一种移动网络下基于双时间戳的数据增量同步研究
2016-05-09林原冲
郝 平 林原冲
一种移动网络下基于双时间戳的数据增量同步研究
郝 平 林原冲
(浙江工业大学计算机科学与技术学院 浙江 杭州 310023)
随着移动计算的广泛应用,数据同步技术在分布式环境下发挥越来越大的作用。针对分布式移动环境的特殊性,研究并提出一种基于双时间戳的数据增量同步机制,为移动数据库复制技术提供一种可行的解决方案。在保证数据一致性的同时,为系统层级扩展提供了新的思路。实验结果表明,设定合理的批量传输单位能有效地提升同步机制的可靠性。最后设计并实现移动执法智能终端系统,辅助现场作业。
数据同步 双时间戳 扩展 批量传输
0 引 言
在移动互联网领域,网络环境变得越来越复杂。传统的在固定主机FH(Fixed Host)保存数据副本,移动终端机MH(Mobile Host)获取的数据都来自FH,数据流动是单向的集中式架构不适合当前的移动环境。根据Jim Gray等提出的两级复制机制思想,使用FM和MH都保存数据副本的两级分布式架构。两者是一对多的关系(一个FM对应一个或多个MH),数据交流是双向的,并采用松散性的差异式同步策略[2]成为应对当前移动网络环境的主要选择。
同步粒度是移动数据库数据同步的基本单位,根据是否为事务性主要分为两类:事务、元组。利用事务提交变更可以保证数据的ACID特性,但事务提交需要保持一段时间的连接性,回滚过多容易影响系统效率[3]。而当前主流的移动操作系统对远程事务支持不足,采用元组作为同步粒度是该类系统的一个考量。本文研究背景以移动环境下的作业为主,以元组作为同步粒度,提出基于双时间戳的数据增量同步机制,有效地保证数据一致性和可用性。
1 算法研究
分布式系统一般采用经典的主从式结构,体系架构如图1所示。
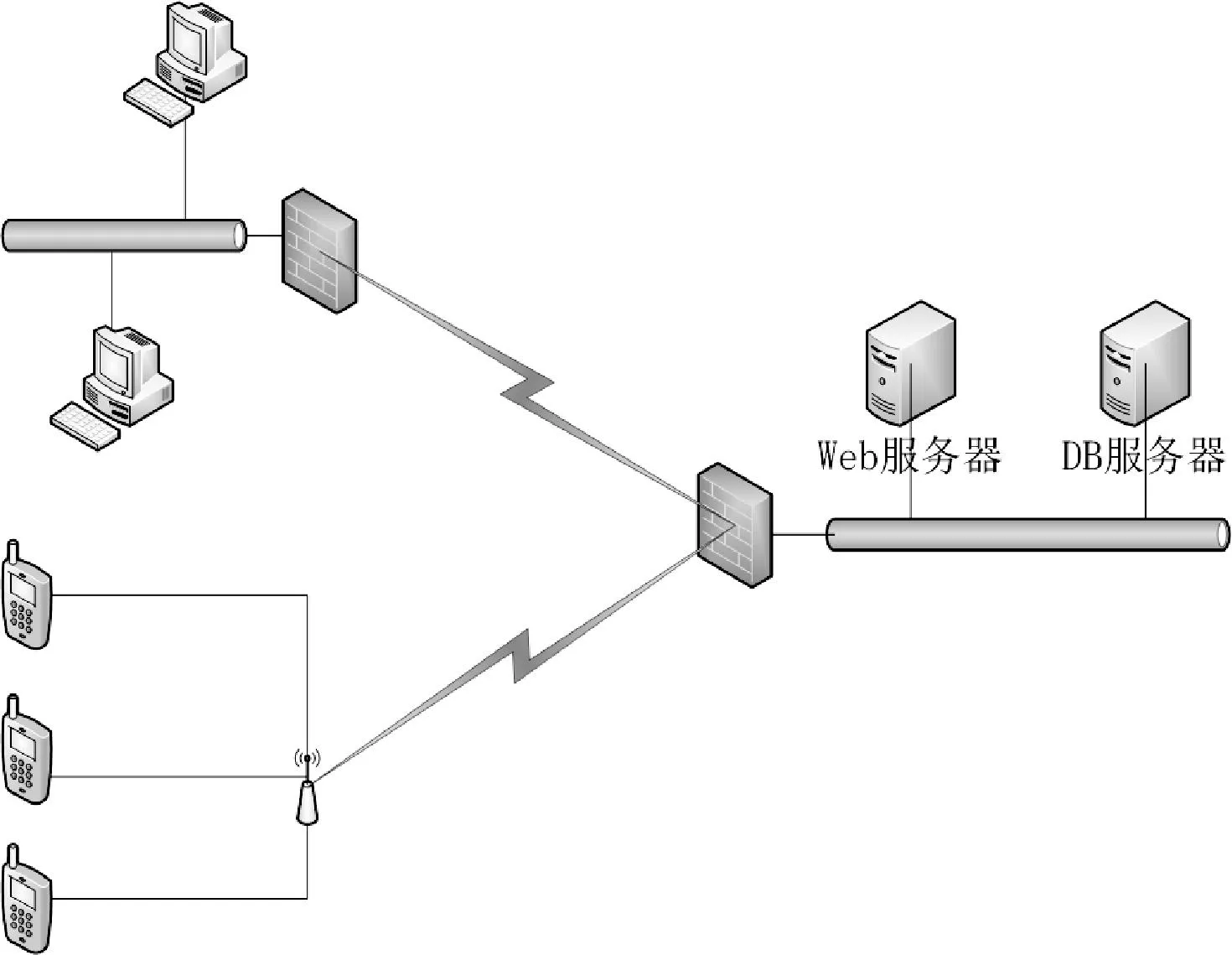
图1 主从式网络架构
这里,我们需要处理好所谓的“CAP原理”[4],即数据一致性(C),系统/数据可用性(A),分区容错性(P)。而分区容错性是在分布式系统中必须实现的,因此为了保证系统/数据的可用性,需要提供在线或是离线时的数据存储,以及进一步通过会话在软实时的更新传播下实现数据的一致性。而当前的移动数据库系统同样可以视作一个准分布式体系结构[5]。
数据同步分为上传和下载两个部分。上传一般由MH发起;下载则有不同的实现方式,可以由MH发起,也可以是在MH上传之后由FM端将针对MH的差异数据返回,即将上传下载合并。
