改进的随机森林算法在乳腺肿瘤诊断中的应用
2016-05-09单文英
王 平 单文英
改进的随机森林算法在乳腺肿瘤诊断中的应用
王 平 单文英
(南昌大学信息工程学院 江西 南昌 330031)
为了解决乳腺肿瘤诊断中误差代价敏感的不平衡分类问题,提出一种改进的随机森林算法的乳腺肿瘤诊断模型。首先,在随机森林算法的基础上,将良恶乳腺肿瘤样本的诊断性能分开考虑,利用随机森林的泛化误差上界相关因素推导出ROC曲线的查全率(TPR)和误警率(FPR)的上界值。给出针对特定类别优化分类性能的基准,绘制出不同决策阈值下的TPR和FPR值的ROC曲线,调整平均关联度,再次训练,依据ROC曲线性能,确定最优平均关联度的诊断模型。最后,将该改进的随机森林算法与传统方法的诊断性能进行对比。实验结果证明,提出的方法模型在保证整体的诊断性能的前提下,对于提高恶性肿瘤的识别能力具有可行性和有效性。
乳腺肿瘤 诊断 代价敏感 不平衡分类 随机森林 ROC曲线
0 引 言
近30年来,我国乳腺癌的发病率每年以3%的速度增长,而且发病的群体呈年轻化,形势不容乐观[1]。其中,乳腺癌就是妇女常见的、发病率最高的、危害健康最大的一种乳腺肿瘤。然而,提高恶性乳腺肿瘤的治愈率关键在于早期诊断与治疗。近年来,利用数据挖掘技术辅助医疗诊断的研究正在发展。因此,对于数据挖掘方法的乳腺肿瘤诊断研究也就应运而生[2]。
目前,已经有学者将决策树[3]、神经网络[4]和支持向量机[5]等方法应用于乳腺肿瘤的诊断研究中。这些方法主要集中在研究如何提高整体的诊断率,但是恶性肿瘤样本总是相对少数的,提高整体的诊断率不一定是最好的方法模型,容易出现过拟合,分类不平衡现象。一旦建立好了模型,很难再调整分类器的性能,更无法考虑误差代价敏感问题。针对代价敏感问题,阮晓宏等人[6]提出了一种基于异构代价敏感决策树分类算法,考虑了不同代价在属性分裂中的作用,提出代价敏感的剪枝方法,解决信息特征值过小而忽视的属性带来的误分类代价问题。但是,单一决策树的本身缺陷,诊断率还是比较低,稳定性差。Wang等人[7]提出了一种重采样的方法改变原训练样本的分布,降低分类的不平衡性。ThaiNghe等人[8]以支持向量机作为基分类器,赋予稀有样本更大的权重,引入代价敏感思想优化分类器的性能,降低分类的不平衡性,但是泛化能力弱。
很明显上述的传统方法及其改进方法都是针对单一分类器,然而,集成分类器在很多情况下要比单一分类器的效果更好。随机森林,作为一种由多个决策树组成的集成分类器,它的每棵决策树实质上是通过引入了Bagging思想随机化训练样本构建出的一个的弱分类器。但是,当多个弱分类器组合在一起形成随机“森林”时分类效果非常惊人。具体表现为:高效率,在短时间内可以并行地处理大量的待测样本;良好的鲁棒性,无需特征选择就可以得到较高的确诊率,适合高维小样本数据;不容易出现过拟合;良好的推广和泛化能力等优势[9,10]。近年来,随机森林在网页分类、故障诊断、入侵检测等领域都得到了应用,已经成为数据挖掘和机器学习的热点[11]。但是,随机森林算法也存在一些缺陷,没有针对误差代价不平衡问题进行考虑,其简单的相对多数投票法有个致命的缺陷就是在两类的投票结果非常相近时,误诊的可能性比较大。对此,Chen等人[12]提出了平衡随机森林和加权随机森林两种方法解决不平衡分类问题。平衡随机森林采用上采样法,增加稀有类的数据,使得训练数据达到平衡,这种改变正负类样本的分布方式必将影响到“森林”中树的结构。而加权随机森林方法是在平衡随机森林的基础上得到的,为稀有类增加权重,该方法对噪声数据较敏感。以上对随机森林的改进方法在一定程度上具有很好的分类效果,无疑也增加了算法的复杂度,有违随机森林简化问题的初衷。