RLPI索引:一种处理连续不确定XML索引
2016-05-09张晓琳郭丹丹韩雨童谭跃生
张晓琳 郭丹丹 韩雨童 郝 琨 谭跃生
RLPI索引:一种处理连续不确定XML索引
张晓琳 郭丹丹 韩雨童 郝 琨 谭跃生
(内蒙古科技大学信息工程学院 内蒙古 包头 014010)
针对目前连续不确定XML数据的概率阈值范围查询,提出一种新的包含路径索引和值索引的RLPI(Reverse Label Probabilistic Index)索引。RLPI路径索引以逆序标签路径作为索引项,通过逆序标签路径可区分不同路径上的同名节点,更具针对性地定位所需节点。RLPI值索引借鉴U树的思想,通过提前计算并存储叶子节点的相关信息,以减少查询中需处理的元素数目,并且其对满足任意连续pdf (probability density function)的不确定数据均适用。理论分析和实验结果表明,RLPI索引技术有效地提高了查询处理的性能。
连续不确定数据 XML 索引 概率阈值范围查询
0 引 言
随着网络技术的快速发展,XML类型的数据已成为当前一种主流的数据形式,并成为Internet中进行数据交换和表示事实上的标准。在实际生活中,数据的不确定性是普遍存在的,传统的确定性数据已经不能准确描述现实世界。随着人们对不确定性数据的认识研究和对数据采集和处理技术的深入理解,不确定性数据在物流、工业、金融、军事等领域得到相当广泛的应用。基本上,在数据库中的不确定性是为了捕捉现实世界的状态,如监控的压强、温度、移动目标的位置都是在不断改变的。数据的不确定性信息可以以概率值或概率分布的形式在XML文档中表示。对于连续不确定的数据,存储用概率密度函数pdf可能值的范围来代替存储数据单一的值。而相应的概率阈值范围查询,是通过给定概率阈值及范围,来获取超过概率阈值起点并满足查询范围的结果。在概率阈值范围查询中,由于满足查询指定的概率值的出现,从而使得结果被扩大化。概率阈值范围查询比传统查询更精确及信息化。
目前,对概率阈值范围查询局限于只对满足正态分布的连续不确定XML数据具有适用性。本文针对概率阈值范围查询,提出一种对任意连续不确定XML数据均适用的RLPI索引。在RLPI路径索引中将具有相同逆序标签路径的索引项聚集存储,节省了空间花销;在RLPI值索引中,通过预处理任意连续不确定数据,并结合相应地过滤策略,过滤与查询无关的节点,减少了pdf的计算,从而提高了查询的速度。
1 相关研究
目前针对XML数据的小枝查询,研究者们已经提出了一些有效而快速的索引结构。文献[1]提出了一种素数序列标记法,这种标记法可快速地建立经典F&B索引,并给出了素数整除匹配算法。通过路径匹配算法可预先排除部分无关节点,并利用节点标记值之间的整除关系来判断子树匹配,有效地加速了查询处理过程。但此索引不能处理不确定XML数据。在文献[2]中PATRICIA-TRIES路径索引是基于关键字空间分解的树结构,只在叶节点存储数据记录,内部节点作为占位符引导检索过程。对路径索引使用压缩字符编码建立路径索引,压缩了索引空间。但这些索引都不能处理不确定XML数据。
对不确定XML数据,在文献[3]中提出将XML Schema路径和数据值组合作为索引值,并利用idlists来确定分支点,可以支持一般关系查询处理策略。文中还提出路径索引和值索引的空间压缩策略,可以很大程度节省建索引的空间花销。文献[4]针对目前大多数索引不支持小枝查询及索引结构存储花销大的缺点提出了USIX算法。该算法仅使用了两个关系表:一个是路径的摘要表;另一个是包含值的叶子节点表。结构紧凑,可以有效地支持分枝查询。
