软件逆向分析过程中的多维图谱抽取方法
2016-05-09蒋烈辉刘铁铭司彬彬朱晓清
井 靖 蒋烈辉, 刘铁铭 司彬彬 曾 韵 朱晓清
软件逆向分析过程中的多维图谱抽取方法
井 靖1蒋烈辉1,2刘铁铭2司彬彬1曾 韵1朱晓清2
1(信息工程大学计算机科学与技术学院 河南 郑州 450000)
2(数学工程与先进计算国家重点实验室 河南 郑州 450000)
由于软件逆向分析过程中产生的结果通常是形式化的符号,且复杂难懂,因此基于软件逆向分析进行代码阅读或漏洞挖掘等工作的效率非常低下。针对这种情况,首先设计多维图谱抽取框架,基于该框架定义多维图谱描述约束(schema),使多维图谱抽取与具体的逆向分析过程之间相互独立;给出逆向分析算法库的构造方式及算法库调用接口,实现基于多维图谱描述的抽象图谱生成;设计基于图形描述语言DOT的抽象图谱转换接口,实现抽象图谱的快速可视化;最后给出多维图谱抽取算法。实验结果表明,采用该方法能有效提高逆向分析过程中生成结果的可读性,大幅提升分析人员代码阅读及漏洞挖掘的工作效率。
多维图谱 抽取 抽象图 DOT接口 可视化
0 引 言
目前比较流行的软件逆向分析算法通常采用基于抽象解释理论的近似逼近技术[1,2]。即依据分析或验证的实际语义,定义具有完备格属性的抽象域,基于抽象解释框架,将被分析的反汇编代码或中间代码上的数据流分析转换为抽象域上的数学运算,并利用抽象域的数学特性迭代求解,最终到达语义不动点从而得到较精确的分析结果。然而这些算法的结果通常是以纯数据或者抽象符号的形式给出,往往晦涩难懂,即便是专业的逆向分析人员,要想从分析结果中发现可执行代码的框架、意图以及漏洞,要花很长的时间,效率非常低下。如果能对各种逆向分析算法进行分类,并按照不同的分析粒度以图谱的形式显示出来,将会大大提高逆向分析人员的工作效率。
比较流行的软件逆向分析工具中(比如IDA、Ollydb、TEMU、Pin等)都或多或少地提供了图表视图的功能,为用户分析代码结构、挖掘漏洞等提供了重要帮助[3-5]。但这些工具通常提供图的维数太少,适用性差,无法为用户自定义的分析算法生成相应的图。因此,如何将软件逆向分析算法进行分类,并将图的生成从具体的逆向分析中独立出来,使其能够灵活地为各种分析结果生成相应的图谱并按照用户的需求打印出来是本文主要研究的内容。
本文首先提出多维图谱抽取框架,给出基于XML[6]的多维图谱描述约束,并在此基础上给出抽象图谱抽取方法。然后设计基于DOT[7]的抽象图转换接口。最后给出图谱抽取示例及相关工作比较。
1 研究基础与内容
从狭义上讲,多维是指由时间轴和空间坐标轴构成的多个独立的时空坐标;从广义上讲,多维是指按照一定的分类规则所划分的不同类别或者不同视角。在本文多维则是指由静态和动态两种分析模式以及不同代码分析粒度构成的多种逆向分析方法(多种逆向分析维度)。而图谱抽取则是指从多维度的逆向分析中提取分析结果,并按照分析人员的需求以自定义图的形式表示出来。
