基于节点聚集系数的分布式标签传播算法
2016-05-09张素智孙嘉彬
张素智 孙嘉彬 王 威
基于节点聚集系数的分布式标签传播算法
张素智 孙嘉彬 王 威
(郑州轻工业学院计算机与通信工程学院 河南 郑州 450002)
随着互联网的发展和普及,越来越多的用户加入到社交网络,逐渐形成了大规模、多样化的社区。对于新浪微博等社交服务来说,这些社区的发现可以为用户和商家提供有价值的信息。在社区发现算法中,标签传播算法(LPA算法)具有算法思想简单、复杂度低、无需初始化社区数量等优点,但准确率较低,同时在大数据环境下,效率还不够高。将节点聚类系数引入LPA的标签更新过程中,提出一种结合MapReduce分布式计算框架的社区发现算法——DisLPA算法。实验表明,该算法不仅提高了准确率,同时有效改善了计算瓶颈问题。
社区发现 标签传播 聚集系数 MapReduce
0 引 言
近年来,随着Web2.0的逐渐兴起,社交网络(SNS)的使用变得越来越普遍,越来越多的人利用SNS扩展个人交际圈,同时发布、查找和共享信息,吸引更多的人去关注热点信息。新浪发布的2012年第三季度财报显示,截止到2012年12月底,新浪微博注册用户数已超5亿,平均每天活跃用户达到4620万。这些用户发布文字、图片、视频,转发微博,搜索信息,关注其他人等等都会产生大量的数据,这对数据分析带来了巨大的挑战,这个挑战[1]不仅是数据量膨胀的问题,而且涉及到数据深度分析需求的增长。
对SNS社区进行挖掘,可以发现网络社区中的潜在的社区结构,从而对用户角色进行评估,扩展社交圈,以实现高效准确的个性化推荐,同时能够提供精准的商业定位,为商家带来更大的商机。但是在线网络社区数据具有庞大性、稀疏性、流动性,这些特性使得社交网络尤为复杂。目前,不同领域的众多研究者对复杂网络的基本统计特性做了很多研究,如小世界效应[2](具有短路径长度和高聚类系数特点),无标度特性[3](节点度服从幂函数分布),聚类特性[4](同社区内节点连接较为紧密)。
目前的社区挖掘大致分为基于优化的方法和基于启发式的方法[5]两种。局部搜索方法和谱方法是基于优化的方法中两类最主要的方法。在基于优化的方法中,典型的有谱平分算法,GA(Guimera-Amaral)算法,FN(Fast Newman)算法等,它们都是将复杂网络的问题转化为优化目标函数来计算复杂网络的社区结构。基于启发式方法的共同特点是:在优化目标不明确的前提下,设计和运用合理的启发式规则来识别网络社区,如GN(Girvan-Newman)算法、MFC算法、HITS算法、CPM算法等。
为了改善社区发现算法复杂度高的问题,Raghavan等人提出了一种启发式的,基于标签传播的社区发现算法(LPA)[6],具有近似线性的时间复杂度,目前在众多的社区发现算法中效率最高。
很多学者对标签传播算法进行了改进和优化。利用特征空间嵌入实现数据点的稀疏重构能反映数据点与特征空间嵌入间的本质相似性结构的特点,陶剑文等人[7]提出了一种稀疏近似最近特征空间嵌入标签传播的方法,使得预测的数据标签具有平滑性和鲁棒性。王庚等人[8]提出了一种基于标签传播的稳定重叠社区挖掘算法(soCLP),该方法引入平衡因子对算法的稳定性进行控制,以解决重叠社区挖掘中效率与稳定性的冲突。