进一步地,文献[5]提出了一个扩展的基于区间的编码索引,并提供了有效的概率XML查询处理。它只访问查询中指定的数据标签,在数据匹配同时,评估结果的概率以消除不必要的数据匹配。该索引减少了数据的存取时间并改善了概率XML查询处理的性能。
针对目前越来越多的连续不确定XML数据,文献[6]扩展了经典的结构索引F-index,针对连续不确定XML数据的概率阈值查询,提出CPTI索引。通过CPTI结构索引查询小枝,并确定小枝的路径概率;通过CPTI值索引过滤与查询无关的元素以减少查询中需要处理的元素数目。但该索引仅限于对满足正态分布的连续不确定XML数据的研究。
对连续不确定数据的处理引起了广泛地研究,文献[7]介绍了两个有效的索引。第一个索引是扩大基于R树的不确定信息的存储,使得I/O操作明显减少。通过把一维的片段映射到二维空间,并由二维多边形进行范围查询。第二个索引基于理论研究,提出基于方差的聚类索引。这个索引将具有相似的不定性的数据节点聚类在一起,可用于各种连续不确定密度函数(pdf)数据的查询。文献[8]针对不确定数据的范围查询提出了U-tree,通过存取方法的优化设计减少I/O操作及CPU的处理时间,而且其中的过滤策略对任意连续不确定密度函数(pdf)数据的过滤均有效。但此索引主要应用在地理信息系统(GIS)。
2 基本概念
2.1 数据模型
目前,支持连续不确定数据的数据模型有概率树模型和P-文档模型。现已有通过分析概率XML数据树中的路径类型从而对不确定XML文档进行简化的概率树模型[9]。在概率树模型中,可能节点会存在大量的冗余信息,给不确定数据管理造成一定的困难,使得效率下降。本文采用的是将概率信息附加在文档树边上的P-文档模型PrXML{mux,ind}[10]。为支持叶子上的连续分布,在叶子节点附加一个cont(连续)类型的分布式节点。
2.2 PEDewey编码
PEDewey编码[11]是在Dewey编码的基础上,增加了对不确定XML中分布节点IND和MUX的处理一种前缀编码。该编码为不确定XML文档树中的每个节点都相应地分配了唯一的标识符。该编码的优点是根据节点对应的编码值可以获得从根节点到该节点的路径标签名序列。
如图1所示是一棵带有PEDewey编码的不确定XML文档树。
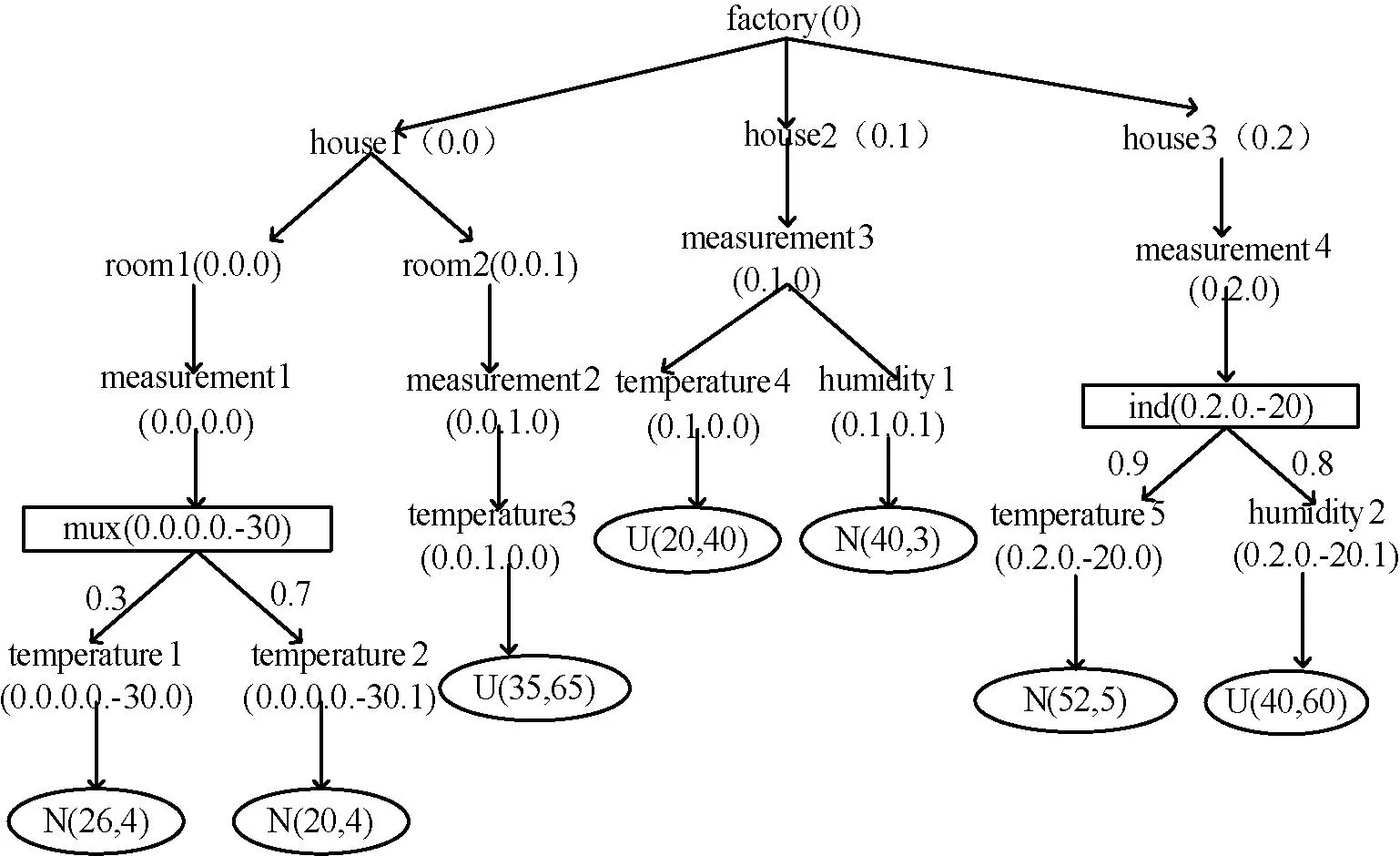
图1 不确定XML文档
3 RLPI索引
3.1 RLPI路径索引
RLPI路径索引的基本思想:根据编码后XML文档树及树中的逆序标签路径,为XML文档树中的所有可能路径建立索引。其中,逆序标签路径是由根节点到当前节点路径的逆序表示。
路径索引的构建采用如图2(a)所示的链表方式进行存储,以逆序路径(ReversePath)即节点标签路径的逆序表示作为索引项,每个索引项存储一个单链表首地址;将同一逆序路径对应的路径信息(PathInformation)依次存入相应单链表节点中。