多维图谱抽取在软件逆向分析过程中所处的位置如图1所示。被分析的代码首先经过多源静态反汇编(将基于不同CPU的可执行代码翻译为对应指令集下的汇编代码)或者多架构动态执行引擎(支持不同硬件平台下可执行代码运行的虚拟机)被翻译成汇编代码;然后经过代码语义提升(中间代码生成)将汇编代码转换为统一的中间语言代码;接着基于统一的中间语言代码;进行多维图谱抽取;最后基于多维图谱进行控制结构恢复、数据结构恢复、代码架构恢复、恶意行为分析和漏洞挖掘等高级语义分析。
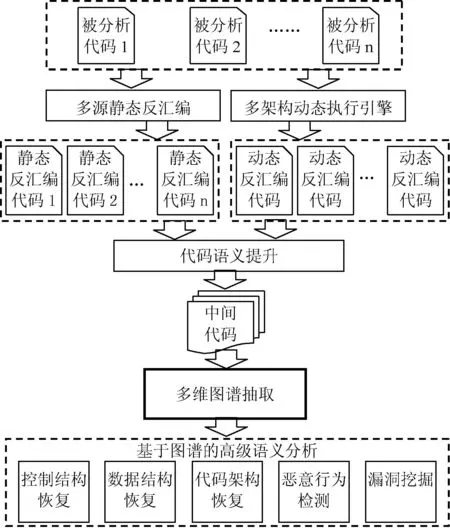
图1 软件逆向分析过程
其中多源静态反汇编已经有很多成熟的工具:比如采用线性扫描算法的BAP[8]、采用递归扫描算法的IDA[9]、采用启发式扫描算法的各种反汇编工具[10]等;基于QEMU虚拟机[11]的多架构动态执行引擎已经被成功用于动态软件逆向分析工作中;代码语义提升也有很多实现方法:比如BAP和BitBlaze[12]的中间代码生成方法、基于语义字典的BRIL中间代码生成[13]等;多维图谱抽取是基于中间代码的分析及结果提取过程,是实现高级语义快速分析的基础,也是本文的主要研究内容。
2 框架设计
多维图谱抽取的框架结构如图2虚线框部分所示。主要由多维图谱描述文件、抽象图谱抽取以及抽象图转换接口三个模块组成。多维图谱描述文件采用基于XML的描述方法,用户可根据具体分析要求,自定义抽取图谱的个数、样式以及采用分析算法的名称等;抽象图谱抽取按照分析代码的粒度分别划分为:语句级、基本块级、结构级以及过程级等(这里的过程级也可以叫做函数级,过程指procedure),负责调用具体逆向分析算法、提取抽象结果以及生成抽象图谱;抽象图谱转换接口负责将生成的抽象图转换为图形描述语言DOT的描述形式,并传递给下层的DOT解析器,最终由DOT解析器将其转换为实际的图形打印在屏幕上。
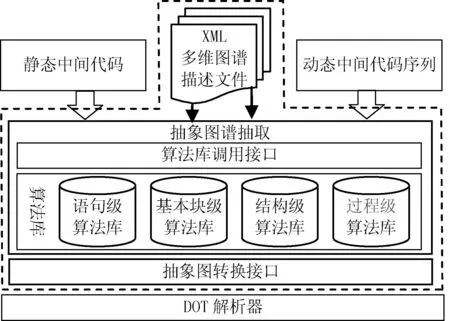
图2 多维图谱抽取框架
3 模块设计
3.1 基于XML的多维图谱描述
XML是一种可扩展的元标记语言,被广泛应用于数据交换、异构系统的整合及系统配置等领域中,独立于任何软硬件平台。为了实现图谱显示与分析算法之间的相互独立性,我们利用基于XML的描述文件对要生成图谱的维数、样式、采用的算法等属性进行描述,并设计了多维图谱描述文件的schema,利用XMLSpy 2011生成的多维图谱描述文件的schema概要图如图3所示。
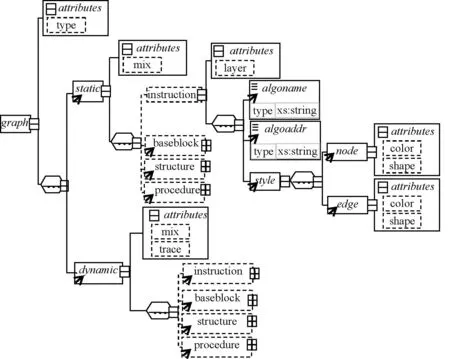
图3 多维图谱描述约束概要图(schema)