但是由于现如今激增的SNS用户和这些用户产生的大数据,传统的LPA算法来分析那些具有庞大节点数的社区效率较低,只靠单一的计算结点无法满足这样的计算需求,此时就需要多个并行的结点来进行处理。
为了解决因节点数增加等问题引起的挖掘算法效率低下的问题,赵雅端等人[9]将传统Newman算法并行化,并应用在GPU并行计算中,使得传统的社区挖掘算法在不失准确性的前提下运行效率有了提高。宋珏等人[10]提出了一种基于日志聚类的邮件网络社区挖掘算法LENCM,该算法在维持执行效率的基础下提高了挖掘社区的质量。
本文提出了一种基于MapReduce的分布式LPA社区发现算法——DisLPA,在提高准确率的基础上,有效改善了计算瓶颈问题。
1 相关工作
1.1 LPA算法
标签传播算法(LPA)的思想是根据已标记节点的标签信息去预测未标记节点的标签。它是由Zhu等人[11]率先提出的一种基于图的半监督学习方法。2007年Raghavan等人[6]根据标签传播的思想,提出了基于标签传播思想的社区发现算法。算法基本思想:一个节点x,它的k个邻居节点分别为x1,x2,…,xk,每个邻居节点对应的label为l1,l2,…,lk,这些邻居节点共同决定了x所在的社区。该算法流程为:
(1) 首先初始化节点label,将每个节点赋予一个唯一的label,此label代表社区标识,即初始化之后每个节点自身为一个社区。
(2) 以迭代的方式更新图中所有的节点。迭代规则为:节点x的所有邻居节点x1,x2,…,xk中,对应的label为l1,l2,…,lk出现次数最多的那个label传递给节点x。当出现num[max(l1,l2,…,lk)]≥2的情况时,将任意一个节点的label作为x的label。
(3) 反复执行步骤(2),直到每个节点的label都不再变化或者达到最大迭代次数为止。
(4) 若两个节点具有相同的label,那么认为这两个节点在同一个社区。
节点标签值更新步骤如图1所示。
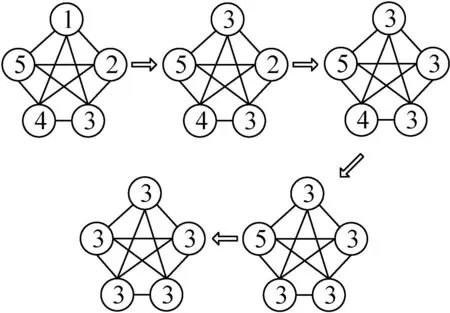
图1 节点label更新步骤
如图1所示,节点label的传递是一个迭代的过程,每一次迭代,节点的label就会根据其邻居节点的label进行更新。这个更新的过程分为同步更新和异步更新两种。
在同步更新中,节点x在第t次迭代的label值lx取决于其邻居节点在第t-1次迭代使所得的label,即:
lx(t)=f(lx1(t-1),…,lxk(t-1))
其中,lx(t)表示节点x在第t次迭代时label,f函数的返回值是在x的邻居节点的label里出现次数最高的那个label。然而在同步更新过程中可能会出现图2中的无限迭代的情形,从而无法得到社区结构。
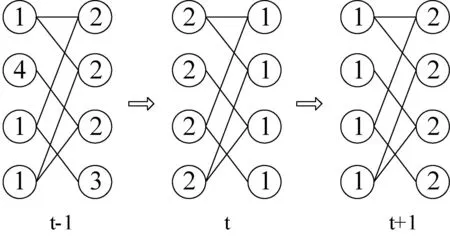