路径信息(PathInformation)结构如图2(b)所示。其中,PEDewey是相应逆序路径所对应节点的编码;PathProbability是从根节点到该节点的路径概率;Distribution是存放叶子节点服从的分布(如节点服从正态分布,则Distribution存放的是N;如服从均匀分布,则Distribution存放的是U)。图1不确定XML文档中逆序标签路径temperature. measurement.room.house.fact- ory的PathInformation信息结构如图2(c)所示,编码为0.0.0.0. -30.0的temperature节点路径概率是0.3,服从正态分布N;编码为0.0.0.0.-30.1的temperature节点路径概率是0.7,服从正态分布N;编码为0.0.1.0.0的temperature节点路径概率是1,服从均匀分布U。

图2 路径索引链表结构
算法1 RLPI-path
输入:编码的XML文档,其中有n个节点{v1,v2,…,vn}。
输出:逆序路径索引链表。
a) Vi=Travelsal(T);
//深度优先遍历树,得到其节点序列
b) Lvi=RLPI_NXPath(Vi);
//根据节点的逆序路径构建索引
c) return Lvi
//返回RLPI路径索引
RLPI-path的核心操作是RLPI_NXPath(Vi),以下为具体过程:
1 if(ReversePathList.isEmpty())
//逆序路径信息链表为空
2 { ReversePathList.add(path);
//将当前路径添加到ReversePathList
3 RLPI_IndexConstructionList.addnodeRLPI_
IndexConstruction(Vi);
//添加PathInformation
}
4 else
5 {if(Vi.ReversePath.equals(ReversePathList.get(i)))
//当前节点逆序路径在逆序路径信息链表中已存在
6 { k=i;
7 RLPI_IndexConstructionList.get(k).addnode
RLPI_IndexConstruction(Vi);
//在路径相同的位置添加PathInformation
}
8 else
9 { ReversePathList.add(path);
//将当前路径添加到ReversePathList
10 RLPI_IndexConstructionList.addnodeRLPI_ IndexConstruction(Vi);
//添加PathInformation
11 }
12 return RLPI_IndexConstructionList;
//返回RLPI路径索引链表
13 }
3.2 RLPI值索引
RLPI值索引的基本思想:提前计算叶子节点的连续不确定数据的相关信息,并将这些信息存储在对应的节点链表。查询时,通过存储的信息及相应的过滤规则进行过滤,以提高查询效率。
定义1 节点o的概率约束区域PCR(Probabilistically Const- rained Regions)由线l1+、 l1-两线分割得到的片段,记作o.pcr(p)。线l1+将不确定片段成两部分(l1+的左、右片段),其中点o出现在l1+右片段的概率为p;相似地,点o出现在线l1-左端的概率也为p,其中p取[0,0.5]。如图3(a)所示。