针对数据冲突,由于时间上的异步而产生的冲突是不可避免的,只能在逻辑上牺牲一方的操作或者在应用上按一定策略进行操作内容的合并。主要机制包括:主从表、逻辑合并、分组[7]。主从表机制虽然简化了冲突处理方式,但弱化了数据操作的时间顺序;逻辑合并和分组机制则都需要根据相关业务设置策略。本文侧重数据操作的时间顺序性(基于时间顺序法),该方法除了实现简便,还能方便在现有的集中式架构基础上扩展分布式系统。
增量同步,需要把整体任务细分成多个独立的子任务, 本地通过队列维护多个子任务,并利用数据的时间戳记录同步的进度。而对于任务生成源的选择,文献[6]给出从FM端获取的方式,好处是方便于FM端对任务统一管理,缺点是增加了同步的请求次数成本。
本文的数据同步模型如图2所示。
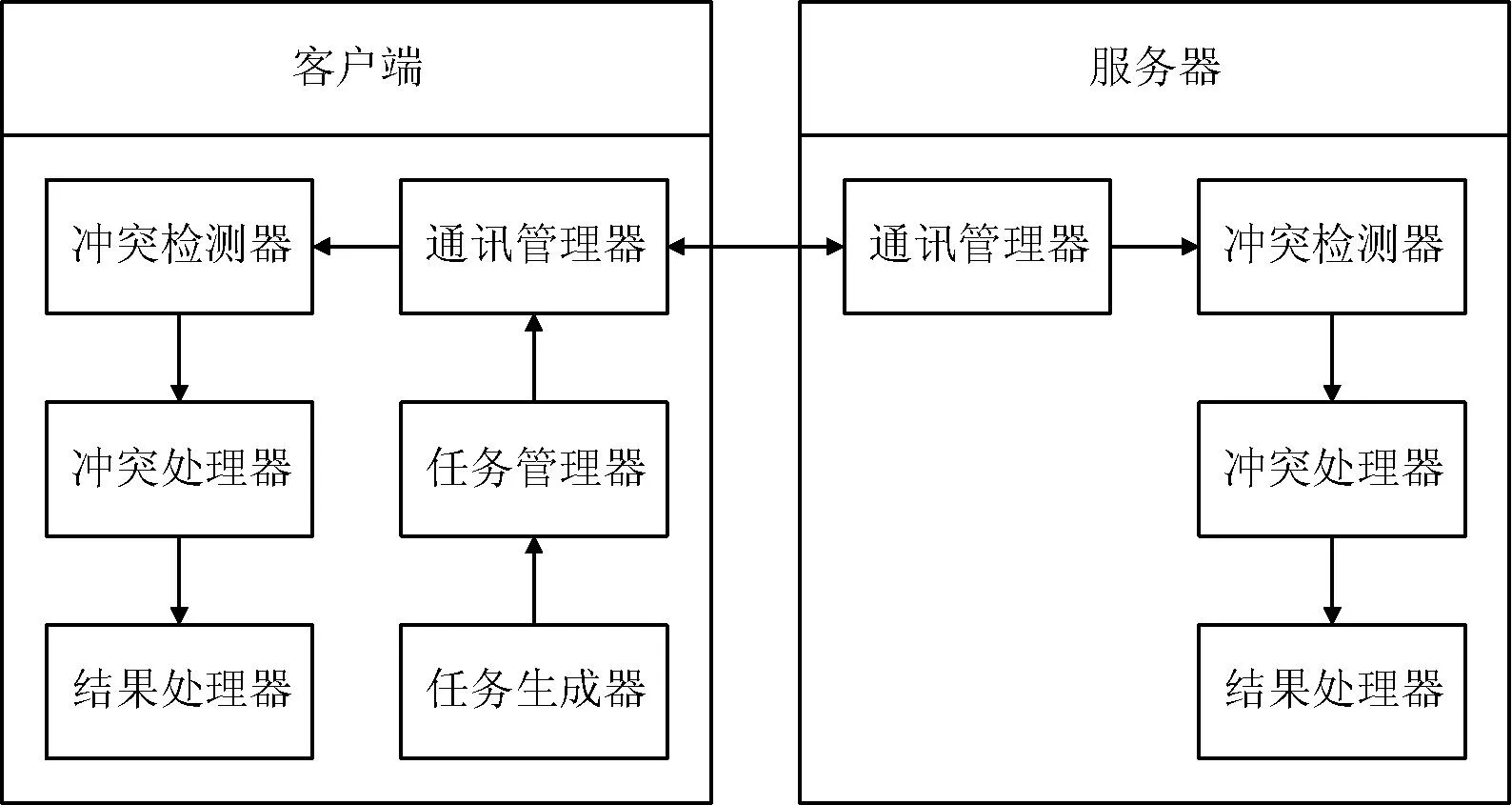
图2 数据同步模型
其中MH和FM各自包含冲突检测、冲突处理、结果处理的功能,以及MH端另外设置了任务的生成、管理功能,其中各个模块之间是调用的关系。
1.1 同步算法
为了便于在现有的集中式系统上扩展分布式系统,本文在MH和FM数据库元组原有属性的基础上做以下调整:
MH端设置或添加三个属性,如表1所示。

表1 MH端调整后的属性
FM端设置或添加以下三个属性,如表2所示。

表2 FM端调整后的属性
其中,本地变更时间记录MH操作时间,用于数据的同步冲突检测。服务器变更时间用于增量数据同步的参照,因此保证MH和FM时间的一致性显得尤为重要[8]。删除标记用于标记被删除的数据对象Ddel,删除标记的引入,将删除操作d(D)当做是一个更新操作u(D),即d(D)∈R(x|x∈u(D)),而且因为任何人都不会对已加删除标记的记录进行修改操作,所以删除有删除标记的记录不会引起数据库数据的删除冲突[9]。
针对TC和TS,通过设置以下几条基本操作规则,作为数据同步的标准:
(1) MH对于数据对象D的操作,只涉及TCm。
(2) 数据对象D的操作结果上传到FM时,令TCf=TCm,TSf=服务器时间。
(3) FM单独对数据对象D的操作,涉及TCf和TSf,且TCf=TSf=服务器时间。
(4) MH下载数据对象D,令TSm=TSf。
(5) 冲突处理以数据对象D的最晚TC为考量(时间顺序法)。
其中规则(3)表现为在FM端直接修改数据的情况,等同于是规则(1)和规则(2)的无间隙合并操作。数据同步围绕TCm、TSm、TCf、TSf进行,图3给出了针对该4个属性的时间顺序闭环图。
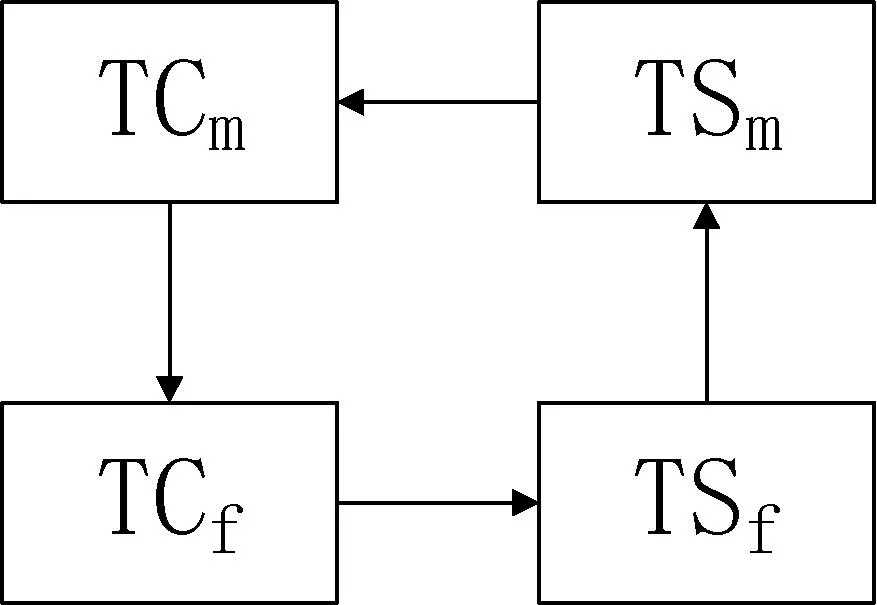
图3 TC-TS闭环图