如何评价某种分类模型的性能,简单地通过正确率和错误率已经不足够评价不平衡分类问题,对于具体问题还要具体分析。由于ROC曲线评价法具有简单、直观、对于分类的界限值不固定、可以完成不同实验在同一个坐标下的比较等优点。Joshi[13]等人指出针对不同类别的误差代价不同,使用ROC曲线评价分类器的性能更适合。倪俊[14]等人提出了使用ROC曲线分析常用的乳腺癌诊断方法性能。所以,ROC曲线也叫受试者工作特性曲线,是医学诊断性能评价的重要指标。然而,ROC曲线是由查全率(TPR)和误警率(FPR)构成的曲线,故改进随机森林的乳腺肿瘤诊断模型的关键是在阈值点,尽量增大TPR,减小FPR的值。
有鉴于此,对于威斯康辛大学医学院整理的乳腺肿瘤病灶组织的细胞核显微图像的量化特征数据集,其样本数据相对不平衡,但是如果将恶性肿瘤样本错误分为良性肿瘤样本造成的误差代价远远高于将良性肿瘤样本错误分为恶性肿瘤样本的误差代价。故针对乳腺肿瘤误差代价敏感问题,提出了一种改进的随机森林算法的乳腺肿瘤诊断模型。首先,在CART算法、Bagging算法的基础上,产生了随机森林算法,分析随机森林的决策树棵树和随机分裂属性的个数对诊断性能的影响。其次,考虑单分类器的分类性能及他们之间的关联度对特定类别的识别影响。对随机森林的投票评价性能的指标进行了推导及改进,简化算法的复杂度,达到参数可调,并给出优化分类器性能的调整基准,提高对恶性肿瘤的识别能力。
1 Bagging算法
1.1 CART算法
CART模型最早是由Breiman等人提出的,采用递归的方式将输入空间分割成矩形,使用Gini指标[15]最小的属性作为分裂节点,最终以二叉树的形式展现。这种方法构建的决策树清晰、直观、易于理解,而且大大减少了建模的时间。但是,由于CART树在递归的过程中,需要对其进行剪枝,无疑增加了算法的复杂度,由于过度分割输入空间,易出现过拟合现象,导致分类器具有泛化能力弱,稳定性差等缺陷。Breiman指出CART算法由于其不稳定性,通过集成得到的集成分类器可以显著提高分类器的性能。
1.2 Bagging算法

Bagging的算法流程如下:
1) 采用Bootstrap方法进行重采样,随机产生k个训练集S1,S2,…,Sk,这里构造不同的训练集目的是为了增加分类模型间的差异,提高组合分类模型的外推预测能力。
2) 利用每个训练集并行地生成对应的CART算法的决策树C1,C2,…,Ck。
3) 利用测试集样本X对每个决策树进行测试,得到对应分类结果C1(X),C2(X),…,Ck(X)。
4) 采用相对多数投票法,根据k个决策树输出的类别结果,由决策树棵数多的类别作为测试集样本X所属的分类结果。
Bagging算法基本思路如图1所示。

图1 Bagging算法基本思路
2 随机森林算法(RFA)
随机森林算法是由Breiman提出的一种统计学习理论[17]。实质上是一个包含多个决策树{h(X,θk),k=1,2,…,K}的组合分类器,其中{θk}是随机向量,服从独立同分布的特性,决定了决策树的形式;K表示随机森林中决策树棵树。它主要利用Bagging方法产生Bootstrap训练数据集,利用CART算法产生无剪枝的决策树。最终采用简单的相对多数的投票方式,根据决策票数H(x)多的类别作为最终样本所属类别。
(1)
2.1 随机森林的算法流程
在Bagging算法基础上得到的随机森林算法的具体流程如下:
1) 原训练集中有n个样本,采用Bootstrap方法进行重采样,随机产生k个训练集S1,S2,…,Sk。
2) 对于每个训练样本集,通过如下过程生成不剪枝CART树:
(1) 假设训练样本的属性个数为M,mtry为大于零且小于M的整数,从M个属性中随机抽取mtry个属性作为当前节点的分裂属性集,在森林生成过程中,保持mtry不变。