根据上述定义可以得到节点针对不同p(p1,p2,…,pm)的PCR,再根据下面的公式计算在这m个PCR外侧的线性函数o.cfbout及在这m个PCR内侧的线性函数o.cfbin(如图3(b)所示):
o.cfbout(p)=αout-βout·p
(1)
o.cfbin(p)=αin-βin·p
(2)

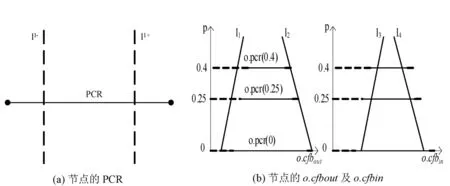
图3 叶子节点的PCR和o.cfbout及o.cfbin
图4(a)为节点值索引组织结构,cont为相应节点的pdf,ur为当前节点的不确定范围。如图4(b)所示为服从均匀分布U(20,40)的叶子节点的值索引结构。如图4(c)所示为服从正态分布N(52,5)的叶子节点的值索引结构。
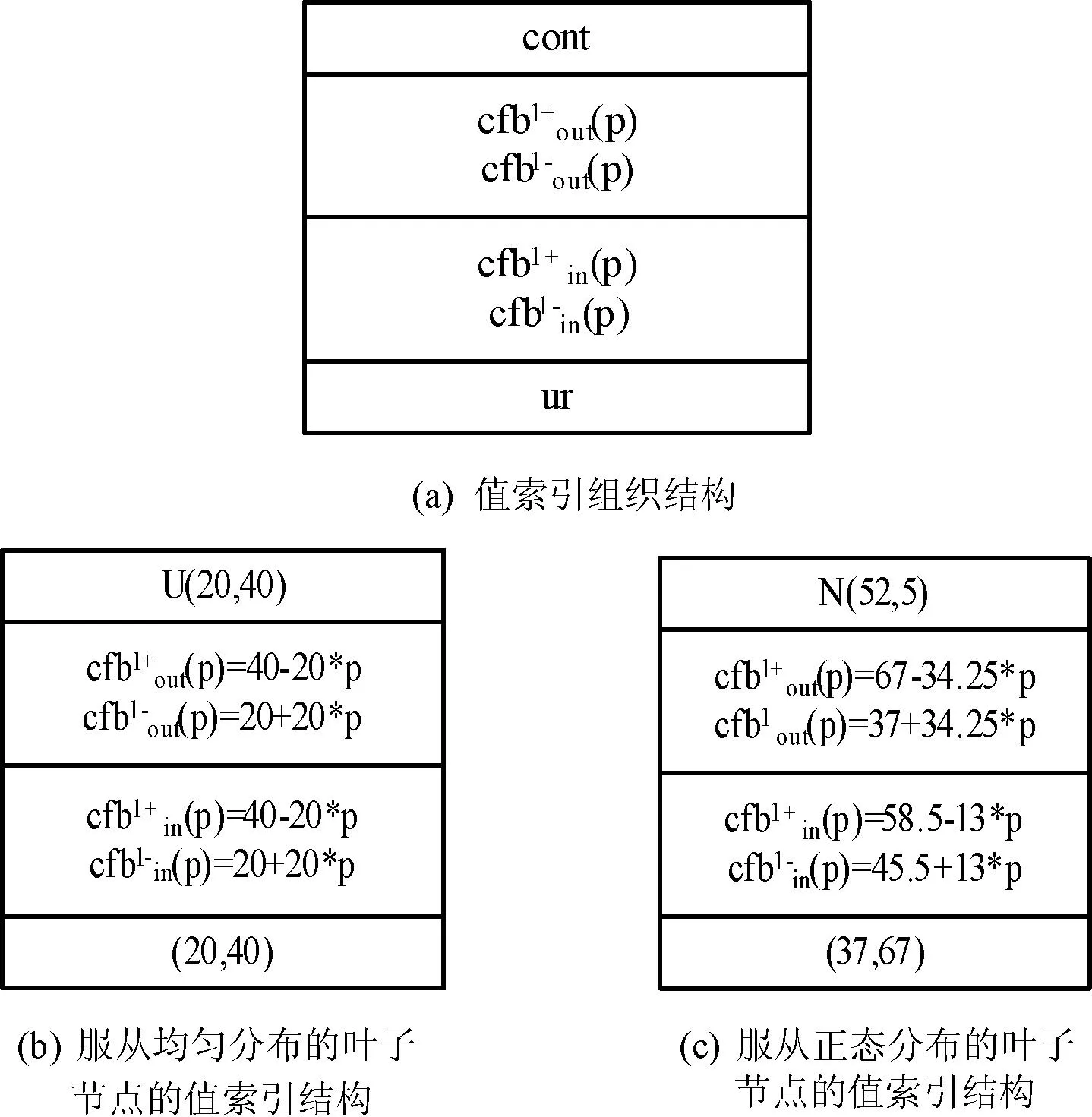
图4 叶子节点的值索引结构
值索引相应的过滤规则(对于给定概率pq的范围查询rq):
1) 当pq>1-pm,如果rq没有完全包括o.cfbin(pj),节点o可以删除。其中pj(1≤j≤m)是U-catalog中不小于1-pq的最小值。
2) 当pq≤1-pm,如果rq和o.cfbout(pj)不相交,节点o可以删除。其中pj是在U-catalog中不大于pq的最大值。
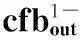
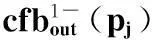
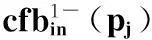
算法2 RLPI-value
输入:编码的XML文档,其中有n个节点{v1,v2,…,vn},RLPI-path索引。
输出:RLPI索引。
1 while(vi是叶子节点)
2 { cont=vi.getText()
//获取其数据
3 valueResultlist=contvalueSolution(cont);
//cfbout,cfbin信息计算
4 RLPI_IndexConstructionList.addvalueResultlist
//将信息插入到对应节点链表
5 return RLPI_IndexConstructionList}
3.3 算法复杂度分析
时间复杂度为:RLPI路径索引,最坏的情况扫描所有节点,为每个节点都构建逆序路径时间复杂度为O(n)。若这n条逆序路径都不同,则其时间复杂度为O(1+2+…+(n-1)),即O((n2-n)/2),其中n表示节点数。所以RLPI路径索引的时间复杂度为O(n+(n2-n)/2),即O((n2+n)/2);RLPI值索引中,叶子节点个数为1,则时间复杂度为O(1)。因此RLPI索引在最坏情况下的时间复杂度为O((n2+n)/2+l)。
空间复杂度:RLPI路径索引,最坏情况下的时间复杂度是O((n2+n)/2),将这n个节点的路径最后都存入链表中。在RLPI值索引构建阶段的空间复杂度仍为O((n2+n)/2),所以RLPI索引的空间复杂度为O((n2+n)/2)。
4 基于RLPI索引的查询处理
4.1 基于RLPI索引的ProTwig查询算法描述
(1) 根据RLPI路径索引中的索引项查询叶子节点所对应的单枝路径,通过有限自动机进行匹配,从而得到相应的编码。
(2) 根据链表中PathProbability确定概率阈值查询的路径概率。如果temperature的路径概率小于查询概率阈值将被过滤掉,否则保留。