图2 同步更新震荡情况
在异步更新中,节点在第t次迭代时的label不仅仅取决于第t次迭代更新过的label,同时和剩下未进入t次迭代的邻居节点在t-1次迭代的label有关,即lx(t)=f(lxi1(t),…,lxin(t),lxi(n+1)(t-1),…,lxk(t-1))其中xi1,…,xin表示在t次(本次)迭代中更新过label的节点,xi(n+1),…,xik表示在本次迭代中还没有更新的节点,f同上。
近年来,有研究人员不断地对LPA社区挖掘算法进行了改进和优化。Leung等人[12]使用LPA算法来分析大规模在线网络,其实验预示了标签传播算法是一种快速有效的社区发现算法,在处理超大规模复杂网络方面潜力巨大。Barber等人[13]为了避免所有的节点都分配到一个社区,设计了一个带约束条件的标签传播算法LPAm,将社区发现算法转化为目标函数优化的问题,但是该算法会有陷入局部最大值的趋势,这会导致社区发现不准确。针对这个问题,Liu等人[14]将LPAm与多步层次贪婪算法MSG(Multi-step Greedy Agglomerative Algorithm)相结合,提出了一个模块化,分层化的标签传播算法LPAm+,使LPA类算法的性能得到进一步改善。
1.2 MapReduce计算模型
MapReduce是由Google公司最早提出的,它是一种用于海量数据计算(大于1T)的并行运算模型,最初被Google应用于Google搜索引擎的服务器集群中[15],实时进行庞大的搜索数据计算。Map和Reduce两个程序构成了MapReduce的整体架构,其中Map程序将input的数据切分成各类型的小块,并分配给大量的服务器处理;Reduce程序将Map处理后的结果汇总整理后输出给客户端[16]。MapReduce的执行流程如图3所示。
在编程的时候,需要编写Map和Reduce这两个主要函数[17]。
Map:
Reduce:
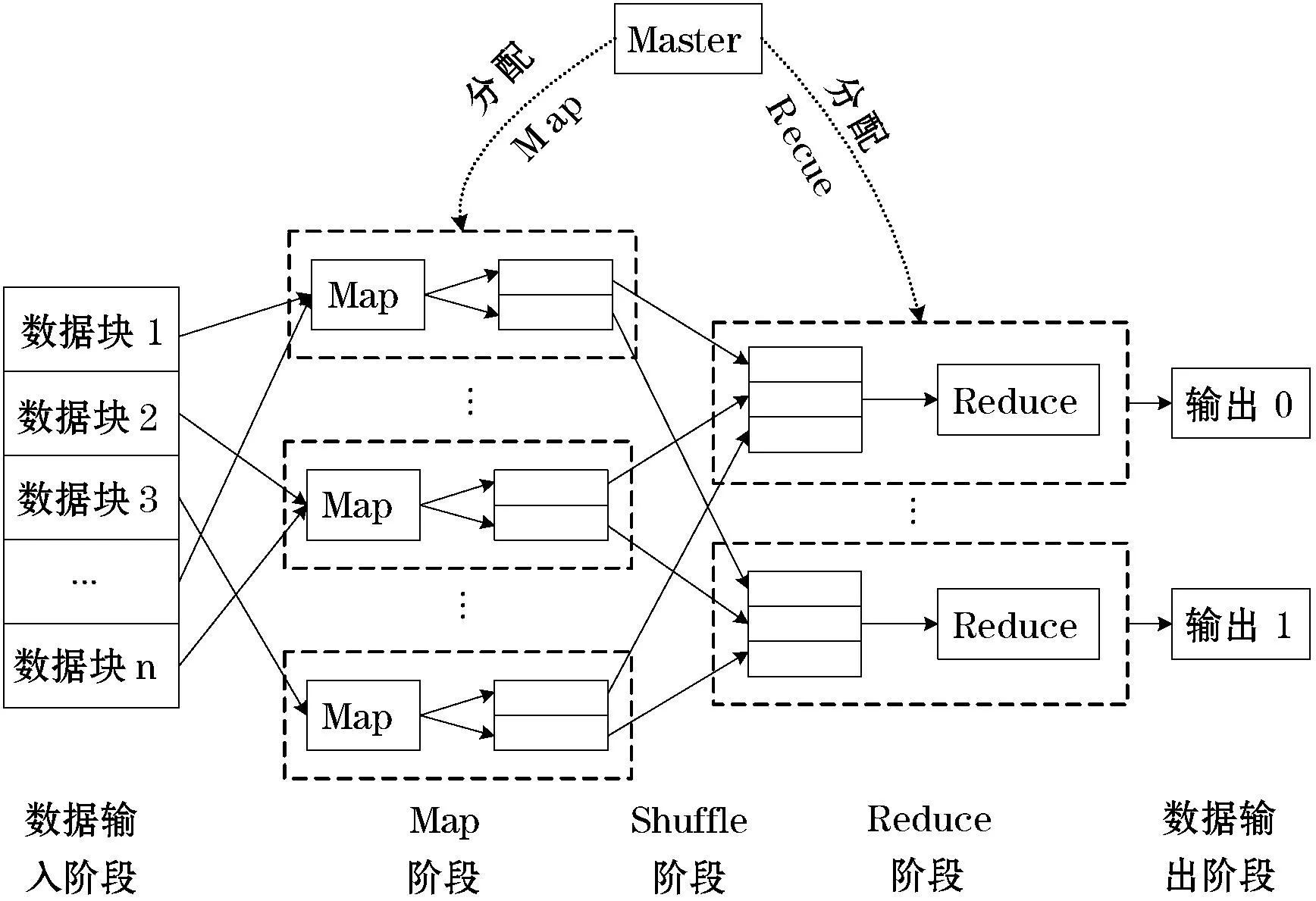
图3 MapReduce执行流程
MapReduce可以充分发挥普通计算机集群的计算能力,以解决单一普通计算机由于处理器以及存储资源的限制而无法高效处理海量数据计算的问题。
2 基于LPA的分布式社区发现算法
2.1 基本思想
本文采用MapReduce分布式编程模型来设计分布式LPA算法——DisLPA,从而解决计算的瓶颈问题。
该算法编程模型分为三个阶段[18]:
(1) 从输入文件读取的元数据转化成
(2) 所有输入数据的
(3) 其中每个key和他所有关联的value值[u1,…,us]传递给reduce函数(某一Hadoop节点上的)调用,用来创建一个输出的key-value键值对[(m1,x1),…,(mt,xt)](reduce阶段,见(2))。整个过程中,输出的key值不需要匹配输入的key,它们不必是相同的。
2.2 算法步骤