(2) 根据Gini指标从mtry个属性中选出最好的分裂方式对该节点进行分裂。
(3) 每棵树都完全成长,无剪枝的过程。最后根据每个训练集生成的CART树分别为C1,C2,…,Ck。
3) 利用测试集样本X对每个决策树进行测试,得到对应分类结果C1(X),C2(X),…,Ck(X)。
4) 采用相对多数投票法,根据k个决策树输出的类别结果,由决策树棵数多的类别作为测试集样本X所属的分类结果。
2.2 随机森林的收敛性
为构造k棵决策树,则由相互独立且同分布的随机向量C1,C2,…,Ck构成的分类器为h(x,Ci),简记为hi(x)。假设输入向量为x,输出类别为y,定义样本点为(x,y)的余量函数为:
(2)
式中I(·)为示性函数,当函数I(·)的括号中等式成立时,其值为1,否则为0;avk表示取平均值。
此余量函数用于评估平均正确分类数超过平均错误分类的程度,该值越大,分类结果的可靠性越强。
设随机森林的泛化误差为PE*[17]:
PE*=Px,y(mg(x,y)<0)
(3)
在随机森林中,如果决策树的个数足够多时,式(2)遵循强大数定理。
定义1 在随机森林中,随着决策树的数目增加,所有序列为θ1,θ2,…,θk,PE*几乎处处收敛于随机森林的边界函数:
(4)
定义1表明随着决策树的增加,随机森林不会产生过拟合现象。但是可能会产生适度范围内的泛化误差。随机森林中决策树的数量是个可调的参数,对于随机森林分类器的性能具有一定的影响。如果建立的决策树的个数不足,则模型得不到充分训练,分类器性能就会下降;如果建立的决策树个数过多,不仅增加了计算量和训练时间,而且达不到提高分类性能的目的。
定义2 基分类器的边界函数为:
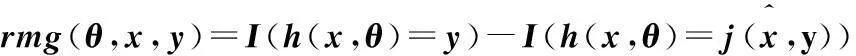
(5)
定义3 随机森林的泛化误差PE*范围:

(6)
Eθvar(θ)≤Eθ(Ex,yrmg(θ,x,y))2-s2≤1-s2
(7)

由定义3可得降低泛化误差的上界的关键是提高树的分类性能和降低树之间的相关度,进而提高了随机森林的分类性能。
2.3 改进的随机森林算法(IRFA)
Breiman提出的随机森林算法的泛化误差范围是假设决策阈值固定,分类误差代价相同的情况下得出的,并没有对分类误差代价不同的情况进行分析。针对二分类问题,可以将正负样本分开对待,在随机森林算法的基础上,优化分类器性能,改进随机森林算法。讨论不同决策阈值下,树之间的平均相关度,树的分类性能s对不同误差代价区域的分类性能的影响,并给出改进随机森林算法的基准。
对于二分类问题的性能评价指标有如表1的分类情况。

表1 二分类情况表
根据表1可定义如下式子评估分类器性能。
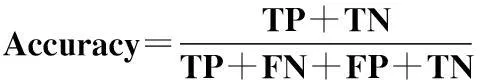
(8)
其中,Accuracy表示整体分类的准确率;TPR表示所有1类样本中正确分类率,简称为查全率;FPR表示所有0类样本中错误分类率,简称为误警率。
针对二分类的余量函数mg(x,y)可以表示为:
(9)
则在此改进的随机森林算法中,当输入样本为x时,不仅仅通过简单的相对多数票数的H(x)进行投票,而且通过如下评分函数进行控制评估多个投票结果:
(10)
其中,K为决策树的总数目,为了防止评分结果相同,通常K取奇数。hk(x)为第k个决策树所投票的类别。显然,评分函数的值域为[-1,1],且直接与上述随机森林的余量函数有关。将正负样本分开对待,当样本类属于1类,即y=1时,评分函数值和边缘数值相等,即score(x)=mg(x,y);当样本类属于0类,即y=0时,评分函数值和边缘数值相反,即score(x)=-mg(x,y)。评分函数是根据中心极限原理,在一定条件可以渐近服从正态分布。如图2表示在不同类别下的评分函数图。