其中graph为描述文件的根元素;static和dynamic为graph的子元素,分别用来描述静态图谱和动态图谱的属性;instruction、baseblock、structure和procedure子元素分别用来描述指令级、基本块级、结构级以及过程级图谱的相关属性;algoname、algoaddr、style子元素则用来描述图谱所选用的算法名称、算法地址、显示图谱的样式等;node和edge是style的子元素,color和shape分别用来描述结点和边的颜色以及形状属性。
说明1:图中dynamic元素的结构与static元素的类似,但是比static元素多了一个trace属性,用于指定动态执行的指令序列;
说明2:baseblock、structure和procedure元素的结构与instruction元素的类似,元素右侧的加号表示未展开;
说明3:虚线框的元素或属性表示是可选的,在描述文件中不是必须被定义的。
3.2 基于图谱描述的抽象图谱抽取
按照被分析对象的来源,抽象图谱抽取可划分为静态和动态两大类。静态抽象图谱抽取基于静态反汇编或代码语义提升得到的中间代码,利用传统的前向、后向数据流分析,或者面向某个抽象域的抽象解释框架,对被分析代码进行不同粒度的迭代求解[14,15]。动态抽象图谱抽取基于动态执行引擎(比如pin for x86、Qemu、TEMU for x86、DroidScope for arm[16]等)记录的虚拟执行序列,即指令流或经过代码语义提升的中间代码序列,采用不同粒度的逆向分析算法进行数据流分析。
抽象图谱抽取模块主要由算法库和算法库调用接口两部分构成。算法库由目前已经比较成熟的逆向分析算法构成,按照分析的粒度进行划分,主要包括语句级算法库、基本块算法库、结构级算法库和过程级算法库。算法库调用接口根据图谱描述文件中static元素以及dynamic元素所描述的属性,比如子元素的个数以及每个子元素下algoname以及algoaddr元素描述的算法名称和算法地址等,依次调用对应的算法进行静态分析,完成抽象图谱的抽取;并将各自style元素定义的属性传递给下层的DOT转换接口。常用的调用接口定义如表1所示,表1中的接口参数algoname和algoname_list均由图谱描述文件中定义过的algoname属性值来确定。
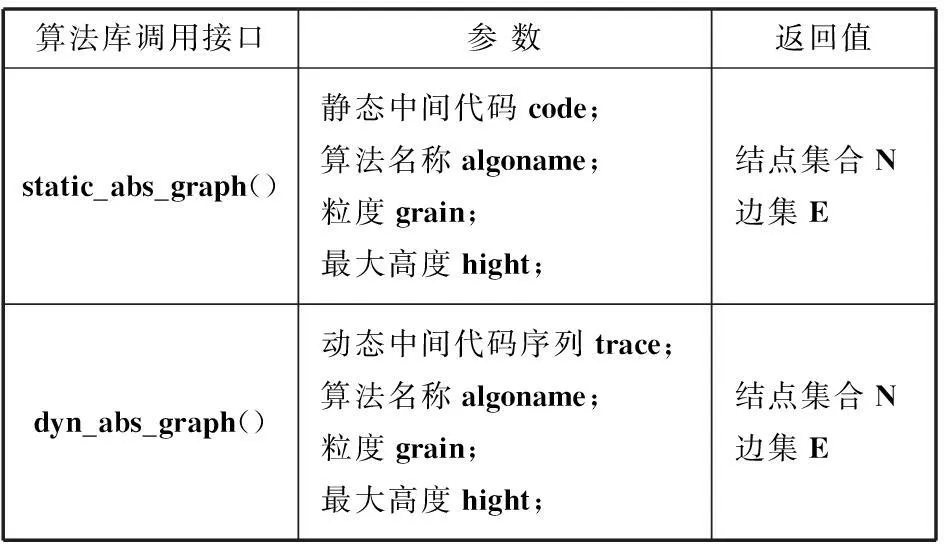
表1 常用算法库调用接口
由于算法库中包括的算法多样,分析的粒度越小,图的复杂程度通常越高。此外动态抽象图谱只针对代码的一条执行路径,对于不同执行路径生成的动态抽象图谱反映了不同路径下的分析结果。所以为了方便分析人员的观察和阅读,描述文件中的mix属性和layer属性分别对生成图的模式进行了限定,并根据这些属性调用不同的接口函数。当mix=1时,表示可以混合显示,即将不同维度(粒度)的图合并为一幅大图,调用mix_*_abs_graph()函数;mix=0表示不同维度的图将分别独立显示,调用single_*_abs_graph()函数。此外,当layer=-1时,hight=-1,表示显示完整的图;layer=n(n∈N)时,hight=N,表示显示到图的高度最多至第n层。