(3) 根据RLPI值索引中o.cfbout和o.cfbin及下面的过滤规则判断在给定范围的温度概率是否大于给定概率值。
(4) 将得到的底层叶子节点集合返回给上一层;再经过步骤(2)过滤并计算小枝的条件概率值,将结果集返回给上一层;同理自底向上依次执行,直到查询到根节点,合并根节点的后代节点集合并计算小枝的条件概率值。
算法3 ProTwig
输入:查询模式Q,其中有n个节点{v1,v2,…,vn};RLPI索引链表。
输出:满足查询模式Q的结果。
a) Vi=Travelsal(T);
//深度优先遍历树,得到其节点序列
b) Rvi=TwigSolution (Vi);
//判断节点是否为叶子节点,并进行相应的处理
c) return Rvi
//返回查询结果
ProTwig查询算法主函数TwigSolution的递归调用实现过程如下:
算法4 TwigSolution
1 if(node是叶子节点)
2 { leafResult= leafSolution(node);
//叶子节点查询处理算法
3 filterSolution(leafResult);
//进行过滤
4 return leafResult;}
//将满足条件的叶子节点集合返回给上层查询节点
5 else
6 { for(all children of node)
7 { ResultList[]=TwigSolution(node.children(i));
8 }
9 Result=QnodIntegration (ResultList);
//合并共同祖先的后代节点集合
10 filterSolution(Result);
11 return Result;
12 }
4.2 基于RLPI索引的查询实例
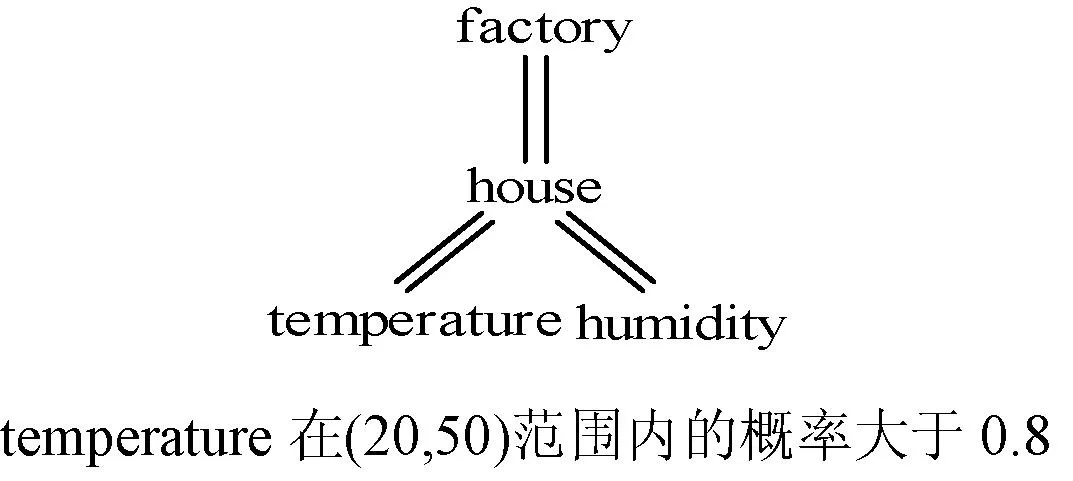
图5 查询实例
例如查询图1中温度在(20,50)范围内的概率大于0.8,如图5所示的小枝。利用RLPI路径索引查询图5中的Twig,首先查询到叶子节点temperature和humidity。再通过相应的过滤策略过滤掉不满足(20,50)范围内的概率大于0.8的温度,根据编码将具有相同祖先的节点由底层向上递归合并从而得到满足条件的结果。
例:查询如图5实例,先根据RLPI路径索引的逆序标签路径temperature.…house.…factory和humidity.…house.…factory,并分别通过有限自动机进行匹配,得到temperature.measurement.room.house.factory路径相应的temperature为0.0.0.0.-30.0,0.0.0.0.-30.1,0.0.1.0.0及temperature.measurement.house.factory路径相应的temperature为0.1.0.0,0.2.0.-20.0;路径humidity.measurement.house.factory相应的humidity为0.1.0.1,0.2.0.-20.1。经过步骤(2)过滤后,保留的temperature为0.0.1.0.0,0.1.0.0,0.2.0.-20.0。其中p1,p2,…,pm分别选取0,1/16,2/16,…,8/16。编码为0.0.1.0.0和0.2.0.