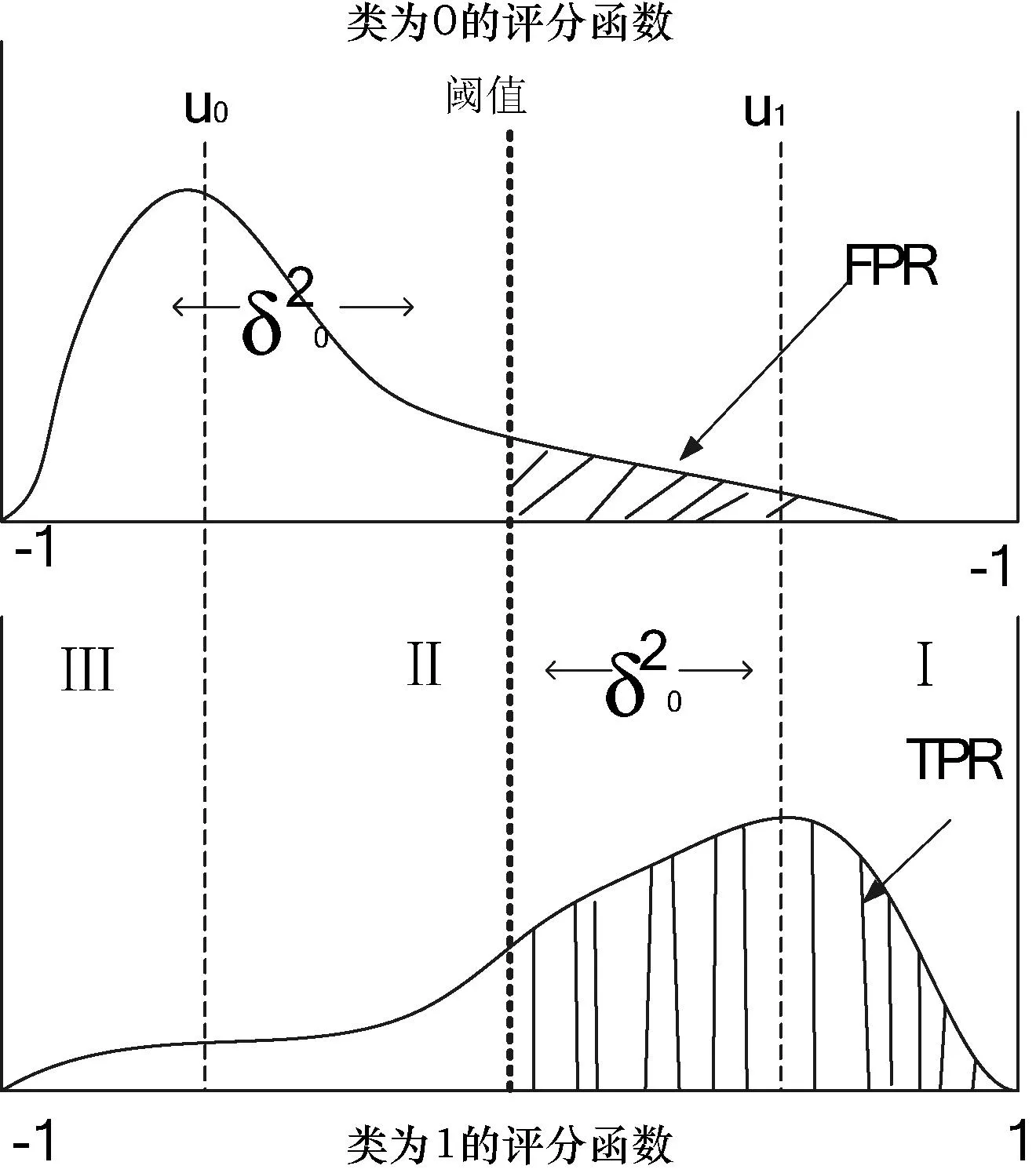
图2 不同类别的评分函数
如图2所示,根据评分函数的分布,正负样本分开考虑后的u0和u1将该评分曲线分为三个区域。设置一个阈值t,将评分曲线分成两部分,最大化TPR的同时还要考虑相对FPR的最小化,找到合适的阈值点是实验的关键。随着阈值的变化,通过扫描,将不同阈值t下分类器的TPR(纵坐标)和FPR(横坐标)的值映射到随机森林的ROC曲线上(如图3所示)。
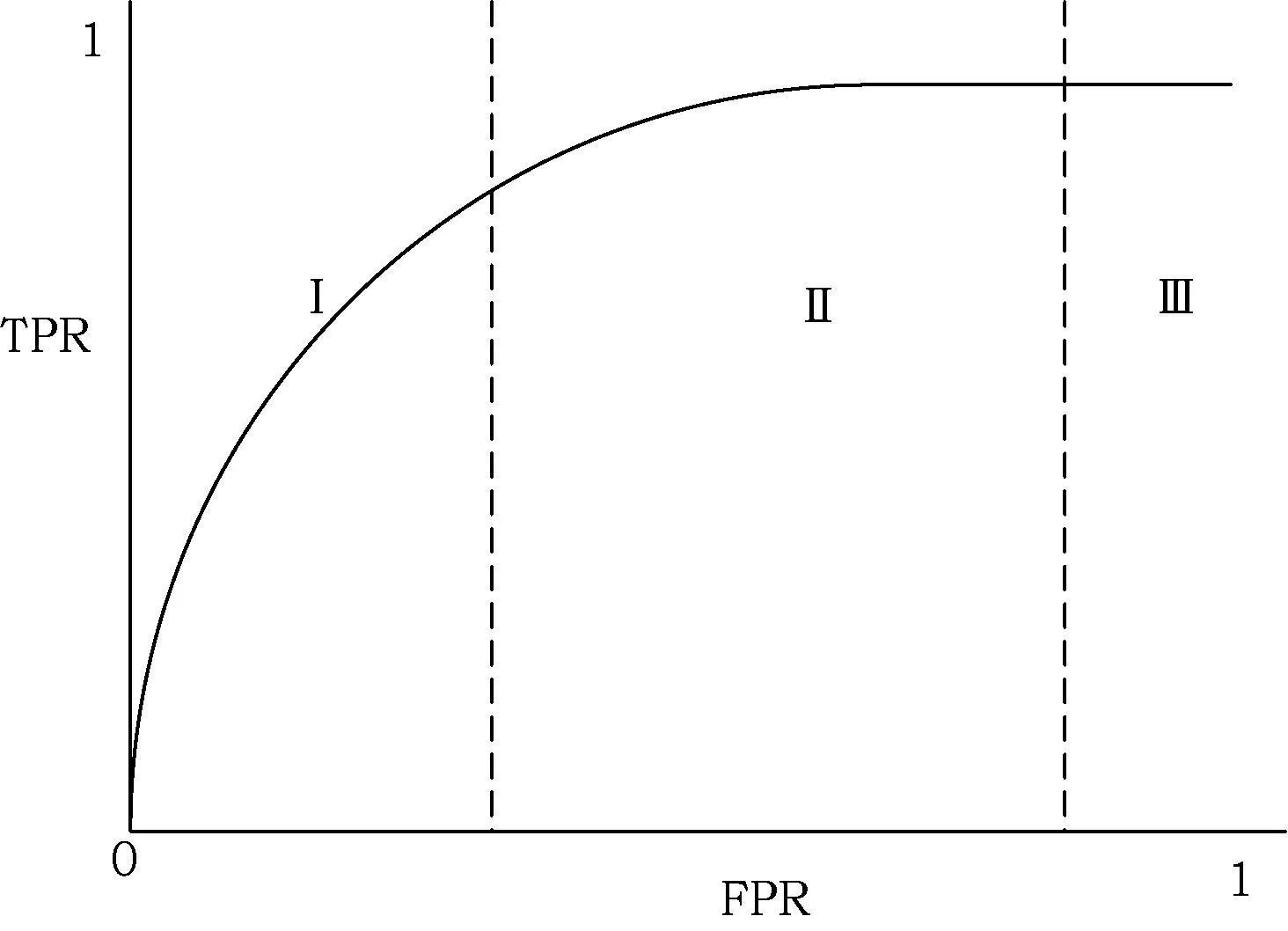
图3 ROC曲线的性能
基于评分函数与边界函数的关系,这里设不同类别的分类性能分别为s0和s1。
(11)
其中,ui为类i的评分函数的期望;ni为类i的样本个数。由上式可知,这里将分类器的整体分类的性能s设为不同类别的分类性能的加权平均。
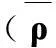
(12)
则针对正负样本有:
(13)
(14)
在构建ROC曲线的过程中,在给定阈值t下,TPR表示所有1类样本的正确率,即1类评分函数构成的评分分布曲线中超过阈值t的区域;FPR表示所有0类样本的错误率,即0类评分函数构成的评分分布曲线中超过阈值t的区域(如图2所示的阴影部分)。分别可表示为:
FPR=P(Z0≥t) TPR=P(Z1≥t)
(15)
其中,Z0和Z1分别表示0类和1类评分分布函数的变量。
利用单边切比雪夫不等式来设置式(15)中FPR和TPR的上界值。单边切比雪夫不等式为:
(16)
其中,u、σ2分别为变量Z的均值和方差。假设t=k+u,则式(16)可表示为:
(17)
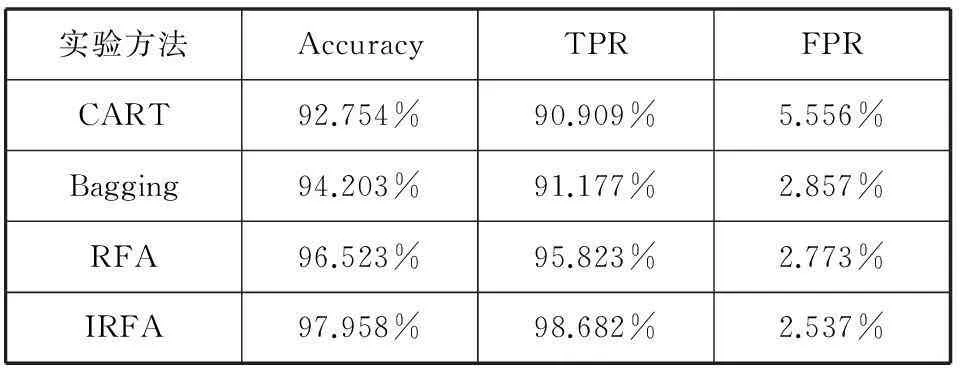
使用1同时减去式(17)的两边,得t (18) 当t∈[u0,1]由式(11)、式(12)、式(15)和式(17)可推得: (19) 在评分函数中,u0和u1将区间[-1,1]分为三个区间[-1,u0]、[u0,u1]和[u1,1]这3个子区间,根据式(12)、式(15)和式(17)设定知阈值t所属的区间是不同,则对应区间[-1,-s0]、[-s0,s1]和[s1,1]中FPR和TPR的上界和下界。如表2所示。 表2 ROC曲线的三个区域内FPR和TPR界限 乳腺肿瘤的诊断问题也就是一个二分类问题。本文的乳腺肿瘤诊断的数据集来源于威斯康辛大学医学院整理的量化特征数据集,包含569个病例,其中,良性乳腺肿瘤357例,恶性乳腺肿瘤212例。数据集中包含乳腺肿瘤的细胞核图像的10个属性(细胞核半径、质地、周长、面积、光滑性、紧密度、凹陷度、凹陷点数、对称度、断裂度)。而且每个属性包含3个属性值(平均值、标准差和最坏值),共有30个字段。另外,还有1个字段为病例编号,最后1个字段是确诊分类结果,其中数字“0”为良性,数字“1”为恶性。该数据库中各个量化特征与肿瘤性质都具有密切的联系,从而根据细胞核显微图像的量化特征利用数据挖掘的技术可以智能的诊断乳腺肿瘤是良性还是恶性的。 该实验的硬件环境是Windows7系统,i5-3230M CPU, 4 GB RAM,500 GB硬盘,算法运行的软件环境为MATLAB 2010版本。根据以上推导得分类决策的评分函数为: (20) 由评分函数分布图(见图2)和上节推导过程可知,如果单分类器的分类性能一定时,调整相应类别的平均相关度时,可以改变评分函数的分布,进而改变FPR和TPR的上界值。