3.3 基于DOT 的抽象图谱转换接口
DOT是一种图形描述语言,它提供了一种简单的图形描述方法,很容易被人和计算机程序理解,具体的语法规范可以参考文献[7]。DOT语言也可以看做是一种脚本语言,由专门的DOT解释程序来解释执行,比如GraphViz就是一组用于处理dot文件的开源工具包[7]。它既可以作为独立的软件来使用,也可以作为库被其他应用程序调用。下面是一个简单的dot描述示例:
digraph sample{
A [shape=box];
A->B->D;
A->C->F;
B->E [style=dotted];
D->A [style=dotted];
}
图4是针对上述dot描述文件使用GraphViz工具解释执行后显示的图形。
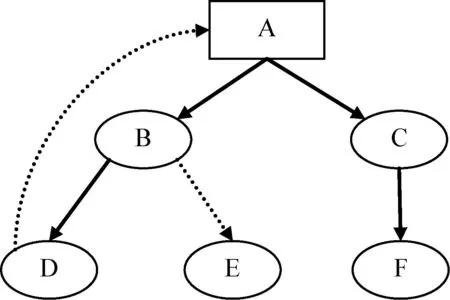
图4 GraphViz解释后生成的图
经过静态、动态图谱抽取模块得到的抽象图通常只含有节点以及边的关系,即结点集合N和边结合E,不利于用户的查看和分析。设计DOT接口可以将这些抽象图(结点集合、边集合)自动转化为DOT描述文件,从而调用DOT解释器实现多维图谱的可视化。DOT接口API定义如表2所示。

表2 DOT转换接口列表
4 多维图谱抽取算法
基于多维图谱抽取框架以及各个模块定义的接口函数,设计多维图谱抽取算法。该算法以多维图谱描述文件Spec_Xml以及被分析代码来源Code_Source为输入参数,以多维图谱GRAPHS为输出结果,具体的算法伪代码如下所示:
算法1 多维图谱抽取算法
输入 Spec_Xml,Code_Source
输出 Graphs
Proc Di_Graphs_Extract (Spec_Xml, Code_Source)
If (Code_Source is static)
mixed=Get_ Attribut _Value(static, mix);
If (Spec_Xml->static->instruction is not null)
Graph[0]=instruction;
End If
If (Spec_Xml->static->baseblock is not null)
Graph[1]= baseblock;
End If
If (Spec_Xml->static->structure is not null)
Graph[2]= structure;
End If
If (Spec_Xml->static->procedure is not null)
Graph[3]= procedure;
End If