在标签传播算法中,通常将网络抽象为一个简单的无向图G(V,E),其中V表示节点(或顶点Vertex)的集合,E表示边(Edge)的集合,同时,集合中的每一条边都与集合V中的一对节点相对应。|V|表示图的阶,即节点集合中节点的个数,|E|表示图的边数,即边集合中边的条数。节点的邻居节点集合Ni(j)可以表示为:
Ni(j)={j:j∈V,(i,j)∈E}
第一次更新节点label时,每个label都是唯一的,更新的原则是在邻居节点中随机选择一个节点进行更新,在第一次更新后,大约90%的节点会划分到最终所属的社区。因此,第一次节点label更新时的选择会直接影响最终的社区划分结果。这极大地降低了算法的鲁棒性,同时影响了社区划分的准确性。
为了解决这一问题,本文对每个label增加权值,用节点聚集系数:
(1)
来衡量节点的影响力,n表示在节点i的所有k个邻居间的边数。将加入了节点聚集系数的标签传播算法记为CLPA算法。
LPA算法的每一次迭代,要执行更新顶点label的操作。对于每个分区,我们需要运行几个带来大开销的map-reduce进程,因此我们将所有的分区并行计算,来取代将整体进行计算的方式。
算法DisLPA的具体步骤如下:
(1) 首先,初始化。DisLPA为每个顶点i分配一个唯一的label,将label初始化为顶点的id,即初始化不同的label,即li=i,此处,i表示节点i的id。将迭代次数初始化为p=1。
(2) Map进程:将节点id赋值给map进程的key,将二元组(lj,j)传递给map进程的value,其中lj表示节点j的标签值,j表示对应id节点的邻居节点和其标签值。输出list(l,n),n是对应标签值l的所有邻居的数量。
(3) Reduce进程:输入list(l,n),得到n值最大对应的label,根据(1)中节点聚集系数Ci,由式(2)更新每个顶点i的label,并赋给节点i:
(2)
其中,δ是克罗内克符号,满足:
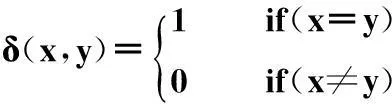
(4) 上一步Reduce输出的结果作为下一个Map的输入。重复步骤(2)-(3),直到所有的节点不再发生变化为止。
DisLPA算法的伪代码如下:
Input:G(V,E),p=1,Ci=1,li=i;
If all vertex not change do
{ p=p+1;
Map(key1,value1)
{
key1←all vertex id;
value1←(lj,j);
//j∈Ni(j),l∈L;
for(each nerghborID in N of i)do
(lj,1);
key2←lj;
value2←Cj·l;
Output(key2,value2);
}
Reduce(key2,value2)
{
key3←nerghborID m of vertex I;
value3←(lm,m);
Output(key3,value3);
}
else
end
}
该算法不仅改进了传统LPA算法不稳定的特点,同时极大地提高了算法执行的效率。
3 实验及分析