这里给出不同区域的平均关联度的调整基准(如表3所示): 表3 不同区域的平均关联度的调整基准 基于改进的随机森林算法实现步骤: Step1 采集数据。采用Bootstrap方法随机化乳腺肿瘤训练集S1,S2,…,Sk,将袋外数据(OOB)作为测试集T。 Step2 模型训练。设置参数:决策树棵树k,随机选择属性的个数mtry。 ① 训练集Sk含有M个属性,随机抽取mtry个属性作为当前节点的分裂属性集,形成新的训练集Sn。② 利用CART算法训练数据集Sn构建决策树,完全成长不进行剪枝。 Step3 循环k次以上Step1和Step2步骤,构建k棵决策树,得到一个随机森林模型。 Step4 预测仿真。① 对测试集T每个样本X进行预测仿真,k棵决策树得到k个决策类别结果。② 计算评分函数score,根据评分结果得到最后样本X所属类别。 Step5 建立100个随机森林模型,计算当前设置参数的随机森林模型的平均值Accuracy、FPR和TPR的值,确定最佳k和mtry的值。 Step6 通过调用[tpr, fpr, t]=ROC(score, target, Lp, Ln)函数,分析不同阈值t的分类器的性能影响,绘制ROC曲线。根据仿真实验对比表3的参考基准,调整不同区域的平均关联度,再次重复以上步骤。 为了验证改进算法的可行性,将实验分为两组:第一组是UCI标准数据集上的实验;第二组是详细分析IRFA在威斯康辛大学医学院整理的乳腺癌数据集上的实验应用。 4.1 UCI数据集的实验分析 为了测试改进的算法的性能,首先选择UCI带标签的二类数据集进行实验,而且选择样本数分布严重不平衡和相对不平衡各两组数据集。四组数据集分布如表4所示。 表4 选择的UCI数据集样本分布 将上述数据集运用于RFA和IRFA的模型中进行验证,最终得到的ROC曲线结果如图4所示。 由图4的实验结果可得,IRFA相对RFA模型的分类性能明显有所提高。样本分布的不平衡性越高,可提高的幅度也就越大,虽然在负类样本与正类样本的不平衡比较低的情况下,TPR的值提高幅度较小,稳定性强,但是在靠近左上角的阈值点处,IRFA算法的TPR值都得到了很大提高,这也就为最大化正类样本的识别率提供了突破点。 图4 UCI数据集在IRFA和RFA模型中的ROC曲线 4.2 乳腺肿瘤数据集的应用实验结果详细分析 通过在UCI数据集上的验证,对此详细分析改进的随机森林算法IRFA在本文的乳腺肿瘤数据集上的实验,首先,分析建立决策树的数目。这里设置决策树的数目分别为51、75、101、151、201、251、301,得到不同的随机森林模型。为了减少随机性对随机森林的性能的影响,针对不同决策树棵树,建立100个随机森林模型,然后取其平均值,作为当前的分类结果。经过多次训练,得到不同决策树数目下的随机森林模型的整体分类的准确率(Accuracy)、查全率(TPR)和误警率(FPR)。记录的实验结果如表5所示。 表5 决策树数目对随机森林分类的性能影响 由表5可得,当决策树小于201时,随着决策树棵树的增加,Accuracy和TPR的值也在增大,而FPR的值在降低。当决策树大于201时,随着决策树的数目增加,Accuracy的值保持不变,但是TPR和FPR的值一直在变化,当决策树等于201时,Accuracy和TPR的值达到最大,而且FPR值也相对较小。很明显,在随机森林的训练中,这里选择决策树的数目为201棵。 随机选择属性数量的分析:对于“森林”中的CART树,一个重要特点是通过在每个分裂节点随机选择属性的方式引入了随机性,从M个属性中随机抽取mtry个属性作为当前节点的分裂属性集。为了评价分裂属性集的属性个数对分类性能的影响,在随机森林中的决策树数目为201时,设置不同的mtry值分别为2、3、4、5、6进行训练,构建随机森林模型。