For (i=0; i<4; i++) do
layer= Get_Attribut_Value(Graph[i], layer);
algoname=Get_Child_Value(Graph[i], algoname);
algoaddr= Get_Child_Value(Graph[i], algoaddr);
style->node.color=
Get_ Attribut _Value(Graph[i]->style->node, color);
style->node.shape=
Get_ Attribut _Value(Graph[i]->style->node, shape);
Style->edge.color=
Get_ Attribut _Value(Graph[i]->style->edge, color);
Style->edge.shape=
Get_ Attribut _Value(Graph[i]->style->edge, shape);
(N, E)= Static_Abs_Graph (algoname, algoaddr);
dot_node_attr=node_attr(style.node);
dot_edge_attr=edge_attr(style.edge);
dot_edges=edge_to_edge( E );
dot_file=create_cot_file(dot_node_attr, dot_edge_attr, dot_edges, mixed);
GraphViz(dot_file);
//调用dot文档解析器
End For
End If
If (Code_Source is dynamic trace)
Similar to static;
//与静态代码的处理方法类似
End If
End Proc
设被分析代码是静态的中间语句,且语句级、基本块级、结构级以及过程级抽象图生成算法的最大复杂度为K,抽象图的边的最大数目为e,转换为dot文档后的语句最大条数为d,则通过分析算法可以得静态多维图谱抽取算法的最大复杂度为C≈O(K+e+d)。
证明:
静态语句级Get_Abs_Graph()的复杂度c11与algoname算法的复杂度相关;edge_to_edge()的复杂度c12与抽象图边的条数相关;Create_Dot_Document()的复杂度c13也与抽象图边的条数相关;GraphViz()的复杂度c14与dot文件中的语句条数相关。
设语句级抽象算法复杂度为k1,抽象图(N, E)边的条数为e1,dot文件中的语句条数为d1,则语句级静态图谱抽取的复杂度为:
C1=c11+c12+c13+c14=k1+e1+e1+d1=k1+2e1+d1
同理,基本块级、结构级和过程级的静态图谱抽取复杂度分别为:
C2= c21+c22+c23+c24=k2+e2+e2+d2=k2+2e2+d2
C3= c31+c32+c33+c34=k3+e3+e3+d3=k3+2e3+d3
C4= c41+c42+c43+c44=k4+e4+e4+d4=k4+2e4+d4
因为K=max(k1, k2, k3, k4),e=max(e1, e2, e3, e4),d=max(d1, d2, d3, d4)。
则静态图谱抽取的最大复杂度为:
C=C1+C2+C3+C4≈4K+8e+4d≈O(K+e+d)
说明:上述结论是以静态图谱抽取部分的复杂度为例,动态图谱抽取的算法与静态类似。只是抽象图生成算法的复杂度以及抽象图边的条数,dot文档的语句条数与静态图谱的不同,可以得到相类似的结论。
5 实验方法与测试
为了验证多维图谱抽取算法的有效性,和时间复杂度,课题组搭建嵌入式二进制分析平台EBAP[15]作为多维静态图谱抽取的前端。基于QEMU搭建动态信息提取系统作为动态图谱提取的前端,以基于BRIL[13]中间语言的中间代码和中间代码序列作为静态图谱抽取和动态图谱抽取的对象。
实验机型为联想ThinkCentre M8400s,处理器为Intel酷睿i5 2400,8 GB内存,主机操作系统为Windows 7,将源程序test1.cpp~test5.cpp经过gcc4.4.3编译得到测试程序test for x86系列test1.exe~test5.exe,将源程序test1.cpp/test2.cpp/test3.cpp经过arm-linux-gcc-4.4.3交叉编译得到test for arm系列test1/test2/test5。选用基于抽象解释的数据依赖分析算法(语句级)、精度可调的控制流图恢复算法(基本块级)[15]、基于结构语义树的高级控制结构恢复算法(结构级)[13]等各粒度的算法构建算法库,编写图谱描述文件,并调用算法1进行测试。
测试的部分结果如图5-图7所示。其中test1.exe语句级静态图谱抽取结果如图5所示,test2.exe基本块级与结构级以普通混合模式显示的静态图谱结果如图6所示,test3.exe过程级最大高度hight=6的静态图谱结果如图7所示。

图5 语句级静态分析图

图6 基本块和结构级静态分析图
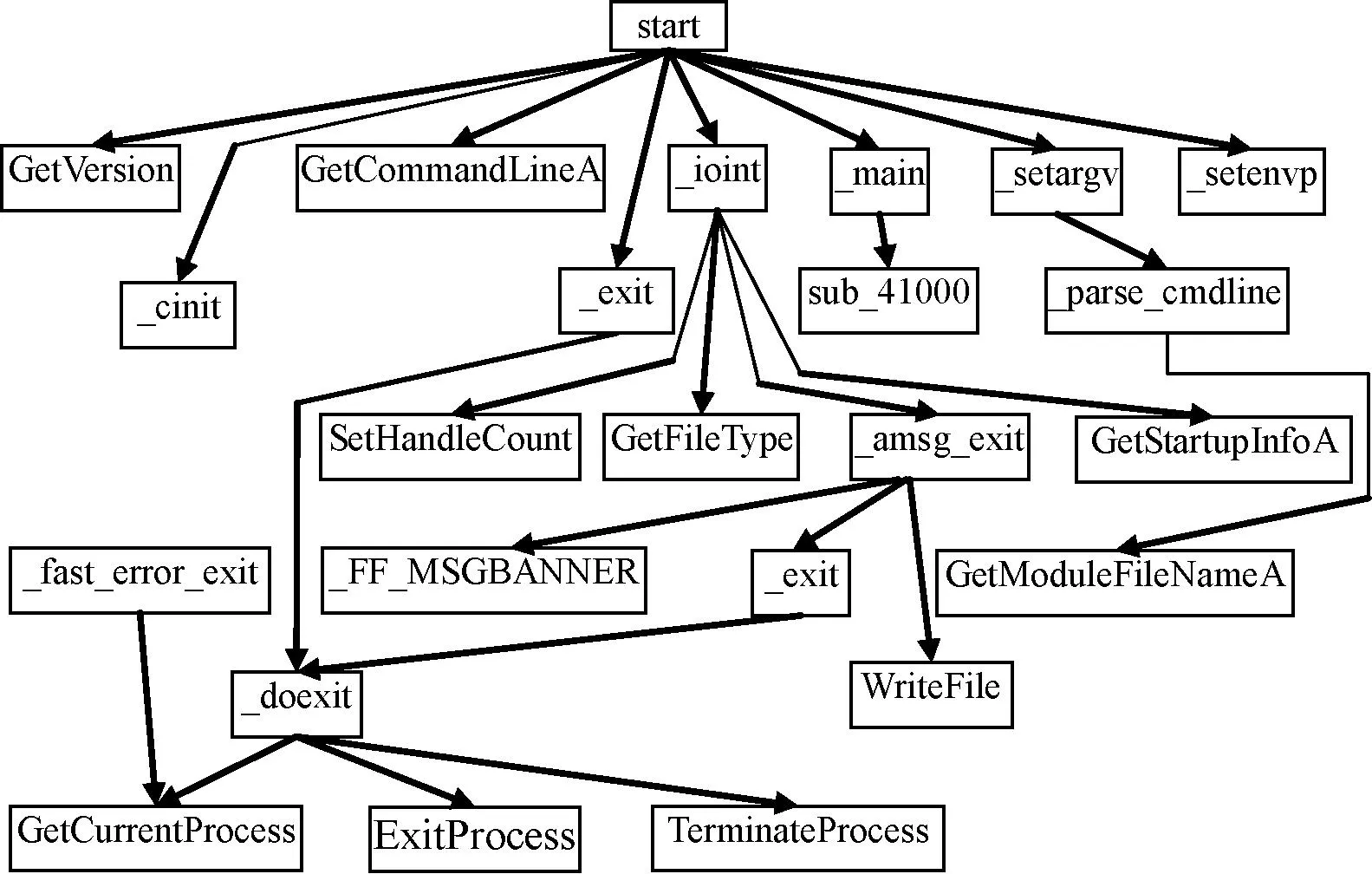
图7 过程级静态分析图
由图可以看到,经过多维图谱抽取算法得到的结果使语句级的依赖关系、基本块间的控制流转关系、高级控制结构的构成方式以及函数间的调用关系一目了然。大大提高了分析人员阅读代码的工作效率,为下一步进行关键区域的漏洞挖掘等安全性分析工作提供了方向性的指导。
多维图谱抽取的时间性能测试如表3和表4所示。
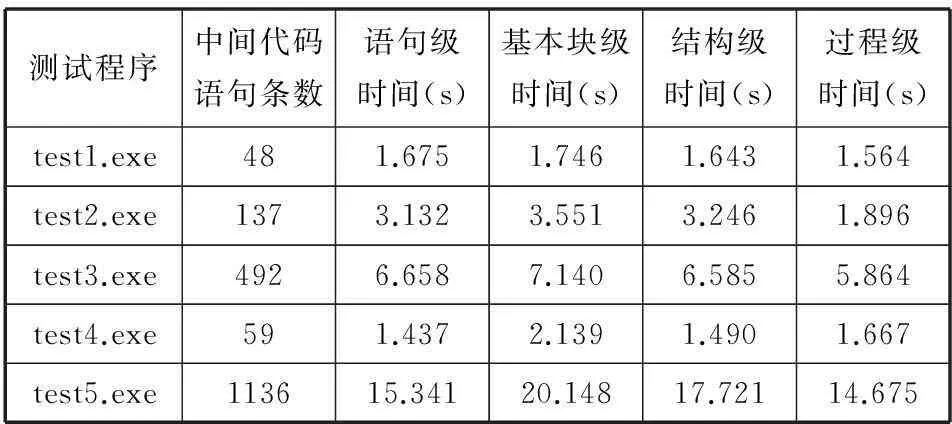
表3 静态图谱抽取时间性能测试结果