该实验分别选取基准数据和实际数据进行对比分析。基准数据采用单机模式进行实验分析算法的准确性,实际数据采用集群模式分析算法的高效性。
3.1 实验环境
在Linux下建立Hadoop集群环境,该集群中配备了4个节点,每个节点的处理器为Alienware Auroa ALX(ALWAD-02)、6 GB、硬盘1500 GB。其中1个节点作为Namenode和Jobtracker,其余3个节点负责具体的计算任务。
3.2 基准网络
实验选取两个经典的基准数据,分别为Zachary’s karate club数据集[19]和Dolphin社会关系网[20],使用基于节点聚集系数的LPA算法(CLPA)来分析。
对比表1结果可以看出,CLPA准确率高于LPA,证明了其可行性。

表1 LPA和CLPA准确率对比
3.3 实际网络
本文通过调用新浪微博官方的API来获取微博数据,用来比较DisPLA算法和单机分析的CLPA算法以及传统LPA算法的性能。
社区质量的评价采用量化指标模块化度量,是由Newman和Girvan提出[21]的,至今为止比较权威的衡量指标。定义为:
其中,M为网络社区数目;表示边两端都在社区s中的边数;Os表示边一端在社区s中的边数;E表示网络中边总数。
算法由于牵涉到多次迭代,在处理小规模数据的时候,其运行时间是可以接受的,但是面对较大规模的数据,算法的处理能力明显下降,幸运地是,算法的并行化版本减缓了这一下降趋势,使得算法能够在有限的时间内处理大规模数据。
LPA,CLPA,DisLPA算法模块度和运行时间对比结果如表2所示。
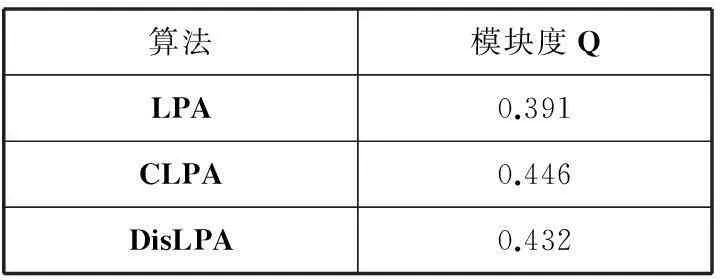
表2 微博数据实验结果
从表1、表2和图4的对比结果可以看出,与传统的LPA算法相比,CLPA算法能够较准确地发现社区结构,同时,随着网络节点数的增加,CLPA算法的扩展——DisLPA算法减少了时间上的开销,提高了发现社区的效率。
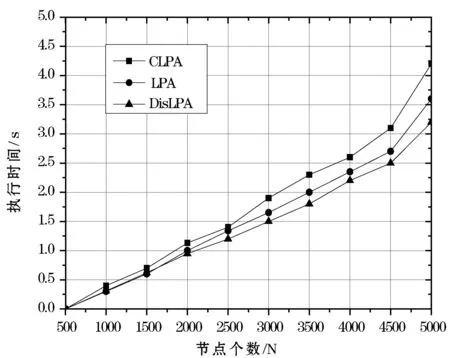
图4 执行时间随节点数的变化情况
4 结 语
本文在节点聚集系数的概念基础上,提出了一种改进的标签传播算法CLPA,同时对CLPA算法并行化处理得到了DisLPA算法,并在Hadoop集群中运行,实验结果证明了,CLPA算法不仅继承了LPA算法优点,而且提高了LPA算法的精度,但时间消耗上略大于传统LPA算法。而DisLPA算法不仅提高了准确率,同时有效地减少了运行时间,提高了效率。
但是我们提出的CLPA和DisLPA算法未考虑社区重叠的问题,在未来的研究中将考虑社区的重叠性,并对现有算法进行相应的改进和应用。
[1] 覃雄派,王会举,杜小勇,等. 大数据分析——RDBMS与MapReduce的竞争与共生[J]. 软件学报,2012,23(1):32-45.
[2] Watts D J,Strogatz S H. Collective dynamics of ‘small-world’networks[J]. nature,1998,393(6684):440-442.