表6记录了不同mtry所得到的Accuracy、TPR和FPR的值。 表6 分裂属性的个数mtry对分类性能影响 由表6可得,mtry=5时,Accuracy和TPR的值都达到最大,故这里选取mtry为5。 ROC曲线的分析:根据以上得到的结果,选择决策树数目为201,mtry为5。针对本文的乳腺肿瘤的诊断要求,改进随机森林算法,由评分函数阈值的取值范围为[-1,1],分别将决策阈值设置为1、0.8、0.7、0.5、0、-0.5、-0.8、-1。在不同阈值下,对随机森林进行训练,得出分类结果的Accuracy、TPR和FPR的值,并将得到的TPR和FPR的值绘制成ROC曲线(如图5所示)。 图5 ROC曲线 由图5所得的八个点从左到右分别表示在决策阈值t为1、0.8、0.7、0.5、0、-0.5、-0.8、-1的情况下,所得的TPR和FPR的值。随着决策阈值t的减小,TPR和FPR的值都在增大,当t=0.5之后,TPR的值相差不大,几乎可以认为保持不变,但是FPR却一直在增加。根据ROC曲线原理,越靠近左上角的点,分类性能越好,此时也就是最好的阈值点。故根据实验结果应选择t=0.5。此时,在满足TPR最大时,FPR相对也比较小。 此时,RFA选择的决策树数目为201,mtry为5,决策阈值t为0.5。根据表3的基准调整RFA相应的平均关联度,得到的改进随机森林算法(IRFA)用于再次训练。在同样条件下,利用单一分类器(CART决策树)、Bagging算法和随机森林(RFA)算法训练乳腺肿瘤数据集,得到的方法模型进行比较分析,统计Accuracy、FPR和TPR的值(如表7所示)。 表7 不同乳腺肿瘤的诊断方法的性能比较 根据表7记录的实验结果可得,随机森林算法相对上述的单一分类器(CART决策树)及Bagging算法的诊断效果明显要更好。在RFA的基础上,IRFA整体诊断精度也略有提高,虽然提高的幅度不大,但是相对RFA,IRFA得到了较高的TPR值,而且提高了2.853%。实验表明,在保证整体诊断精度的前提下,IRFA明显提高了对恶性肿瘤的诊断精度。最后,为了更加直观地说明IRFA在RFA的基础上具有更好的诊断性能,将两种方法的ROC曲线绘制在一个坐标进行比较(如图6所示)。 图6 IRFA与RFA的ROC曲线 本文综合考虑随机森林的决策树棵树和随机分裂属性的个数对乳腺肿瘤的诊断性能的影响,在随机森林的基础上,将正负类样本分开考虑,提出了改进的随机森林算法的乳腺肿瘤诊断模型。增加了决策阈值的参数,根据随机森林的泛化误差推导出了FPR和TPR的上界调整基准,绘制ROC曲线,进一步优化随机森林对恶性肿瘤的诊断性能。仿真结果证明了该方法模型相对随机森林算法有所改进,最重要的是根据需要,参数可调。在保证整体的诊断性能的前提下,针对代价敏感问题,可以优化特定类别样本的识别性能,为细胞核显微图像诊断识别乳腺肿瘤提供重要参考价值。 [1] Xu Guangwei,Hu Yongsheng,Kan Xiu.The preliminary report of breast cancer screening for 100000 women in China[J].China Cancer,2010,19(9):565-568. [2] Chaurasia V,Pal S.Data Mining Techniques:To Predict and Resolve Breast Cancer Survivability[J].International Journal of Computer Science and Mobile Computing,2014,3(1):10-22. [3] 毛利锋,瞿海斌.