对于FM上的数据对象D,TCf~TSf称之为其操作op(D)的 “风险时段”,即如果其他Site上有op(D)’的TCm处于该时段,则op(D)有在该时间段被替换的风险,否则予以保留。所以需要将上传下载分开,并且每次MH端要先执行下载操作,通过下载其他MH可能操作并上传过的数据对象,错开TCm和TCf~TSf,可以降低本地操作被替换的几率。
对于数据的上传下载,设置单次数据传输大小上限N。因为考虑到移动网络环境下数据上下行带宽的差异性以及本地设备硬件性能等问题,对于大量数据的传输,如果不分批次进行,一旦传输失败,则要全部重新开始,这无疑提高了操作的失败成本;如果每个批次分得过小,又会增加网络请求次数成本。
数据上传算法描述如下:
BEGIN
(a) MH从待上传数据集中取得数据量大小不大于N的数据集Sm。
(b) 如果Sm为空
(c) 跳到END
(d) 否则
(e) FM收到数据集Sm,对于每个数据对象Dm∈Sm,检测库中是否已存在该数据。
(f) 如果存在
(g) 比较Dm的本地变更时间TCm与库中的数据Df的本地变更时间TCf。
(h) 如果TCm>=TCf,则
(i) 将Dm更新到FM数据库中。
(j) 否则
(k) 将Df的TSf设为TSm并返回,更新到MH数据库中,从待上传数据集中移除Dm。
(l) 否则
(m) 将数据添加到数据库中
(n) 跳到BEGIN
END
数据下载时序一致性保证策略:
MH需要从FM获取数据集总量包含m个数据对象,对应的TSf依次为t1,t2,…,tm(t1≤t2≤…≤tm)。假设分为多次获取,对应的时序分别为(t1,t2,…,ti),(tj,tj+1,…,tk),…,(tl,tl+1,…,tm)。为了保证数据下载时序一致性以及避免重复下载的情况,需要保证相连的两序列满足ti-1≤ti
数据下载算法描述:
BEGIN
(a) 设置本地数据累加池S,用于存放数据集。
(b) MH将本地最大的TSm作为参数向FM发起下载请求。
(c) MH收到FM返回TSf>TSm且数据大小不大于N的数据集Sf。
(d) 如果Sf为空
(e) 跳到END
(f) 否则
(g) 对于Sf的状态码flag
(h) 如果状态码flag等于1或2
(i) 将Sf添加到S
(j) MH对每个数据对象Df∈S,检测本地是否有该数据对象。
(k) 如果存在
(l) 则比较Df的本地变更时间TCf与库中的数据对象Dm的本地变更时间TCm。
(m) 如果TCf>=TCm,则
(n) 将Df更新到MH数据库中,如果待上传数据集中有Dm则移除。
(o) 否则
(p) 将Df添加到MH数据库中
(q) 清空S
(r) 如果状态码flag等于3
(s) 将Sf加到S,向FM发送继续获取请求,保持TSm参数不变,并以S中Df个数作为偏移量参数,请求得到从FM返回的新数据集Sf。