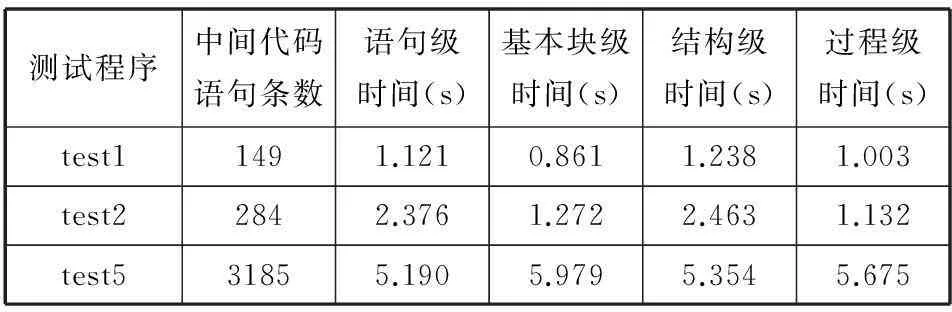
表4 动态图谱抽取时间性能测试结果
由测试结果可以发现,动态抽取的中间代码语句条数比静态分析下得到的要多,而静态图谱抽取的时间却比动态图谱提取的时间要长,原因如下:
1) 动态图谱提取测试针对中间代码序列的一次运行过程,在运行时会将循环结构的代码按照实际的循环次数进行展开,故其语句条数通常会比静态分析得到的要多;
2) 动态图谱因为其语句级依赖关系、基本块之间的控制关系、结构关系以及函数间的调用关系是确定的,比较简单,这使得抽象图谱生成算法可以迅速到达不动点,因此整个图谱的抽取也就会比静态图谱抽取的速度要快。
另外测试结果中的时间性能还与采用的算法库中的抽象图谱生成算法的复杂度密切相关,选用的算法复杂度越高,图谱抽取所需的时间就越长。
6 结 语
目前常用的其他逆向分析工具,比如IDA、Ollydb等,都仅提供基于某种特定静态汇编代码的语句级、基本块级、过程级的结构图。当用户基于汇编代码采用其他逆向分析算法进行分析的时候,无法帮用户更新这些结构图,不方便分析人员的分析和比较。多维图谱抽取技术实现了图谱生成与逆向分析算法的独立,即当采用的逆向分析算法发生变化的时候,只需要修改图谱描述文件中对应维度下算法元素的名称和地址属性,就可以自动生成对应算法的实际图形。分析人员不需要关心具体图形是如何显示的。
下一步需要完成的工作主要有:完成图谱复杂混合模式的显示功能,增强不同粒度之间图谱的对比性和关联性,尤其是基本块级、结构级与过程级之间的关联性;实现复杂图谱的部分以及连续显示,更加方便用户的阅读和分析;完成基于不同抽象图谱提取算法的时间性能测试及比较,为用户算法选择提供参考;另外基于多维图谱的恶意行为检测技术和漏洞挖掘技术等也是我们进一步重点研究的内容。
[1] JeanLouis Boulanger.Static analysis of software:The abstract interpretation[M].Hoboken:Wiley Press,2013.
[2] Patrick Cousot,Radhia Cousot.Abstract interpretation:a unified lattice model for static analysis of programs by construction or approximation of fixpoints[C]//Proceedings of the 4th ACM SIGACT-SIGPLAN symposium on principles of programming languages,Los Angeles,California,1977:238-252.
[3] 李永伟.基于Hex-Rays的缓冲区溢出漏洞挖掘技术研究[D].郑州:解放军信息工程大学,2013.