-20.0的temperature根据过滤规则1被过滤掉;编码为0.1.0.0的temperature根据过滤规则3,可得其满足在(20,50)的范围内概率大于0.8。将此时留下的{0.1.0.0}的temperature和{0.1.0.1,0.2.0.-20.1}的humidity进行匹配返回给上一层{(0.1.0.0,0.1.0.1),0.1};同理自底向上依次执行,直到执行到factory的位置,合并共同祖先factory的后代节点集合。因此,最终结果为{(0.1.0.0,0.1.0.1),0.1,0}。
5 实验结果分析
5.1 实验环境和数据集
实验的硬件环境为:CPU Inter(R) Core i5(3.2 GHz),RAM为8 GB,操作系统为64位的Windows 7,实验工具为MyEclipse 6.5,JDK 6.0。实验测试所用数据集是通过XMark生成合成数据集,然后利用一个随机化的算法随机加入一些分布节点,其中包括满足正态分布和均匀分布的连续不确定数据,合成具有连续不确定性节点的XML数据集。
5.2 测试和结果分析
实验采用Java实现提出的RLPI索引算法,并将该算法与只针对数据满足正态分布的连续不确定XML的CPTI索引算法以及在经典F-index算法上集成连续节点处理的CF-index算法进行对比。
实验部分共有三组测试条件来对比两种算法。第一组测试条件是不同文档、相同查询用例,相同概率阈值;第二组测试条件是相同文档、不同查询用例,相同概率阈值;第三组测试条件是相同文档、相同查询用例,不同概率阈值。每组实验均重复十次,得到的实验数据采用去掉最大值和最小值,取平均值的方法记录整理。查询用例如表1所示。

表1 查询用例
第一组测试使用的查询用例为Q3,查询在(20,50)范围内且概率阈值Pq=0.8的temperature,选取6个大小不同文档测试,查询结果如图6所示;第二组测试文档大小为56.4 MB,查询在(20,50)范围内且概率阈值Pq=0.8的temperature,分别执行表1的3个查询用例,查询结果如图7所示;第三组测试选取文档大小为56.4 MB,查询用例为Q3,改变在(20,50)范围内查询temperature的概率阈值Pq值,查询结果如图8所示;明显看出这三种情况下算法RLPI性能均优于算法CPTI与CF-index。原因是算法RLPI中相较CPTI算法与CF-index,不仅能过滤掉满足正态分布的节点而且可过滤掉满足均匀分布的节点,从而减少了大量无用中间结果的生成。
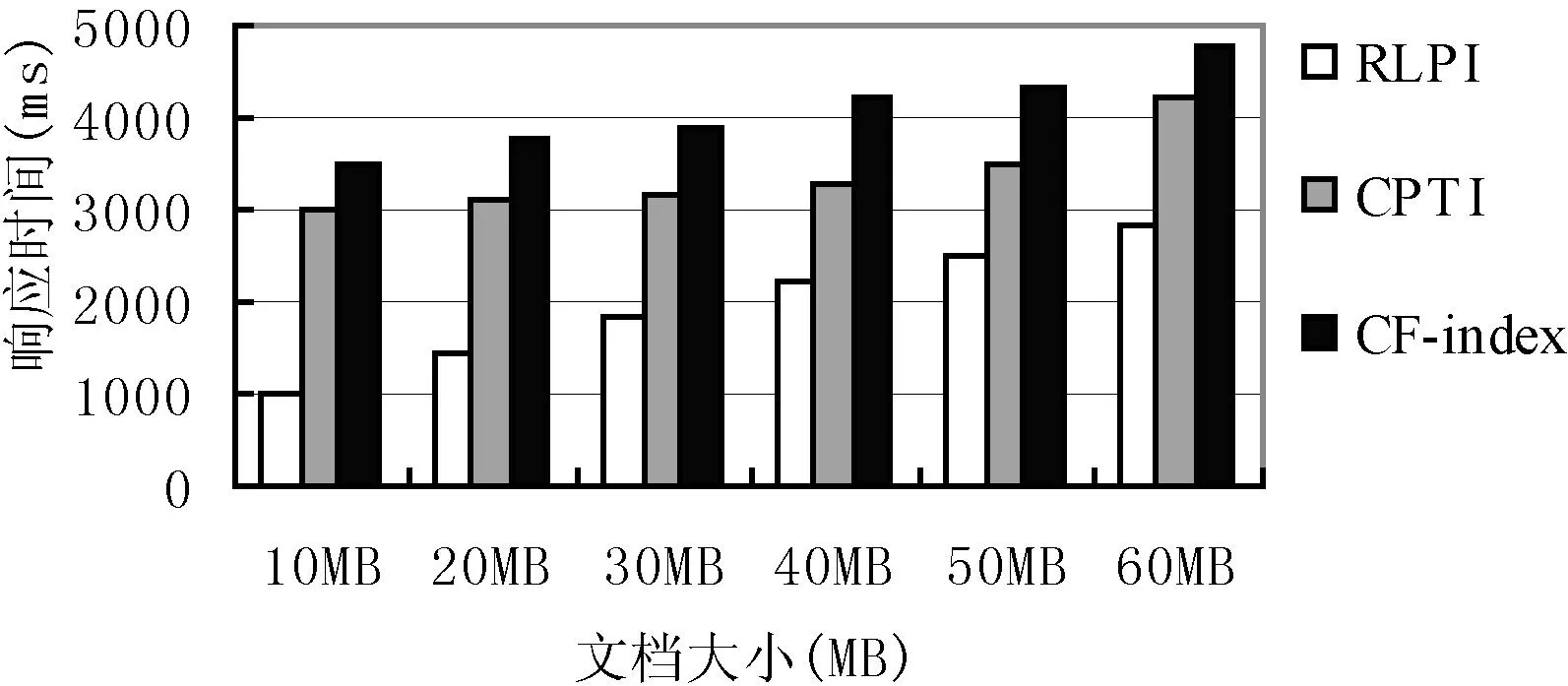
图6 不同文档的响应时间对比
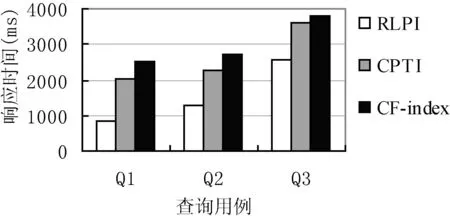
图7 不同查询用例的响应时间对比
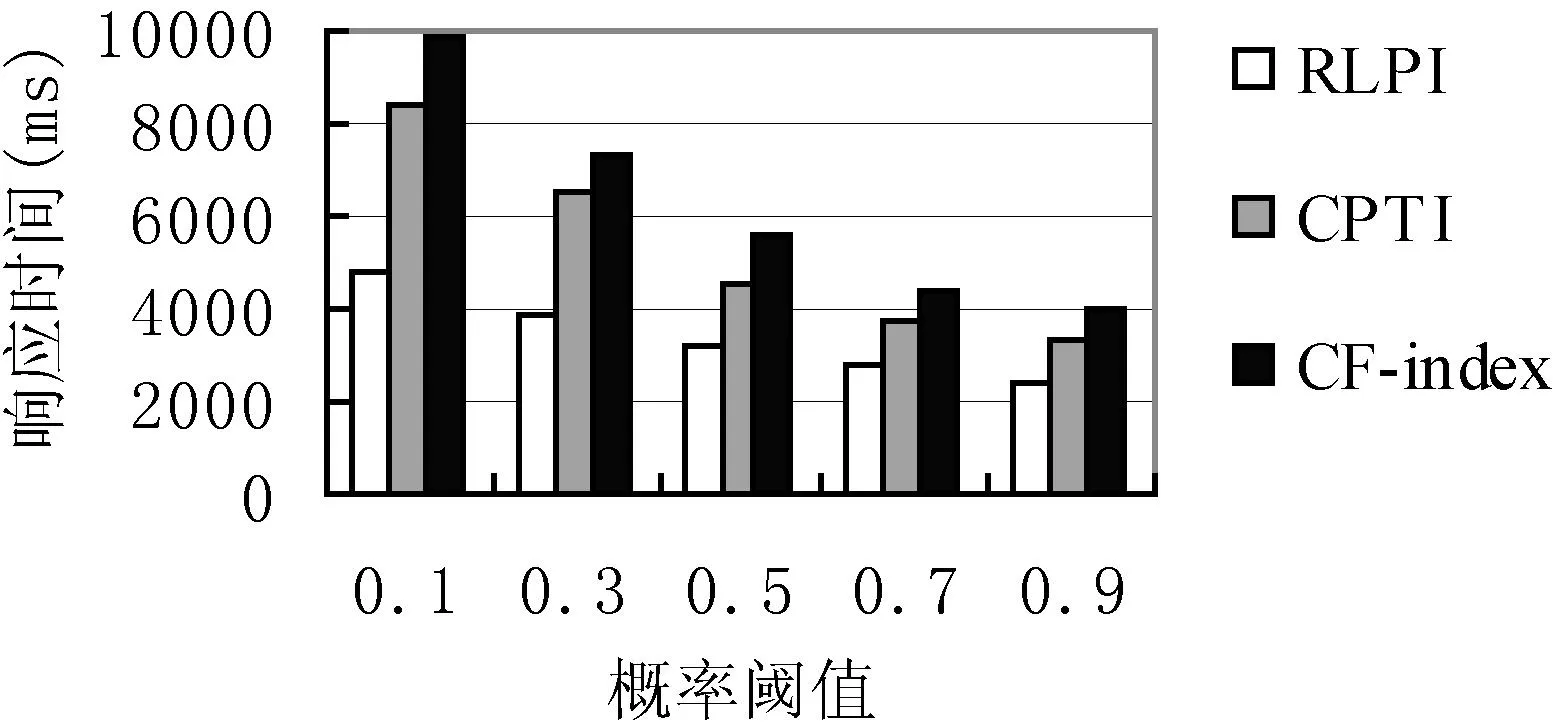
图8 不同阈值的响应时间对比
6 结 语
本文提出一种针对连续不确定XML数据概率阈值查询的索引算法:RLPI算法通过其路径索引加速了Twig查询;使用其值索引过滤连续不确定XML数据,过滤掉不满足条件的节点,减少了中间结果的连接,在一定程度上提高了查询的效率。
[1] 王洪强,李建中,王宏志.基于F&B索引的XML查询处理算法[J].计算机研究与发展,2010,47(5):866-877.