(t) 跳到(g)
(u) 跳到BEGIN
END
对于比较是否为相同对象,可以采用分值法:根据关键度给若干属性设置不同的分值,针对两个元组相同的属性,累加分值,根据总分所属区间判定。采用分值法比较对象,可以解决数据添加冲突,但如果比较的属性过多容易影响效率,需要权衡把控。
1.2 多级扩展
前面提到的TC-TS机制适用于两级分布式主从架构系统,有时因为一些其他需求,需要将FM当做MH,如各个部门的系统需要定时将新数据上交到中央数据库;或是将MH当做FM,如外出作业的几个人员,因为业务需要,可将数据都传给其中的一个人,由他和FM交互数据,临时充当了FM的角色。针对三级或多级分布式主从架构系统,TC-TS理论上也可以很容易得到扩展,如图4所示。

图4 多级闭环图
其中Level-1与Level-2、Level-2与Level-3之间各自形成闭环,并通过TS2实现数据的跨层交互。TS2在不同的闭环中起着不同的作用。每层只负责跟相连层通信,降低了数据的耦合,体现了数据同步的层次性。
2 技术实现与应用
相比于传统的时间戳方式:在元组中添加2个属性,如创建时间和更新时间,通过它们获取新插入和更新过的数据;本文采用本地时间结合服务器时间的形式,更加契合客户端和服务器的同步关联性,结合删除标记,降低了冲突检测的维度。
2.1 Android平台下数据同步流程
通过后台设置任务队列并定时获取队列任务,根据任务标识执行相应的子任务。
部分代码如下:
while(true){
if(!tasks.isEmpty()){
Task task=tasks.poll();
if(null!=task){
doTask(task);
}}Thread.sleep(2000);}
下载的数据主要包括两类: (1) 表记录;(2) 数据库文件。对于记录,可以采用本文的增量同步机制更新;对于数据库文件,通过从FM下载压缩包的形式更新,系统中往往定义有数据库的版本信息,因此可以和系统更新相结合。
初次安装系统,提示下载对应版本号的初始数据库;每次升级系统,自定义的数据库升级方案可以将数据库版本号升级到最新;如果选择替换本地数据库,要保证本地没有待上传的数据,以免数据丢失。
如果本地有数据待上传,则当用户退出系统时,提醒用户是否上传,退出后在后台上传数据,上传结束后通知用户上传结果。
2.2 本地化编码策略
分布式环境下,因为某些特殊业务需要(如本地新增数据的离线打印),可能需要在本地生成一些标识信息(如标识记录的编码),我们通过在标识信息基础上添加后缀的形式,并通过语义控制,一定程度上保证了数据的有效和合理性。
