. 知识发现及地理元胞自动机[J]. 中国科学:D辑, 2004, 34(9): 865-872.
[11]黎夏, 叶嘉安. 基于神经网络的元胞自动机及模拟复杂土地利用系统[J].地理研究, 2005, 24(1): 19-27.
LI X, YIE A G-O. Cellular automata for simulating complex land use systems using neural networks[J]. Geographical Research, 2005, 24(1): 19-27.
[12]杨青生, 黎夏. 基于支持向量机的元胞自动机及土地利用变化模拟[J].遥感学报, 2007, 10(6): 836-846.
YANG Q S, LI X. Cellular automata for simulating land use changes based on support vector machine[J]. Journal of Remote Sensing, 2006, 10(6): 836.
[13]陈沛玲, 决策树分类算法优化研究[D]. 长沙:中南大学, 2007:5.
[14]樊为民. 基于遗传算法的神经网络算法研究[J]. 太原师范学院学报(自然科学版), 2005, 3(4): 14.
[15]季桂树,陈沛玲,宋航.决策树分类算法研究综述[J].科技广场,2007(1):9-12.
JI G S,CHEN P L,SONG H. Study the survey into the decision tree classification algorithms rule[J].Science Mosaic,2007(1):9-12.
[16]张春霞,张讲社.选择性集成学习算法综述[J].计算机学报,2011,34(8):1400.
ZHANG C X,ZHANG J S. A survey of selective ensemble learning algorithms[J]. Chinese Journal of Computers,2011,34(8):1400.
[17]沈学华,周志华,吴建鑫,等.Boosting 和 Bagging 综述[J].计算机工程与应用,2000,36(12):32.
SHEN X H, ZHOU Z H, WU J X, et al. Survey of boosting and bagging[J]. Computer Engineering and Application,2000,36(12):32.
[18]LI X, LIU Y, LIU X, et al. Knowledge transfer and adaptation for land-use simulation with a logistic cellular automaton[J]. International Journal of Geographical Information Science, 2013,27(10):1829-1848.
[19]HO T K. The random subspace method for constructing decision forests[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998,20(8):832-844.
[20]刘艳丽,随机森林综述[D].天津:南开大学,2008:15.
[21]方匡南,吴见彬,朱建平,等.随机森林方法研究综述[J].统计与信息论坛,2012,26(3):34.
[22]丁雍,李小霞.基于Adaboost和CART结合的优化分类算法[J].微型机与应用,2011,30(23):46.
DING Y,LI X X. Optimization of classification based on combination of Adaboost and CART algorithm[J]. Microcomputer & Its Applications,2011,30(23):46.
【中文责编:庄晓琼英文责编:肖菁】
Urban Geosimulation Based on Ensemble Learning and Cellular Automata
ZHANG Ruihao1,2, ZHAO Yaolong1,2*, WU Zhigang3, LUO Wenfei1,2
(1. School of Geography, South China Normal University, Guangzhou 510631, China;2. Center for Smart Land and Environmental Research, South China Normal University, Guangzhou 510631, China;3. Center for Regional and Urban Development Research, South China Normal University, Guangzhou 510631, China)
Abstract:In order to alleviate the limitation of obtaining transformation rules in GIS using cellular automata, a cellular automata based on ensemble learning is proposed for simulating urban dynamic geosimulation. Decision tree is used as weak classifier in the ensemble learning and cellular automata to simulate the urban spatio-temporal dynamics in Dongguan from 2001 to 2005. The accuracy results show that the simulation of ensemble learning is better than using decision tree alone for urban dynamic geosimulation. The new method can obtain better generalization ability.
Key words:ensemble learning; cellular automata; urban geosimulation; decision tree
收稿日期:2014-11-05《华南师范大学学报(自然科学版)》网址:http://journal.scnu.edu.cn/n
基金项目:“十二五”国家科技支撑计划课题(2012BAJ22B06)
*通讯作者:赵耀龙,教授, Email: yaolong@scnu.edu.cn.
中图分类号:P209;TU984
文献标志码:A
文章编号:1000-5463(2016)01-0101-07