[4] 焦永生,舒辉.基于TEMU的进程间通信过程逆向[J].计算机应用研究,2013,30(7):2091-2095.
[5] Heng Yin,Dawn Song.TEMU:Binary Code Analysis via Whole-System Layered Annotative Execution[EB/OL].(2012-10-11).[2014-09-11].http://www.eecs.berkeley.edu/Pubs/TechRpts/2010/EECS-2010-3.html.
[6] XML可扩展标记语言[EB/OL].(2014-08-20).[2014-09-11].http://zh.wikipedia.org/zh-cn/XML.
[7] Dot language[EB/OL].(2014-09-11).[2014-09-11].http://www.graphviz.org/content/dot-language.
[8] David Brumley,Ivan Jager,Thanassis Avgerinos,et al.BAP:A Binary Analysis Platform[C]//Proceedings of the conference on computer aided verification,2011:1-7.
[9] IDA:About[EB/OL].(2014-01-25).[2014-09-11].https://www.hex-rays.com/products/ida/index.shtml.
[10] 吴伟民,司斯,阮奕邦,等.基于函数划分块及置信度的反汇编优化研究[J].计算机应用与软件,2014,31(1):85-88,164.
[11] QEMU Internals[EB/OL].(2014-08-01).[2014-09-11].http://qemu.weilnetz.de/qemu-tech.html.
[12] Dawn Song,David Brumley,Heng Yin,et al.BitBlaze:A New Approach to Computer Security via Binary Analysis[C]//Proceedings of the 4th international conference on information systems security,Hyderabad,India,2008:1-25.
[13] 刘絮颖.反编译中控制流重构与控制结构恢复技术研究[D].郑州:信息工程大学,2010.
[14] 邢雨辰.用于程序验证的数据流分析技术的整合[D].南京:南京大学,2013.
[15] Jing Jing,Jiang Liehui,Liu Tieming,et al.A Precision tunable CFG Reconstruction Algorithm[C]//Proceedings of international conference on Mechatronic sciences,Electric engineering and Computer,Shenyang,China 2013:2095-2099.
[16] Lok Kwang Yan,Heng Yin.DroidScope:Seamlessly Reconstructing the OS and Dalvik Semantic Views for Dynamic Android Malware Analysis[C]//Proceedings of the 21st USENIX Security Symposium,2012:1-16.
MULTIDIMENSIONAL GRAPHS EXTRACTION METHOD IN SOFTWARE REVERSE ANALYSIS PROCESS
Jing Jing1Jiang Liehui1,2Liu Tieming2Si Binbin1Zeng Yun1Zhu Xiaoqing2
1(SchoolofComputerScienceandTechnology,InformationandEngineeringUniversity,Zhengzhou450000,Henan,China)2(TheStateKeyLaboratoryofMathematicalEngineeringandAdvancedComputing,Zhengzhou450000,Henan,China)
The results of software reverse analysis process are usually the formal symbols, which are complicated and unintelligibility, therefore the efficiency of the works of code behaviour understanding or code vulnerabilities mining based on software reverse analysis is very slow. In view of this, we design the multidimensional graphs extraction framework firstly, and based on this framework we define the multidimensional graphs description constraints (schema), which makes the multidimensional graphs extraction and specific reverse analysis process be independent from each other. And we present the construction approach of reverse analysis algorithm library and design the call interfaces of the algorithm library, realise the multidimensional graphs description-based abstract graphs generation. What’s more, we design the abstract graphs convert interface which is based on DOT (a graph description language), and achieves the fast visualisation of abstract graphs. At last we present an algorithm of multidimensional graphs extraction. Experimental results show that to use this algorithm can effectively improve the readability of the generated results in reverse analysis process, and greatly increase the work efficiency of analysers in code behaviour understanding and code vulnerabilities mining.
Multidimensional graphs Extract
2014-09-12。国家自然科学基金项目(61272489)。井靖,讲师,主研领域:软件逆向分析。蒋烈辉,教授。刘铁铭,讲师。司彬彬,讲师。曾韵,讲师。朱晓清,讲师。
TP311
A
10.3969/j.issn.1000-386x.2016.04.001
graph DOT interface Visualisation