[2] 易平,胡运安,陈福生,等.基于PATRICIA-TRIES的XML路径索引设计[J].小型微型计算机系统,2006,27(3):475-480.
[3] Chen Z,Gehrke J,Korn F,et al.Index structures for matching XML twigs using relational query processors[J].Data & Knowledge Engineering,2007,60(2):283-302.
[4] Mohammad S,Martin P,Powley W.Relational universal index structure for evaluating XML twig queries[C]//Proceedings of Communications and Information Technology (ICCIT).Aqaba:IEEE,2011:116-120.
[5] Yun J H,Chung C W.Efficient probabilistic XML query processing using an extended labeling scheme and a lightweight index[J].Information Processing & Management,2012,48(6):1181-1202.
[6] 张换香,张晓琳,刘立新.连续不确定XML数据索引技术[J].计算机应用与软件,2013,30(8):51-53.
[7] Cheng R,Xia Y,Prabhakar S,et al.Efficient indexing methods for probabilistic threshold queries over uncertain data[C]//Proceedings of the Thirtieth international conference on Very large data bases-Volume 30.Hong Kong:VLDB Endowment,2004:876-887.
[8] Tao Y,Cheng R,Xiao X,et al.Indexing multi-dimensional uncertain data with arbitrary probability density functions[C]//Proceedings of the 31st international conference on Very large data bases.Hong Kong:VLDB Endowment,2005:922-933.
[9] 王建卫,郝忠孝.一种概率XML数据树的化简算法[J].计算机应用研究,2010,27(12):4541-4543.
[10] Abiteboul S,Chan T H,Kharlamov E.Aggregate queries for discrete and continuous probabilistic XML[C]//Proceedings of the 13th International Conference on Database Theory.Lausanne:ACM Press,2010:50-61.