[3] Adamic L A,Huberman B A. Power-law distribution of the world wide web[J]. Science,2000,287(5461):2115-2115.
[4] Girvan M,Newman M E J. Community structure in social and biological networks[J]. Proceedings of the National Academy of Sciences of the United States of America,2002,99(12):7821-7826.
[5] 刘大有,金弟,何东晓,等. 复杂网络社区挖掘综述[J]. 计算机研究与发展,2013,50(10):2140-2154.
[6] Raghavan U N,Albert R,Kumara S. Near linear time algorithm to detect community structures in large-scale networks[J]. Physical Review E,2007,76(3):036106.
[7] 陶剑文,FLC,王士同,等. 稀疏近似最近特征空间嵌入标签传播[J]. 软件学报,2014,25(6):1239-1254.
[8] 王庚,宋传超,盛玉晓,等. 基于标签传播的稳定重叠社区挖掘算法研究[J]. 山东科学,2013,26(5):61-68.
[9] 赵雅端,卢罡,赵莹,等. 基于GPU的复杂网络社区挖掘算法并行计算[J]. 计算机应用研究,2013,30(8):2426-2428.
[10] 宋钰,何小利. 一种基于日志聚类邮件网络社区划分挖掘算法[J]. 科技通报,2014,30(2):96-98.
[11] Zhu X,Ghahramani Z. Learning from labeled and unlabeled data with label propagation[R]. Technical Report CMU-CALD-02-107,Carnegie Mellon University,2002.
[12] Leung I X,Hui P,Lio P,et al. Towards real-time community detection in large networks[J]. Physical Review E,2009,79(6):066107.
[13] Barber M J,Clark J W. Detecting network communities by propagating labels under constraints[J]. Physical Review E,2009,80(2):026129.
[14] Liu X,Murata T. Advanced modularity-specialized label propagation algorithm for detecting communities in networks[J]. Physica A: Statistical Mechanics and its Applications,2010,389(7):1493-1500.
[15] Dean J,Ghemawat S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM,2008,51(1):107-113.
[16] 杨文志. 云计算技术指南: 应用,平台与架构[M]. 北京: 化学工业出版社,2010.
[17] 刘鹏. 云计算[M].2版. 北京:电子工业出版社,2011.
[18] 曾大聃,周傲英. Hadoop 权威指南中文版[M]. 北京: 清华大学出版社,2010.
[19] Zachary W. An Information Flow Modelfor Conflict and Fission in Small Groups1[J]. Journal of anthropological research,1977,33(4):452-473.
[20] Lusseau D,Schneider K,Boisseau O J,et al. The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations[J]. Behavioral Ecology and Sociobiology,2003,54(4):396-405.
[21] Newman M E J,Girvan M. Finding and evaluating community structure in networks[J]. Physical Review E,2004,69(2):026113.
DISTRIBUTED LABEL PROPAGATION ALGORITHM BASED ON NODES CLUSTERING COEFFICIENT
Zhang Suzhi Sun Jiabin Wang Wei
(SchoolofComputerandCommunicationEngineering,ZhengzhouUniversityofLightMdustry,Zhengzhou450002,Henan,China)
Along with the development and popularity of Internet,more and more users join in social networks,and this gradually forms the large-scale and diverse communities. For social networking services such as Sina microblogging,the detection of these communicates can offer valuable information to users and merchants. Among numerous community detection algorithms,the label propagation algorithm (LPA) has the advantages of simple algorithm idea,low complexity,and no need in initialising the numbers of community,etc. However,its accuracy is rather lower,and meanwhile its efficiency is not high enough in the environment of big data. We proposed a community detection algorithm,which combines MapReduce distributed computation framework,by introducing nodes clustering coefficient into the process of LPA label update,we call it DisLPA. Experiment showed that the algorithm not only improved the accuracy,but also effectively solved the bottleneck problem of calculation.
Community detection Label propagation Clustering coefficient MapReduce
2014-09-10。国家自然科学基金项目(61201447)。张素智,教授,主研领域:Web数据库,分布式计算和异构系统集成。孙嘉彬,硕士生。王威,硕士生。
TP301.6
A
10.3969/j.issn.1000-386x.2016.04.030