一种基于决策树的乳腺癌计算机辅助诊断新方法[J].江南大学学报:自然科学版,2004,3(3):227-229. [4] 金强,髙普中.人工神经网络在乳腺癌诊断中的应用[J].计算机仿真,2011,28(6):235-238. [5] 章永来,史海波,尚文利,等.面向乳腺癌辅助诊断的改进支持向量机方法[J].计算机应用研究,2013,30(8):2373-2376. [6] 阮晓宏,黄小猛,袁鼎荣,等.基于异构代价敏感决策树的分类器算法[J].计算机科学,2013,40(11A):140-142. [7] Wang T,Qin Z,Zhang S,et al.Cost-sensitive classifycation with inadequate labeled data[J].Information Systems,2012,37(5):508-516. [8] ThaiNghe N,Gantner Z,SchmidtThieme L.Cost-sensitive learning methods for imbalanced data[C]//Neural Networks (IJCNN),The 2010 International Joint Conference on.IEEE,2010:1-8. [9] 方匡南,吴见彬,朱建平,等.随机森林方法研究综述[J].统计与信息论坛,2012,26(3):32-38. [10] Kulkarni V Y,Sinha P K.Random Forest Classifiers:A Survey and Future Research Directions[J].Int Journal of Advanced Computing,2013,36(1):1144-1153. [11] Verikas A,Gelzinis A,Bacauskiene M.Mining data with random forests:A survey and results of new tests[J].Pattern Recognition,2011,44(2):330-349. [12] Chen C,Liaw A,Breiman L.Using random forest to learn imbalanced data[R].University of California,Berkeley,2004. [13] Joshi M V.On evaluating performance of classifiers for rare classes[C]//Data Mining,2002.ICDM 2003.Procedings.2002 IEEE International Conference on.IEEE,2002:641-644. [14] 倪俊,顾海峰,张杏梅,等.乳腺癌常用诊断方法的ROC曲线分析[J].中华肿瘤防治杂志,2012,19(13):1025-1028. [15] 宋丽.基于决策树的组合分类器的研究[D].西安:西安电子科技大学,2012. [16] Breiman L.Bagging predictors[J].Machine learning,1996,24(2):123-140. [17] Breiman L.Random forests[J].Machine learning,2001,45(1):5-32. APPLICATION OF IMPROVED RANDOM FOREST ALGORITHM IN BREAST TUMOUR DIAGNOSIS Wang Ping Shan Wenying (SchoolofInformationEngineering,NanchangUniversity,Nanchang330031,Jiangxi,China) To solve the problem of cost-sensitive imbalanced classification in breast tumour diagnosis, the paper proposes a breast tumour diagnosis model using the improved random forest algorithm. First, on the basis of random forest algorithm, we separately dealt with the diagnosis performances of benign and malignant breast tumour samples, made use of the corresponding factor of upper bound of random forests generalisation errors to deduce the upper bounds of recall rate (or TPR) and false alarm rate (or FPR) of ROC curve, then we gave the benchmark of optimising classification performance for specific categories, and drew the ROC curves with TPR and FPR values gained in different decision thresholds. After that we adjusted the average correlation and train the model again, and according to ROC curve performance we determined the diagnosis model with optimal average correlation. Finally, we compared the improved random forest algorithm with traditional methods in terms of diagnosis performance. Experimental results showed that the proposed model has the feasibility and effectiveness in improving the recognition ability of malignant tumour while keeping up with the overall diagnostic accuracy. Breast tumour Diagnosis Cost-sensitive Imbalanced classification Random forest ROC curve 2014-09-14。江西省教育厅2014年度科学技术研究项目(GJJ14137)。王平,教授,主研领域:模式识别,图像处理。单文英,硕士生。 TP391 A 10.3969/j.issn.1000-386x.2016.04.059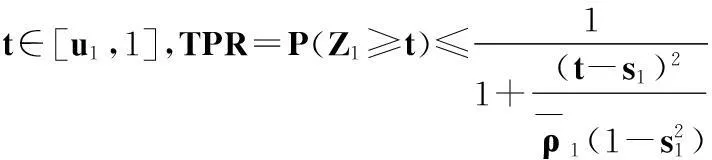


3 构建IRFA的乳腺肿瘤诊断模型


4 实验结果及分析





5 结 语