该策略比较适用于网络信号差或没有信号的环境,虽然可能存在本地打印的标识信息和服务器端保存的标识信息相差一个后缀的情况。但对查询等操作影响不大,满足了一定程度上的业务需求。
2.3 实验结果与分析
测试使用的是2G网络,基于Android2.3.3系统,利用第三方类库Ksoap2调用WebService接口实现数据交互。以同步500 MB的数据为例,通过设置断网模拟偏远地区无信号时的环境,对于设定不同的N,实验结果如图5、图6所示,其中横坐标表示N大小,单位MB。

图5 各类时长对比 图6 同步被阻断的概率
实验结果表明,使用上述增量同步方法,能有效地保证数据同步的一致性,并且通过合理的设置N,不仅可以缩短总的同步时间,也能有效降低同步请求被阻断的几率,提高了系统的可靠性和使用性。
3 结 语
随着移动互联网的不断发展,移动办公在今后的作用会不断显现。本文通过设计的数据增量同步机制,以及其他一些策略的调整,便于在原有的集中式系统架构下扩展,并且也探讨了批次传输大小对同步性能的影响,保证并最大化满足人员的办公需求。基于本文设计并实现的移动执法智能终端系统,已经在农业执法领域投入使用,并取得了良好的成效。
[1] 陶涛.基于Android平台的嵌入式数据库同步及优化策略研究[D].天津:南开大学,2010.
[2] 姚岚.基于Web服务的智能客户端数据同步[D].上海:复旦大学,2008.
[3] 张晓丹,何锐,牛建伟.基于关联事务的移动数据库冲突处理算法[J].计算机工程,2008,34(16):60-65.
[4] Lomotey R K,Deters R.Reliable Consumption of Web Services in a Mobile-Cloud Ecosystem Using REST[C]//2013 IEEE Seventh International Symposium on Service-Oriented System Engineering(SOSE),2013(3):13-24.
[5] 赵旸.基于移动数据库的事务处理模型的研究[J].计算机工程,2006,32(5):68-70.
[6] 刘宇,戴鸿君,郭凤华,等.Android平台可增量同步的网络应用协议[J].计算机工程,2011,37(18):59-64.
[7] 邵宝军,王延章.非连接数据库间的数据交换方法[J].计算机工程,2004,30(17):77-78.
[8] 茅敏涛.基于Mobilink实现分布式数据库同步的研究[J].计算机应用与软件,2009,26(6):152-154,174.
[9] 封明玉,赵政,张钢.分布式环境下数据冲突及其解决方案[J].计算机应用研究,2002,19(2):72-74.
ON A DATA INCREMENT SYNCHRONISATION BASED ON DOUBLE TIMESTAMP IN MOBILE NETWORK
Hao Ping Lin Yuanchong
(SchoolofComputerScienceandTechnology,ZhejiangUniversityofTechnology,Hangzhou310023,Zhejiang,China)
Along with the wide use of mobile computing, data synchronisation technique plays an increasing important role in distributed environment. To deal with the specificity of distributed mobile environment, we studied and proposed a double timestamp-based data increment synchronisation mechanism, which provided a viable solution to mobile database replication technology. It presented a new thought to the hierarchical expansion of system while ensuring data consistency. Moreover, it was demonstrated through experimental results that to properly set bulk transfer units could improve the reliability of synchronous mechanism effectively. Finally we designed and implemented the intelligent terminal system of law enforcement to help site operations.
Data synchronisation Double timestamp Expansion Bulk transfer
2014-08-30。郝平,副教授,主研领域:智能控制,过程监控,故障诊断,数据仓库和挖掘。林原冲,硕士。
TP3
A
10.3969/j.issn.1000-386x.2016.04.034