[11] Ning B,Liu C,Yu J X,et al.Matching top-k answers of twig patterns in probabilistic XML[J].Lecture Notes in Computer Science,2010,5981:125-139.
RLPI INDEX:AN INDEX PROCESSING CONTINUOUS UNCERTAIN XML DATA
Zhang Xiaolin Guo Dandan Han Yutong Hao Kun Tan Yuesheng
(SchoolofInformationEngineering,InnerMongoliaUniversityofScienceandTechnology,Baotou014010,InnerMongolia,China)
Aiming at current probability threshold range query on continuous uncertain XML data, we put forward a new RLPI index (reverse label probabilistic index). RLPI index contains RLPI path index and RLPI value index. RLPI path index takes reverse label path as the index item, through reverse label path it can distinguish tag nodes with same name on different paths, and is more targeted to locate the desired nodes. RLPI value index gets reference from the idea of U Tree. It calculates in advance and stores some related information of leaf nodes in order to reduce the number of elements to be processed in a query. RLPI value index is applicable to uncertain data satisfied with any continuous pdf (probability density function). Theoretical analysis and experimental results show that this index technique greatly improves query processing performance.
Continuous uncertain data XML Index Probability threshold range query
2014-09-24。国家自然科学基金项目(61163015);内蒙古自然科学基金项目(2013MS0909)。张晓琳,教授,主研领域:数据库理论与技术。郭丹丹,硕士生。韩雨童,硕士生。郝琨,硕士生。谭跃生,教授。
TP392
A
10.3969/j.issn.1000-386x.2016.04.007
